







Work-in-Progress: Impacts of Critical-Section Granularity When Accessing Shared Resources
目录
表1说明:GPU访问持续时间(以微秒为单位),在CPU上测量,针对我们考虑的每种访问分组配置
四、案例研究:不可抢占协议 (Case Study: Non-Preemptive Protocol)
A. 调度算法和资源访问协议 (Scheduling Algorithm and Resource Access Protocol)
B. 临界区粒度的影响 (Impact of Critical-Section Granularity)
一 、文章核心
随着自动驾驶车辆中计算机视觉应用的普及,使用图形处理单元(GPUs)变得必要。由于尺寸、重量、功耗和成本的限制,多个任务必须共享这些GPU,这通常通过锁协议来管理。然而,实验显示,这种共享的粒度存在权衡;如果将多个GPU访问操作组合成一个锁请求(即形成一个临界区),而不是每个访问都单独处理,GPU操作的执行时间会减少。这种组合暴露了一个更广泛的权衡:单个任务所承受的额外锁开销(和阻塞)与系统中所有其他任务经历的分析性阻塞之间的权衡。本文通过扩展的资源模型和示例任务系统来表达这种权衡,展示了不同访问组合启发式的影响。
二、相关背景
随着新车上辅助驾驶功能的不断增加和完全自动驾驶的未来,计算机视觉(CV)应用变得越来越重要。这类应用通常需要专用硬件加速器,如图形处理单元(GPUs)。由于尺寸、重量、功耗和成本等严格限制,这些GPU必须在同一平台上的多个CV应用之间共享。
然而,共享硬件资源管理普遍具有挑战性,尤其是对于GPU。预先中断计算通常是不现实的,NVIDIA GPU的内置调度行为可能导致意外延迟。锁协议可以用于仲裁对这些共享GPU的访问。
要求互斥的GPU访问带来了一个权衡:任务在持有锁(即在临界区内)时执行的计算越多,它完成的越快,因为它不需要承受多次锁定和解锁请求的额外开销;然而,额外的计算会导致其他任务经历更长的阻塞时间。
三、初步实验
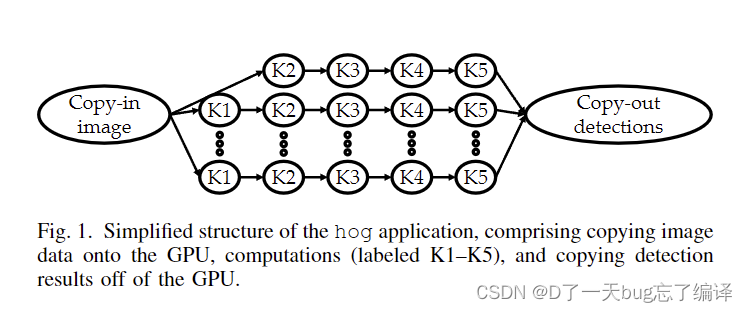
注:
在这篇文章中,K1到K5表示的是在处理图像时需要在GPU上执行的五个不同的计算操作。这些操作是方向梯度直方图(HOG)应用的一部分,每张图像在不同分辨率级别上进行处理时都会执行这五个计算。具体而言:
- K1:表示第一步计算,通常是对图像进行预处理或初步变换。
- K2:表示第二步计算,可能是进一步的图像处理或特征提取。
- K3:表示第三步计算,可能是进行复杂的图像分析或处理操作。
- K4:表示第四步计算,可能是对前面计算结果的进一步处理。
- K5:表示第五步计算,通常是最后一步处理,可能包括生成最终的检测结果或其他输出。
在文章中提到第一级没有K1是因为对于原始图像分辨率,第一级的计算跳过了K1操作。K1操作通常是对图像进行缩放或者预处理,而对于原始图像分辨率,这一步骤是多余的,因此跳过了这一步。
具体来说,K1到K5表示不同的GPU计算操作,在不同分辨率级别上的处理流程如下:
- 原始分辨率级别:跳过K1,只进行K2到K5的计算。
- 其他分辨率级别:进行K1到K5的所有计算操作。
这是因为在处理多分辨率图像时,原始分辨率的图像不需要再次缩放,而其他分辨率的图像则需要先进行K1的缩放操作,之后才进行K2到K5的计算。
A. 实验设置
-
实验平台:
- 使用的硬件:两台八核2.10 GHz Intel Xeon Silver 4110 CPU和一台NVIDIA Titan V GPU。
- 每个CPU核心有32 KB的一级指令和数据缓存,以及1 MB的二级缓存;所有八个CPU核心共享一个11 MB的三级缓存。
- 禁用了超线程和图形输出以减少干扰。
-
工作负载:
- 工作负载为基于GPU的计算机视觉应用——方向梯度直方图(HOG)。
- HOG工作负载基于计算机视觉库OpenCV,通过处理不同分辨率的图像进行行人检测。
- 每张图像(视频中的一帧)在13个不同的分辨率级别上进行处理,每个级别执行五次GPU计算(K1到K5,如图1所示)。
-
实验步骤:
- 执行两个实例的HOG程序,每个实例处理5000帧。
- 使用
clock_gettime()函数在CPU上测量每次GPU计算的持续时间。 - 通过锁协议仲裁GPU访问,确保在任何给定时间只有一个实例可以使用GPU。
- 考虑了三种不同的锁配置,分别对GPU复制和计算操作进行分组,这些操作统称为访问:
- GROUP-NONE:不进行任何访问分组。处理一张图像需要78次锁请求(一次复制输入,(13×5)-1次计算,以及13次复制输出操作)。
- GROUP-MINOR:每个K3到K5序列在一个临界区内完成,复制输出操作进行小规模分组。处理一张图像需要1 + 13 × 3 + ⌈13/3⌉ = 45次锁请求。
- GROUP-MAJOR:所有计算操作在一个临界区内完成(第一级为K2到K5,其他级别为K1到K5);所有复制输出操作进行大规模分组。处理一张图像需要1 + 13 + 1 = 15次锁请求。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











