







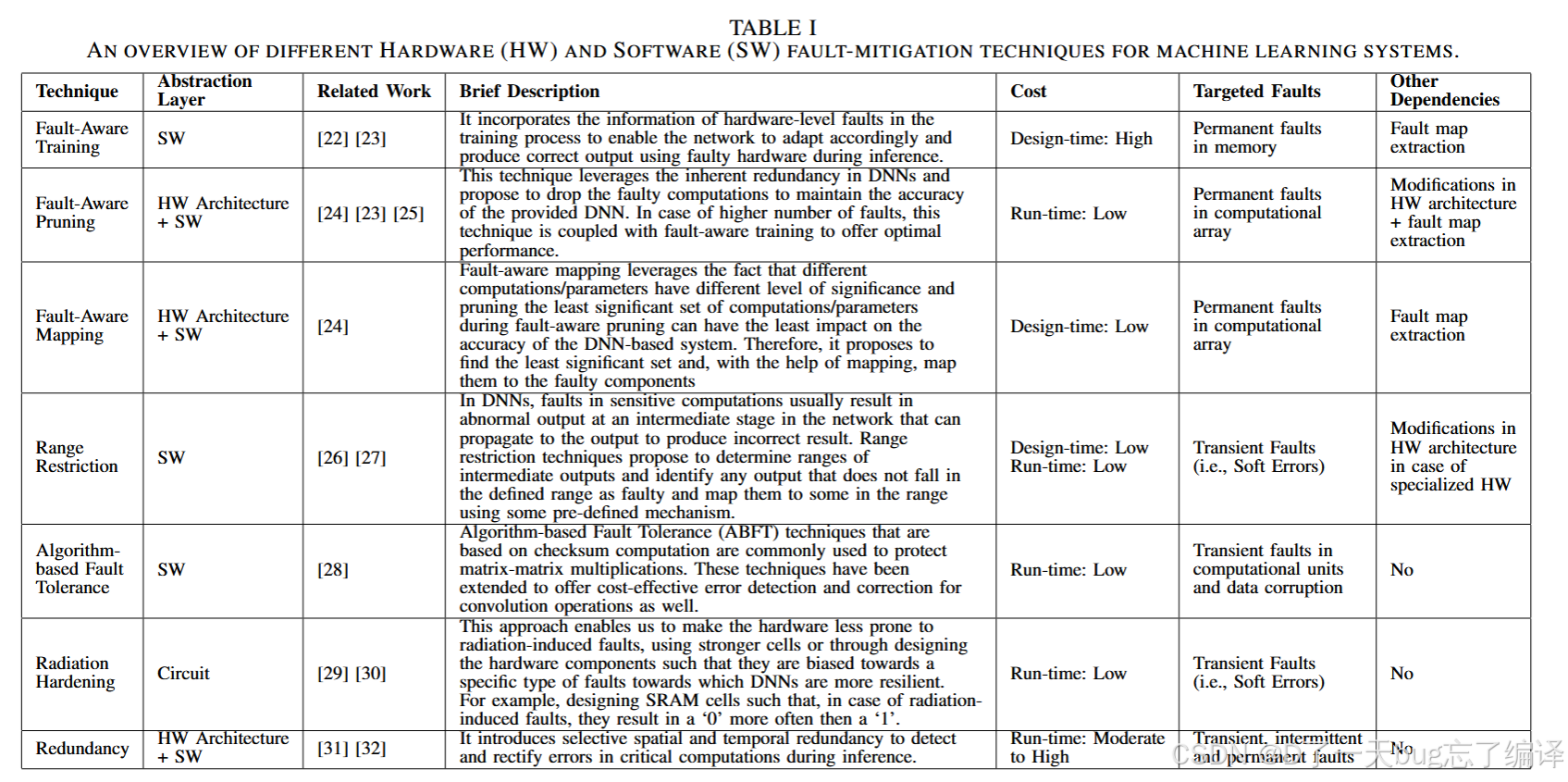
Dependable Deep Learning: Towards Cost-Efficient Resilience of Deep Neural Network Accelerators against Soft Errors and Permanent Faults
本人评论
1. 感觉应对软错误的方式开销非常非常低,这个可以去尝试一下是否有效。
2. 应对永久性错误,与其说是给了三种方法,不如说是三种方向,但这些方法都需要一个前提:即我知道永久性错误的位置在哪,但是其实最大的挑战就是检错,而不是应对方法,所以这三种均需要与某种方法配合。
3. 永久性错误的方法1不新鲜,离线开销也很高,方法2本人没有尝试过,但是这个开销看起来不大;方法三因为NPU内部的复杂性,事实上为这个单独补一个调度模块并非一个很好的解决方案,而且如何识别哪些部分更重要仍旧是一个非常重要的问题。
背景与动机
-
深度神经网络(DNN)在图像识别、语音识别等任务中取得了近乎人类水平的表现,因此被广泛部署于自动驾驶、医疗诊断等安全关键场景中。
-
DNN硬件加速器虽然计算性能强大,但也面临硬件故障(如软错误、老化、制造缺陷等)带来的威胁,这些错误可能会导致误判、系统失效,甚至安全事故。
-
传统容错方法如DMR/TMR冗余机制和ECC等由于开销高,不适用于计算密集的DNN推理场景。
文章的贡献
-
分类整理了适用于DNN系统的各种软硬件层面的低成本容错技术。
-
提出一个跨层容错框架,将不同技术集成起来,针对多种故障类型实现代价可控的鲁棒性提升。
-
指出未来研究挑战,如测试验证难题、SNN容错研究、自动构建可靠DNN模型等。
容错技术综述
1. 软错误(Soft Errors)缓解
-
关键思路:不是所有bit-flip都严重,有选择地保护重要位。
-
技术手段包括:
-
Range Restriction(范围限制):识别中间输出异常值并纠正。
-
Radiation Hardening:硬件级加固,如让SRAM更容易翻转成0而不是1。
-
ABFT算法级纠错:如卷积操作中的校验机制。
-
工具:BinFI、ARES,用于分析DNN各层的容错能力。
-
2. 永久故障(Permanent Faults)缓解
-
技术依赖于制造后提取的故障地图:
-
Fault-Aware Training:在训练阶段考虑硬件故障,提升对已知缺陷的适应性。
-
Fault-Aware Pruning:剪除映射到故障PE的计算。
-
Fault-Aware Mapping(SalvageDNN):将不重要的参数映射到故障单元上。
-
3. 时序错误(Timing Errors)
-
如ThunderVolt技术,利用Razor Flip-Flop检测时序错误,出错时“跳过”部分计算以保持系统运行。
一、intro
1. 深度学习的应用背景
-
深度学习(DL)利用多层结构的计算模型(即深度神经网络,DNN),可以从原始数据中自动学习层次化特征。
-
DNN在图像分类、图像分割、目标检测、语音识别等多个人工智能领域达到了先进水平,有些场景甚至宣称超越了人类的准确性。
-
正因为如此,它们已经被广泛用于安全关键应用中,例如自动驾驶和医疗诊断。
2. 对DNN硬件的性能和可靠性需求
DNN计算量大,因此出现了许多专用的DNN加速器硬件(例如TPU、MAERI、Eyeriss),旨在提供高效能和能耗优化的推理能力。
在安全关键场景中,这些系统除了要有高性能,还必须具备高度可靠性。
-
然而,硬件容易受到以下因素影响:
-
软错误(如由辐射引起的位翻转)
-
器件老化
-
制造缺陷
-
这些问题会导致误报(false positive)、漏报(false negative),甚至整个系统故障。
3. 传统容错方案的局限
像DMR(双模冗余)、TMR(三模冗余)这类传统冗余容错技术,虽然能提高可靠性,但对DNN来说代价过高,因为它们涉及冗余硬件或冗余执行,会严重增加计算资源消耗。
其他方法如指令复制(Instruction Duplication)和ECC(纠错码)也带来明显的性能与能效损失。
4. 本文研究的动机与方向
-
为了解决传统方法的高开销问题,近年来研究者提出了面向DNN特性的低开销容错技术,旨在不破坏DNN原有性能的前提下提升其鲁棒性。
二、硬件引起的可靠性威胁
1. CMOS工艺缩小引发的挑战
随着CMOS技术的持续缩放(为了提升性能和能效),硬件在纳米尺度下变得越来越脆弱,可靠性问题加剧。
2. 三类主要故障类型详解
Soft Errors(软错误)
-
属于瞬态故障,通常表现为比特翻转(bit-flip)。
-
诱因:
-
外部粒子轰击:如封装材料中释放的α粒子,或来自宇宙射线的中子。
-
高温:会加速软错误率(SER)。
-
-
会引发数据损坏,进而造成推理错误甚至系统崩溃。
Aging(老化)
-
电路老化源于多种物理现象,包括:
-
BTI(Bias Temperature Instability)
-
HCI(Hot Carrier Injection)
-
TDDB(时变介电击穿)
-
EM(电迁移)
-
-
后果:
-
电路变慢(例如阈值电压升高)
-
逐渐表现为时序错误(Timing Errors),最终可能演变为永久故障(Permanent Faults)
-
Process Variations(工艺波动)
-
制造工艺引入的不一致性(如沟道长度、氧化层厚度等)带来:
-
芯片间/片上性能差异
-
能效降低
-
良率下降(更多永久故障)
-
三、方法
A. Soft Error Mitigation(软错误缓解机制)
技术背景
软错误是由辐射粒子或高温等因素引发的瞬时比特翻转。虽然DNN在一定程度上对扰动容忍,但关键位上出现的错误仍可能导致严重后果,尤其在安全关键场景(自动驾驶、医疗)中不可接受。
技术 1:Range Restriction(范围限制)
技术原理
在 DNN 中,某些中间层的输出受软错误影响后可能出现“离谱值”。这类值如果不加以处理,会在后续传播中被放大,最终导致输出错误。
Range Restriction 技术的目标是:
-
在推理阶段对中间激活值进行范围校验
-
将超出范围的值裁剪、替换或压缩到可接受区间
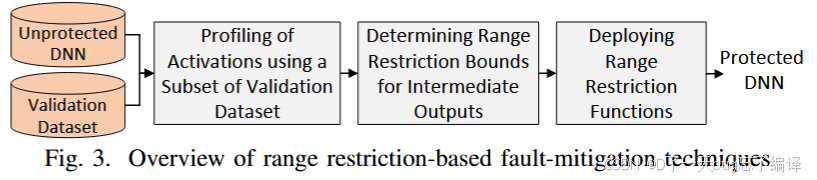
技术流程(图 3)
从图中可以看到 Range Restriction 技术的三个阶段:
-
Profiling:
-
用一小部分验证集(不是训练集!)输入未保护的 DNN
-
统计中间层激活值的分布范围
-
-
确定裁剪边界:
-
为每一层输出建立“合法区间”,例如:[μ − 3σ, μ + 3σ],或按最大最小值构建
-
-
部署限制函数:
-
在线推理时,把超出区间的输出值替换为区间边界值
-
不需要改结构、不需要再训练
-

效果评估(图 4)
图中蓝线代表加入 FT-ClipAct(Range Restriction 代表性算法)后的准确率,红线代表未经保护的模型。
-
随着故障率升高(横轴为 log scale 的 fault rate),未保护的模型准确率快速下降
-
FT-ClipAct 模型在 fault rate 高达 10−5时仍保持>70% 准确率,展现不错的抗软错误能力
总结:
-
Range Restriction 是**“不动网络结构、不改硬件”的纯软件防护手段**
-
成本极低,适合部署后即插即用的可靠性增强
B. Permanent Fault Mitigation(永久故障缓解机制)
技术背景
永久故障由制造缺陷或老化引起,表现为某些硬件单元始终不可用(例如,某些MAC单元无法乘加)。
与软错误不同,永久故障具有可检测性 → 可以通过后制造测试得到Fault Map,为容错机制提供依据。
技术 1:Fault-Aware Training(图 5)
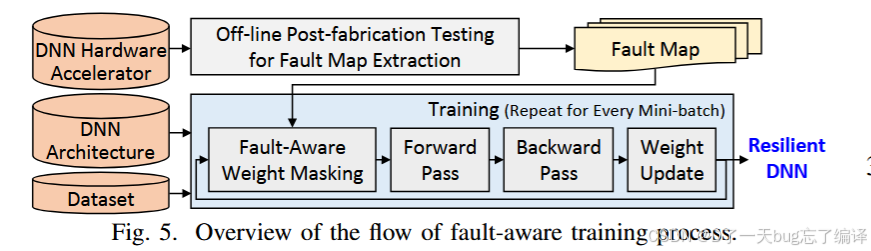
技术原理
-
在训练阶段就加入故障信息,模型学会规避坏掉的硬件路径
-
类似于“在坏掉的硬件上量身定制一个能用的网络”
训练流程详解:
-
提取Fault Map(左上角)
-
对加速器进行post-silicon测试,记录坏掉的MAC、存储bit等
-
-
Fault-Aware Weight Masking
-
在每次训练迭代前将映射到故障位置的权重屏蔽(置0)
-
-
标准训练过程(Forward → Backward → Update)
局限性:
-
每张chip都要重新训练 → 若有大量带故障芯片,开销极大
-
若缺失原始训练集 → 无法应用
技术 2:Fault-Aware Pruning(图 8a+b)
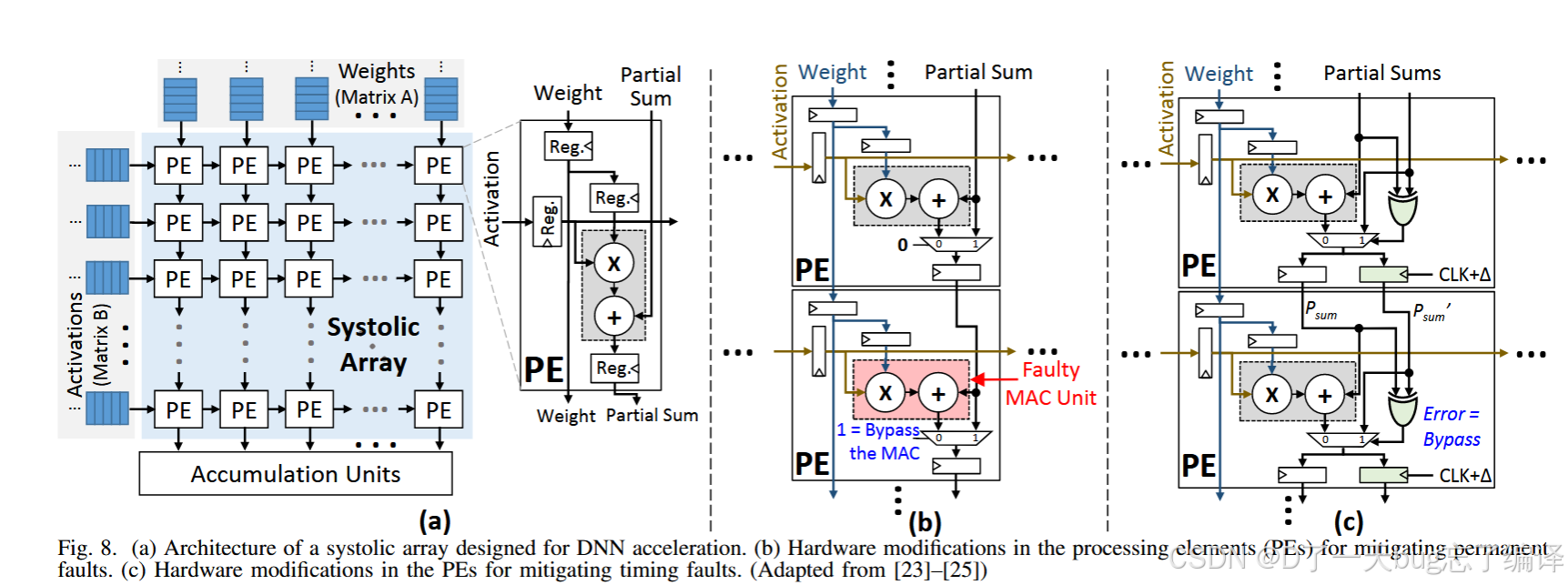
技术原理
-
DNN 具有大量冗余 → 可删除部分计算仍保持准确性
-
将映射到故障MAC的计算剪掉
对硬件支持要求:
-
Systolic Array PE 单元中需引入 bypass 控制(图 8b 红色块)
-
检测到该PE无法使用 → 将其输出置0或跳过
局限性:
-
裁剪越多 → 性能下降越多
-
精度下降不可避免
技术 3:Fault-Aware Mapping(图 6 + 图 7)
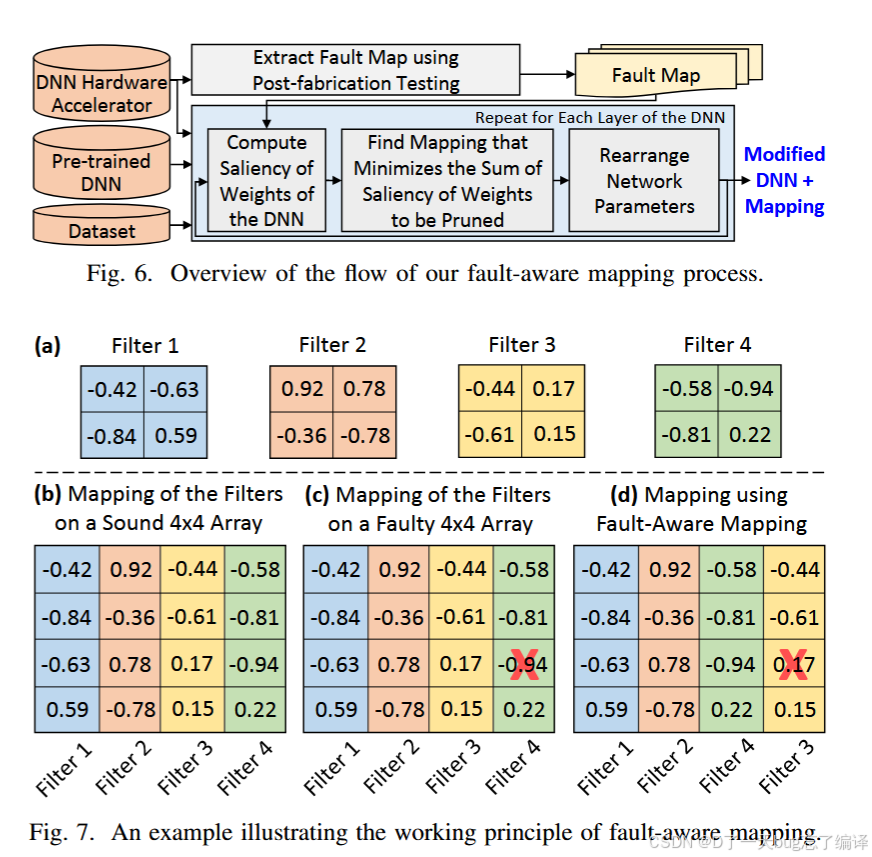
技术创新点
-
和剪枝不同,不是剪掉坏的,而是“重新安排好人和坏人干的活”
具体流程如下(图 6):
-
提取 Fault Map
-
分析网络中各权重的 saliency(重要性)
-
寻找映射方案,使“最不重要”的权重去执行“坏掉的单元”
-
重排卷积核/参数,实现智能调度
👁🗨图 7:直观示例
-
图 7a:4个 2×2 卷积核
-
图 7b:健康阵列下的映射
-
图 7c:若按默认映射,重要权重落在故障单元(-0.94),会被错误裁剪
-
图 7d:通过 Fault-Aware Mapping,把 -0.94 换到不重要位置,减少精度损失
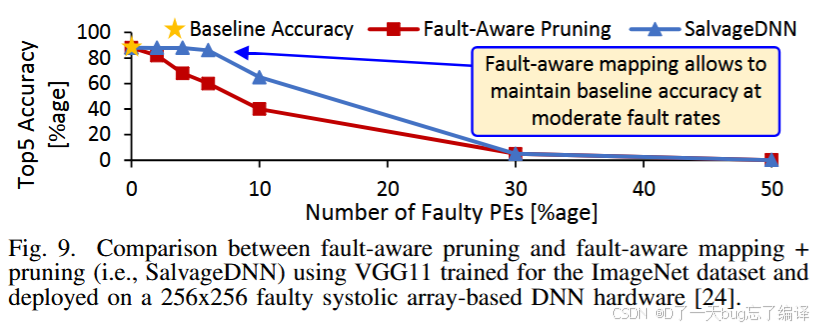
图 9:效果验证
-
蓝线(SalvageDNN)明显优于红线(Pruning-only)
-
在 10~30% 故障PE率下仍可保持 Top-5 准确率接近 baseline
结论:
-
Fault-Aware Mapping 是一种主动容错机制,精准调度计算任务,提升资源利用率与精度
C. Timing Error Mitigation(时序错误缓解)
技术背景
时序错误是电路老化(例如Vth升高)、电压降低带来的延迟导致的错误,属于渐进性失效。
技术:ThunderVolt(图 8c)
核心机制:
-
在乘加单元(MAC)中加入 Razor Flip-Flop 检测器
-
一旦输出延迟超时 → 检测到 timing error
-
立即跳过该单元计算(bypass),把上一时刻结果或默认值传递下去
-
保证系统稳定运行,避免错误传播
动态旁路机制:
| 时钟周期 | PE1 出错? | PE2 行为 |
|---|---|---|
| t | 出错 | 不计算,旁路错误值 |
| t+1 | 正常 | 正常处理 |
技术优势:
-
在保证可接受精度的同时,大幅降低供电电压 → 实现节能 + 容错
总结:可组合、可配置的容错技术框架
| 故障类型 | 代表方法 | 是否需要训练集 | 是否依赖硬件改造 | 开销 | 可组合性 |
|---|---|---|---|---|---|
| Soft Errors | Range Restriction | ❌ | ❌ 或低 | 极低 | ✅ |
| Permanent Faults | Fault-Aware Mapping | ✅ / ❌ | 中等(bypass逻辑) | 中 | ✅ |
| Timing Errors | ThunderVolt | ❌ | ✅(Razor flip-flop) | 低中 | ✅ |



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











