







Java容器–HashMap底层简单理解
一、存储介绍
HashMap底层实现采用了哈希表,数据结构中由数组和链表来实现数据的存储。
- 数组:占用连续的空间。寻址容易,查询速度快。但是,增加和删除效率非常低。
- 链表:占用空间不连续。寻址困难,查询熟读慢。但是删除和增加效率高。
哈希表就是结合两者有点而产生的,也就是哈希表的本质就是“数组+链表”。
二、HashMap中常见的成员变量
/**
* 默认初始容量
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* 最大的数组容量
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* 负载因子:决定数组在什么情况下进行扩容,当数组容量已经使用75%,
*就需要扩容。
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
*是否转换为红黑树的阈值
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* 将红黑树转化为链表的阈值
*/
static final int UNTREEIFY_THRESHOLD = 6;
/**
*达到转化红黑树的数组长度
*/
static final int MIN_TREEIFY_CAPACITY = 64;
/**
* The number of key-value mappings contained in this map.
*/
transient int size;
/**
*桶数组
*/
transient Node<K,V>[] table;

三、HashMap中存储元素的节点类型
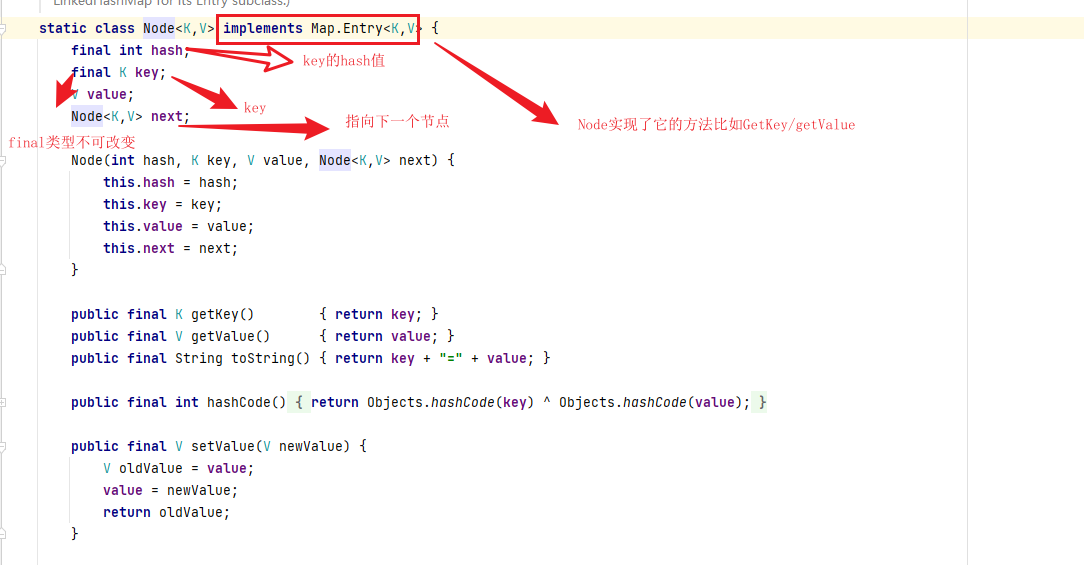
- Node节点类型
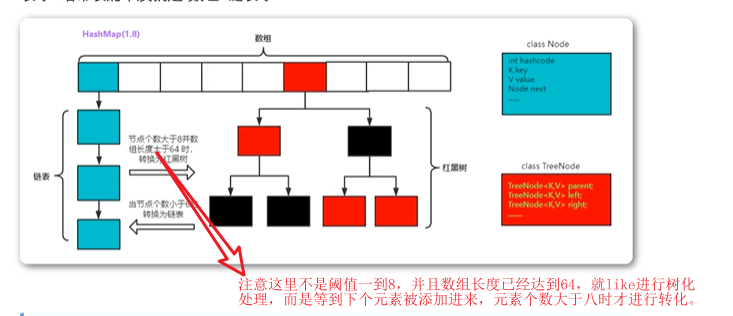
我们常听说当HashMap中的链表长度大于8,且Hash桶的长度大于64时会将长度大于8的链表转化为红黑树。树的结构是什么样子的呢?
transient是一个修饰符,用于告诉编译器在序列化(将对象转化为字符序列)时不需要持久化保存该字段的值。在反序列化(将字符序列转化为对象)时,该字符将初始化为其的值默值,引用类型为null,原始数据类型为0.
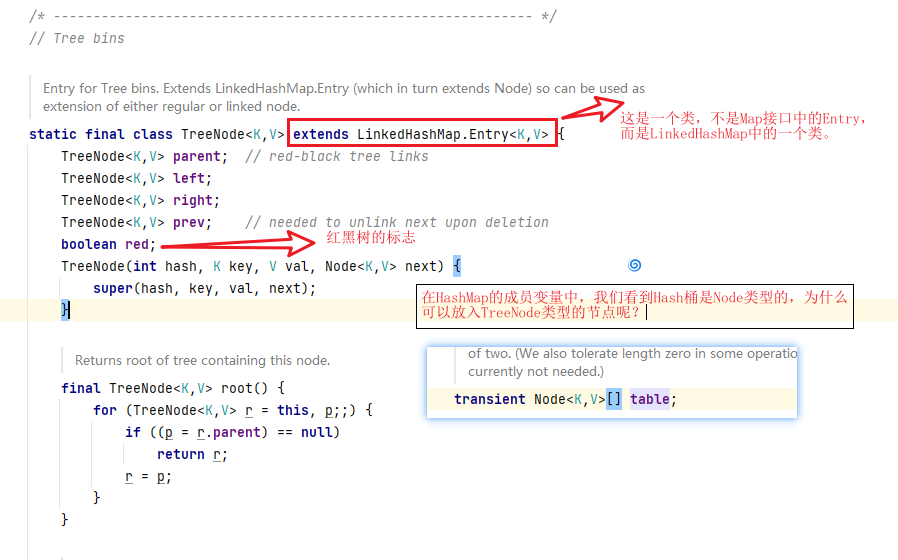
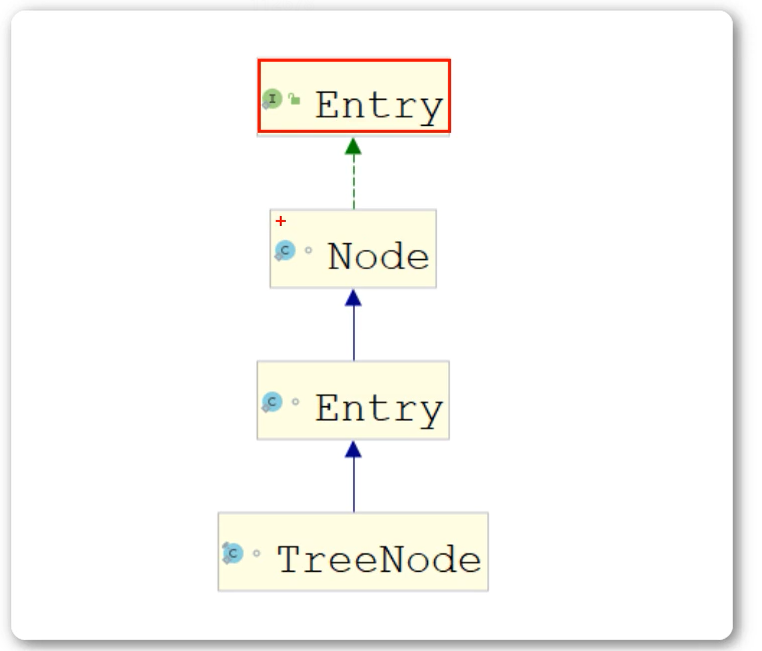
对于两种不同的节点为什么可以放入一个Node类型的桶数组中,原因是它们之间存在着继承的关系:
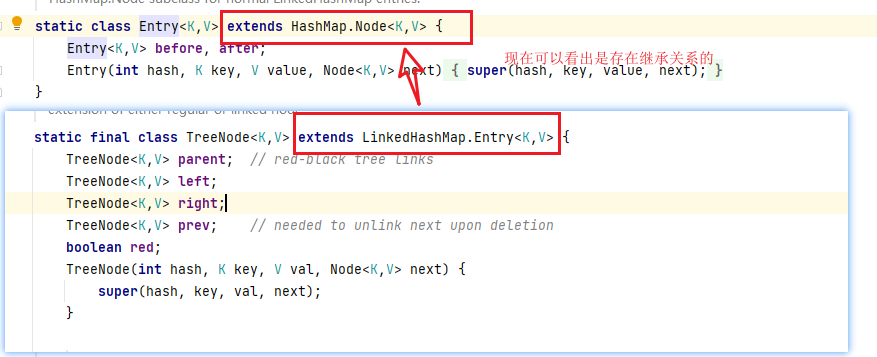
四、HashMap中数组的初始化
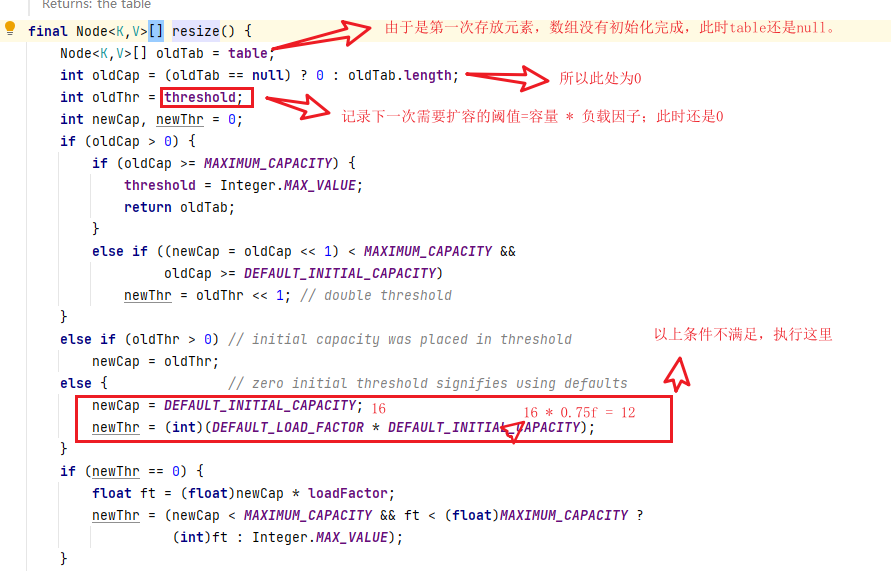
在JDK 1.8 的HashMap中对于数组的初始化是采用延时加载的初始化方式。通过resize()实现数组 的初始化处理。该方式即实现了数组的初始化化,也实现数组实现扩容处理。
何为延时初始化,也就是在new一个实例时候,它不会去初始化数组table而是等到第一个元素加入时,才进行初始化操作。

在这里我们进入无参构造方法中看一眼,它只是对loadFactor 负载因子赋值一个默认的负载因子0.75f。

进入HashMap的put方法中,可见也很简单,只是调用了一个putVal方法。

进入putVal中
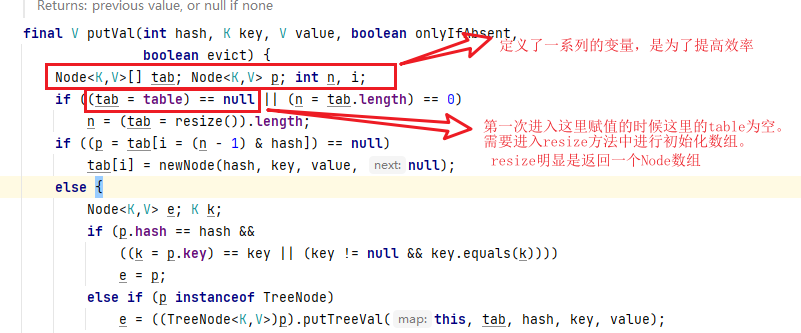
进入resize中
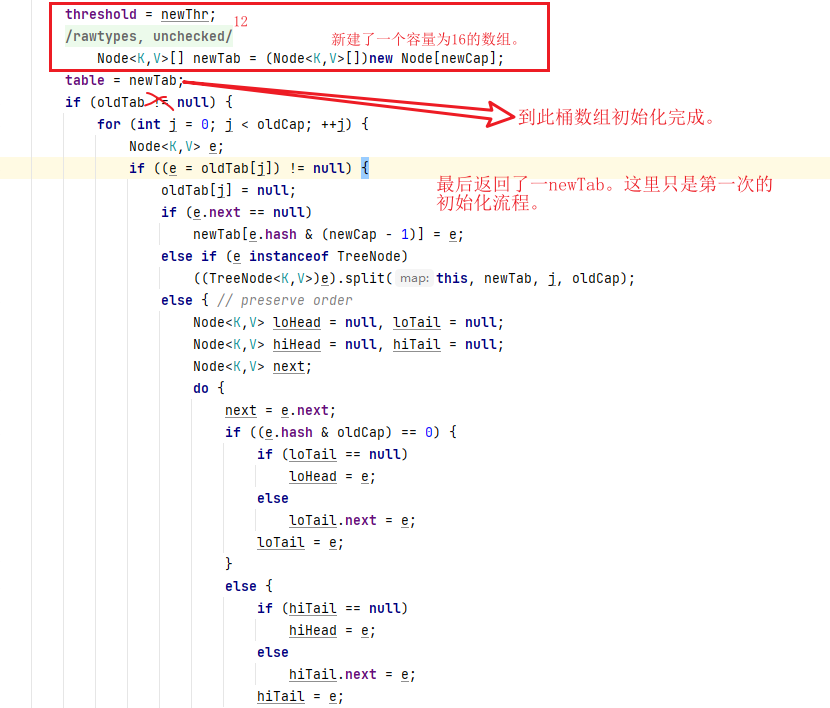
五、HashMap中计算Hash值
- 首先,获得key对象的hashcod,调用key对象的hashcodee()方法,获得key的hash值。
- 这个hashcode计算出hash值(要求在【0,数组长度-1】),hashcode是一个整数,我们需要将其转化成【0,数组长度-1】的范围内,要求尽量均匀的分布在这个区间 内。

还是从put方法进入


使用key的hashcode与其高16位进行异或运算,例如
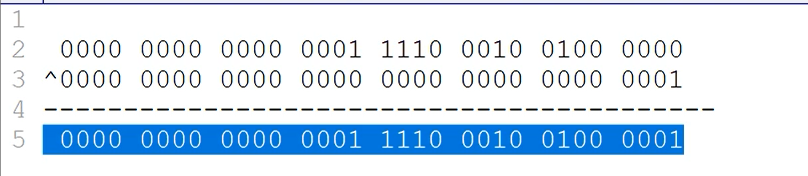
这里产生的hash值显然不在数组的范围内,也不是最终的hash值。
回到putVal中
异或运算例子:

六、添加元素
上面计算hash值时候第一次没有元素,就直接放入,现在计算出来的位置已经有元素了。
那么现在有元素了,我们怎么处理。
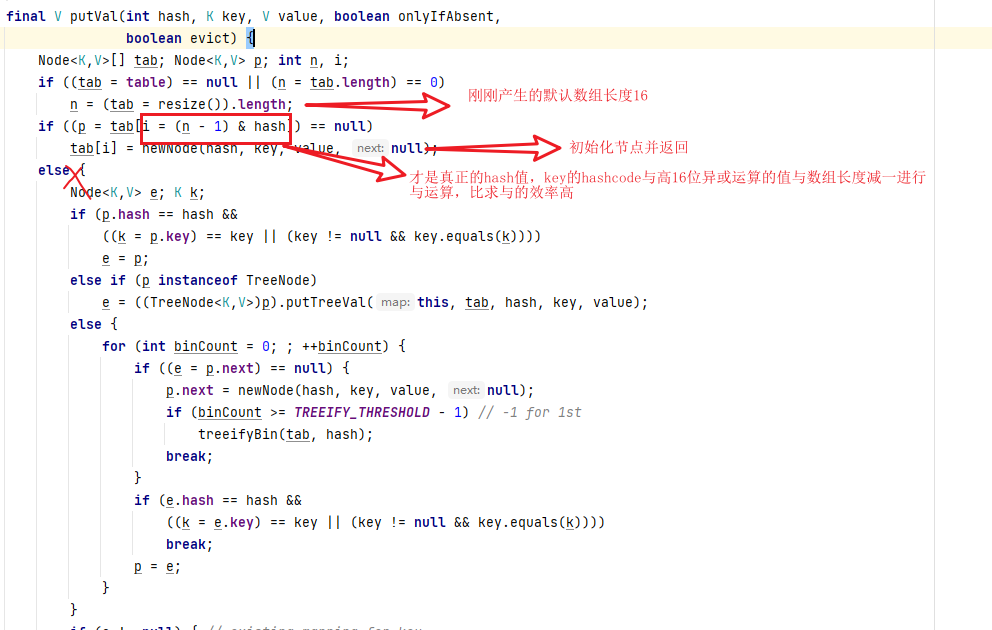
在putVal中,
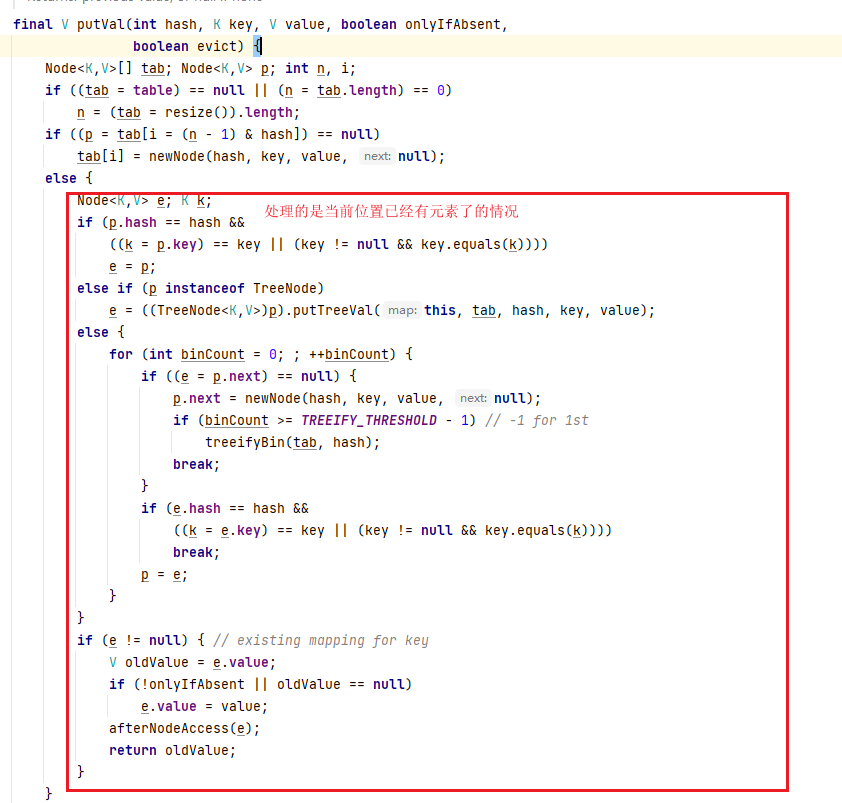
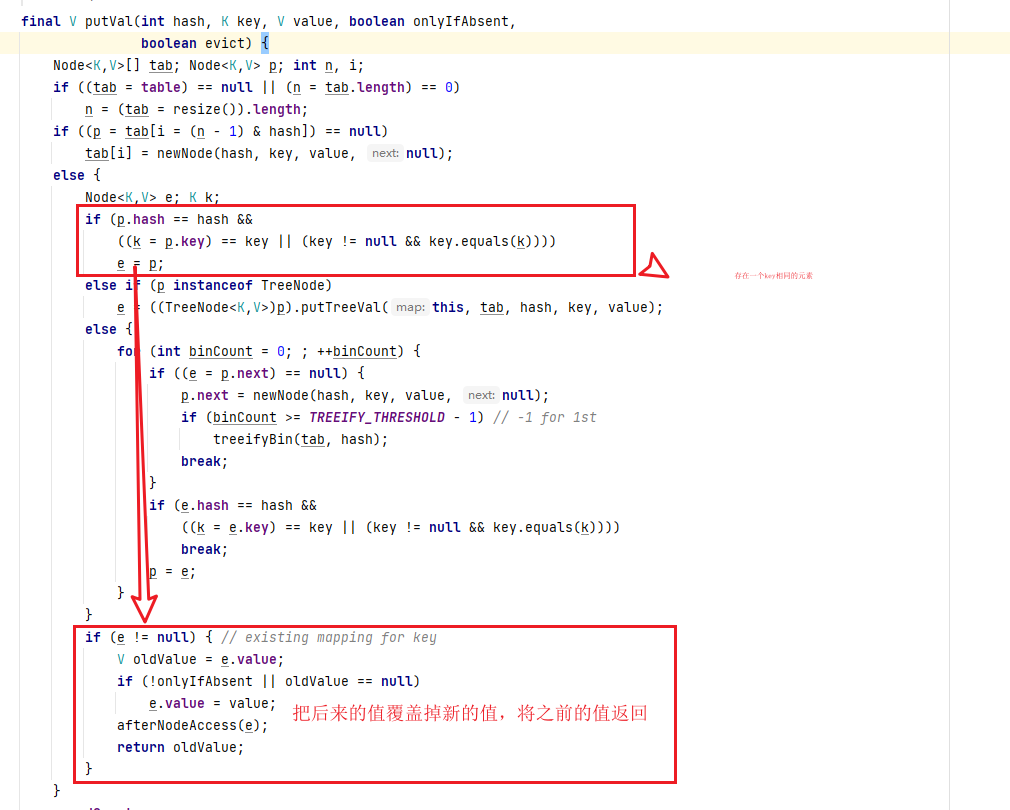
如果hash值相同,但是value不同就会执行上图的else,遍历到链表的最后,将其挂载链表的最后。
七、数组扩容
还是从put开始进入putVal中

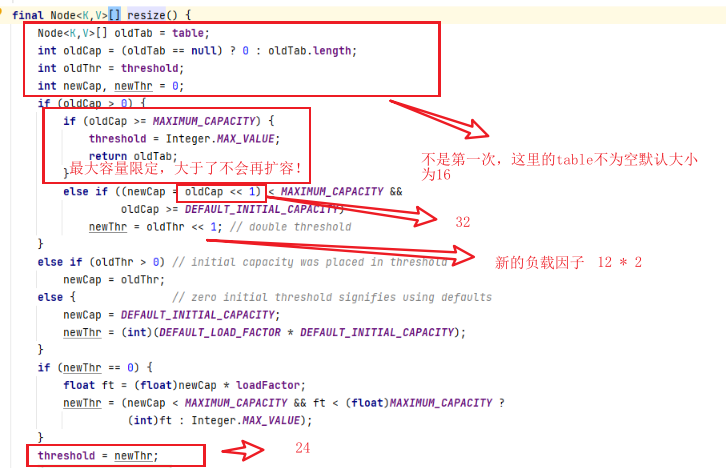
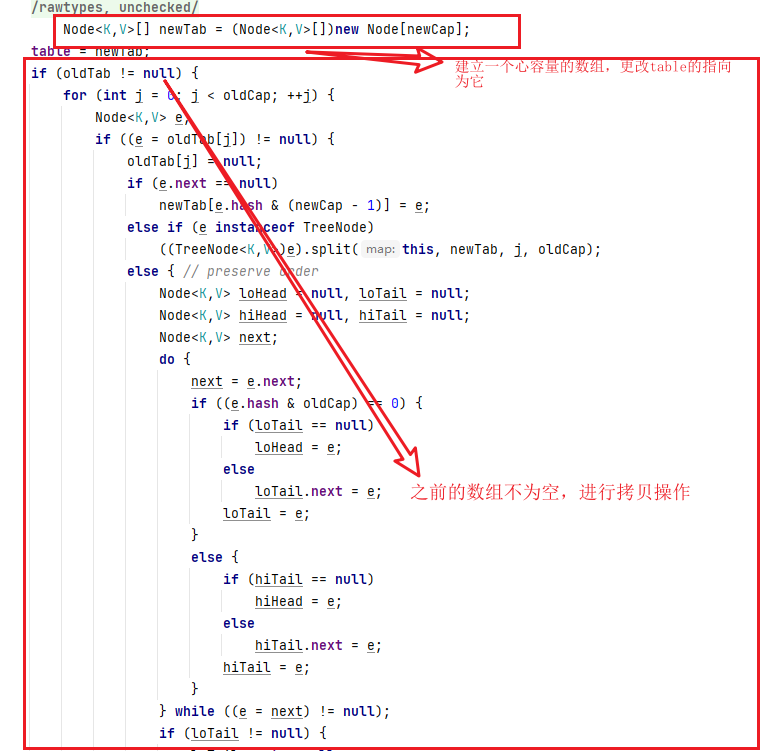
七、数组扩容
还是从put开始进入putVal中
七、数组扩容
还是从put开始进入putVal中

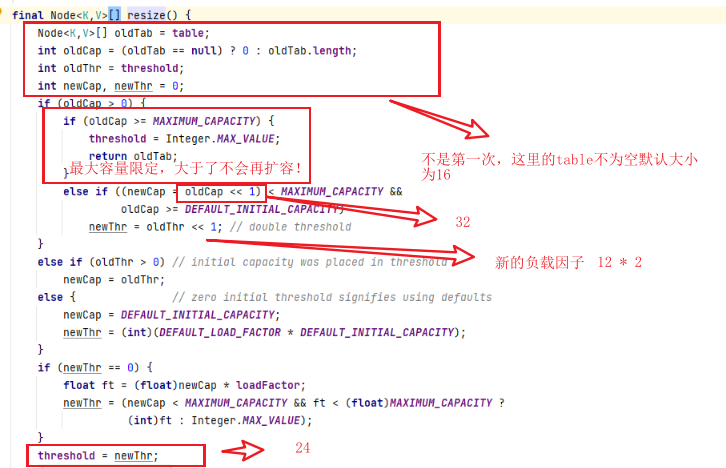
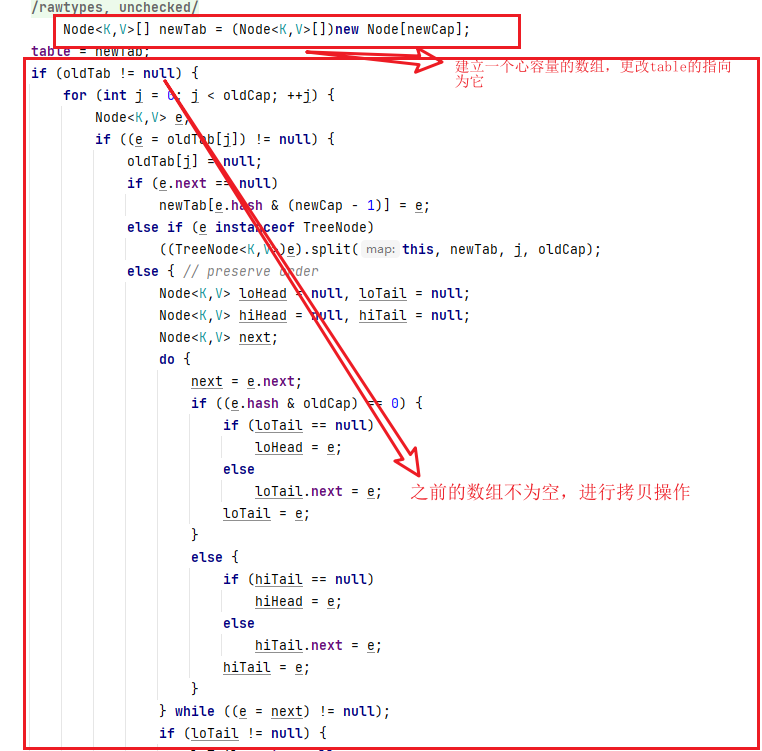
这就是主要过程的原理的理解!
















 800
800











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











