






问题描述
在进行数据爬取时,我想爬取一个岗位为C++的数据,但是在浏览器中显示的是C (空格)(空格),就是将+转义成了空格,如下所示
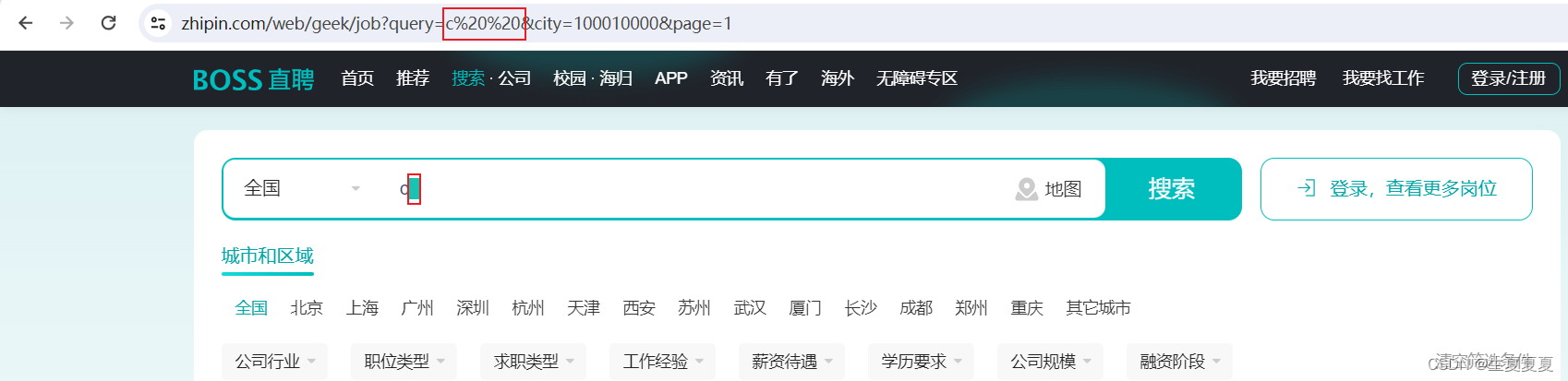
解决
使用urllib.parse.quote() ,它是 Python 中 urllib.parse 模块提供的一个函数,用于对 URL 中的特殊字符进行编码,以便在网络中传输或存储。
在网络传输中,URL 中的某些字符具有特殊含义,例如空格、问号、井号等。如果 URL 中包含这些特殊字符,那么就需要对它们进行编码,以确保它们能够被正确地传输并且不会引起混淆。
urllib.parse.quote() 函数接受一个字符串作为参数,并返回一个经过编码的新字符串。该函数会将 URL 中的特殊字符替换为其对应的编码表示。例如,空格会被替换为 %20,问号会被替换为 %3F,井号会被替换为 %23,以此类推。
import urllib.parse
url = "https://www.example.com/search?q=python+tutorial"
encoded_url = urllib.parse.quote(url)
print(encoded_url)
在这个示例中,原始的 URL 包含+,并且包含一个查询参数 q。使用 urllib.parse.quote() 函数对该 URL 进行编码后,得到的编码后的 URL 将会是 https://www.example.com/search?q=python%2Btutorial,其中+被替换为 %2B。
那么,如果不想让编码的数据保存到数据库或CSV文件,那就直接解码就可以
urllib.parse.unquote(url)














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









