







一、Elasticsearch
搜索引擎,响应速度非常快,特别是对大数据量的情况
1.初始elasticsearch


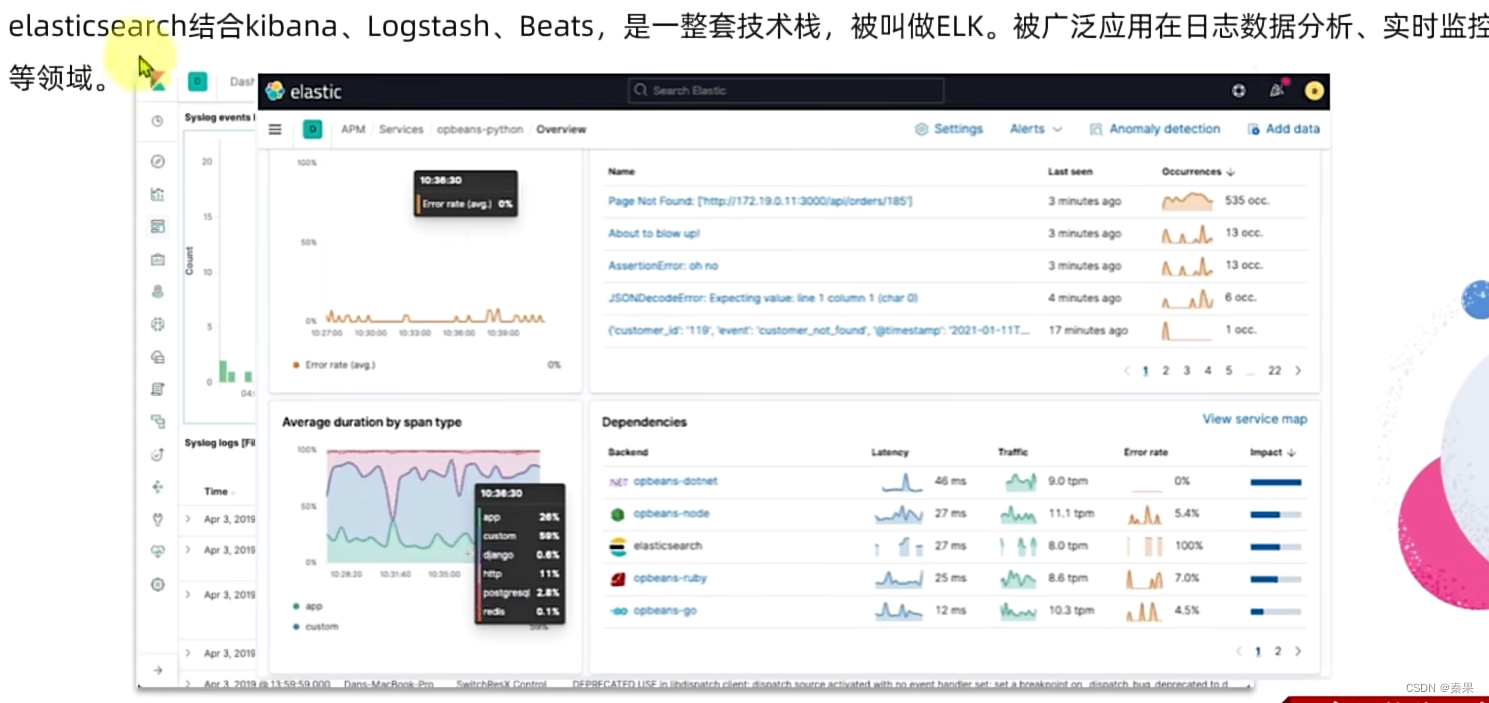

如果只需要商品搜索,百度这种搜索网站,只需要第二个就够了
docker部署:day08-Elasticsearch - 飞书云文档 (feishu.cn)
es是restful的接口,只要发http请求就可以访问到它。
想要可视化还要安装Kibana:
由于es直接使用http请求访问接口,不方便记不住路径,使用kibana:
Tools有提示,且方便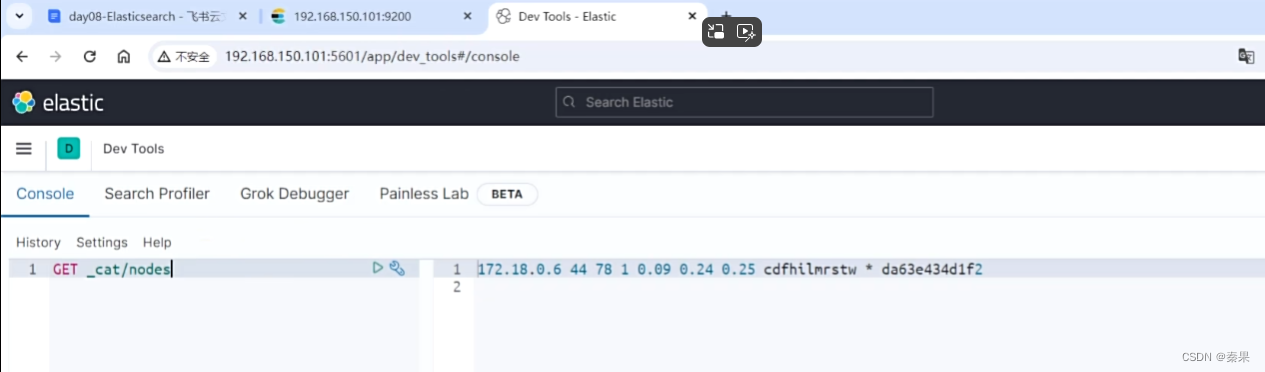
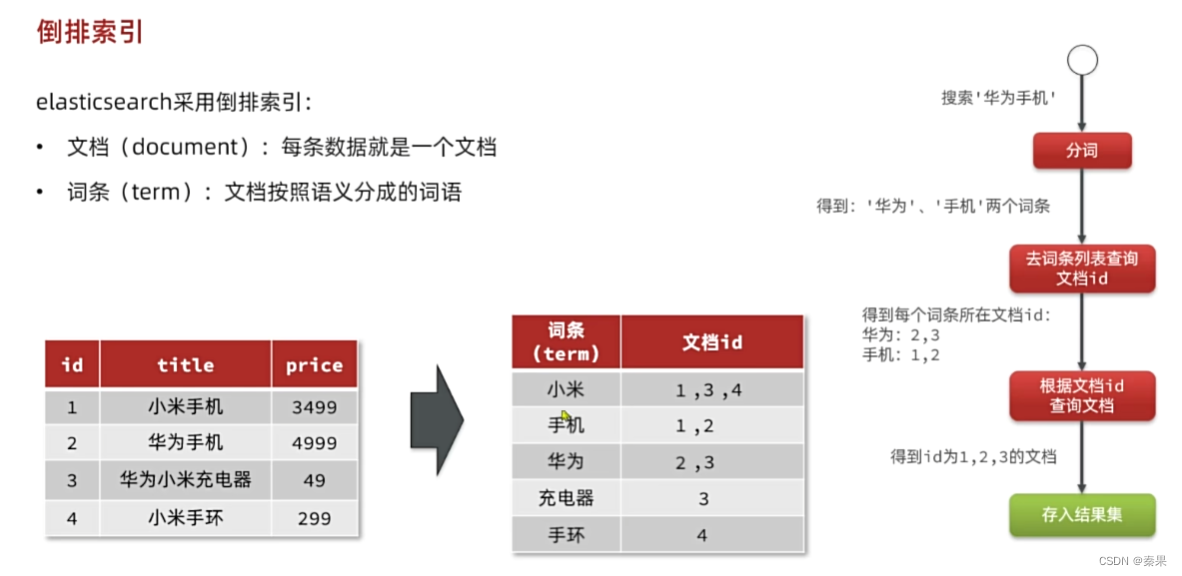
①倒排索引
使用id索引搜索的话它把id放入B+树,可以很快查询到目标,但是不使用id且模糊搜索就会一条一条进行判断,速度很慢
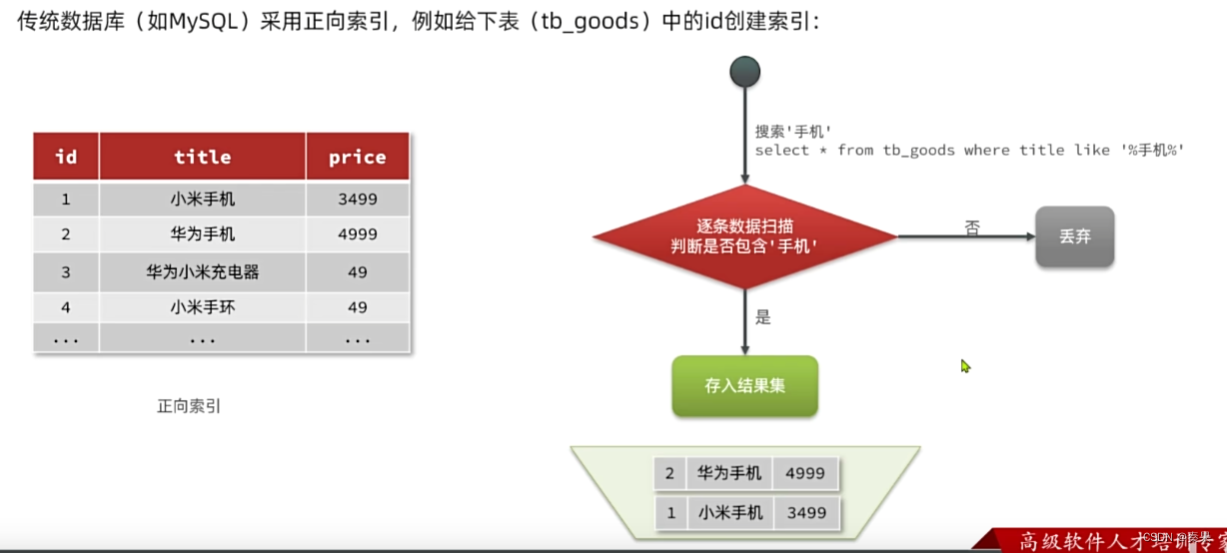
两次搜索,第一次是目标分词后的文档id,再根据文档id查询到所需目标
②IK分词器
中文语义没有空格,分词外国人干不好

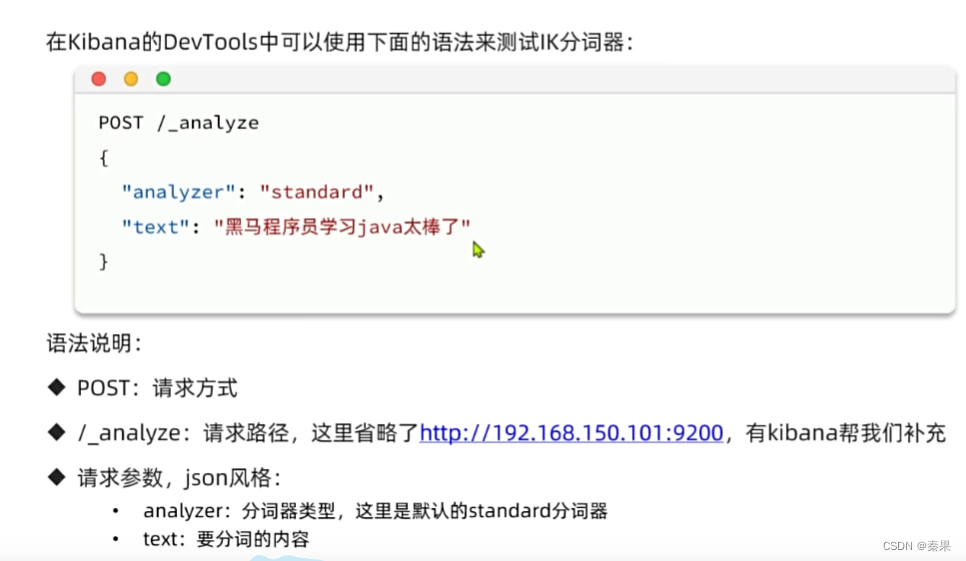
ik中包含了词典,ik会遍历你的句子两个两个遍历词典中有就是一个词,然后三个三个
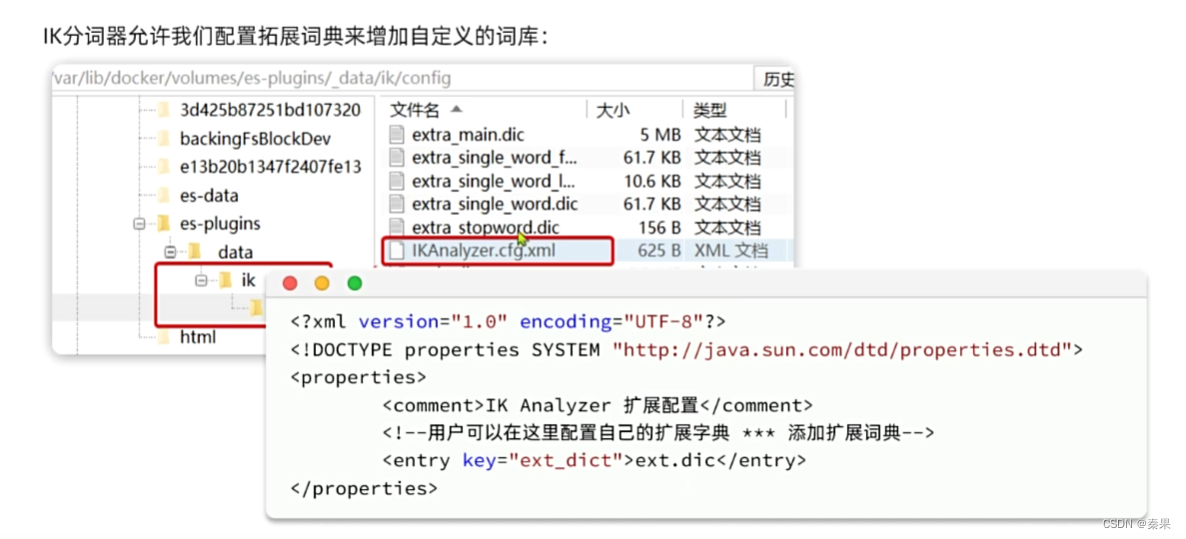
词典可能已经落后了,自定义词典后就可以被分词了
③基础概念
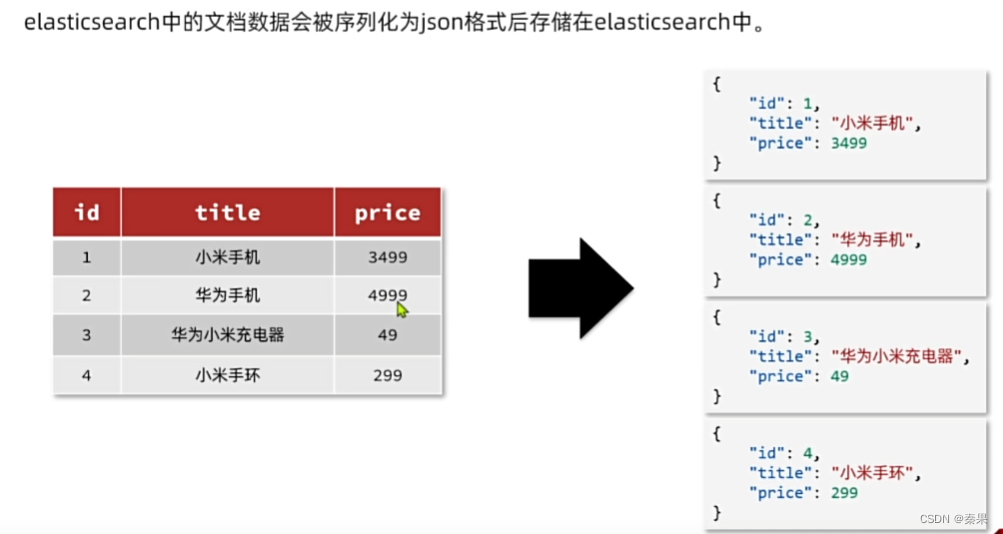
它会把相同类型的放入一起,可以称为索引库

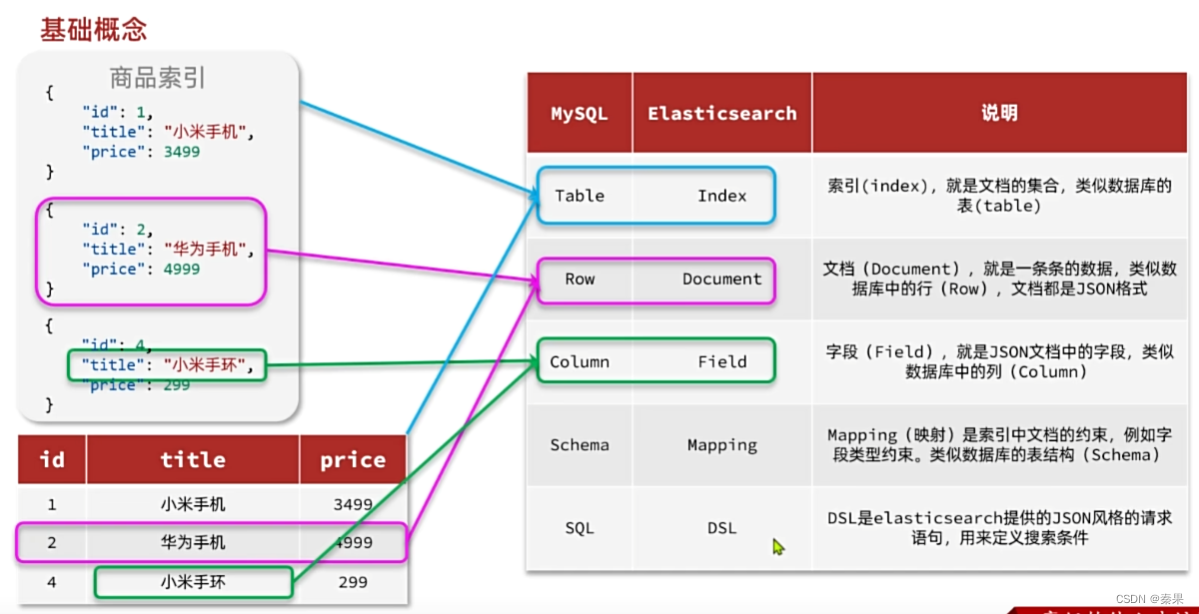
dsl就是类似之前查询分词结果的搜索方式:使用JSON语句进行搜索
2.索引库操作
①Mapping映射属性

字符串中keyword指那些不能被分词的内容,分词了就没有意义了:例如比亚迪
有根据它搜索和排序的需求就需要设置index为true
analzer是有分词的需求
properties是会有嵌套的属性
②索引库操作
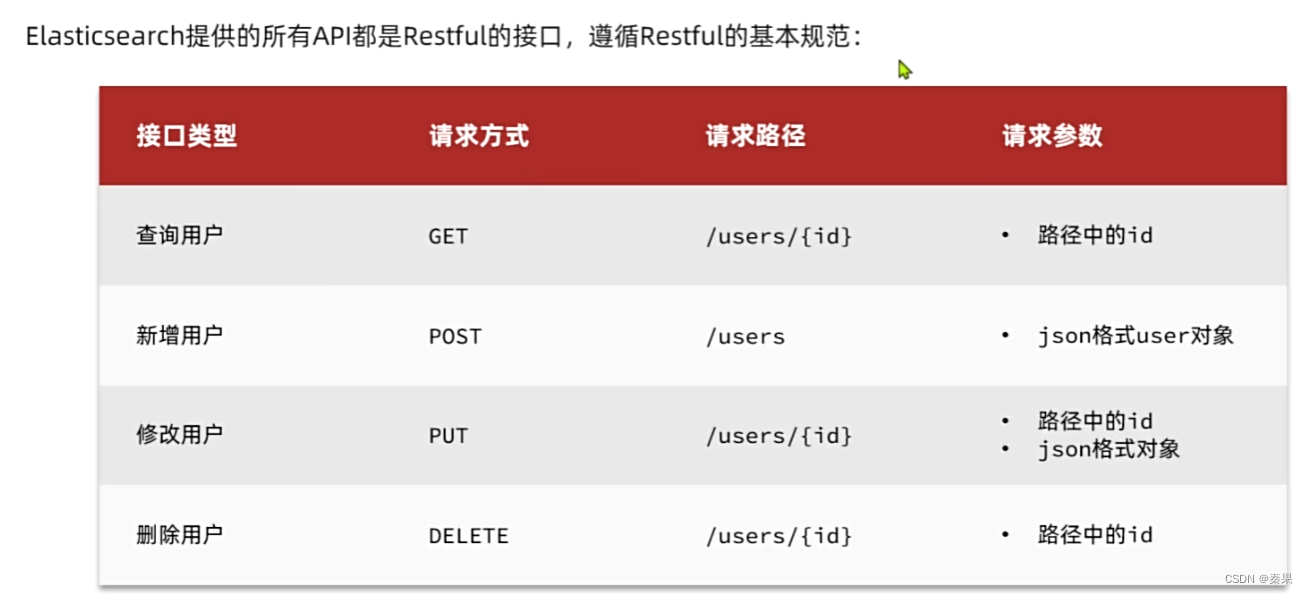


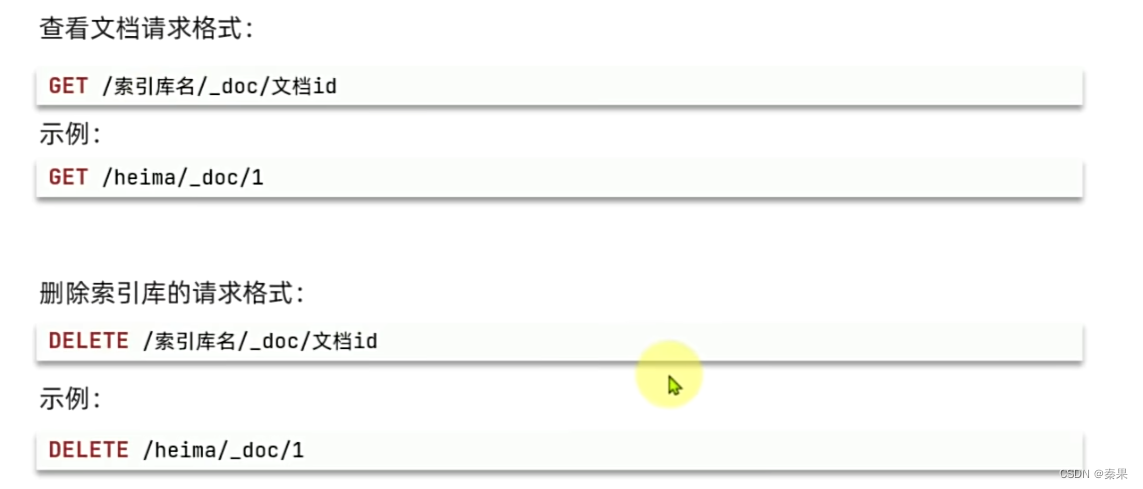
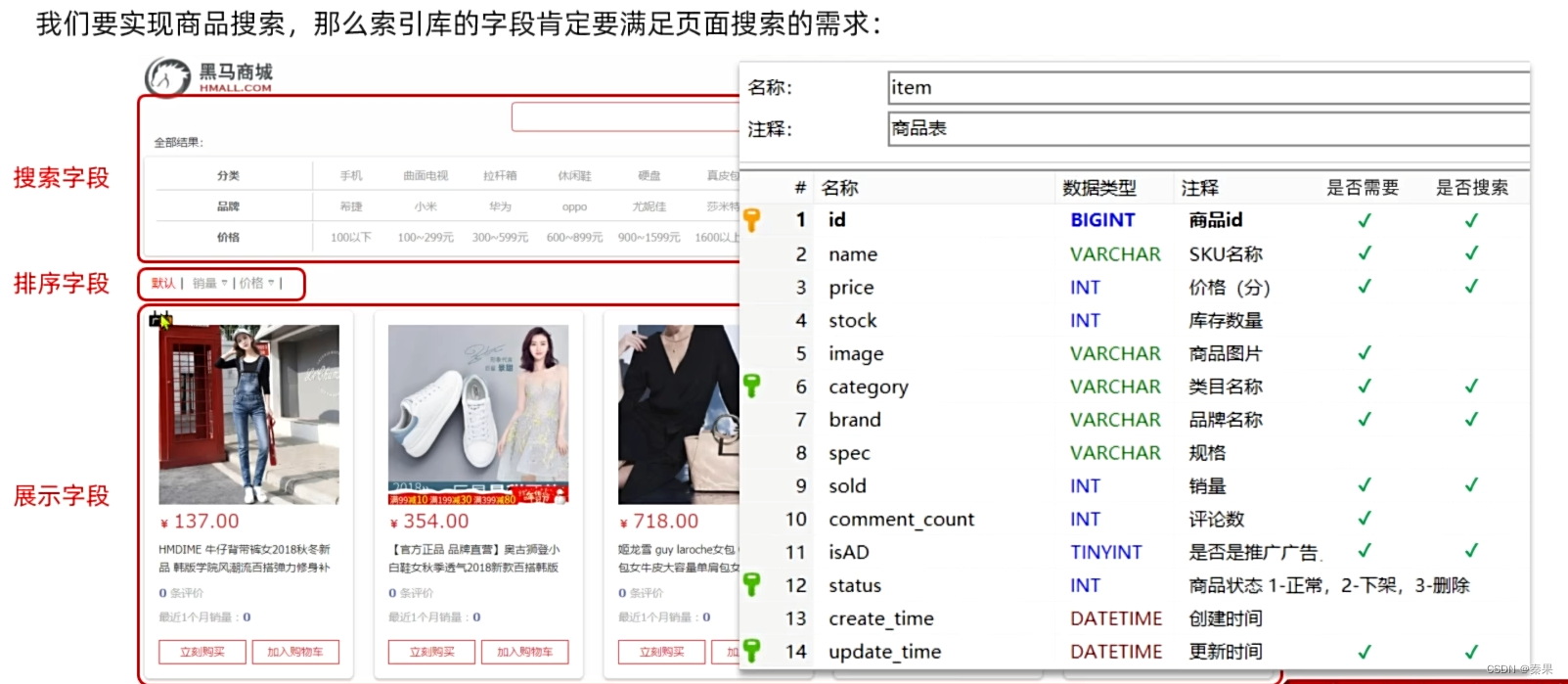
3.文档操作
①文档CRUD
新增:

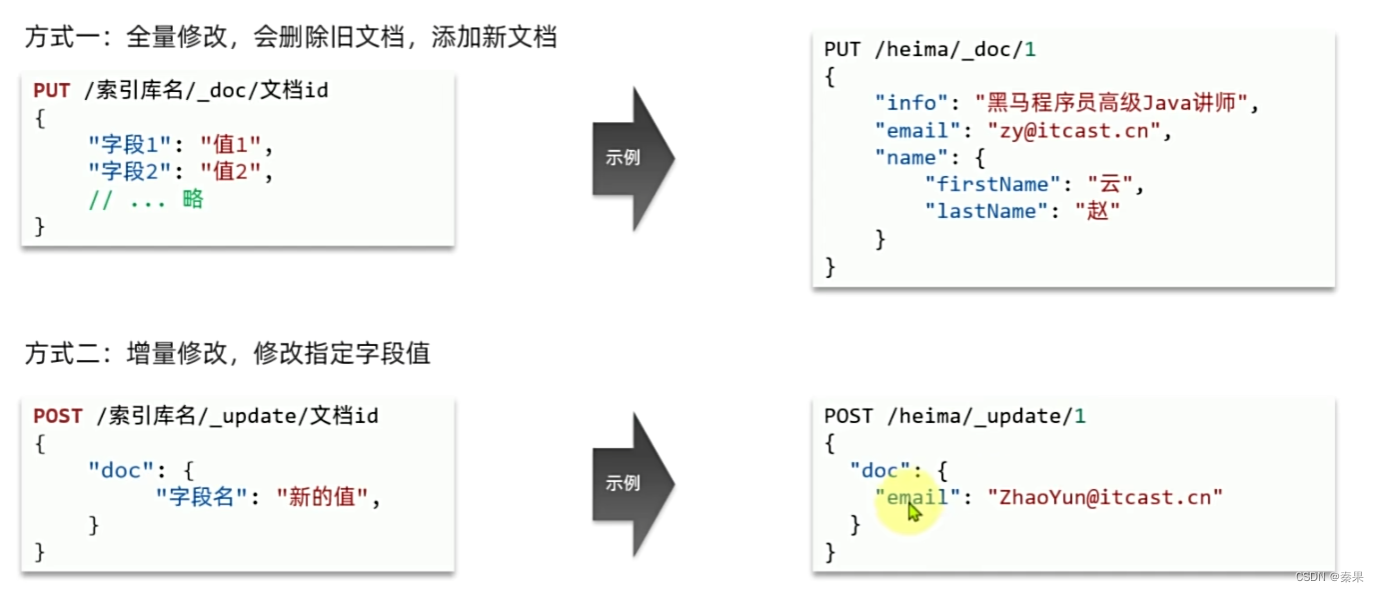
修改一种是使用PUT,如果存在id它会删除原来的再添加
如果需要只修改某些字段就采用POST
②批处理
这里可以一次进行多次增删改

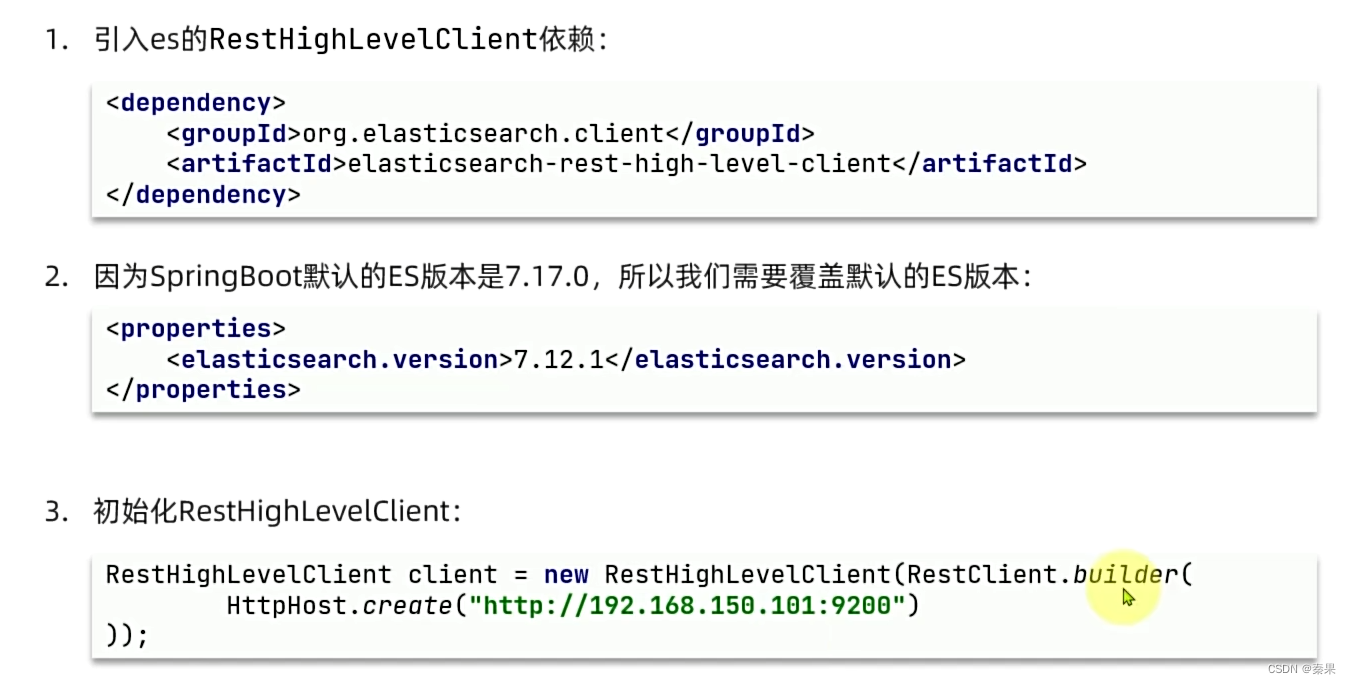
4.JavaRestClient
在java中向es发送请求
①客户端初始化
②商品Mapping映射
PUT /items
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "ik_max_word"
},
"price":{
"type": "integer"
},
"stock":{
"type": "integer"
},
"image":{
"type": "keyword",
"index": false
},
"category":{
"type": "keyword"
},
"brand":{
"type": "keyword"
},
"sold":{
"type": "integer"
},
"commentCount":{
"type": "integer",
"index": false
},
"isAD":{
"type": "boolean"
},
"updateTime":{
"type": "date"
}
}
}
}③索引库操作
其中MAPPING_TEMPLATE就是这个请求中的参数,请求参数放入“”中
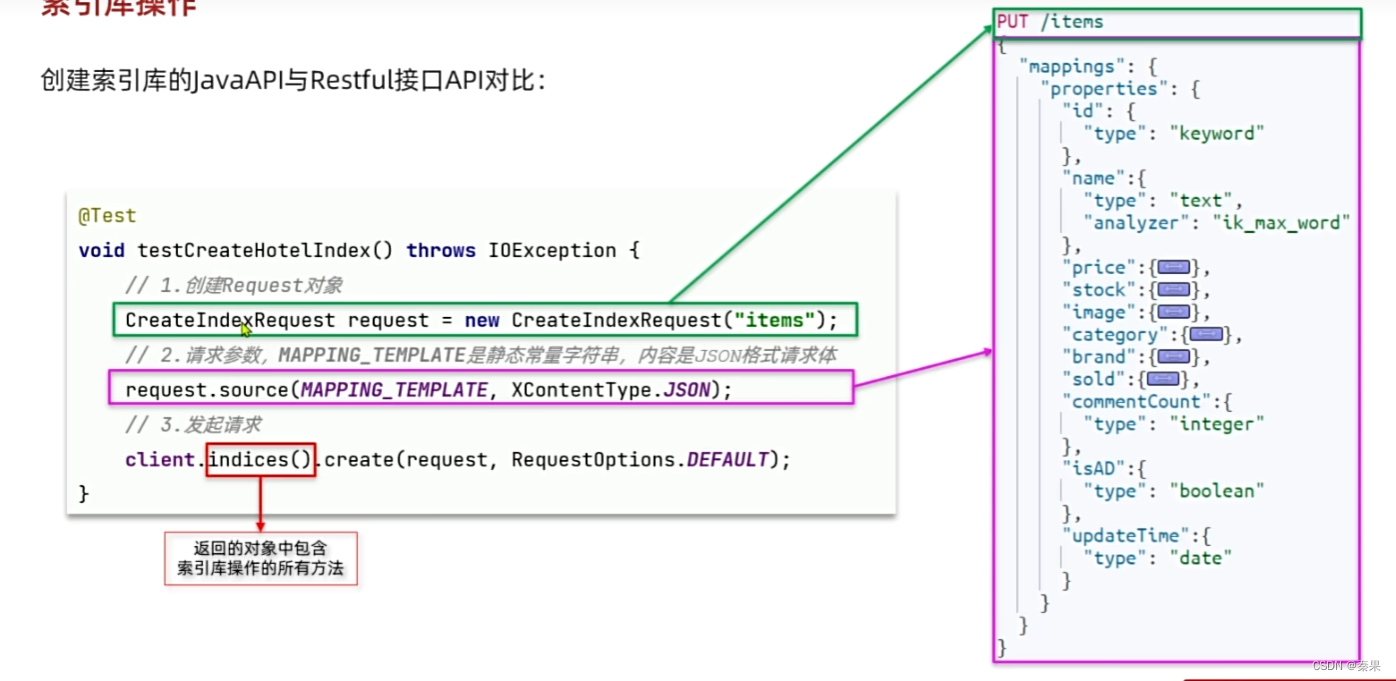
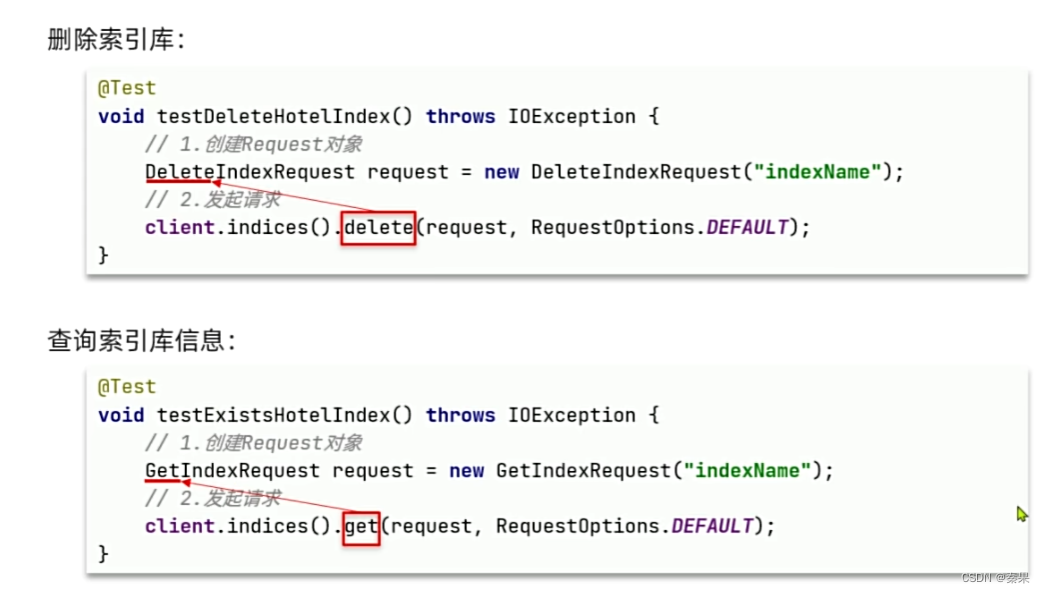
④文档操作
新增文档: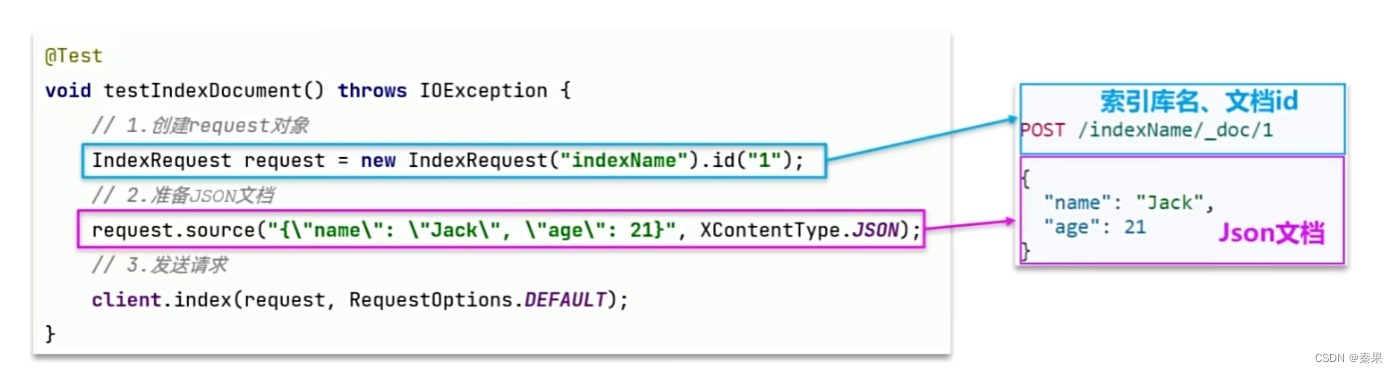
mysql中有商品数据,可以从中取出来放入es

删除文档:
查询文档

使用hutu工具包可以将json类容转化为对象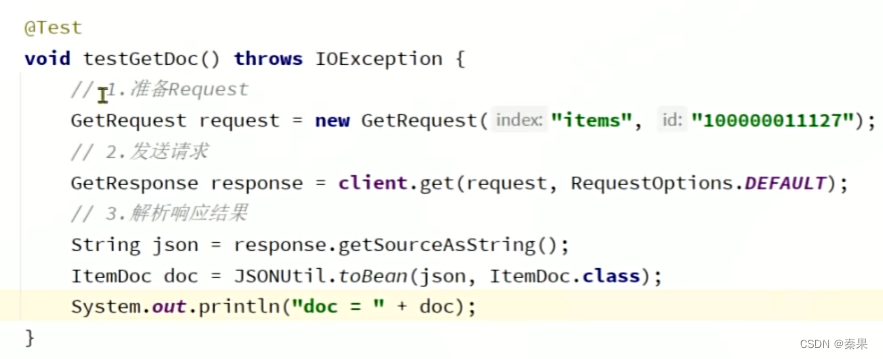
修改文档:
⑤批处理
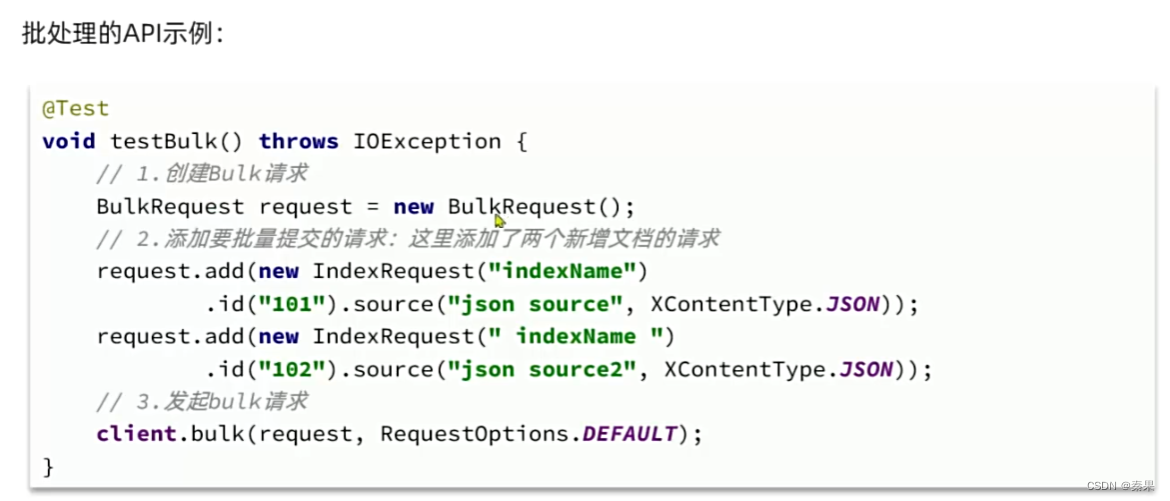
二、Elasticsearch查询
1.DSL查询

①快速入门
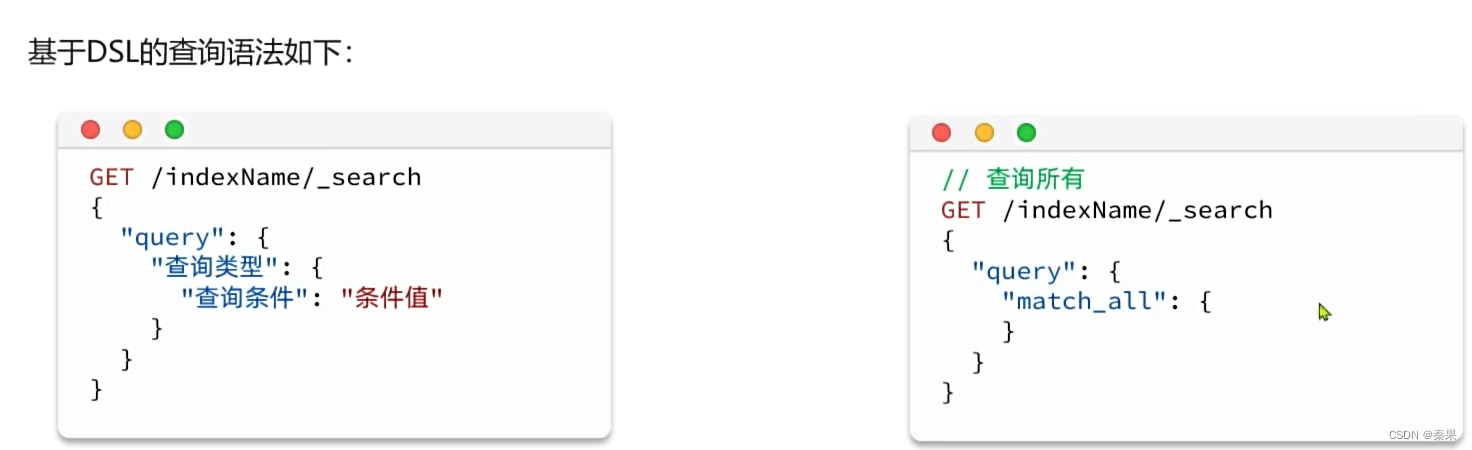

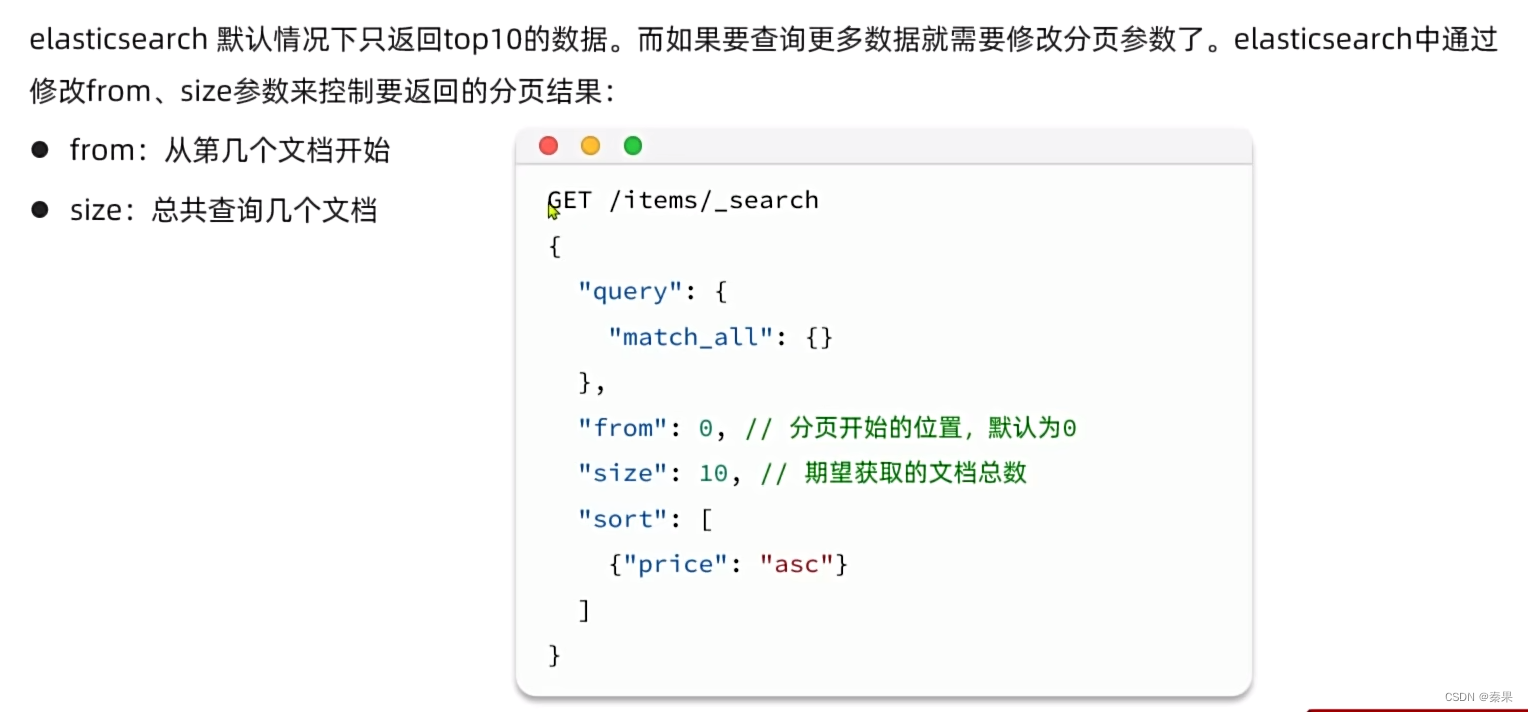
响应结果中并不会包含索引库中的所有文档,而是仅有10条。这是因为处于安全考虑,elasticsearch设置了默认的查询页数。
②叶子查询

全文检索就是之前提到的倒排索引
全文检索:

第二个意思是查询“FIELD1”,“FIELD2”中是否有TEXT的内容

全文检索会给结果进行打分,分越高就代表匹配度越高
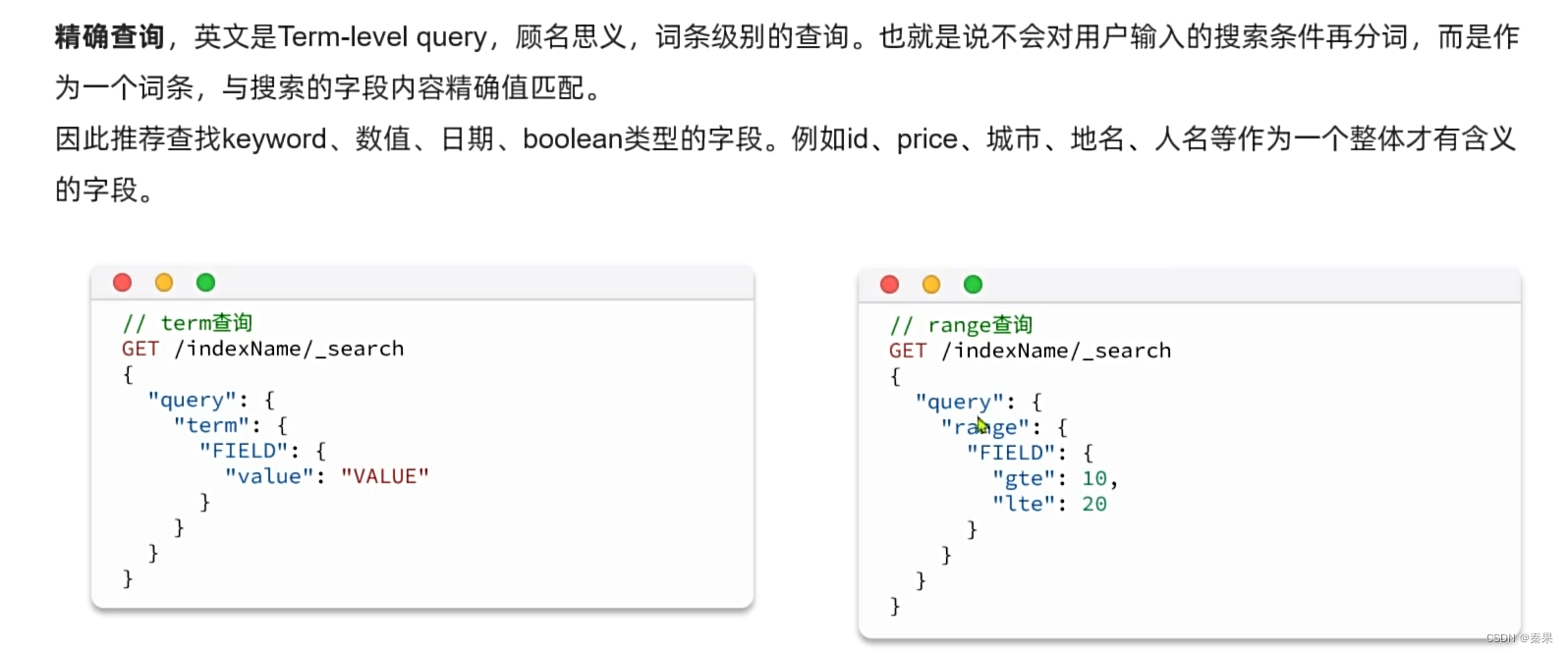
精确查询:
③复合查询


must和should参与算分,filter也是与但是不参与算分
![]()

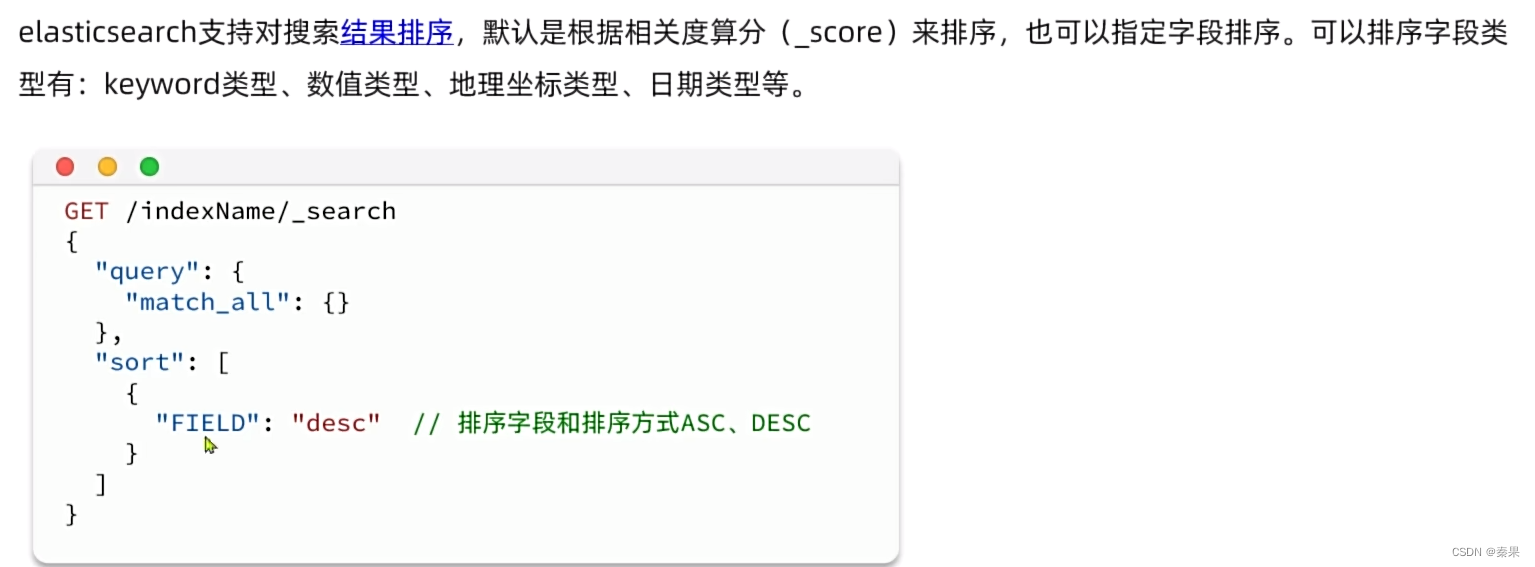
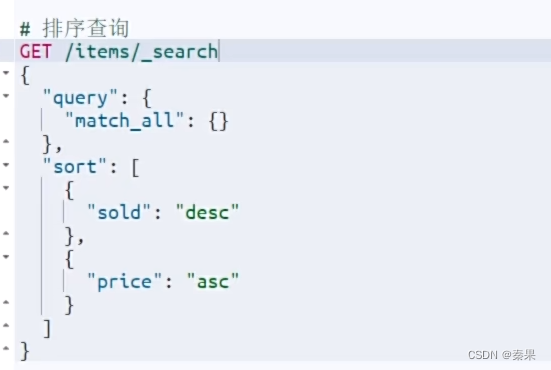
④排序和分页
排序
分页
深度分页

要找出前1000名就需要每一片的1000名拿出来进行排序得到全部的1000名。
但是这样就出现一个问题,搜索数据量越大,我要10000名就得每片都去排出前10000名

search after就是每一页排序后,拿到最后的排序值,第二页可以就根据这个排序值重新开始查找高于或低于这个排序值的目标,这样每一页都是重新开始查询,就不会出现深度查询
但是不适合随机翻页,原始查询就会设置页码上限避免深度分页
⑤高亮显示
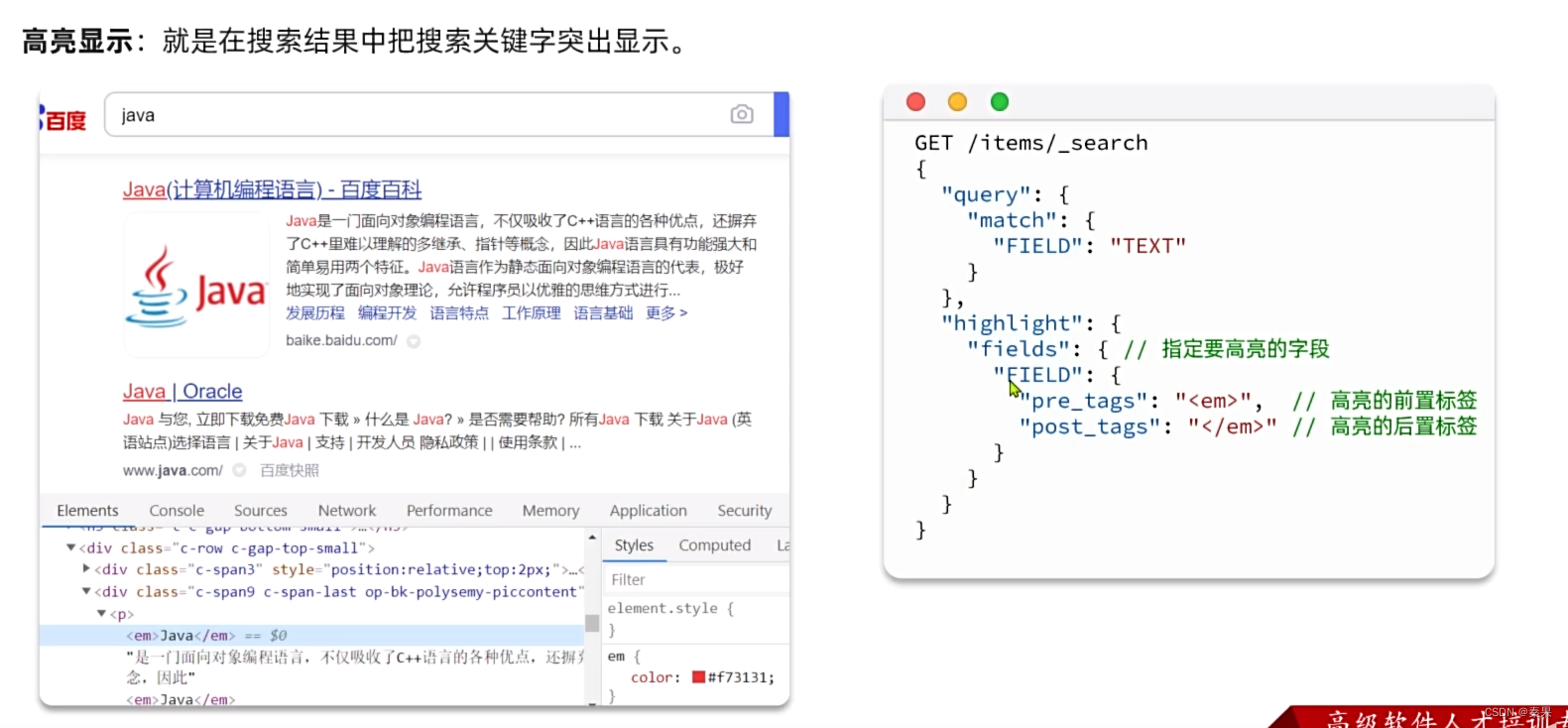
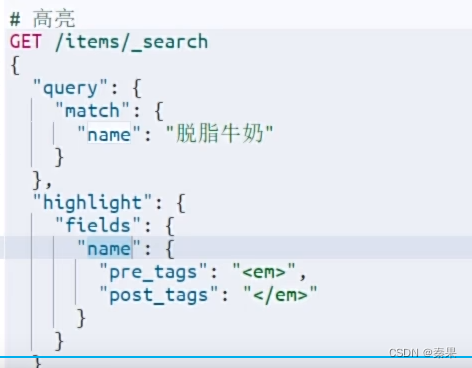
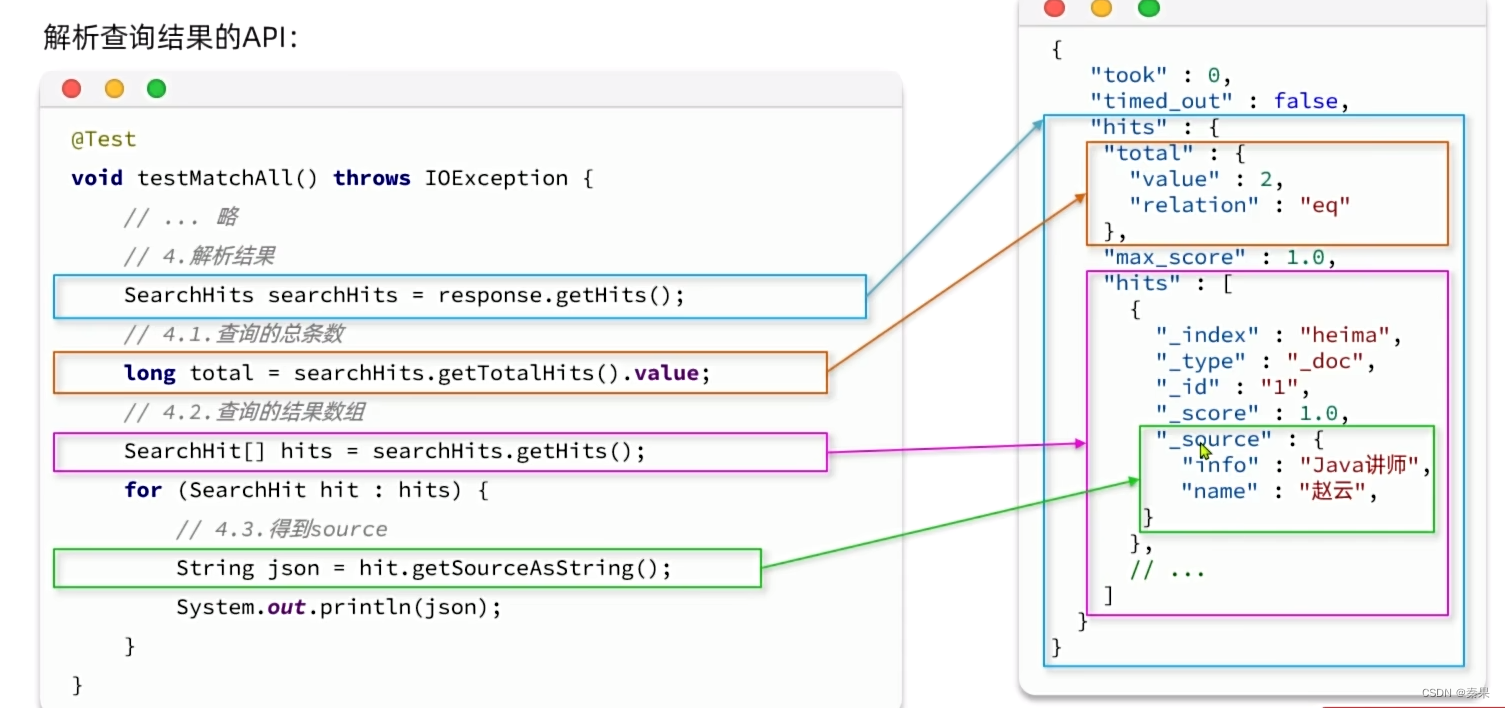
2.JavaRestClient
①快速入门
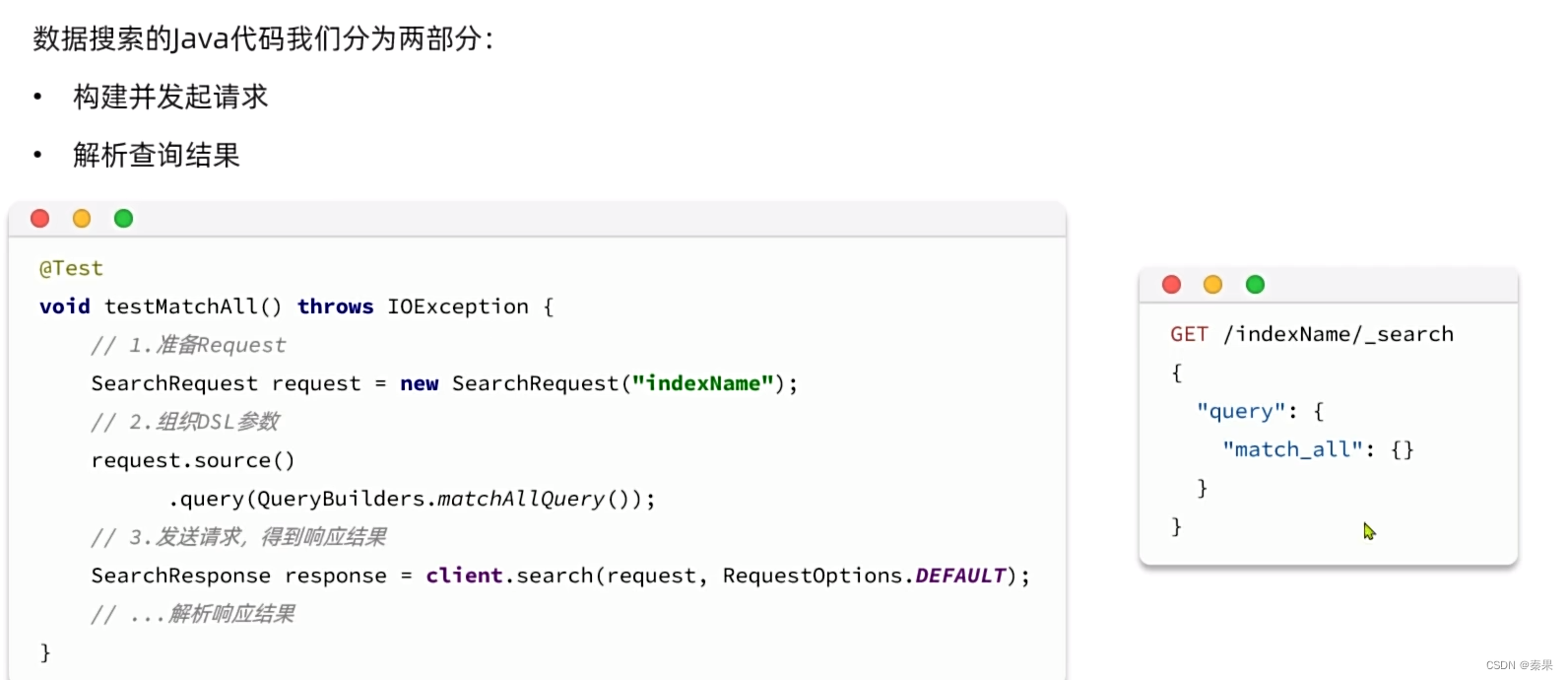
source中就是构建查询条件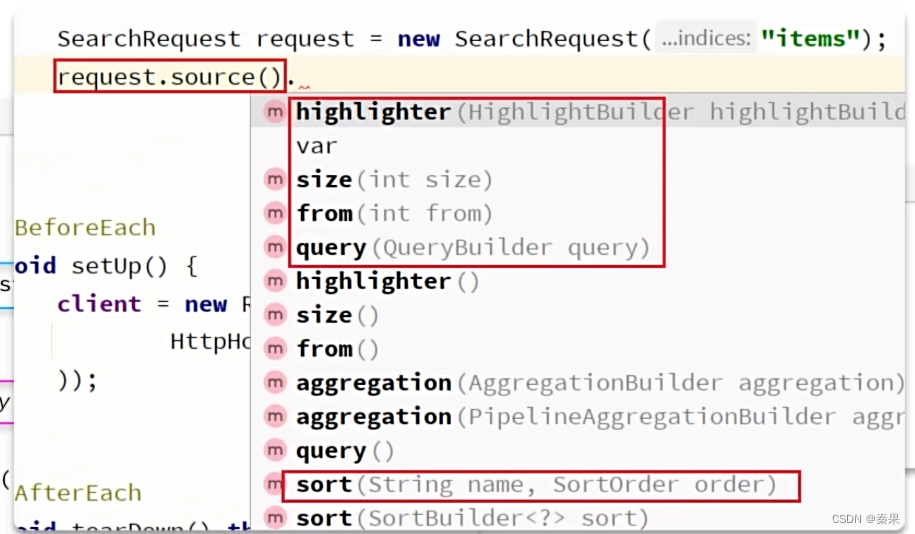
QueryBuilders包含了所有的查询细节
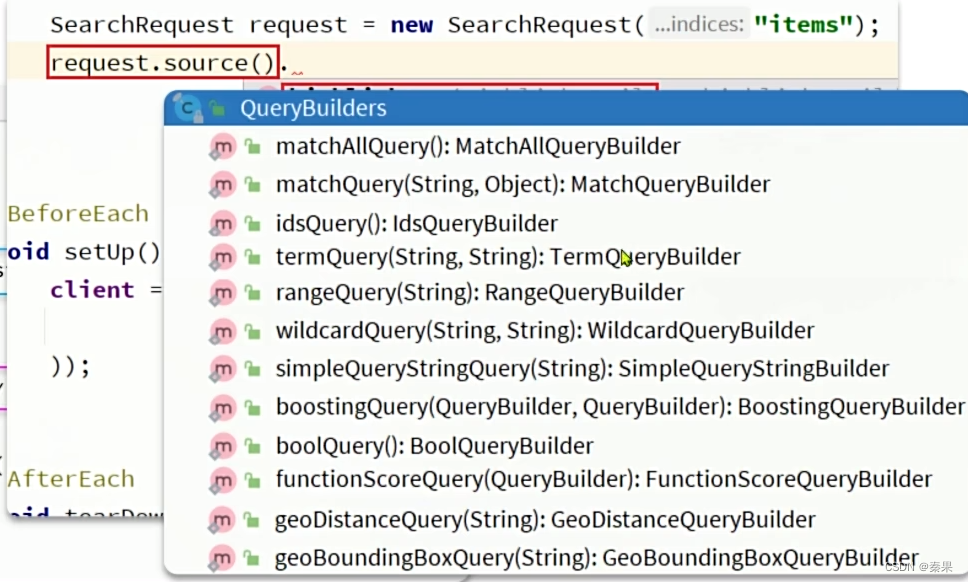
②构建查询条件
全文检索:
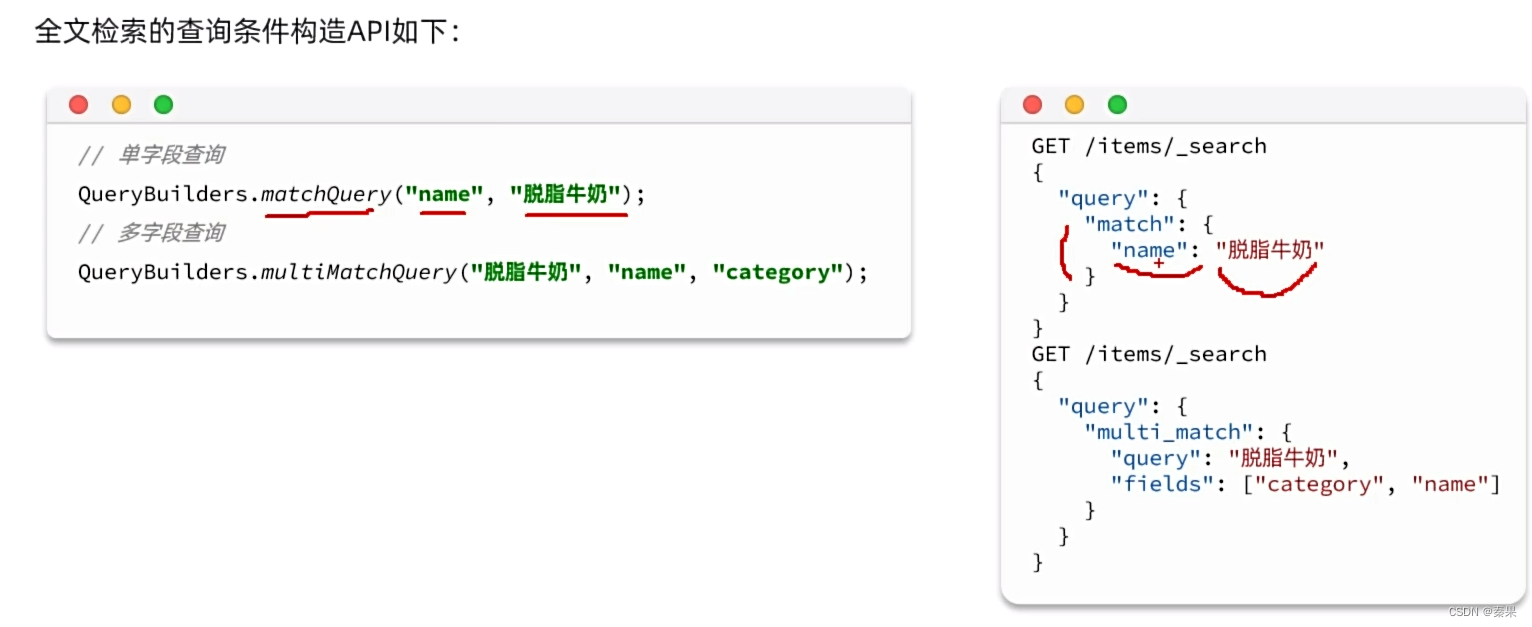
精确查询: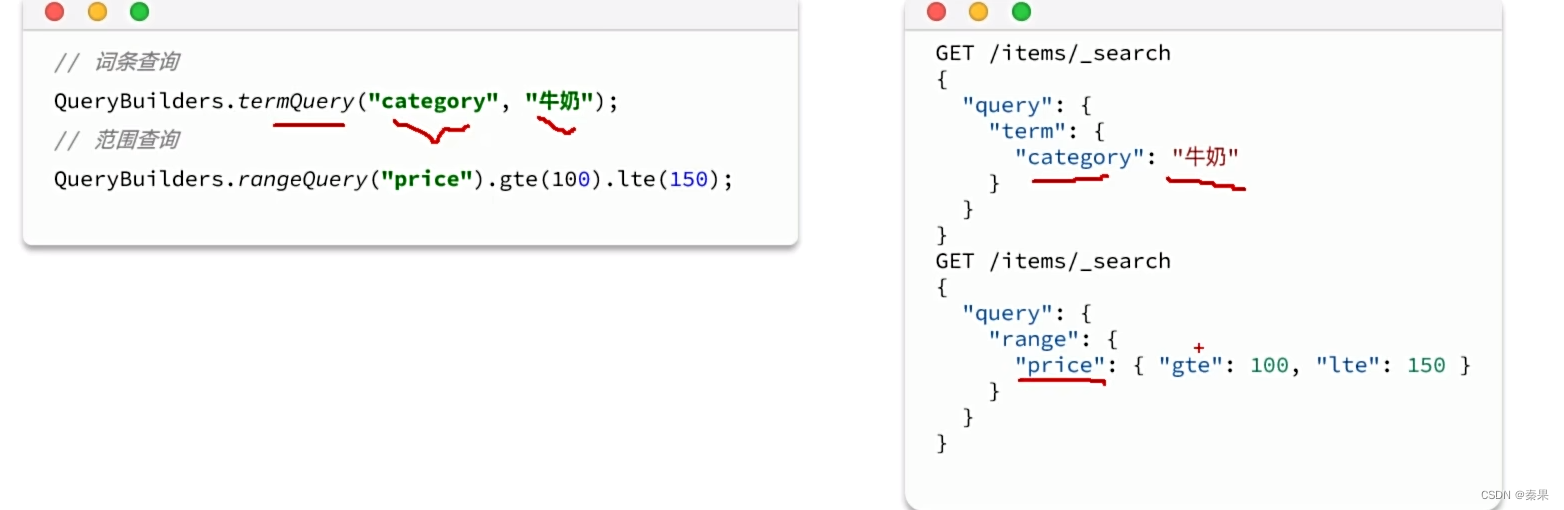
复合查询(bool):
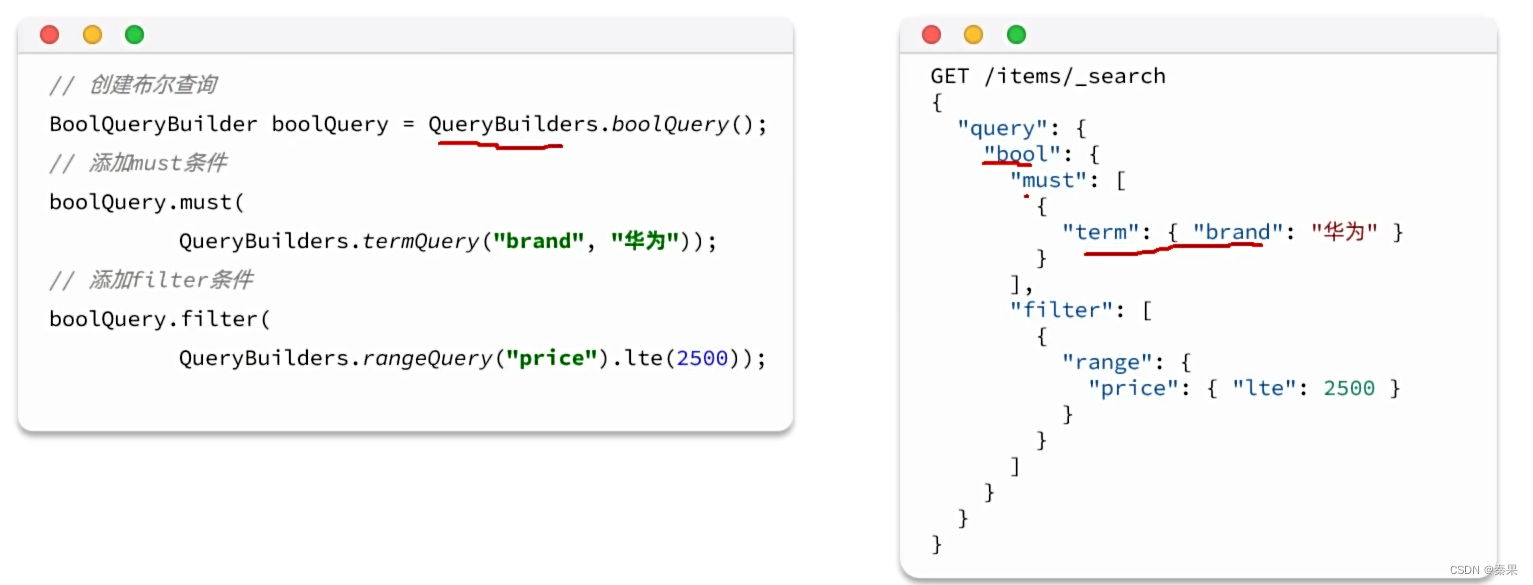


③排序和分页

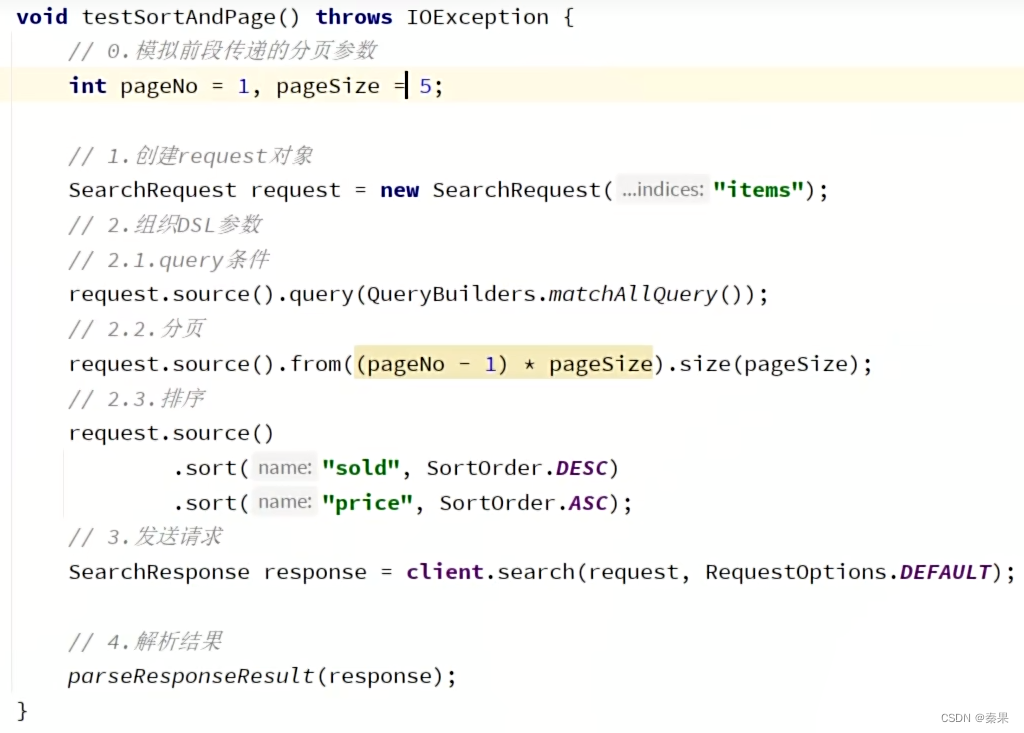
④高亮显示
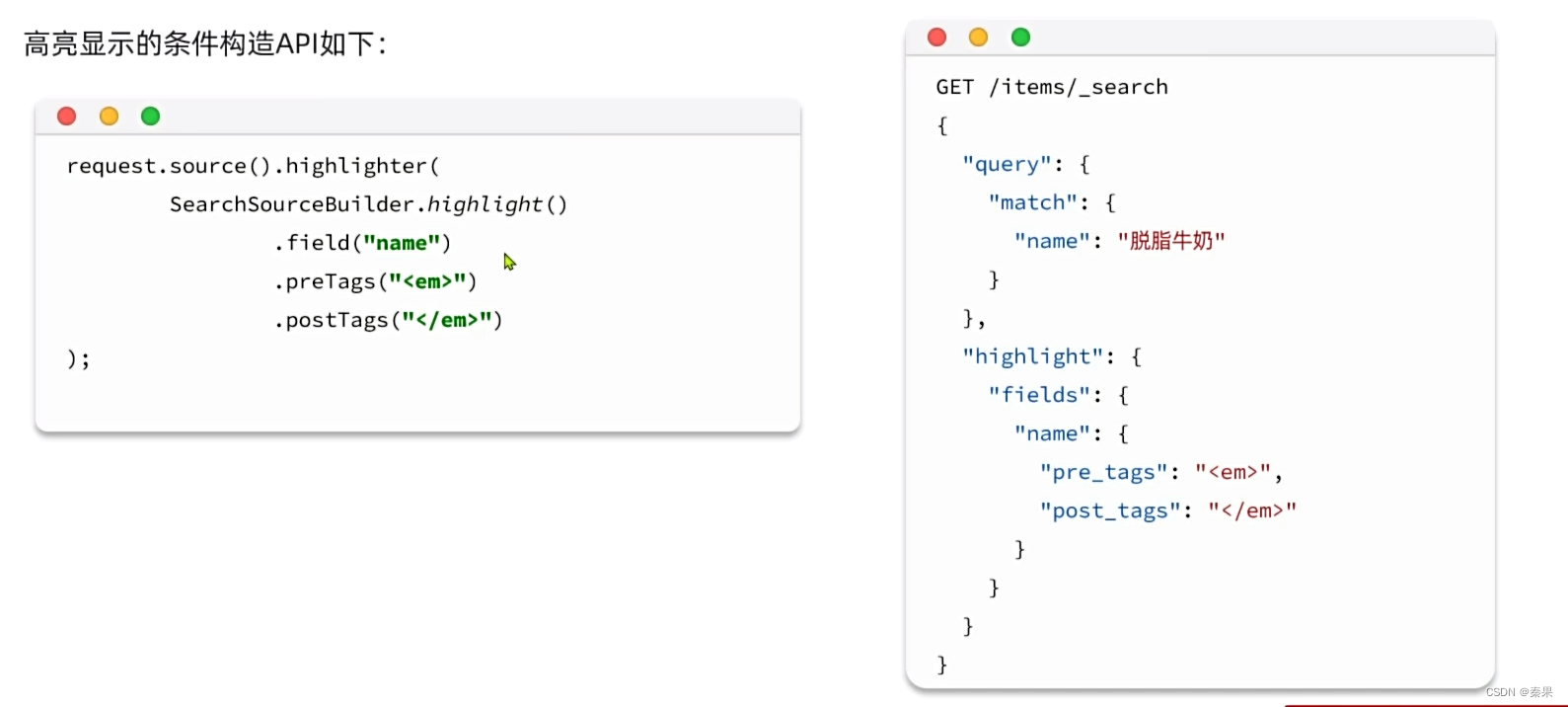
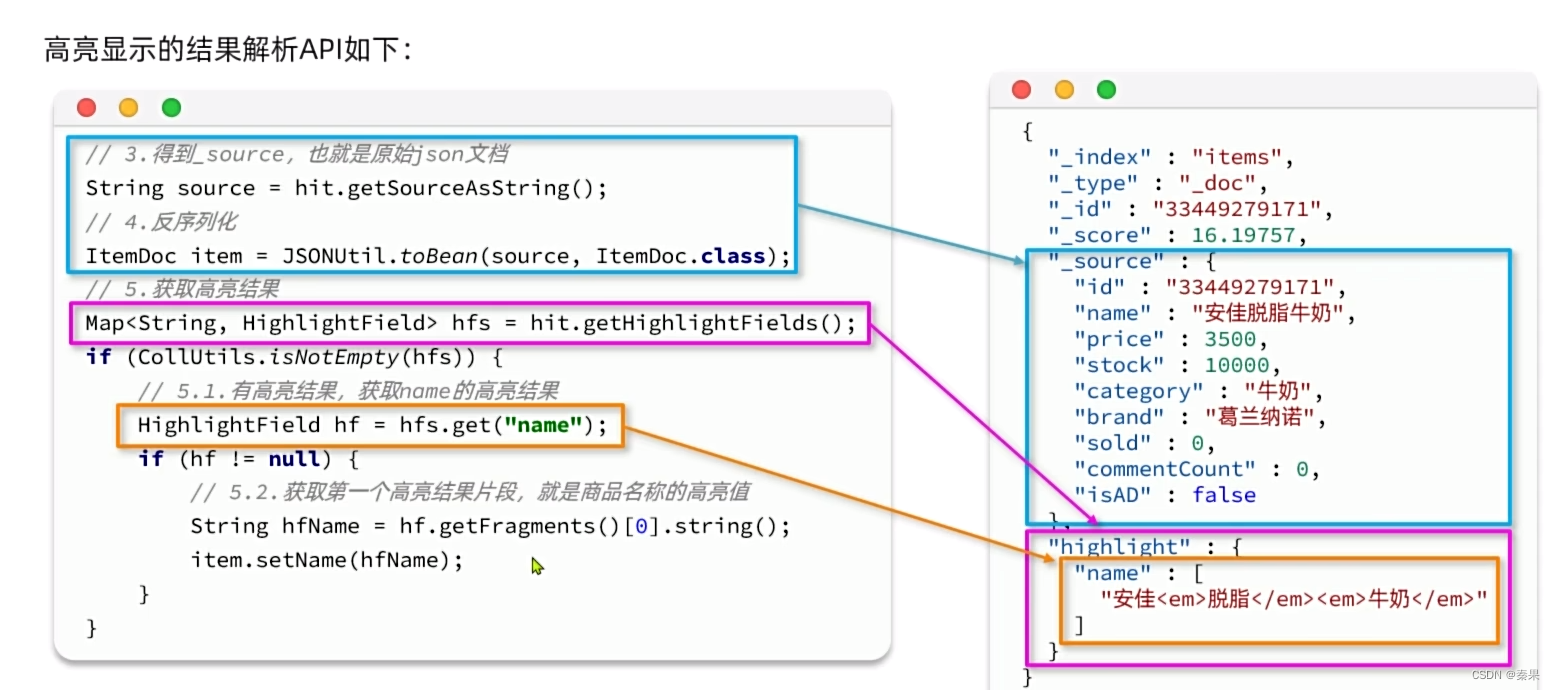
3.数据聚合

①DSL聚合
Bucket聚合

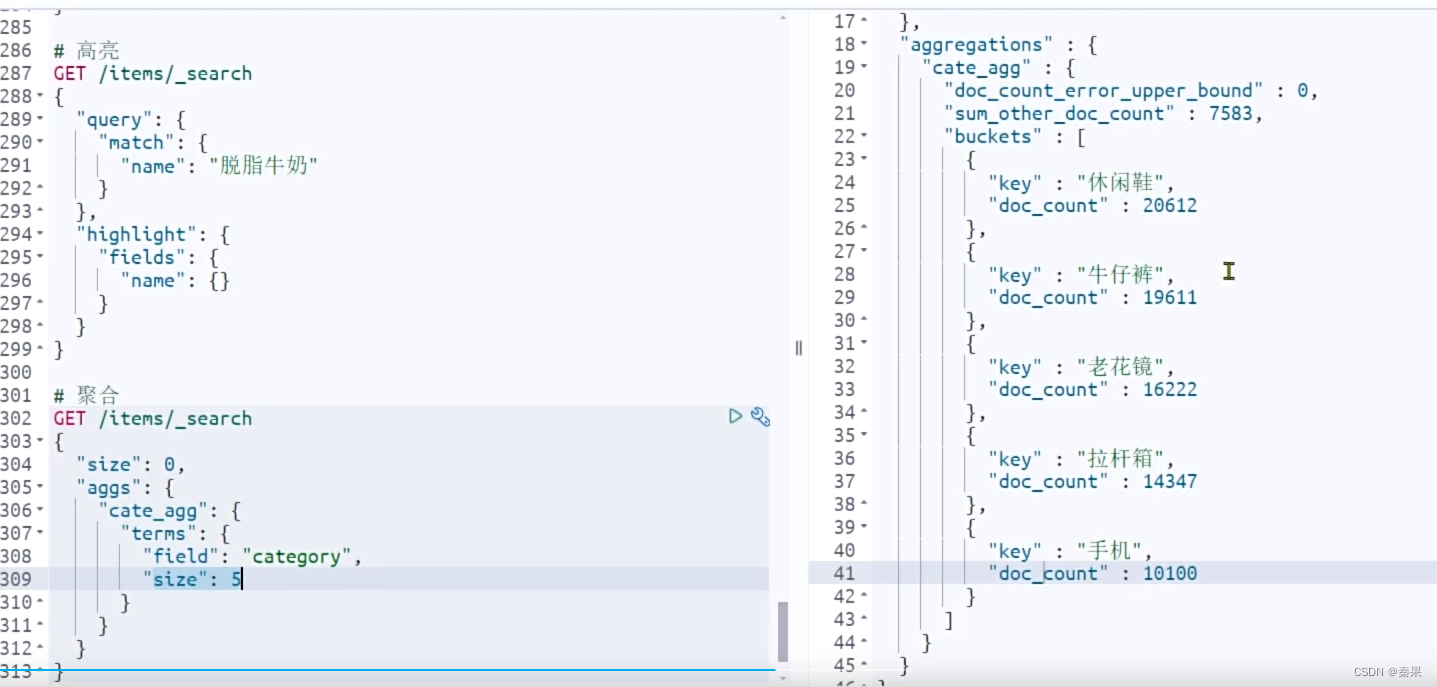
size会返回这个大小的目标,数量最多的才会显示

度量聚合

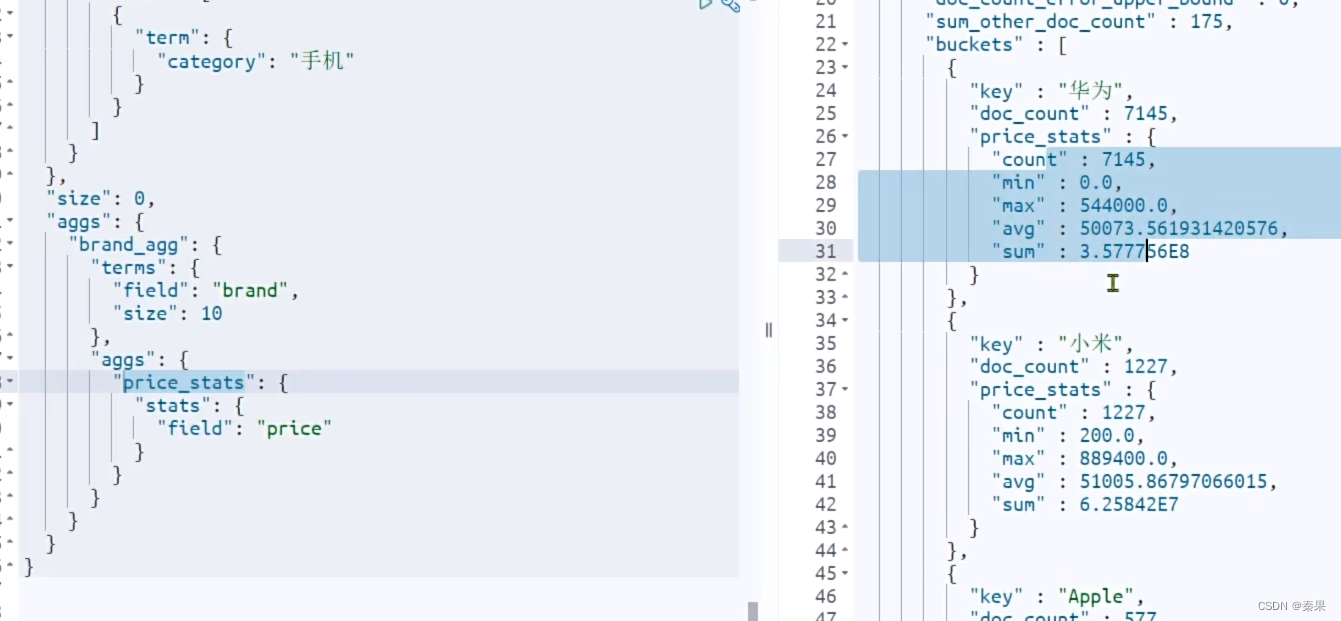
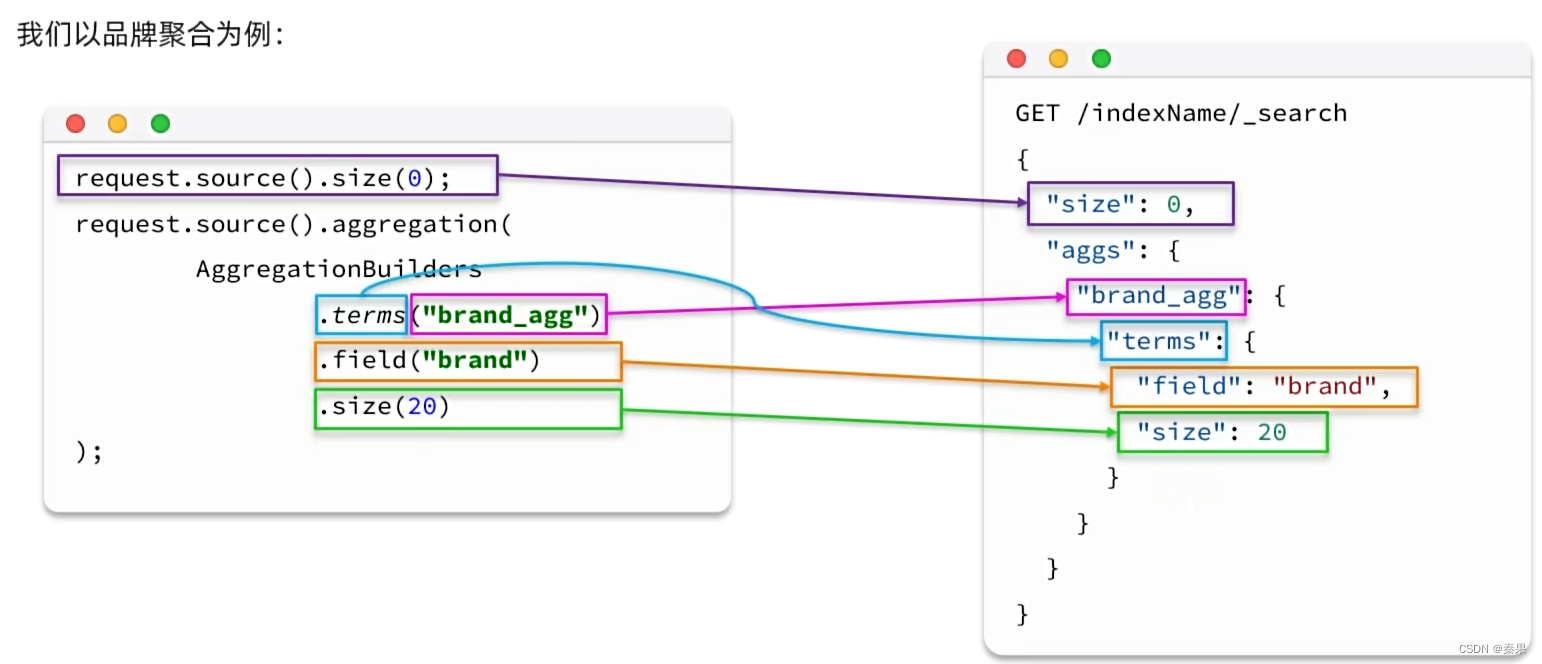
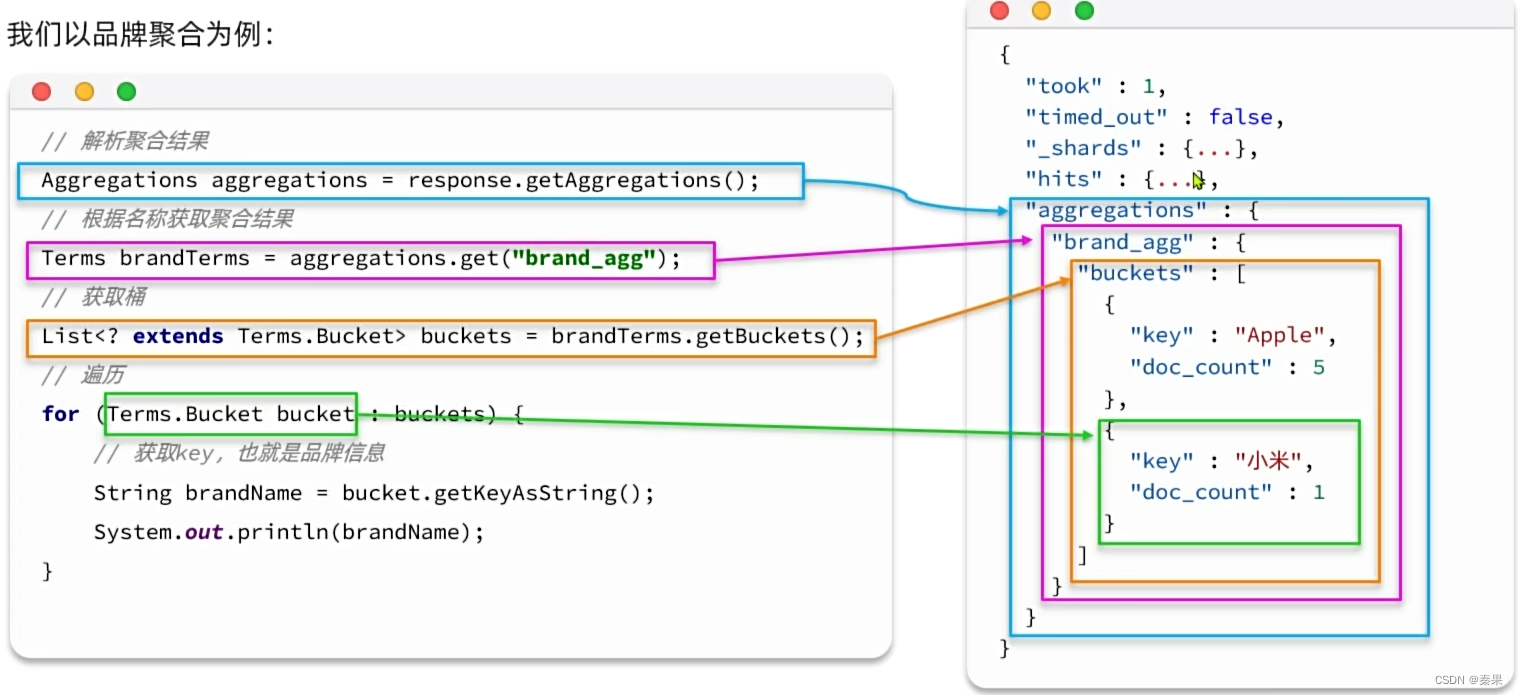
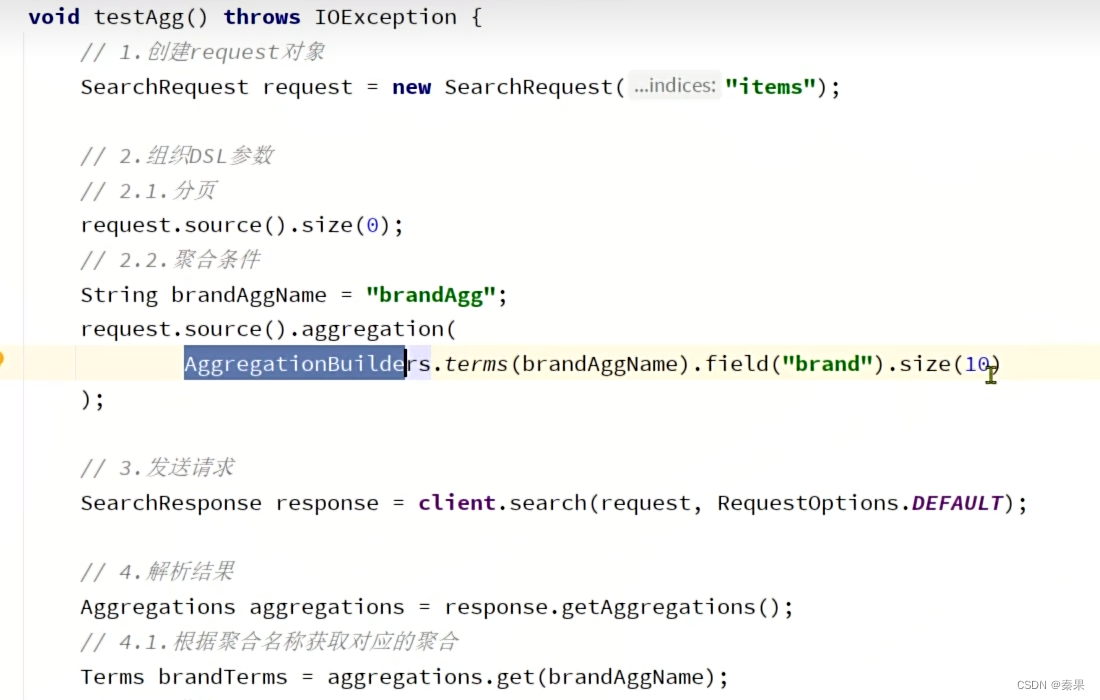
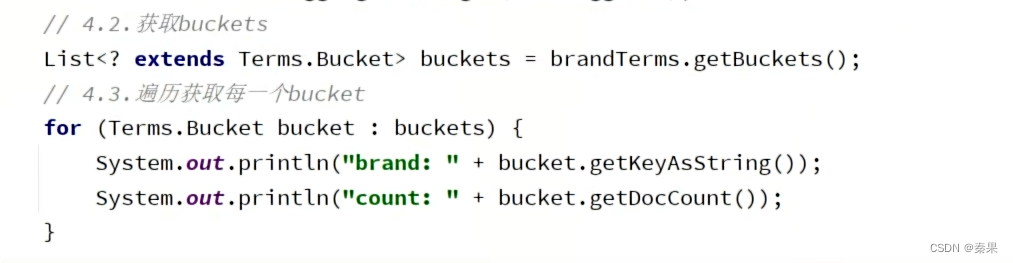
②RestClient聚合
聚合三要素:聚合类型,聚合名称,聚合字段
















 4668
4668











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











