







 本文探讨了电商行业的四个发展阶段,重点介绍了电商4.0的新零售模式,包括线上服务、线下体验和新物流。同时,详细讲述了黑马甄选公司的业务流程,项目背景,以及大数据处理平台的需求,涵盖了离线数仓架构、项目架构详解、人员规划和开发周期等内容。
本文探讨了电商行业的四个发展阶段,重点介绍了电商4.0的新零售模式,包括线上服务、线下体验和新物流。同时,详细讲述了黑马甄选公司的业务流程,项目背景,以及大数据处理平台的需求,涵盖了离线数仓架构、项目架构详解、人员规划和开发周期等内容。
1. 行业背景
1.1 电商发展历史
电商1.0: 初创阶段
20世纪90年代,电商行业刚刚兴起,主要以B2C模式为主,如亚马逊、eBay等
电商2.0: 发展阶段
21世纪初,电商行业进入了快速发展阶段,出现了淘宝、京东等大型电商平台,同时也出现了C2C模式和O2O模式
电商3.0: 成熟阶段
2010年代,电商行业进入了成熟阶段,各大电商平台开始加强自身的品牌建设和服务体系,同时也出现了跨境电商、社交电商、农村电商等新兴模式。
电商4.0: 新零售阶段
2016年以后,电商行业进入了电商阶段,以阿里巴巴、京东等为代表的电商巨头开始布局线下实体店,实现线上线下的无缝衔接,推动电商行业向更高层次发展。
1.2 什么是电商4.0
电商4.0其实就是新零售阶段, 主要由三部分组成: 线上服务、线下体验、新物流
线上服务:
线上服务指的是通过互联网平台提供的购物、支付、物流等服务
线下体验:
线下体验则是指在实体店铺中提供的商品展示、试穿试用、售后服务等体验
新物流:
新物流则是指通过物流技术和网络优化提高物流效率和服务质量
1.3 电商企业类型
-
1- 电商服务商
-
2- 货架、售货机
-
3- 无人便利店
-
4- 线上线下实体店
-
5- 生鲜、果蔬平台
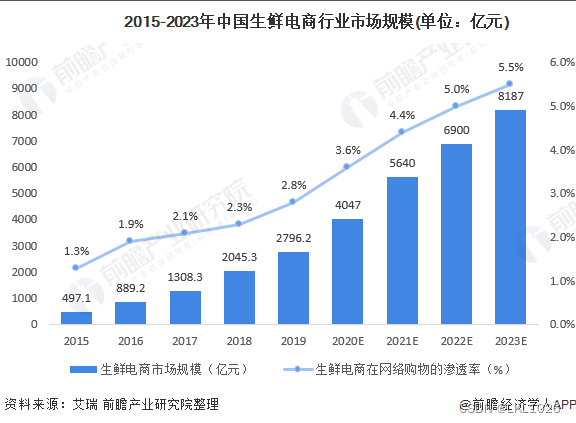
1.4 生鲜电商行业概述
生鲜产品具有高频刚需的特点, 是具有即时性需求, 目前在线下占比要远高于线上, 未来线上生鲜销售将会是庞大的市场

各大头部企业也可以着手布局生鲜市场
1.5 生鲜电商行业发展趋势
随着消费者网购生鲜习惯逐渐养成, 以及目前直播带货等多重作用下, 生鲜市场线上渗透率将不断提高
2. 项目业务流程与需求说明
2.1 公司介绍
黑马甄选与2016年7月成立, 发展至今经过6年时间, 门店遍布全国30多个城市, 超过1300家门店
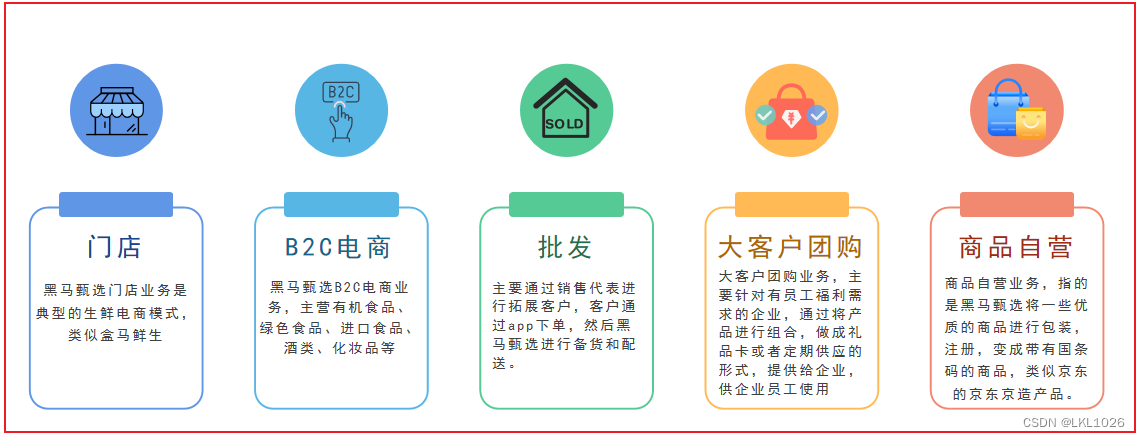
目前主营业务线有五条: ==门店 B2C电商 批发 大客户团购 商品自营==
2.2 业务介绍
2.3 项目背景
随着生鲜电商行业的迅速发展,公司累计了大量数据。为了从已有的数据中挖掘出有价值的信息,搭建了黑马甄选大数据处理平台。主要对各业务线的数据进行分析,从而便于精细化管理,最终提高用户数量及活跃度,提高商品销量,降低运营成本。
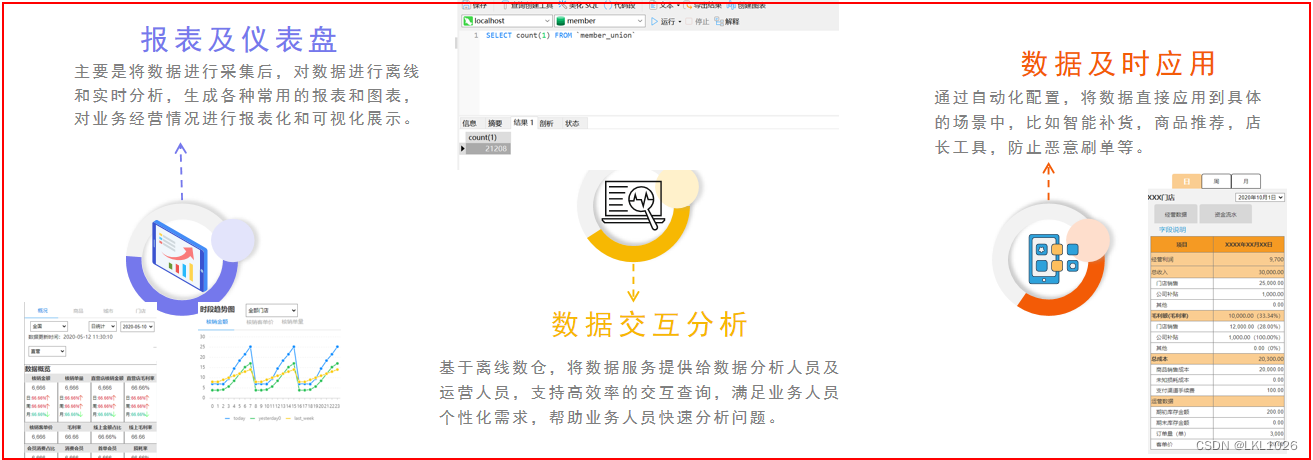
2.4 需求说明
==本次项目共计有四大需求: 销售需求 会员需求 供应链需求 商城需求==
-
销售需求:
划分为线上销售流程和线下销售流程,业务部门需要全面分析线上线下的销售情况,包括销售、取消、退款的金额、成本、单量、SKU以及活动的情况。
-
会员需求:
因为黑马甄选是生鲜电商业务,包括线上和线下,所以会员也分为线上会员和线下会员。 主要统计会员的注册、消费、充值、余额情况。注意线上会员也可以在线下消费,使用相同的手机号即可。
-
供应链需求
划为为要货到货流程与商品划拨流程 为精细化运营,业务部门严格管控供应链,要求计算:库存的数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3038
3038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









