






hudi搭建
题目分析
本任务需要使用root用户完成相关配置,具体要求如下:
1、 从宿主机/opt目录下将maven相关安装包复制到容器Master中的/opt/software(若路径不存在,则需新建)中,将maven相关安装包解压到/opt/module/目录下(若路径不存在,则需新建)并配置maven本地库为/opt/software/RepMaven/,远程仓库使用阿里云镜像,配置maven的环境变量,并在/opt/下执行mvn
-v,将运行结果截图粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>central</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
要求:
- root用户完成
- 宿主机和docker容器文件的传输,使用docker cp命令
- 搭建maven,配置阿里云仓库
2、 从宿主机/opt目录下将Hudi相关安装包复制到容器Master中的/opt/software(若路径不存在,则需新建)中,将Hudi相关安装包解压到/opt/module/目录下(若路径不存在,则需新建),将命令复制并粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
要求:
- 宿主机和docker容器文件的传输,使用docker cp命令
- tar文件的解压
3、完成解压安装及配置后使用maven对Hudi进行构建(spark3.1,scala-2.12),编译完成后与Spark集成,集成后使用spark-shell操作Hudi,将spark-shell启动使用spark-shell运行下面给到的案例,并将最终查询结果截图粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下。
(提示:编译需要替换以下内容:
1.将父模块pom.xml替换;
2.hudi-common/src/main/java/org/apache/hudi/common/table/log/block/HoodieParquetDataBlock.java替换;
2. 将packaging/hudi-spark-bundle/pom.xml替换
3.将packaging/hudi-utilities-bundle/pom.xml替换
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.hudi.common.model.HoodieRecord
val tableName = "hudi_trips_cow"
val basePath = "file:///tmp/hudi_trips_cow"
val dataGen = new DataGenerator
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Overwrite).
save(basePath)
val tripsSnapshotDF = spark.read.format("hudi").load(basePath + "/*/*/*/*")
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
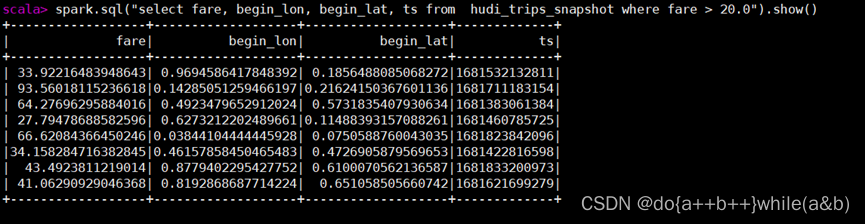
spark.sql("select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0").show()
要求:
- 配置hudi,题目中已经给出修改位置,并说明替换?比赛中服务器可能会给pom文件,选手只需要替换即可
- 使用maven对hudi进行构建,需注意使用spark和scala的版本
- hudi与spark的集成
- 使用spark-shell运行给定的案例
搭建部署
由于当前没有提供hudi-0.12版本的安装包,需要自己去官网去下载,解压完以后使用idea进行配置操作
- 修改中央仓库地址(hudi/pom.xml)
<repository>
<id>nexus-aliyun</id>
<name>nexus-aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
- 修改版本(hudi/pom.xml)
<hadoop.version>3.1.3</hadoop.version>
<hive.version>3.1.2</hive.version>
-
修改代码兼容(\hudi-release-0.12.0\hudi-common\src\main\java\org\apache\hudi\common\table\log\block\HoodieParquetDataBlock.java)

-
安装kafka依赖到本地仓库(需要注意参数需要加引号),如依赖没有找到可以联系我
- common-config-5.3.4.jar
- common-utils-5.3.4.jar
- kafka-avro-serializer-5.3.4.jar
- kafka-schema-registry-client-5.3.4.jar
mvn install:install-file "-DgroupId=io.confluent" "-DartifactId=common-config" "-Dversion=5.3.4" "-Dpackaging=jar -Dfile=./common-config-5.3.4.jar"
mvn install:install-file "-DgroupId=io.confluent" "-DartifactId=common-utils" "-Dversion=5.3.4" "-Dpackaging=jar -Dfile=./common-utils-5.3.4.jar"
mvn install:install-file "-DgroupId=io.confluent" "-DartifactId=kafka-avro-serializer" "-Dversion=5.3.4" "-Dpackaging=jar -Dfile=./kafka-avro-serializer-5.3.4.jar"
mvn install:install-file "-DgroupId=io.confluent" "-DartifactId=kafka-schema-registry-client" "-Dversion=5.3.4" "-Dpackaging=jar -Dfile=./kafka-schema-registry-client-5.3.4.jar"
- 修改hudi-spark-bundle的pom文件
hudi-0.12.0/packaging/hudi-spark-bundle/pom.xml
<!-- Hive -->
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-service</artifactId>
<version>${hive.version}</version>
<scope>${spark.bundle.hive.scope}</scope>
<exclusions>
<exclusion>
<artifactId>guava</artifactId>
<groupId>com.google.guava</groupId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.pentaho</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-service-rpc</artifactId>
<version>${hive.version}</version>
<scope>${spark.bundle.hive.scope}</scope>
</dependency>
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-jdbc</artifactId>
<version>${hive.version}</version>
<scope>${spark.bundle.hive.scope}</scope>
<exclusions>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet.jsp</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-metastore</artifactId>
<version>${hive.version}</version>
<scope>${spark.bundle.hive.scope}</scope>
<exclusions>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.datanucleus</groupId>
<artifactId>datanucleus-core</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet.jsp</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<artifactId>guava</artifactId>
<groupId>com.google.guava</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-common</artifactId>
<version>${hive.version}</version>
<scope>${spark.bundle.hive.scope}</scope>
<exclusions>
<exclusion>
<groupId>org.eclipse.jetty.orbit</groupId>
<artifactId>javax.servlet</artifactId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- 增加hudi配置版本的jetty -->
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-server</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-util</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-webapp</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-http</artifactId>
<version>${jetty.version}</version>
</dependency>
- 修改hudi-utilities-bundle的pom文件
hudi-0.12.0/packaging/hudi-utilities-bundle/pom.xml
<!-- Hoodie -->
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-common</artifactId>
<version>${project.version}</version>
<exclusions>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-client-common</artifactId>
<version>${project.version}</version>
<exclusions>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- Hive -->
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-service</artifactId>
<version>${hive.version}</version>
<scope>${utilities.bundle.hive.scope}</scope>
<exclusions>
<exclusion>
<artifactId>servlet-api</artifactId>
<groupId>javax.servlet</groupId>
</exclusion>
<exclusion>
<artifactId>guava</artifactId>
<groupId>com.google.guava</groupId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.pentaho</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-service-rpc</artifactId>
<version>${hive.version}</version>
<scope>${utilities.bundle.hive.scope}</scope>
</dependency>
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-jdbc</artifactId>
<version>${hive.version}</version>
<scope>${utilities.bundle.hive.scope}</scope>
<exclusions>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet.jsp</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-metastore</artifactId>
<version>${hive.version}</version>
<scope>${utilities.bundle.hive.scope}</scope>
<exclusions>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.datanucleus</groupId>
<artifactId>datanucleus-core</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet.jsp</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<artifactId>guava</artifactId>
<groupId>com.google.guava</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-common</artifactId>
<version>${hive.version}</version>
<scope>${utilities.bundle.hive.scope}</scope>
<exclusions>
<exclusion>
<groupId>org.eclipse.jetty.orbit</groupId>
<artifactId>javax.servlet</artifactId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- 增加hudi配置版本的jetty -->
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-server</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-util</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-webapp</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-http</artifactId>
<version>${jetty.version}</version>
</dependency>
- 编译
mvn clean package "-DskipTests" "-Dspark3.1" "-Dscala-2.12" "-Dhadoop.version=3.1.3" "-Pflink-bundle-shade-hive3"
- packaging包下的每个模块的target目录下就是最终我们所需要的jar包
- 将编译好的hudi-spark、hudi-hadoop包拷贝到spark安装目录的jars下
- 启动spark-shell,配置启动序列化参数
spark-shell --conf "spark.serializer=org.apache.spark.serializer.KryoSerializer"
- 将题目中给的案例直接复制到shell中运行
欢迎一起交流,有问题欢迎指正!!

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











