







目录
信号量
前面所讨论的锁机制都有一个限制,那就是在锁获得期间不能调用调度器,即不能引起进程切换。但是内核中有很多函数都可能会触发对调度器的调用(在中断的章节列举过一些),这给驱动开发带来了一些麻烦。另外,我们也知道,对于忙等锁来说,当临界代码段执行的时间比较长的时候,会降低系统的效率。为此内核提供了一种叫信号量的机制来取消这一限制,它的数据类型定义如下。
struct semaphore{
raw_spinlock_t lock;
unsigned int count;
struct list_head wait_1ist;
}
可以看到,它有一个 count 成员,这是用来记录信号量资源的情况的,当 count 的值不为0时是可以获得信号量的,当 count 的值为0时信号量就不能被获取,这也说明信号量可以同时被多个进程所持有。我们还看到了一个 wait_list 成员,不难猜想,当信号量不能获取时,当前的进程就应该休眠了。最后,lock 成员在提示我们,信号量在底层其实使用了自旋锁的机制。信号量最常用的 API接口如下。
void sema_init(struct semaphore *sem,int val);
void down(struct semaphore *sem);
int down_interruptible(struct semaphore *sem);
int down_trylock(struct semaphore *sem);
int down_timeout (struct semaphore *sem, long jiffies);
void up(struct semaphore *sem);
sema_init:用于初始化信号量,val是赋给 count 成员的初值,这样就可以有 val个进程同时获得信号量。
down:获取信号量(信号量的值减 1),当信号量的值不为0时,可以立即获取信号量,否则进程休眠。
down_interruptible:同 down,但是能够被信号唤醒.
down_trylock:只是尝试获取信号量,如果不能获取立即返回,返回0表示成功获取返回 1表示获取失败。
down_timeout;同 down,但是在 jiffies 个时钟周期后如果还没有获取信号量,则超时返回,返回0表示成功获取信号量,返回负值表示超时。
up:释放信号量(信号量的值加 1),如果有进程等待信号量,则唤醒这些进程。为了能更好地理解信号量,我们不妨来看看 down 函数的实现代码,下面的代码略做了改写。
/*
* Copyright (c) 2008 Intel Corporation
* Author: Matthew Wilcox <willy@linux.intel.com>
*
* Distributed under the terms of the GNU GPL, version 2
*
* This file implements counting semaphores.
* A counting semaphore may be acquired 'n' times before sleeping.
* See mutex.c for single-acquisition sleeping locks which enforce
* rules which allow code to be debugged more easily.
*/
/*
* Some notes on the implementation:
*
* The spinlock controls access to the other members of the semaphore.
* down_trylock() and up() can be called from interrupt context, so we
* have to disable interrupts when taking the lock. It turns out various
* parts of the kernel expect to be able to use down() on a semaphore in
* interrupt context when they know it will succeed, so we have to use
* irqsave variants for down(), down_interruptible() and down_killable()
* too.
*
* The ->count variable represents how many more tasks can acquire this
* semaphore. If it's zero, there may be tasks waiting on the wait_list.
*/
#include <linux/compiler.h>
#include <linux/kernel.h>
#include <linux/export.h>
#include <linux/sched.h>
#include <linux/semaphore.h>
#include <linux/spinlock.h>
#include <linux/ftrace.h>
static noinline void __down(struct semaphore *sem);
static noinline int __down_interruptible(struct semaphore *sem);
static noinline int __down_killable(struct semaphore *sem);
static noinline int __down_timeout(struct semaphore *sem, long jiffies);
static noinline void __up(struct semaphore *sem);
/**
* down - acquire the semaphore
* @sem: the semaphore to be acquired
*
* Acquires the semaphore. If no more tasks are allowed to acquire the
* semaphore, calling this function will put the task to sleep until the
* semaphore is released.
*
* Use of this function is deprecated, please use down_interruptible() or
* down_killable() instead.
*/
void down(struct semaphore *sem)
{
unsigned long flags;
raw_spin_lock_irqsave(&sem->lock, flags);
if (likely(sem->count > 0))
sem->count--;
else
__down(sem);
raw_spin_unlock_irqrestore(&sem->lock, flags);
}
EXPORT_SYMBOL(down);
/**
* down_interruptible - acquire the semaphore unless interrupted
* @sem: the semaphore to be acquired
*
* Attempts to acquire the semaphore. If no more tasks are allowed to
* acquire the semaphore, calling this function will put the task to sleep.
* If the sleep is interrupted by a signal, this function will return -EINTR.
* If the semaphore is successfully acquired, this function returns 0.
*/
int down_interruptible(struct semaphore *sem)
{
unsigned long flags;
int result = 0;
raw_spin_lock_irqsave(&sem->lock, flags);
if (likely(sem->count > 0))
sem->count--;
else
result = __down_interruptible(sem);
raw_spin_unlock_irqrestore(&sem->lock, flags);
return result;
}
EXPORT_SYMBOL(down_interruptible);
/**
* down_killable - acquire the semaphore unless killed
* @sem: the semaphore to be acquired
*
* Attempts to acquire the semaphore. If no more tasks are allowed to
* acquire the semaphore, calling this function will put the task to sleep.
* If the sleep is interrupted by a fatal signal, this function will return
* -EINTR. If the semaphore is successfully acquired, this function returns
* 0.
*/
int down_killable(struct semaphore *sem)
{
unsigned long flags;
int result = 0;
raw_spin_lock_irqsave(&sem->lock, flags);
if (likely(sem->count > 0))
sem->count--;
else
result = __down_killable(sem);
raw_spin_unlock_irqrestore(&sem->lock, flags);
return result;
}
EXPORT_SYMBOL(down_killable);
/**
* down_trylock - try to acquire the semaphore, without waiting
* @sem: the semaphore to be acquired
*
* Try to acquire the semaphore atomically. Returns 0 if the semaphore has
* been acquired successfully or 1 if it it cannot be acquired.
*
* NOTE: This return value is inverted from both spin_trylock and
* mutex_trylock! Be careful about this when converting code.
*
* Unlike mutex_trylock, this function can be used from interrupt context,
* and the semaphore can be released by any task or interrupt.
*/
int down_trylock(struct semaphore *sem)
{
unsigned long flags;
int count;
raw_spin_lock_irqsave(&sem->lock, flags);
count = sem->count - 1;
if (likely(count >= 0))
sem->count = count;
raw_spin_unlock_irqrestore(&sem->lock, flags);
return (count < 0);
}
EXPORT_SYMBOL(down_trylock);
/**
* down_timeout - acquire the semaphore within a specified time
* @sem: the semaphore to be acquired
* @jiffies: how long to wait before failing
*
* Attempts to acquire the semaphore. If no more tasks are allowed to
* acquire the semaphore, calling this function will put the task to sleep.
* If the semaphore is not released within the specified number of jiffies,
* this function returns -ETIME. It returns 0 if the semaphore was acquired.
*/
int down_timeout(struct semaphore *sem, long jiffies)
{
unsigned long flags;
int result = 0;
raw_spin_lock_irqsave(&sem->lock, flags);
if (likely(sem->count > 0))
sem->count--;
else
result = __down_timeout(sem, jiffies);
raw_spin_unlock_irqrestore(&sem->lock, flags);
return result;
}
EXPORT_SYMBOL(down_timeout);
/**
* up - release the semaphore
* @sem: the semaphore to release
*
* Release the semaphore. Unlike mutexes, up() may be called from any
* context and even by tasks which have never called down().
*/
void up(struct semaphore *sem)
{
unsigned long flags;
raw_spin_lock_irqsave(&sem->lock, flags);
if (likely(list_empty(&sem->wait_list)))
sem->count++;
else
__up(sem);
raw_spin_unlock_irqrestore(&sem->lock, flags);
}
EXPORT_SYMBOL(up);
/* Functions for the contended case */
struct semaphore_waiter {
struct list_head list;
struct task_struct *task;
bool up;
};
/*
* Because this function is inlined, the 'state' parameter will be
* constant, and thus optimised away by the compiler. Likewise the
* 'timeout' parameter for the cases without timeouts.
*/
static inline int __sched __down_common(struct semaphore *sem, long state,
long timeout)
{
struct task_struct *task = current;
struct semaphore_waiter waiter;
list_add_tail(&waiter.list, &sem->wait_list);
waiter.task = task;
waiter.up = false;
for (;;) {
if (signal_pending_state(state, task))
goto interrupted;
if (unlikely(timeout <= 0))
goto timed_out;
__set_task_state(task, state);
raw_spin_unlock_irq(&sem->lock);
timeout = schedule_timeout(timeout);
raw_spin_lock_irq(&sem->lock);
if (waiter.up)
return 0;
}
timed_out:
list_del(&waiter.list);
return -ETIME;
interrupted:
list_del(&waiter.list);
return -EINTR;
}
static noinline void __sched __down(struct semaphore *sem)
{
__down_common(sem, TASK_UNINTERRUPTIBLE, MAX_SCHEDULE_TIMEOUT);
}
static noinline int __sched __down_interruptible(struct semaphore *sem)
{
return __down_common(sem, TASK_INTERRUPTIBLE, MAX_SCHEDULE_TIMEOUT);
}
static noinline int __sched __down_killable(struct semaphore *sem)
{
return __down_common(sem, TASK_KILLABLE, MAX_SCHEDULE_TIMEOUT);
}
static noinline int __sched __down_timeout(struct semaphore *sem, long jiffies)
{
return __down_common(sem, TASK_UNINTERRUPTIBLE, jiffies);
}
static noinline void __sched __up(struct semaphore *sem)
{
struct semaphore_waiter *waiter = list_first_entry(&sem->wait_list,
struct semaphore_waiter, list);
list_del(&waiter->list);
waiter->up = true;
wake_up_process(waiter->task);
}
代码第 57行首先获得了保护 count 成员的自旋锁,如果 count 的值大于0,则将cout的值自减 1,然后释放自旋锁立即返回。否则调用 __down, __down 又调用了__down_common,准备将进程的状态切换为TASK_UNINTERRUPTIBLE,表示不能被信号唤醒。代码第 210 行, __down_common 调用 list_add_tail 将进程放到信号量的等待链表中,然后在代码第 221 行调用调度器,进程主动放弃 CPU,调度其他进程执行。很显然,进程在不能获得信号量的情况下会休眠,不会忙等待,从而适用于临界代码段运行时间比较长的情况。
当给信号量赋初值 1 时,则表示在同一时刻只能有一个进程获得信号量,这种信号量叫二值信号量,利用这种信号量可以实现互斥,典型的应用代码如下。
/*定义信号量*/
struct semaphore sem;
/*初始化信号量,赋初值为1,用于互斥*/
sema_init(&sem,1);
/*获取信号量,如果是被信号唤醒,则返国-ERESTARTSYS*/
if (down_interruptible(&sem))
return -ERESTARTSYS;
/*对共享资源进行访问,执行一些耗时的操作或可能会引起进程调度的操作*/
Xxx;
/* 共享资源访问完成后,释放信号量*/
up(&sem);
对于信号量的特点及其他的一些使用注意事项总结如下。
(1)信号量可以被多个进程同时持有,当给信号量赋初值1时,信号量成为二值信号量,也称为互斥信号量,可以用来互斥。
(2)如果不能获得信号量,则进程休眠,调度其他的进程执行,不会进行忙等待。
(3)因为获取信号量可能会引起进程切换,所以不能用在中断上下文中,如果必须要用,只能使用 down_trylock。不过在中断上下文中可以使用 up 释信号量,从而唤配其他进程。
(4)持有信号量期间可以调用调度器,但需要特别注意是否会产生死锁。
(5)信号量的开销比较大,在不违背自旋锁的使用规则的情况下,应该优先使用自旋锁。
读写信号量
和相对于自旋锁的读写锁类似,也有相对于信号量的读写信号量,它和信号量的本质是一样的,只是将读和写分开了,从而能获取更好的并发性。读写信号量的结构类型是structrw_semaphore,针对它的主要操作如下。
init rwsem(sem)
void down_read(struct rw semaphore *sem);
int down read_trylock(struct rw semaphore *sem);
void down write(struct rw'semaphore *sem);
int down write trylock(struct rw semaphore *sem);
void up read(struct rw semaphore *sem);
void up write(struct rw semaphore *sem);
其使用方法和读写锁类似,在此不再细述。
互斥量
信号量除了不能用于中断上下文,还有一个缺点就是不是很智能。在获取信号量的代码中,只要信号量的值为0,进程马上就休眠了。但是更一般的情况是,在不会等待太长的时间后,信号量就可以马上获得,那么信号量的操作就要经历使进程先休眠再被唤醒的一个漫长过程。可以在信号量不能获取的时候,稍微耐心地等待一小段时间,如果在这段时间能够获取信号量,那么获取信号量的操作就可以立即返回,否则再将进程休眠也不迟。为了实现这种比较智能化的信号量,内核提供了另外一种专门用于互斥的高效率信号量,也就是互斥量,也叫互斥体,类型为
struct mutex,相关的API如下。
mutex init (mutex)
void mutox_lock(struct mutex *lock);
int mutex_Iock_interruptible(atruct mutex *lock);
int mutex_trylock(struct mutex *lock);
void mutex_unlock(struct mutex *Iock);
有了前而互斥操作的基础,使用互斥量来做互斥也就很容易实现了,示例代码如下
int i = 5;
/*定义互斥量*/
struct mutex lock;
/* 使用之前初始化互斥量 */
mutex_init (&block);
/* 访问共享资源之前获得互斥量 */
mutex_lock(&lock);
i++;
/*访问完共享资源后释放互斥量 */
mutex_unlock(&lock);
互斥量的使用比较简单,不过它还有一些更多的限制和特性,现将关键点总结如下:
(1)要在同一上下文对互斥量上锁和解锁,比如不能在读进程中上锁,也不能在进程中解锁。
(2)和自旋锁一样,互斥量的上锁是不能递归的。
(3)当持有互斥量时,不能退出进程。
(4)不能用于中断上下文,即使 mutex_trylock 也不行。
(5)持有互斥量期间,可以调用可能会引起进程切换的函数。
(6)在不违背自旋锁的使用规则时,应该优先使用自旋锁。
(7)在不能使用自旋锁但不违背互斥量的使用规则时,应该优先使用互斥量,而不是信号量。
RCU机制
RCU(Read-Copy Update)机制即读一复制一更新。RCU 机制对共享资源的访问都是通过指针来进行的,读者(对共享资源发起读访问操作的代码)通过对该指针进行解引用,来获取想要的数据。写者在发起写访问操作的时候,并不是去写以前的共享资内存,而是另起炉灶,重新分配一片内存空间,复制以前的数据到新开辟的内存空间(有时不用复制),然后修改新分配的内存空间里面的内容。当写结束后,等待所有的读者完成了对原有内存空间的读取后,将读的指针更新,指向新的内存空间,之后的读操将会得到更新后的数据。这非常适合于读访问多、写访问少的情况,它尽可能地减少对锁的使用。
内核使用 RCU 机制实现了对数组、链表和 NMI(不可屏中断)操作的大量 API,不过要能理解 RCU,通过下面几个最简单的 API 即可。
void rcu_read_lock(void);
rcu_dereference(p)
void rcu_read_unlock(void);
rcu_assign_pointer(p, v)
void synchronize_rcu(void);
rcu_read_lock:读者进入临界区。
rcu_dereference: 读者用于获取共享资源的内存区指针。
rcu_read_unlock: 读者退出临界区。
rcu_assign_pointer:用新指针更新老指针。
synchronize_rcu:等待之前的读者完成读操作
使用 RCU 机制最简单的示例代码如下。
struct foo {
int a;
char b;
long c;
};
DEFINE_SPINLOCK(foo_mutex);
struct foo *gbl_foo;
void foo_update_a(int new_a)
{
struct foo *new_fp;
struct foo *old_fp;
new_fp = kmalloc(sizeof(*new_fp),GFP_KERNEL);
spin_lock(&foo_mutex);
old_fp = gbl_foo;
*new_fp = *old_fp;
new_fp->a = new_a;
rcu_assign_pointer(gbl_foo, new_fp);
spin_unlock(&foo_mutex);
synchronize_rcu();
kfree(old_fp);
}
int foo_get_a(void)
{
int retval;
rcu_read_lock();
retval = rcu_dereference(gbl_foo)->a;
rcu_read_unlock();
return retval;
}
代码第1 行到第 5 行是共享资源的数据类型定义。代码第 6 行定义了一个用于写保护的自旋锁。代码第8 行定义了一个指向共享资源数据的全局指针。
代码第15行,写者分配了一片新的内存。代码第 17 行保存原来的指针,第18行进行数据复制,即将原来的内存中的数据复制到新的内存中。代码第 19行完成对新内存中数据的修改。代码第20行则用新的指针更新原来的指针。在这之后不能立即释放原来指针所指向的内存,因为可能还有读者在使用原来的指针访问共享资源的数据,所以在代码第22行等待使用原来指针的读者,当所有使用原来的指针的读者都读完数据后,代码第23 行释放原来的指针所指向的内存。在数据更新和指针更新时使用了自旋锁进行保护。
代码第 30 行是读者进入临界区,代码第 31 行使用 rcu_dereference 取共享资源的内存指针后进行解引用,获取相关的数据。访问完成后,代码第 32 行退出临界区。
虚拟串口驱动加入互斥
严格来说,前面讲解的虚拟串口驱动都是错误的,因为驱动中根本没有考虑并发能导致的竞态。但是程序运行又基本正确,这说明竞态出现的概率很小,但是不代表态就不会产生。驱动开发者应该对这个问题保持高度的警惕,因为竞态所造成的后果有时是非常严重的,并且错误的原因也是很难发现的。所以在驱动设计的初期就应该考虑这些因素的影响,并采取对应的措施。
为了方便说明问题,我们将之前的虚拟串口的运行机制稍加修改。首先,一个类似于串口的设备应该具有排他访问属性,即不能同时有多个进程都能打开串口并操作串口.在一段时间内,只允许一个进程操作串口,直到该进程关闭该串口为止,在这段时间内其他的进程都不能打开该串口,这也是实际的串口常规属性。其次,写给串口的数据不再环回,为简化问题,我们仅仅是把用户发来的数据简单地丢弃,认为数据是无等待地发送成功,那么写方向上也就不再需要等待队列。最后,串口接收中断还是通过网卡中断来产生,并将随机产生的接收数据放入接收 FIFO 中。
针对串口功能的重新定义,我们来考虑驱动中的并发问题。首先,应该安排一个变量来表示当前串口是否可用的状态,当有一个进程已经成功打开串口,那么这将阻止其他的进程再打开串口,很显然,这个反映状态的变量是一个共享资源,当多个进程同时打开这个串口设备时,可能会产生竞态,应该对该共享资源做互斥处理。其次,写入的数据是简单丢弃(复制到一个局部的缓冲区中,非共享资源),所以不考虑并发。但是,当接收中断产生时,在中断或中断下半部处理中需要将数据写入接收 FIFO,这就存在着针对接收 FIFO 的读一写并发,即用户进程读取接收 FIFO,同时在中断或中断的下半部写数据到接收 FIFO,共享资源就是这个全局的接收 FIFO,针对该共享资源应该提供互斥的访问。根据上面的分析,相应的驱动代码如下
#include <linux/init.h>
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/fs.h>
#include <linux/cdev.h>
#include <linux/kfifo.h>
#include <linux/ioctl.h>
#include <linux/uaccess.h>
#include <linux/wait.h>
#include <linux/sched.h>
#include <linux/poll.h>
#include <linux/aio.h>
#include <linux/interrupt.h>
#include <linux/random.h>
#include "vser.h"
#define VSER_MAJOR 256
#define VSER_MINOR 0
#define VSER_DEV_CNT 1
#define VSER_DEV_NAME "vser"
#define VSER_FIFO_SIZE 32
struct vser_dev {
wait_queue_head_t rwqh;
struct fasync_struct *fapp;
atomic_t available;
unsigned int baud;
struct option opt;
struct cdev cdev;
};
DEFINE_KFIFO(vsfifo, char, VSER_FIFO_SIZE);
static struct vser_dev vsdev;
static void vser_work(struct work_struct *work);
DECLARE_WORK(vswork, vser_work);
static int vser_fasync(int fd, struct file *filp, int on);
static int vser_open(struct inode *inode, struct file *filp)
{
if (atomic_dec_and_test(&vsdev.available))
return 0;
else {
atomic_inc(&vsdev.available);
return -EBUSY;
}
}
static int vser_release(struct inode *inode, struct file *filp)
{
vser_fasync(-1, filp, 0);
atomic_inc(&vsdev.available);
return 0;
}
static ssize_t vser_read(struct file *filp, char __user *buf, size_t count, loff_t *pos)
{
int ret;
int len;
char tbuf[VSER_FIFO_SIZE];
len = count > sizeof(tbuf) ? sizeof(tbuf) : count;
spin_lock(&vsdev.rwqh.lock);
if (kfifo_is_empty(&vsfifo)) {
if (filp->f_flags & O_NONBLOCK) {
spin_unlock(&vsdev.rwqh.lock);
return -EAGAIN;
}
if (wait_event_interruptible_locked(vsdev.rwqh, !kfifo_is_empty(&vsfifo))) {
spin_unlock(&vsdev.rwqh.lock);
return -ERESTARTSYS;
}
}
len = kfifo_out(&vsfifo, tbuf, len);
spin_unlock(&vsdev.rwqh.lock);
ret = copy_to_user(buf, tbuf, len);
return len - ret;
}
static ssize_t vser_write(struct file *filp, const char __user *buf, size_t count, loff_t *pos)
{
int ret;
int len;
char *tbuf[VSER_FIFO_SIZE];
len = count > sizeof(tbuf) ? sizeof(tbuf) : count;
ret = copy_from_user(tbuf, buf, len);
return len - ret;
}
static long vser_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
if (_IOC_TYPE(cmd) != VS_MAGIC)
return -ENOTTY;
switch (cmd) {
case VS_SET_BAUD:
vsdev.baud = arg;
break;
case VS_GET_BAUD:
arg = vsdev.baud;
break;
case VS_SET_FFMT:
if (copy_from_user(&vsdev.opt, (struct option __user *)arg, sizeof(struct option)))
return -EFAULT;
break;
case VS_GET_FFMT:
if (copy_to_user((struct option __user *)arg, &vsdev.opt, sizeof(struct option)))
return -EFAULT;
break;
default:
return -ENOTTY;
}
return 0;
}
static unsigned int vser_poll(struct file *filp, struct poll_table_struct *p)
{
int mask = POLLOUT | POLLWRNORM;
poll_wait(filp, &vsdev.rwqh, p);
spin_lock(&vsdev.rwqh.lock);
if (!kfifo_is_empty(&vsfifo))
mask |= POLLIN | POLLRDNORM;
spin_unlock(&vsdev.rwqh.lock);
return mask;
}
static ssize_t vser_aio_read(struct kiocb *iocb, const struct iovec *iov, unsigned long nr_segs, loff_t pos)
{
size_t read = 0;
unsigned long i;
ssize_t ret;
for (i = 0; i < nr_segs; i++) {
ret = vser_read(iocb->ki_filp, iov[i].iov_base, iov[i].iov_len, &pos);
if (ret < 0)
break;
read += ret;
}
return read ? read : -EFAULT;
}
static ssize_t vser_aio_write(struct kiocb *iocb, const struct iovec *iov, unsigned long nr_segs, loff_t pos)
{
size_t written = 0;
unsigned long i;
ssize_t ret;
for (i = 0; i < nr_segs; i++) {
ret = vser_write(iocb->ki_filp, iov[i].iov_base, iov[i].iov_len, &pos);
if (ret < 0)
break;
written += ret;
}
return written ? written : -EFAULT;
}
static int vser_fasync(int fd, struct file *filp, int on)
{
return fasync_helper(fd, filp, on, &vsdev.fapp);
}
static irqreturn_t vser_handler(int irq, void *dev_id)
{
schedule_work(&vswork);
return IRQ_HANDLED;
}
static void vser_work(struct work_struct *work)
{
char data;
get_random_bytes(&data, sizeof(data));
data %= 26;
data += 'A';
spin_lock(&vsdev.rwqh.lock);
if (!kfifo_is_full(&vsfifo))
if(!kfifo_in(&vsfifo, &data, sizeof(data)))
printk(KERN_ERR "vser: kfifo_in failure\n");
if (!kfifo_is_empty(&vsfifo)) {
spin_unlock(&vsdev.rwqh.lock);
wake_up_interruptible(&vsdev.rwqh);
kill_fasync(&vsdev.fapp, SIGIO, POLL_IN);
} else
spin_unlock(&vsdev.rwqh.lock);
}
static struct file_operations vser_ops = {
.owner = THIS_MODULE,
.open = vser_open,
.release = vser_release,
.read = vser_read,
.write = vser_write,
.unlocked_ioctl = vser_ioctl,
.poll = vser_poll,
.aio_read = vser_aio_read,
.aio_write = vser_aio_write,
.fasync = vser_fasync,
};
static int __init vser_init(void)
{
int ret;
dev_t dev;
dev = MKDEV(VSER_MAJOR, VSER_MINOR);
ret = register_chrdev_region(dev, VSER_DEV_CNT, VSER_DEV_NAME);
if (ret)
goto reg_err;
cdev_init(&vsdev.cdev, &vser_ops);
vsdev.cdev.owner = THIS_MODULE;
vsdev.baud = 115200;
vsdev.opt.datab = 8;
vsdev.opt.parity = 0;
vsdev.opt.stopb = 1;
ret = cdev_add(&vsdev.cdev, dev, VSER_DEV_CNT);
if (ret)
goto add_err;
init_waitqueue_head(&vsdev.rwqh);
ret = request_irq(167, vser_handler, IRQF_TRIGGER_HIGH | IRQF_SHARED, "vser", &vsdev);
if (ret)
goto irq_err;
atomic_set(&vsdev.available, 1);
return 0;
irq_err:
cdev_del(&vsdev.cdev);
add_err:
unregister_chrdev_region(dev, VSER_DEV_CNT);
reg_err:
return ret;
}
static void __exit vser_exit(void)
{
dev_t dev;
dev = MKDEV(VSER_MAJOR, VSER_MINOR);
free_irq(167, &vsdev);
cdev_del(&vsdev.cdev);
unregister_chrdev_region(dev, VSER_DEV_CNT);
}
module_init(vser_init);
module_exit(vser_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("name <e-mail>");
MODULE_DESCRIPTION("A simple character device driver");
MODULE_ALIAS("virtual-serial");
代码第 31 行添加了一个 available 原子变量成员,用于表示当前设备是否可用。代码第 248 行使用 atomic_set 将原子变量赋值为 1,表示可用。代码第 47 行使用atomic_dec_and_test 先将 available 的值减 1,然后判断减1后的结果是否为0。如果结果是0,函数返回真,表示设备是首次被打开,所以代码第 48 行返回 0,表示打开成功。atomic_dec_and_test 将减和测试结果按原子操作,即不会被打断,所以即便有另外一个进程想打开串口,二者也只能有一个竞争成功。代码第 50 行表示竞争失败的进程应该将available 的值加回来,否则以后串口将永远无法打开。代码第 58 行表示竞争成功的进程在使用完串口后,将 available 的值加回来,使串口又可用。
代码第 62 行至第 87 行是用户读操作的驱动实现,代码第 68 行首先修正了读取的字节数,然后第 69 行使用了读等待队列头中自带的自旋锁,进行加锁操作,因为之后都要对共享的接收 FIFO 进行操作(包括判空)。代码第 72 行,如果接收 FIFO为空,并且是非阻塞操作,那么应该释放自旋锁,然后返回-EAGAIN,如果不释放自旋锁将会导致重复获取自旋锁的错误,这是比较容易遗忘的内容,应该注意。如果接收 FIFO 为空,并且是阻塞操作,那么调用 wait_event_interruptible_locked 来使进程休眠,当接收 FIFO不为空时,进程被唤醒。之前我们说过,在自旋锁获得期间,不能调用可能会引起进程切换的函数,但是这里用的是 wait_event_interruptible_locked,在进程休眠前,会自动释放自旋锁,醒来后将重新获得自旋锁,这就非常巧妙地对接收 FIFO 的判空实现原子化操作,从而避免了竞态。代码第 77 行是进程被信号唤醒应该释放自旋锁,也容易被遗忘,需要注意。代码第 82 行将 FIFO中的数据读出放入一个临时的缓冲区中,然后释放自旋锁。这里没有使用 kfifo_to_user,是因为该函数可能会导致进程切换,在自旋锁持有期间不能被调用。所以直到代码第 85行才使用 copy_to_user 将读取到的数据复制到用户空间。代码第 135行至第 138 行是对 FIFO的判空操作做,避免在此期间产生的竞态代码第 187行至第 206行是中断下半部的工作队列实现,同样也是在操作接收 FIFO的整个过程中,通过自旋锁来保护。代码第 201 行在接收 FIFO 访问完成后立即释放了自旋锁,尽量避免长时间持有自旋锁。
我们来讨论一下上面的并发情况,如果在用户读期间下半部开始执行了,那么下半部会因为不能获取自旋锁而忙等待,直到 wait_event_inierruptible_locked 被调用,在真正的进程切换之前,释放了自旋锁。下半部将会立即获得自旋锁,从而完成对接收FIFO的完整操作,操作完成后,释放自旋锁并唤醒读进程,读进程醒来后马上获取自旋锁,确定接收 FIFO不为空的情况下,在自锁持有的过程中将接收 FIFO 的数据读出,即便这时中断下半部又执行,也会因为不能获得自旋锁而忙等待,所以竞态不会产生。读取了接收FIFO中的数据后,再释放自旋锁,之后将数据复制到用户空间,因为不涉及接收FIFO 共享资源的操作,所以不需要持有自旋锁。其他可能的情况请大家自行分析。
下面是用于测试的命令。
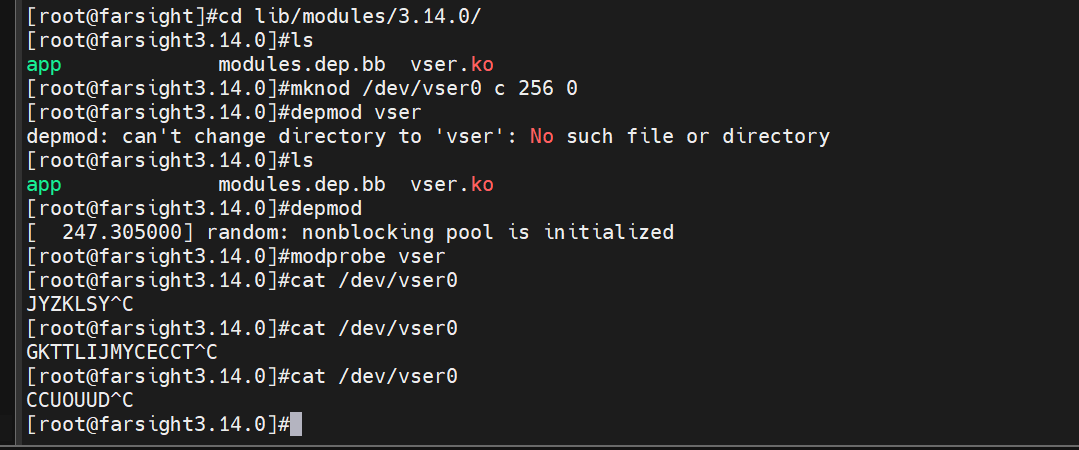
接下来我们来归纳一下在驱动中如何解决竞态的问题。
(1)找出驱动中的共享资源,比如 available 和接收 FIFO。
(2)考虑在驱动中的什么地方有并发的可能、是何种并发,以及由此引起的竞态比如例子中的 vser_open、vser_release、 vser_read、vser_poll 和 vser_work。其中,vser_open,vser_release 在打开和关闭设备的时候可能会产生竞态,而其他的则发生在对接收 FIFO的访问上。
(3) 使用何种手段互斥。互斥的手段有很多种,我们应该尽量选用一些简单的、开销小的互斥手段,当该互斥手段受到某条使用规则的制约后再考虑其他的互斥手段。
当然,对于一个复杂的驱动,刚开始时我们不一定就能有一个全局的认识,很多认识是逐渐产生的。但是我们应该有这个意识,当问题刚引入的时候就应该考虑它的解决方案,事后再进行处理往往会比较麻烦。
完成量
讨论完内核中的互斥后,接下来我们来看看内核中的同步。同步是指内核中的执行路径需要按照一定的顺序来进行,例如执行路径A 要继续往下执行则必须要保证执行路径B 执行到某一个点才行。以一个 ADC 设备来说,假设一个驱动中的一个执行路径是将ADC 采集到的数据做某些转换操作(比如将干次采样结果做平均),而另一个执行路径专门负责 ADC 采样,那么做转换操作的执行路径要等待做采样的执行路径。
同步可以用信号量来实现,就以上面的 ADC 驱动来说,可以先初始化一个值为0的信号量,做转换操作的执行路径先用 down 来获取这个信号量,如果在这之前没有采集到数据,那么做转换操作的路径将会体眠等待。当做采样的路径完成采样后,调用即释放信号量,那么做转换操作的执行路径将会被唤醒,这就保证了采样发生在转换之前,也就完成了采样和转换之间的同步。
不过内核专门提供了一个完成量来实现该操作,完成最的结构类型定义如下.
struct completion {
unsigned int done;
wait_queue_head_t wait;
}
done 是是否完成的状态,是一个计数值,为0表示未完成。wait 是一个等待队列头,回想前面阻塞操作的知识,不难想到完成量的工作原理。当 done为0时进程阻塞,当内核的其他执行路径使 done 的值大于 0时,负贵唤醒被阻塞在这个完成量上的进程。完成量的主要 API如下。
void init_completion(struct completion *x);
wait_for_completion(struct completion *);
wait_for_completion_interruptible(struct completion *x);
unsigned long wait_for_completion_timeout (struct completion *x, unsigned long timeout);
long wait_for_completion_interruptible_timeout (struct completion *x, unsigne long timeout);
bool try_wait_for_completion(struct completion *x);
void complete(struct completion *);
void complete_all(struct completion *);
有了前面知识的积累,上面函数的作用及参数的意义都能见名知意,在这里就不再细述。只是需要说明一点,complete 只唤醒一个进程,而complete_all 唤醒所有休眠的进程。完成量的使用例子如下。
/*定义完成量 */
struct completion comp;
/* 使用之前初始化完成量*/
init completion(&comp);
/* 等待其他任务完成某个操作 */
wait_for_completion(&comp);
/*某个操作完成后,唤醒等待的任务 */
complete(&comp);
习题
1.内核中的并发情况有(ABCDE )。
[A] 硬件中断[C] 抢占内核的多进程环境
[B] 软中断和 tasklet[D]普通的多进程环境
[E] 多处理器或多核CPU
2、local_irg_save 的作用是 ( C)。
[A]禁止全局中断[C] 止本CPU中断并将之前的中断使能状态保存下来
[B]禁止本CPU中断
3、可以对原子变量进行的操作有( ABC)。
[B] 加上一个整数值并返回结果
[D] 变量中指定的比特位交换
[A]自减并测试结果是否为0
[C] 进行位清除
4、关于自旋锁的使用说法错误的是( D)。
[A] 获得自旋锁的临界代码段执行时间不宜过长
[B]在获得锁的期间不能够调用可能会引起进程切换的函数
[C]自旋锁可以用于中断上下文中
[D]在所有系统中,即不管是否抢占、是否是多核,自旋锁都是忙等待
5.关于信号量的使用说法错误的是 (A )。
[A] 如果不能获得信号量,则进程休眠
[B]在中断上下文中不能调用 down 函数来获取信号量
[C]在获得信号量期间,进程可以睡眠
[D] 相比于自旋锁,优先使用信号量
6.关于RCU 说法错误的是 ( A)。
[A] 写者完成写后立即更新指针
[B] 适合于读访问多、写访问少的情况
[C] 对共享资源的访问都是通过指针来进行的
[D] 尽可能减少了对锁的使用
7.完成量的complete 函数可以唤醒( A)进程
[A]一个
[B] 所有
















 757
757











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











