






完美解决SourceInsight3.X中文乱码问题
有时候打开别人现有文件,常常出现中文乱码
查找相关资料,发现都不怎么靠谱,要么就是让手动去编辑器改编码。但这对于多数文件是不管用的!!!!
于是自己动手,成功解决,效果如图:

解决方法:
使用jupyter notebook(当然可以是其他python软件)
一:查看文件类型
import chardet
import os
def detect_encoding(file_path):
with open(file_path, 'rb') as f:
rawdata = f.read()
result = chardet.detect(rawdata)
return result['encoding']
# 指定待检测文件夹路径
folder_path = '这里是自己的文件路径'
# 遍历文件夹中的所有文件
for root, dirs, files in os.walk(folder_path):
for file_name in files:
file_path = os.path.join(root, file_name)
try:
# 检测文件编码
encoding = detect_encoding(file_path)
print(f'The file encoding of {file_path} is: {encoding}')
except Exception as e:
print(f'Error detecting encoding of file {file_path}: {e}')

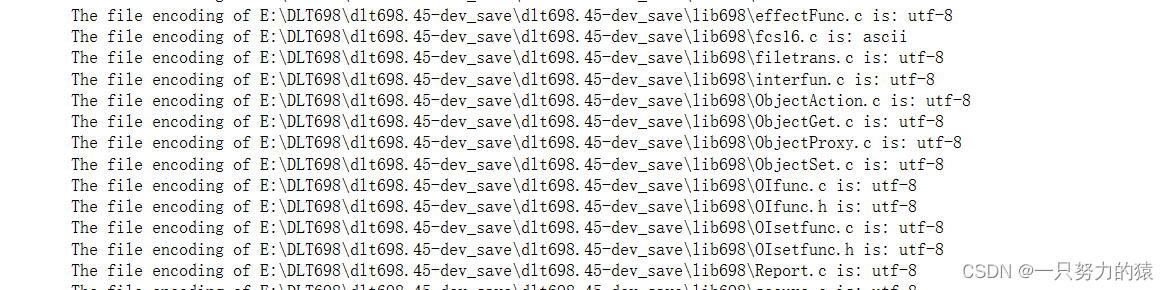
可以看见都是utf-8的,这就是我们要处理的东西,转成GB2312让Source Insight识别。
二:修改文件类型
import os
import shutil
import codecs
def contains_chinese(filepath):
try:
with open(filepath, 'r', encoding='utf-8') as f:
for line in f:
for char in line:
if '\u4e00' <= char <= '\u9fff':
return True
except UnicodeDecodeError:
try:
with open(filepath, 'r', encoding='ascii') as f:
for line in f:
for char in line:
if '\u4e00' <= char <= '\u9fff':
return True
except UnicodeDecodeError:
pass
return False
# 指定待转换文件夹路径
folder_path = 'E:\DLT698\dlt698.45-dev_save\dlt698.45-dev_save'
# 遍历文件夹中的所有文件
for root, dirs, files in os.walk(folder_path):
for file_name in files:
file_path = os.path.join(root, file_name)
# 只对包含中文字符的文件进行编码转换
if contains_chinese(file_path):
try:
# 读取 UTF-8 编码文件内容
with codecs.open(file_path, 'r', 'utf-8') as f:
content = f.read()
# 将内容以 GB2312 编码重新写入文件
with codecs.open(file_path, 'w', 'gb2312') as f:
# 忽略特殊字符,直接写入内容
f.write(content.encode('gb2312', 'ignore').decode('gb2312'))
print(f'Converted file: {file_path}')
# 转换成功,备份原始文件
backup_path = file_path + '.bak'
shutil.copyfile(file_path, backup_path)
except Exception as e:
print(f'Error converting file {file_path}: {e}')
这里增加了对特殊字符的处理,如果UTF-8打不开转ASCII处理,忽略无法解析的特殊字符。
三:测试结果:
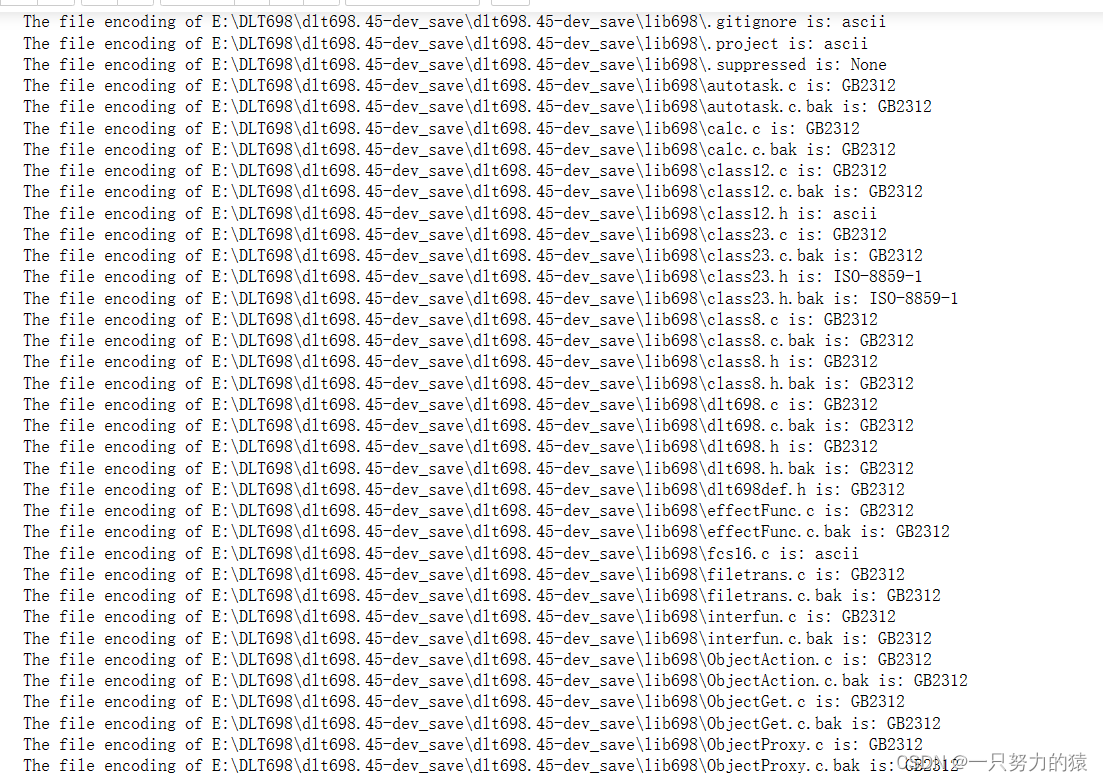
可以看见都变成了GB2312,再来看看Souce Insight里面效果
转换完成!!!
这里要注意如果文件丢失那么就是转换途中出现问题,注意备份一份压缩包防止文件丢失,笔者目前问题已经解决。
















 268
268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









