






用接口方式的爬虫,获取到页面的url
例如csdn的网页:https://silkroad.csdn.net/api/v2/assemble/list/channel/search_hot_word?new_hot_flag=1&channel_name=pc_hot_word&size=20&user_name=qq_52611659&platform=pc&imei=10_19872475880-1689927112269-775170
我需要爬取我之前的搜索关键词,就是从这个接口拿到数据的
第一步复制接口路径的CURL
第二步,复制到apifox当中,类似于这种有足够的请求参数 header和parm
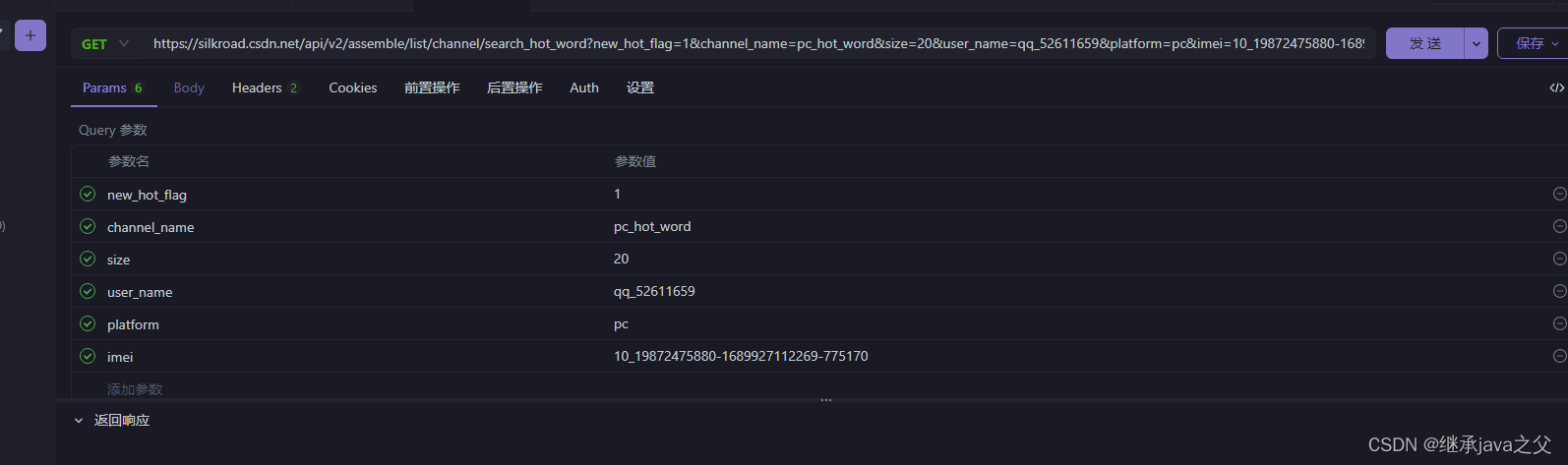
第三步:模仿参数写代码 ,这样就能爬取到需要参数的值是什么,例如这里是爬取的总条数.
String format = LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy年MM月dd日HH时mm分调剂爬虫数据"));
List<AdjustReptileDataBean> data = new ArrayList<>();
JSONObject fieldDescription = new JSONObject();
try {
HttpRequest request = HttpRequest.post("网页的路径");
request.header("Accept", "application/json, text/javascript, */*; q=0.01");
request.header("Content-Type", "application/x-www-form-urlencoded; charset=UTF-8");
request.header("Referer", "https://fe.bnu.edu.cn/pc/cms1info/list/1/13");
Map<String, Object> params = new HashMap<>();
// 不能设置大了。会被重置为20
params.put("columnid", 13);
params.put("page", 1);
request.form(params);
HttpResponse response = request.execute();
int status = response.getStatus();
if (status != 200) {
log.info("网站状态码:{}, 不满足爬取逻辑", status);
return;
}
String body = response.body();
JSONObject json = JSONUtil.parseObj(body);
Integer nowNum = json.get("count", Integer.class);
最后拿到nowNum数据之后就证明已经爬取到数据了















 8489
8489











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









