







实验六、综合练习(1)
一、单选题
1、Python语言采用()来表明每行代码的层次关系(D)
A 、注释和制表符
B、制表符或括号
C、括号
D、空格或制表符
2、下列不属于python3中保留字的是(A )
A、elseif
B、del
C、raise
D、class
3、“ab”+”c”*2 结果是:(B )
A、abc2
B、abcabc
C、abcc
D、ababcc
4、下面一段代码需要(C)保证其正常输出
mylen(my def):
mydef.split()
return len(my def)
res =mylen('hfweiie8832 fej中文')
print(res)
A、首行缩进与第二行保持一致
B、首行添加def关键字且用空格与函数名隔开
C、第三行去掉len关键字
D、无需修改,程序可以正常输出
5、已知ls=[12,34.5,Truetest’,3+5j],则下列选项中,输出结果为“[test”]”的选项是(C)
A、ls[3:4]
B、ls[4:5]
C、ls[3]
D、ls[4]
6、以下的运行的结果是(C)
strs ='I like python and java'
print(strs.replace( I',Your')
print(strs.replace('a','*',2))
A、Your like python and java’,I like python nd jv*”
B、I like python and java’,I like python nd jv*’
C、Your like python and java’,‘I like python nd jva’
D、I like python and java’,‘I like python nd jva’
7、在Python3中,下列程序运行结果为(B)
dicts = {}
dicts[(1,2)] = ({3,(4,5)})
print(dicts)
A、报错
B、{(1, 2): {(4, 5),3}}
C、{(1, 2): [(4, 5), 3]}
D、{(1, 2): [3, 4, 5]}
8、在python3中,程序运行结果为(B)
truple=(1.23)
print(truple*2)
A、(2,4, 6)
B、(1, 2, 3, 1, 2,3)
C、[1, 2, 3, 1, 2, 3]
D、None
9、以下选项,不是Python保留字的选项是(D)
A、del
B、pass
C、not
D、string
10、以下关于函数的描述,错误的是(B)
A、函数是一种功能抽象
B、使用函数的目的只是为了增加代码复用
C、函数名可以是任何有效的Python标识符
D、使用函数后,代码的维护难度降低了
11、以下不属于Python的pip工具命令的选项是(D)
A、show
B、install
C、dowload
D、get
12、以下关于文件的描述,错误的是:(C)
A、二进制文件和文本文件的操作步骤都是“打开-操作-关闭”
B、open0打开文件之后,文件的内容并没有在内存中
C、open0只能打开一个已经存在的文件
D、文件读写之后,要调用close()才能确保文件被保存在磁盘中了
13、以下关于循环结构的描述,错误的是(A)
A、遍历循环使用for<循环变量> in<循环结构语句>,其中循环结构不能是文件
B、使用range()函数可以指定for循环的次数
C、for i in range(5)表示循环5次,i的值是从0到4
D、用字符串做循环结构的时候,循环的次数是字符串的长度
14、以下程序的输出结果是:(B)
def test( b = 2,a=4):
global z
z=a*b
return z
z=10
print(z,test())
A、18 None
B、10 18
C、UnboundLocalError
D、18 18
15、以下程序的输出结果是:(B)
ss= list(set("jzzszyj"))
ss.sort()
print(ss)
A、[‘z’,‘j’,‘s’,‘y’]
B、[‘j’,‘s’,‘y’,‘z’]
C、[‘j’,‘z’,‘z’,s’,‘z’,‘y’,‘j’]
D、[‘j’,‘j’,‘s’,‘y’,‘z’,‘z’,‘z’]
二、改错题
1、修改程序,实现求以 1 到 n 以内(包括 n)的偶数和,错误的位置已在程序中标出。
【输入】 输入 n
【输出】 输出 1-n 以内的偶数和
【输入输出样例 1】

#以下是改完之后的正确代码:
#在程序中修改错误,以使程序能够正确运行白#求1到n间的偶数和
n=int(input())
sum=0
for i in range(2,n+1,2): #错误在本行(已修改)
sum=sum+i
print (sum)
2、修改程序,输入 2 个整数 m,n 求它们的最小公倍数。
【输入】 输入两个整数 m,n
【输出】求两个整数的最小公倍数
【输入输出样例 1】

#以下是已修改的代码:
#求m,n的最小公倍数
m, n = map(int,input().split())
r = m % n
t = m * n
while r != 0:#本行有错(已修改)
m=n
n=r
r=m % n #本行有错(已修改)
print(t//n)
三、程序填空题
1、在程序中指定的位置补齐代码,完成下列分段函数:
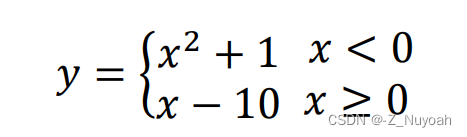
【输入】 输入 1 个整数 n
【输出】输出结果 y
【输入输出样例 1】

x = eval(input())
#请在这行下面补上代码
if x < 0:
y = x * x + 1
else:
y = x - 10
print (y)
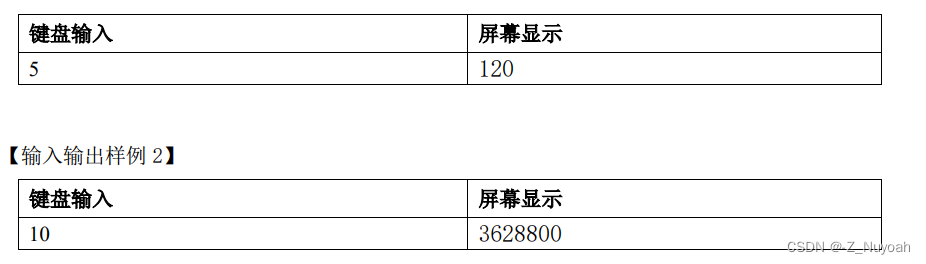
2、在键盘上输和一个整数 n,求它的阶乘。
【输入】 输入 1 个整数 n
【输出】输出它的阶乘
【输入输出样例 1】
n = int(input())
result = 1
#请在这行下面补上代码
for i in range(1,n + 1):
result = result * i
print (result)
四、编程题
1、使用给定的正整数 n,编写一个程序生成一个包含(i, i*i)的字典,该字典包含 1 到 n 之间的整数(两者都
包含)。然后程序应该打印字典。
【输入】 输入一个整数 n
【输出】按要求输出字典
【输入输出样例 1】

n = int(input())
d = {}
for i in range(1,n+1):
d[i] = i*i
print(d)
2、编写一个程序,输入 2 个 3 位的正整数 m,n,求它们之间的所有这些数字(均包括在内),这样数字的每个
数字都是偶数。获得的数字应以逗号分隔的顺序打印在一行上。
【输入】 输入 2 个整数 m,n
【输出】按要求输出查找的数字
【输入输出样例 1】

num_1,num_2 = map(int,input().split())
list = []
if num 1 > num 2:
num_1,num_2 = num_2,num_1
for i in range(num_1,num_2 + 1):
if (i // 100) % 2 == 0 and (i // 10) % 2 == 0 and (i % 2) == 0:
list.append(i)
list_2 = [str(item) for item in list]
print(",".join(list_2))
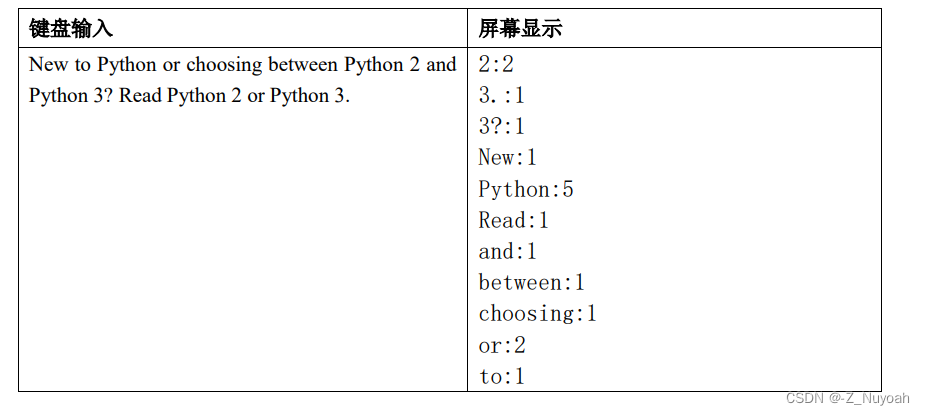
3、编写一个程序来计算输入中单词的频率。 按字母顺序对键进行排序后输出。
【输入】 输入一段英文文字
【输出】计算单词出现的频率,并按字母顺序排序输出。
【输入输出样例 1】

from collections import defaultdict
text = input()
words = text.split()
word_frd = defaultdict(int)
for word in words:
word_fr[word] += 1
sorted_word = sorted(word_fr.keys())
for word in sorted_word:
print (f"{word}:{word_fr[word]}")
4、有 n(2≤n≤20)块芯片,有好有坏,已知
①好芯片比坏芯片多。每个芯片都能用来测试其他芯片。
②用好芯片测试其他芯片时,能正确给出被测试芯片是好还是坏。而用坏芯片测试其他芯片时,会随机给
出好或是坏的测试结果(即此结果与被测试芯片实际的好坏无关)。
给出所有芯片的测试结果,问哪些芯片是好芯片。
提示:好芯片比坏芯片数量多,且所有的好芯片对其他芯片的测试结果都为 1。所以,当一个芯片的被测
结果为 1 的数量大于芯片总数的一半(n/2)时,则这个被测芯片是好芯片。
【输入】数据第一行为一个整数 n,表示芯片个数。
第二行到第 n+1 行为 n*n 的一张表,每行 n 个数据。表中的每个数据为 0 或 1,在这 n 行中的第 i 行第 j
列(1≤i, j≤n)的数据表示用第 i 块芯片测试第 j 块芯片时得到的测试结果,1 表示好,0 表示坏,i=j
时一律为 1(并不表示该芯片对本身的测试结果。芯片不能对本身进行测试)。
【输出】按从小到大的顺序输出所有好芯片的编号
【输入输出样例 1】

n = int(input())
table =[]
list = []
for i in range(n):
row = input().split()
table. append(row)
list.append(0)
for row in table:
i=0
for col in row:
list[i] += int(col)
i += 1
for j in range(len(list)) :
if list[j] > n/2:
print (j + 1, end=" ")
















 2504
2504











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











