







目录
一、基本概念
(1)排序定义:将一个数据元素(或记录)的任意序列,重新排列成一个按关键字有序的序列。
(2)排序分类:按待排序记录所在位置
- 内部排序:待排序记录存放在内存
- 外部排序:排序过程中需对外存进行访问的排序
(3)排序分类:按排序依据原则
- 插入排序:直接插入排序、折半插入排序、希尔排序
每次将一个待排序的记录,按关键字的大小插入到已排好序的子序列中的适当位置,直到全部记录插入完毕为止
- 交换排序:冒泡排序、快速排序
两两比较待排序记录的关键值,交换不满足顺序要求的记录,直到全部满足顺序要求为止
- 选择排序:简单选择排序、堆排序
每次从待排序记录中选出关键字最小的记录,顺序放在已排序的记录序列的后面,直到全部排完为止
- 归并排序:2-路归并排序
每次将两个或两个以上的有序表组合成一个新的有序表
- 基数排序:多关键字排序方法
- 外部排序:多路平衡归并、置换-选择排序、最佳归并树
(4)排序分类:按排序所需工作量
- 简单的排序方法: T(n)=O(n²)
- 先进的排序方法:T(n)=O(nlogn)
(5)排序基本操作:
- 比较两个关键字大小
- 将记录从一个位置移动到另一个位置
(6)排序算法稳定性
待排序数列中如果有关键字相等的记录,例如:
65 49 38 63 97 49 13 27 55 04
经某一种算法排序时,
04 13 27 38 49 49 55 63 65 97
关键字相等的记录其先后次序始终不变,
则称排序算法为稳定的,具有稳定性;
否则不稳定,具有不稳定性
二、插入排序
插入排序的基本思想:
每次将一个待排序的记录,按关键字的大小插入到已排好序的子序列中的适当位置,直到全部记录插入完毕为止。
2.1 直接插入排序
排序过程:
- 先将序列中第1个记录看成是一个有序子序列,然后从第2个记录开始,逐个进行插入,直至整个序列有序;
- 整个排序过程为n-1趟插入。
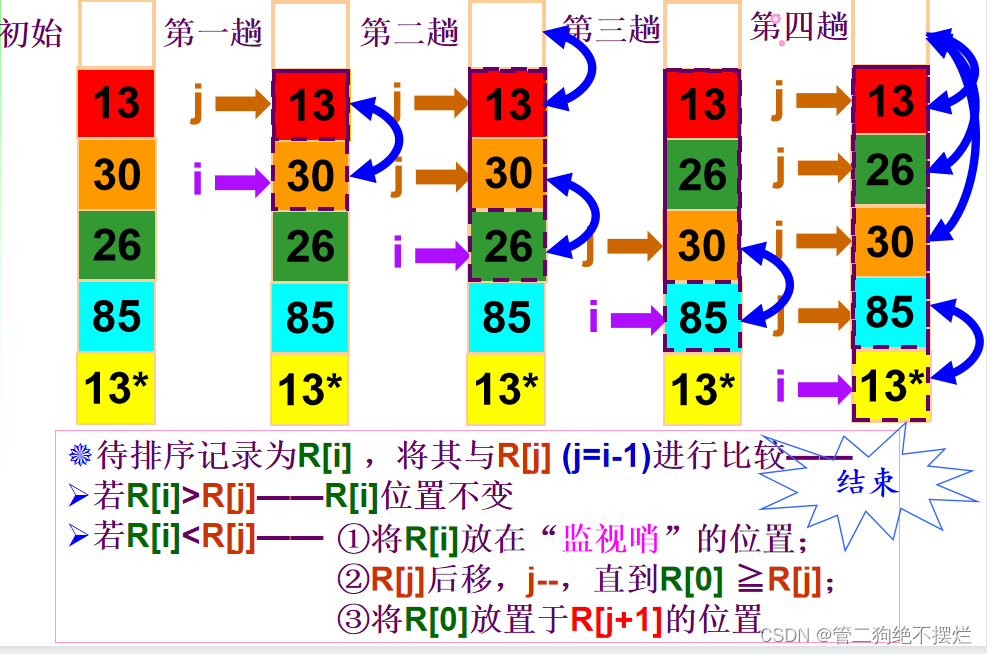
图2.1-1 直接插入排序演示
代码实现:
void InsertSort(SqList L)
{
int i, j;
for (i = 2; i <= L.length; i++)
{
if (L.r[i].key < L.r[i - 1].key)
{
L.r[0] = L.r[i];
for (j = i - 1; L.r[0].key < L.r[j].key; j--)
L.r[j + 1] = L.r[j];
L.r[j + 1] = L.r[0];
}
}
}
算法评价

图2.1-2 直接插入排序算法评价
稳定性:为稳定排序
2.2 折半插入排序
排序过程:用折半查找方法确定插入位置的排序
待排序记录为R[i],先将R[i]移至监视哨
low=1,high=i-1,mid=(low+high)/2
将R[i]与R[mid]比较,进行折半查找,直到low>high
将i之前low及low之后元素后移
将R[0]插入到low所指示位置
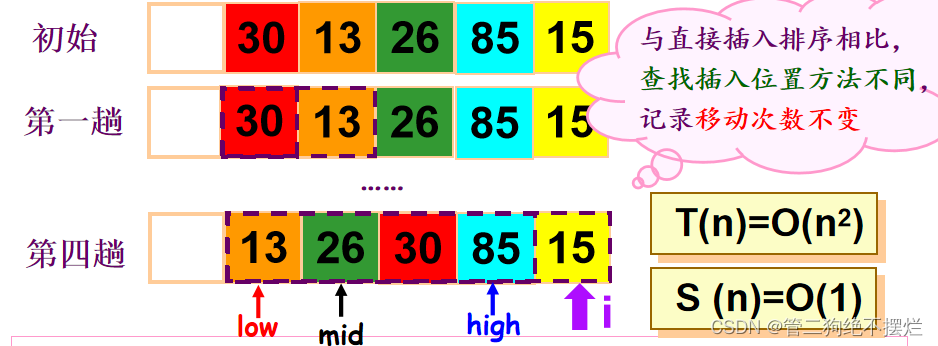
图2.2-1 折半插入排序演示与算法评价
代码实现
void BinSort( SqList &L)
{ int i, j, high, low, mid;
for(i=2; i<=L.length; i++)
{ L.r[0]=L.r[i];
low=1; high=i-1;
while(low<=high)
{ mid=(low+high)/2;
if(L.r[0].key<L.r[mid].key)
high=mid-1;
else low=mid+1; }
for(j=i-1; j>=low; j--)
L.r[j+1]=L.r[j];
L.r[low]=L.r[0];
}
}
稳定性:为稳定排序
2.3 希尔排序
基本思想:先将整个待排序记录分割成若干个子序列分别进行直接插入排序,待整个序列中的记录“基本有序”时,再对全体记录进行一次直接插入排序。
对待排记录先作“宏观”调整,再作“微观”调整。
“宏观”调整:“跳跃式”的插入排序。
排序过程:
- 先取一个正整数d1<n,把所有相隔d1的记录放一组,组内进行直接插入排序;
- 取d2<d1,重复上述分组和排序操作;
- 取d3<d2,……,直至dt=1,即所有记录放进一个组中排序为止。
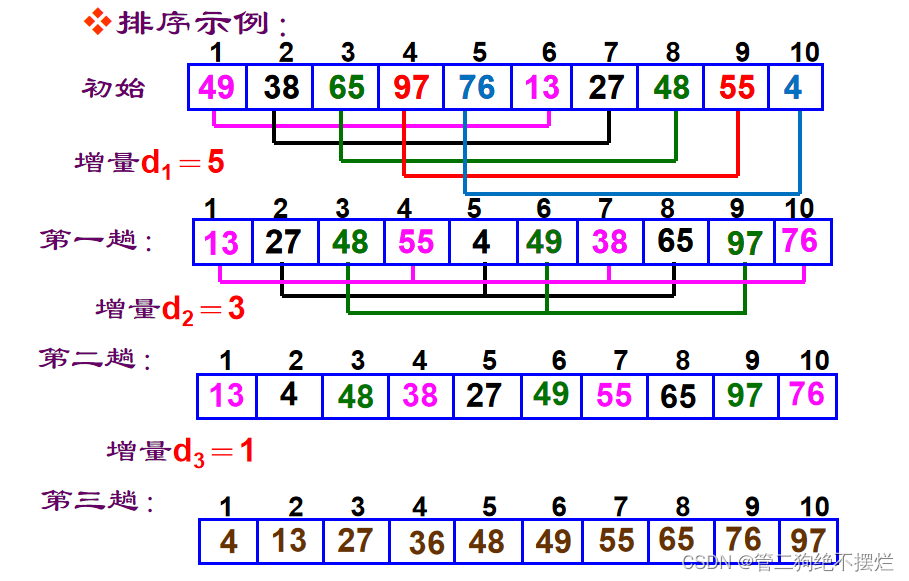
图2.3-1 希尔排序算法演示
希尔排序特点:
子序列的构成不是简单的“逐段分割”,而是将相隔某个增量的记录组成一个子序列
希尔排序可提高排序速度,因为关键字较小的记录跳跃式前移,在进行最后一趟dt=1的插入排序时,序列已基本有序。
增量序列取法:
d1>d2>…>dt,且无除1以外的公因子(即取得这些di必须是互质的,因为如果非互质就会增多无意义的操作),dt=1
代码实现:
void ShellInsert ( SqList &L, int dk ) {
for ( i=dk+1; i<=n; ++i )
if ( L.r[i].key< L.r[i-dk].key) {
L.r[0] = L.r[i]; // 暂存在R[0]
for (j=i-dk; j>0&&(L.r[0].key<L.r[j].key);
j-=dk)
L.r[j+dk] = L.r[j]; // 记录后移,查找插入位置
L.r[j+dk] = L.r[0]; // 插入
} // if
} // ShellInsert
void ShellSort (SqList &L, int dlta[], int t)
{ // 增量为dlta[]的希尔排序
for (k=0; k<t; ++t)
ShellInsert(L, dlta[k]);
//一趟增量为dlta[k]的插入排序
} // ShellSort
复杂度分析:
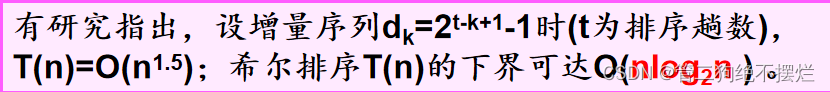
图2.3-1 希尔排序算法评价
稳定性:为不稳定排序
三、交换排序
交换排序的基本思想:
两两比较待排序记录的关键值,交换不满足顺序要求的记录,直到全部满足顺序要求为止。
3.1 冒泡排序
排序过程
- 比较1st与2nd记录的关键字,若逆序则交换;然后比较2nd与3rd记录的关键字;……直至比较n-1th与nth记录为止。完成第一趟冒泡排序,则关键字最大的记录被放置在最后一个位置上;
- 对前n-1个记录进行第二趟冒泡排序,将关键字次大的记录放置在倒数第二个位置上;
- 重复上述过程,直到“在一趟排序过程中没有进行过交换记录的操作”为止。
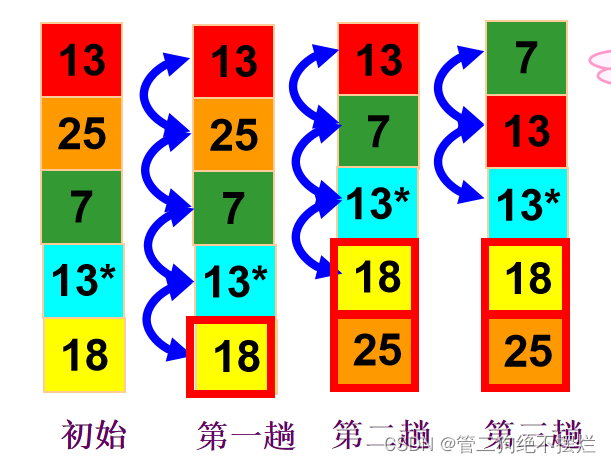
图3.1-1 冒泡排序算法演示
代码实现:
void BubbleSort( SqList &L)
{ int m, j, flag=1;
m=L.length-1;
while((m>0)&&(flag= =1))
{ flag=0;
for(j=1;j<=m;j++)
if(L.r[j].key>L.r[j+1].key)
{ flag=1;
L.r[0]=L.r[j]; L.r[j]=L.r[j+1]; L.r[j+1]=L.r[0];
}
m--;
}
}
算法评价:

图3.1-2 冒泡排序算法复杂度
稳定性:为稳定排序
3.2 快速排序(重点)
基本思想:
- 在待排序记录中任取一个记录(通常为1st记录) , 作为枢轴(pivot),将其它记录分为两个子序列:
子序列1中,记录的关键值<枢轴的关键值;
子序列2中,记录的关键值>=枢轴的关键值; - 将枢轴放置在两个子序列之间(即枢轴的最终位置),完成一趟快速排序。
- 分别对两个子序列重复上述过程,直到序列有序。
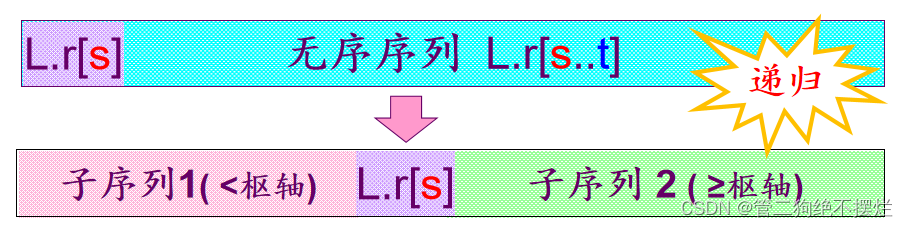
图3.2-1 快速排序算法思想


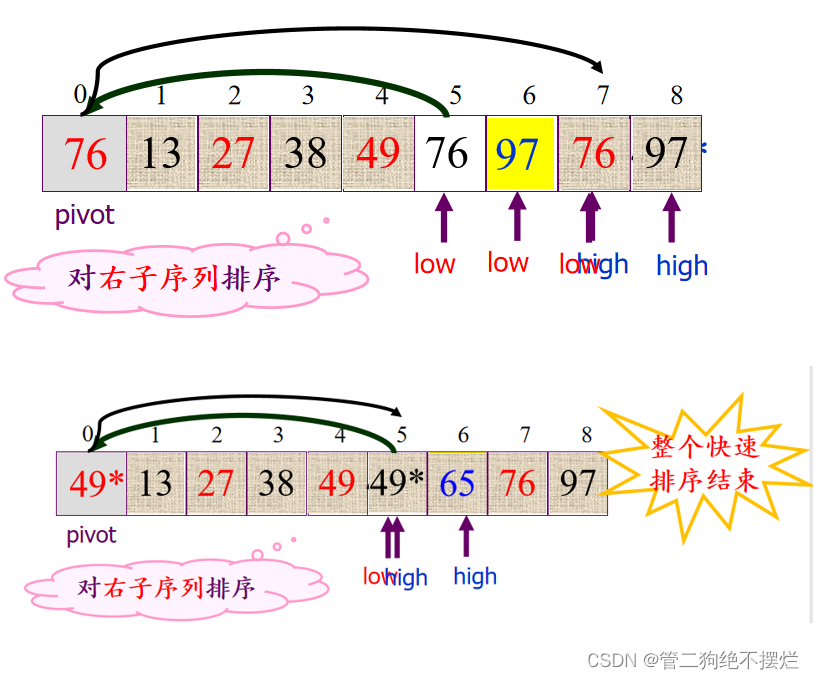
图3.2-2 快速排序算法演示
代码实现:
int Partition(SqList &L, int low, int high)
{
KeyType pivotkey;
L.r[0] = L.r[low]; pivotkey = L.r[low].key;
while (low < high)
{
while (L.r[high].key >= pivotkey && low < high)
high--;
if (low < high)
{
L.r[low] = L.r[high];
low++;
}
while (L.r[low].key <= pivotkey && low < high)
low++;
if (low < high)
{
L.r[high] = L.r[low];
high--;
}
}
L.r[low] = L.r[0];
return low;
}
void QuickSort(SqList &L, int low, int high)
{
int pivotloc;
if(low<high)
{
pivotloc=Partition(L, low, high);
QuickSort(L, low, pivotloc-1);
QuickSort(L, pivotloc+1, high);
}
}
复杂度分析:

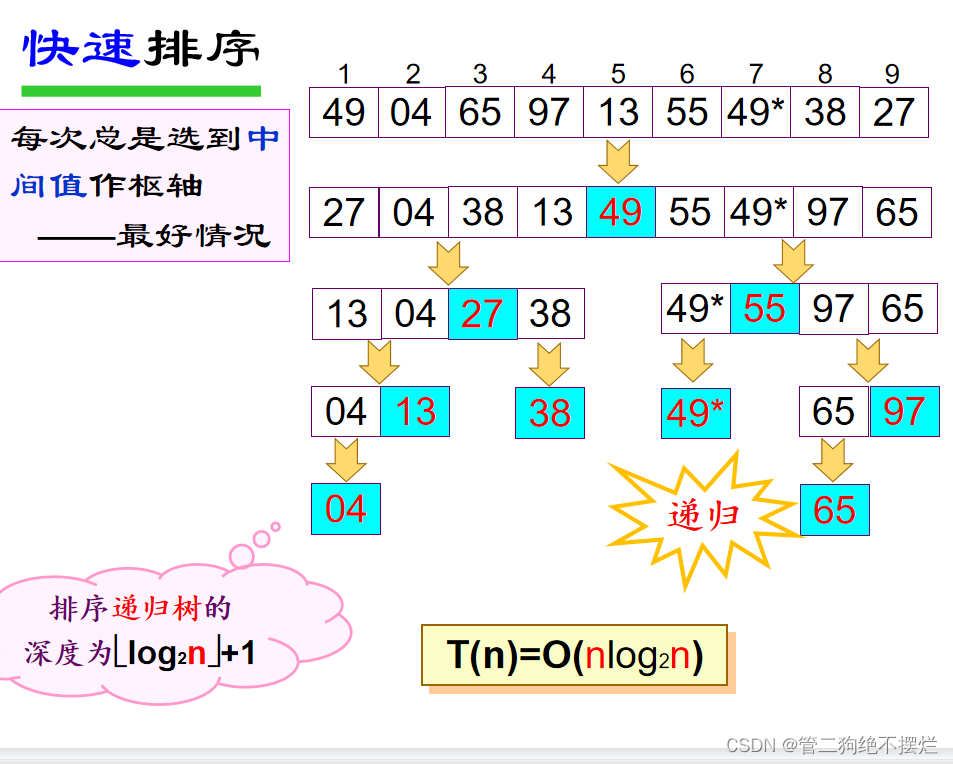

稳定性:为不稳定排序

















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











