







中文标题:有限监督下的视频异常检测跨域学习
发表于:ECCV2024
论文地址:https://arxiv.org/pdf/2408.05191
目录
3.2 Feature Extraction and Temporal Processing
3.3 Bias Estimation for External Data
3.6 Inference - Extending Segment-level Scores to Frame-level Scores
4.2 Noise in the Test Annotations of Benchmark Datasets
4.3 Comparison with Prior Works
4.4 Correlation between Uncertainty Scores and BCE Loss (Proxy to Label Quality)
4.5 Progression of Uncertainty Scores
4.6 Ablation Studies and Hyper-parameter Analysis
Abstract.
视频异常检测(VAD)能够自动识别异常事件,例如监控视频中的安全威胁。在实际应用中,VAD模型必须在跨域环境中有效运行,识别那些在训练数据中未得到充分体现的罕见异常和场景。然而,现有的跨域VAD方法主要侧重于无监督学习,其性能未能达到实际应用的预期。由于获取源域的弱监督(即视频级标签)成本效益较高,我们推测将其与外部未标记数据相结合,在提升跨域性能方面具有显著潜力。为此,我们提出了一种全新的用于VAD跨域学习(CDL)的弱监督框架。该框架在训练过程中通过估计预测偏差并利用预测不确定性自适应地最小化偏差,从而融入外部数据。我们在两个大规模VAD数据集UCF-Crime和XD-Violence上进行了多种配置的综合实验,以证明所提出的CDL框架的有效性。在跨域评估中,我们的方法显著优于现有最先进的方法,在UCF-Crime数据集上平均绝对提升了19.6%,在XD-Violence数据集上平均绝对提升了12.87%。
1 Introduction
视频异常检测(VAD)旨在定位视频中的异常事件[3, 10, 11, 14, 20, 24, 30, 31, 39, 44]。与成本高昂且耗时的人工监控不同,视频异常检测无需大量人力,节省了资源和时间。它通过识别异常行为和活动,如事故、盗窃、爆炸以及其他表明存在安全威胁的事件,在视频监控中发挥关键作用的潜力巨大。
视频异常检测(VAD)此前已被广泛研究[11, 14, 20, 30, 31, 44]。由于获取帧级标签成本高且耗时,大多数方法将该问题构建为无监督学习[10, 14, 20]或弱监督学习[11, 30, 31]的模式。在无监督(或基于一类分类)的学习模式中,仅使用正常视频对正常时空模式的潜在分布进行建模,任何偏离该建模分布的情况都会被视为异常。尽管无监督学习模式操作便捷,但训练过程中缺乏异常视频,这限制了模型学习异常行为特定特征的能力。这导致模型性能有限,无法满足实际应用的期望。 为了解决这个问题,弱监督学习模式受到了极大关注。在这种模式下,仅将表明视频中存在异常的视频级标签作为弱监督信息,用于训练能够在推理时进行帧级预测的模型。多实例学习(MIL)[30]是该领域的一项重要技术。基于MIL的算法将每个视频视为一个“包”,每个视频片段视为一个“段”,其运行的前提是在最坏的情况下,将预测为异常概率最高的段作为代表整个视频的候选段。
在实际应用中,不可避免地会遇到模型训练集中未充分涵盖的环境和场景。然而,模型在这些新情况下做出正确预测至关重要。例如,当训练数据缺乏“暴乱”等罕见事件或新场景中事故的样本时,模型应能够在这些情况发生时将其识别为异常情况。先前的研究在跨域问题的定义下探讨这些新情况[3,13,22]。
现有的跨域视频异常检测(VAD)方法[3,13,22,24]依赖无监督技术,因此性能有限,这在我们后文表2和表3的实证评估中有所体现。一种解决办法是在跨域VAD中采用弱监督技术。虽然弱监督方法在单域场景中已显示出良好前景[11, 30, 31],但其在跨域场景中的有效性尚未得到广泛研究。我们在表2和表3中的评估表明,直接使用现有的弱监督方法来应对跨域挑战,即使在性质相似的场景(如监控视频场景)中进行测试,也会导致性能显著下降。我们认为这种性能差距是由以下原因造成的。第一,异常事件本质上缺乏特定模式或预定义结构。因此,异常的定义依赖于上下文,简单沿用以前的方法无法捕捉多个领域中与上下文相关的因素。第二,异常事件相对较少发生,这使得VAD成为一个类别不平衡的问题。在处理多个领域的数据时,这个问题会更加严重。第三,由于弱标记训练数据的数量有限,模型检测新的(开放集)异常的学习能力也受到限制。由于这些挑战,弱监督方法不能轻易应用于跨域或跨数据集的场景。
为了克服这些挑战并开发出通用的视频异常检测(VAD)模型,需要大量的弱标记数据。然而,为大量视频获取哪怕只是视频级别的标签,都是低效且耗费人力的。另一方面,大量未标记的视频通常很容易获取。将有限的弱标记数据与这些丰富的未标记数据结合使用,为解决跨域VAD中的上述挑战提供了一个重要契机。合理利用未标记数据可以深入了解潜在的数据分布,从而改进决策并更好地识别异常事件。
为此,我们提出了一种用于视频异常检测(VAD)的弱监督跨域学习(CDL)框架。该框架将从外部获取的未标记数据与有限的弱标记数据相结合,以实现跨域的泛化能力。这一目标是通过利用估计的预测方差自适应地最小化对外部数据的预测偏差来实现的,预测方差作为不确定性正则化分数。在我们提出的框架中,首先在弱标记数据上训练细粒度的伪标签生成模型,以获得外部数据集的片段级预测结果。其次,计算多个预测器预测结果的方差,以此作为代表外部数据中片段不确定性的指标。第三,在对标记数据和外部数据进行训练的优化过程中,我们使用不确定性正则化分数自适应地重新调整每个外部数据的偏差权重。这种动态加权确保在训练过程中,更接近源数据集的外部数据集片段得到更多关注,而不确定性较高的片段则被降低权重。最后,我们使用在标记数据和伪标记数据上训练的模型迭代地重新生成伪标签,重新估计不确定性,并在标记数据和外部数据集的并集上重新训练模型。随着训练的推进,这个迭代过程有助于优化伪标签。通过这个训练过程,模型仅在源数据的监督下,就能学习对源数据和外部数据进行泛化。图1展示了CDL框架的有效性。
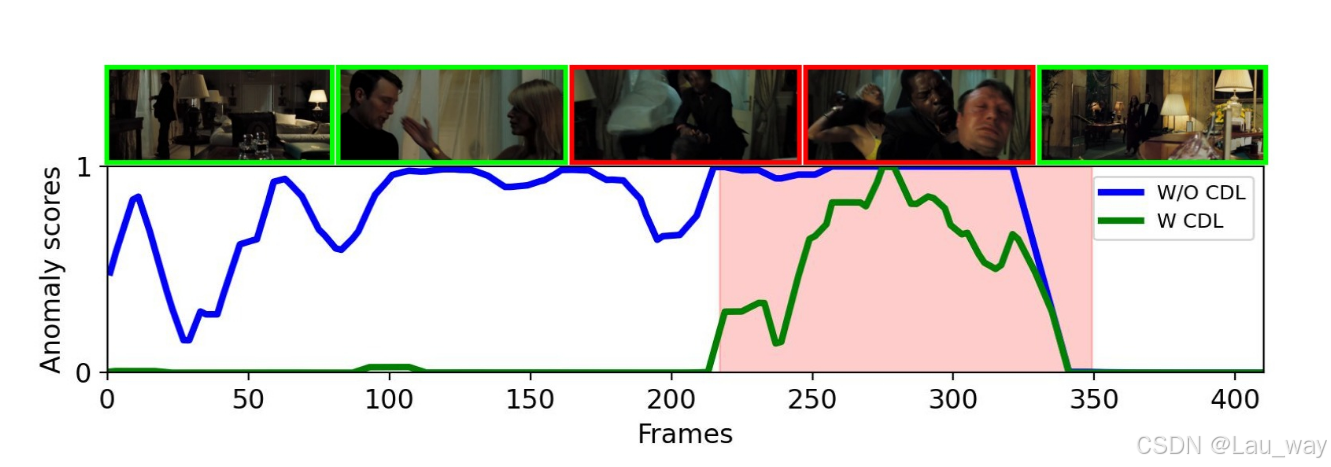
图1:在XD-Violence数据集中某一视频上,使用和未使用所提出的CDL框架的异常分数对比。以UCF-Crime作为弱标记集且未使用CDL进行训练的模型,始终会产生较高的异常分数。相比之下,以UCF-Crime作为弱标记集、HACS作为未标记集并使用CDL进行训练的模型,能够更好地定位异常帧。
综上所述,我们做出了以下贡献:
- 我们提出了一种实用的用于弱监督视频异常检测的跨域学习(CDL)框架,该框架利用外部未标记视频来增强模型的跨域泛化能力。
- 我们设计了一种新颖的不确定性量化方法,该方法能够基于不确定性自适应地将外部视频融入训练集。
- 通过在基准数据集上进行广泛的实验和消融研究,我们验证了所提出的方法。该方法在跨域设置中展现出了最先进的性能,同时在域内数据上也保持了具有竞争力的性能。
2 Related Works
视频异常检测(VAD)。VAD是一个已得到充分研究的问题,大多数研究将其构建为无监督学习[14,20,21,38,41]或弱监督学习[28,30,31,40,45]问题。在无监督设置中,训练数据仅包含正常视频,大多数研究通过帧重建[14,36]、未来帧预测[20]、字典学习[21,41]和一类分类[16,23]等技术对正常模式进行编码。任何偏离编码模式的情况都被视为异常。由于模型将超出其所学表示的任何内容都归类为异常,因此它可能会将训练过程中在不同环境下遇到的新视频动作和场景标记为异常。弱监督VAD方法通过将视频级标签作为模型的弱监督来帮助缓解这些问题,大多数方法使用多实例排序损失[11,30,33,44]。
鉴于视频异常检测(VAD)模型在部署过程中预计会遇到以前未见过的场景,因此模型具有较高的跨域泛化能力至关重要。先前的研究将此称为跨域[3]或跨数据集泛化[9]。我们在表1中概述了现有的在VAD中使用外部数据的研究。以前关于跨域泛化的研究主要集中在基于少样本目标域场景自适应的无监督方法上。[22,24]通过元学习利用目标域的数据来适应特定领域。Aich等人[3]提出了一种零样本目标域自适应方法,该方法结合外部数据生成伪异常帧。尽管这些设置很有趣,但这些无监督的跨域泛化方法缺乏关于异常构成的明确知识,这阻碍了模型学习异常特定特征的能力。为此,我们提出使用弱监督学习进行跨域泛化。我们整合来自不同领域的外部数据集,以使以弱监督方式训练的模型能够实现跨域泛化。
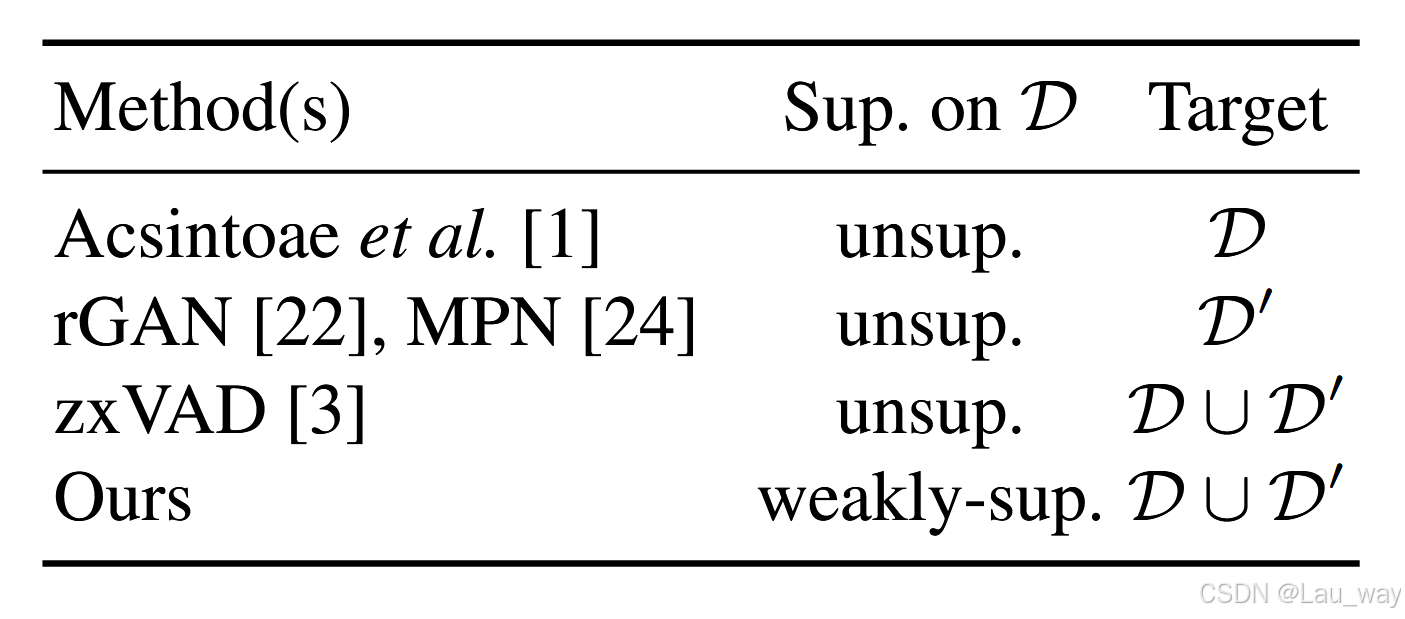
表1:使用源域数据集(\((D)\))和辅助域数据集\((D')\)的当前视频异常检测(VAD)工作分类简要概述。所有这些方法在对\((D')\)进行训练时均不使用任何标签,并且假设\(D\)和\(D'\)具有不同的分布。
伪标记和自训练。伪标记[4, 27]是一种常见技术,即利用在标记数据上训练的模型为未标记数据分配标签。随后,模型会在初始标记数据和伪标记数据上进行训练。这种自训练策略[25, 37]以迭代方式运行,使模型能够逐步提高其泛化能力。在视频异常检测(VAD)领域,有多项研究利用伪标记和自训练来生成细粒度的伪标签[11, 19, 39]。然而,与之前的方法不同,我们不是为弱标记数据生成伪标签,而是利用伪标签来融入外部数据。
不确定性估计 为了解决伪标签噪声问题,此前不同领域的研究探索了多种不确定性估计方法,如数据增强[5, 29]、推理增强[12]和模型增强[43]。虽然数据增强对图像有效,但它会破坏视频帧之间的时间关系,并且对于像视频这样的高基数数据训练效率不高。另一方面,推理增强方法,如蒙特卡洛随机失活(MC Dropout)[12, 39],在模型推理过程中引入扰动以获得略有不同的预测结果,但这对于固定骨干网络的训练效率较低。相比之下,模型增强使用不同的模型。由于不同模型可能具有不同的偏差和感受野,这会导致多样化的预测。这种预测差异有助于量化不确定性,使模型增强与我们的问题非常契合。 为了避免在训练过程中从伪标签学习时进行手动阈值设定,我们遵循[15, 43],使用不确定性值对损失进行自适应重新加权。在[43]中,郑等人通过使用库尔贝克 - 莱布勒散度(Kullback–Leibler,KL散度)估计两个分类器的预测差异来量化不确定性。然而,鉴于视频异常检测(VAD)是一个二分类任务,仅基于后验概率的两种结果计算的散度并不能提供最佳的信息。因此,我们提出一种在高维特征空间而非概率空间中量化不确定性的方法。
3 Method
3.1 Problem Definition
在这项工作中,我们解决了一个实际的视频异常检测(VAD)问题,即有一个弱标记数据集\(D_{l}=\{(X_{l}^{i}, Y_{l}^{i})\}_{i = 1}^{n_{l}}\)和一个外部未标记数据集\(D_{u}=\{X_{u}^{i}\}_{i = 1}^{n_{u}}\)可用于训练。这里,\(n_{l}\)和\(n_{u}\)分别表示两个数据集中视频的数量,由于收集未标记视频数据更为便捷,所以\(n_{u} \gg n_{l}\) 。\(X_{l}\)的视频级标签用\(Y_{l} \in \{0, 1\}\)表示。我们不对\(D_{l}\)和\(D_{u}\)的分布做任何假设,因此,它们可以来自不同的分布。我们旨在找到由\(\theta\)参数化的模型\(F(\cdot | \theta)\),该模型能对弱标记数据做出准确预测,同时利用不确定性正则化分数自适应地最小化对外部数据的预测偏差。我们在图2中展示了所提出的框架。
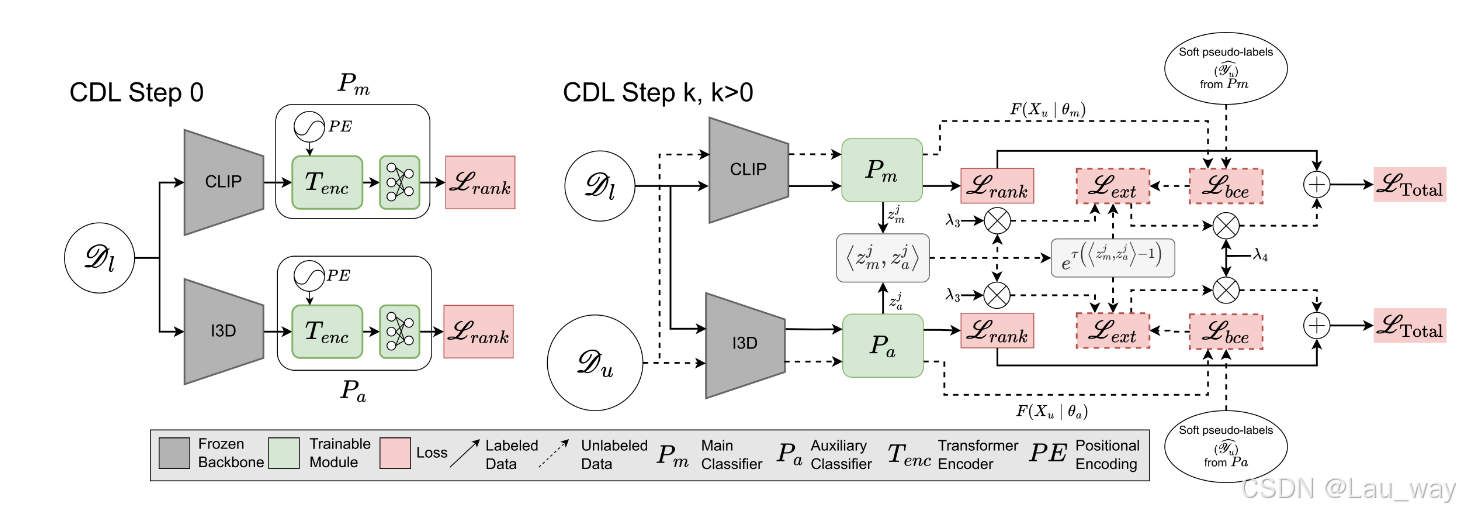
图2:所提出的跨域学习(CDL)框架概述。 CDL步骤0:使用排序损失\(L_{rank}\)(补充材料§6)在弱标记数据\(D_{L}\)上训练两个伪标签生成模型\(P_{m}\)和\(P_{a}\)(§3.2)。 CDL步骤\(k =\) (\(k > 0\)):在\(D_{l} \cup D_{u}\)上迭代训练\(P_{m}\)和\(P_{a}\),并纳入在上一个CDL步骤结束时为\(D_{u}\)生成的伪标签。为处理伪标签中的噪声,使用两个模型预测结果之间的差异来估计不确定性正则化分数(§3.4)。在对\(D_{u}\)进行优化时,使用计算得到的不确定性正则化分数对外部数据的预测偏差\(L_{bee}\)(§3.3)重新加权(§3.5)。
3.2 Feature Extraction and Temporal Processing
所提出的不确定性量化方法(第3.4节)通过比较每个样本的两种不同表示,来估计与外部数据的片段级预测相关的不确定性。为此,我们采用了两种不同的主干网络来从视频中提取特征,这两种主干网络在异常检测任务中被广泛使用。 第一种是传统的I3D主干网络[6],它使用三维卷积来提取片段级特征;另一种是CLIP主干网络[26],它使用已冻结的CLIP模型的ViT编码器来提取帧级特征。基于三维卷积的I3D和基于Transformer的CLIP所具有的不同归纳偏差,有助于有效地捕捉预测方差。 需要注意的是,在推理过程中仅使用CLIP主干网络。我们开发了两个预测头,即构建在CLIP主干网络之上的主模型\(P_{m}\),以及构建在I3D主干网络之上的辅助模型\(P_{a}\)。
视频帧在时间维度上具有高度的相关性。为了减少CLIP主干网络提取的帧级特征中的冗余信息,我们通过双线性插值的方式将这些特征表示聚合到一个根据经验确定的固定长度\(n_s\)。\(n_s\)个插值后的特征中的每一个都代表一个片段。为确保一致性,我们还固定了由I3D主干网络提取的特征表示的长度。第4.6节中的评估分析了\(n_s\)对模型性能的影响。为了捕捉序列上的长程时间信息,我们采用了一个轻量级的时间网络,即Transformer编码器,来实现主模型\(P_m\)和辅助模型\(P_a\)。
3.3 Bias Estimation for External Data
与[43]类似,我们将外部数据的预测偏差表示为:
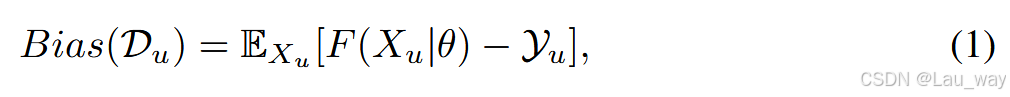
其中\(F(X_{u} | \theta)\)表示一组预测概率分布,每一个分布都对应\(X_{u}\)的一个不同片段,\(y_{u}\)表示\(X_{u}\)未知的片段级标签集合。\(Bias(D_{u})\)可以改写为:
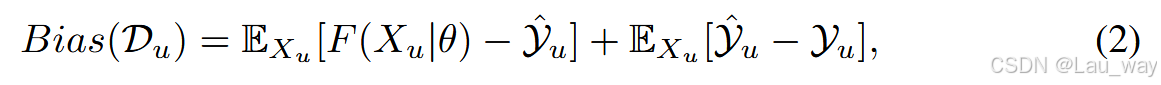
其中\(\hat{Y}_{u}\)表示\(X_{u}\)的片段级伪标签集合。\(\hat{Y}_{u}\)可以通过对在\(D_{l}\)上训练的模型进行推理来生成。公式(2)中的第一项表示预测后验概率与伪标签之间的差异,而第二项表示伪标签与真实标签之间的误差。在最小化预测偏差时,由于缺乏真实标签的监督,我们采用一种自训练机制,将\(\hat{Y}_{u}\)视为软标签,从而将第二项视为一个常数,并最小化第一项。具体来说,我们使用二元交叉熵(BCE)损失\(C_{bce }\),其表达式为:
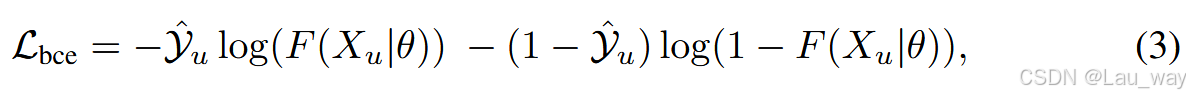
来估计与\(P_{m}\)和\(P_{a}\)的每个视频片段相关的预测偏差。
3.4 Uncertainty Estimation
由于\(D_{u}\)和\(D_{l}\)不一定具有相同的分布,所生成的伪标签存在噪声。这种噪声会对后续的训练过程产生不利影响,因为它会导致偏差在模型中进一步放大和传播。这个问题被称为证实偏差[4],通常可以通过量化与伪标签相关的不确定性,然后将这种不确定性纳入训练过程以补偿噪声来缓解。 正如在第2节中所讨论的,我们选择通过模型增强来计算不确定性,以此解决证实偏差问题。为了通过模型增强来量化不确定性,我们遵循[43]的方法,估计预测方差,其公式表示为:
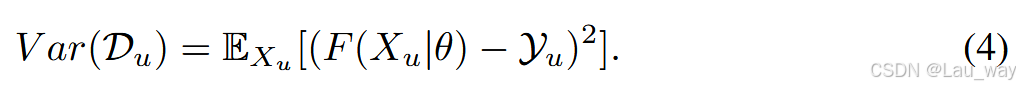
由于缺乏真实标签,公式4可以近似表示为:
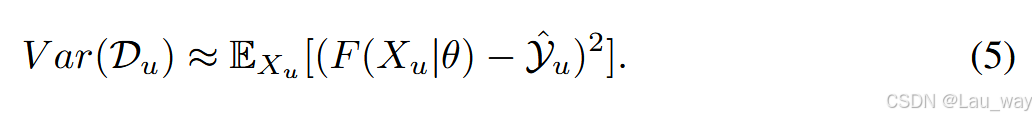
在优化公式(2)中的预测偏差时,公式(5)中的方差也会被最小化,这可能会导致对真实预测方差的量化不准确。为了解决这个问题,我们采用了一种替代的近似方法,表达式如下:
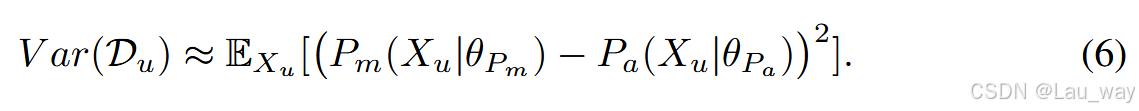
由于视频异常检测(VAD)是一项二分类任务,每个片段对应的概率分布的取值范围有限。因此,像公式(6)中那样仅使用预测的异常分数来估计预测方差,可能不够稳健。所以,我们不测量两个类别的预测后验概率之间的差异,而是提出在高维空间中量化伪标签的不确定性。 为此,我们计算分别从主模型\(P_{m}\)和辅助模型\(P_{a}\)的倒数第二层得到的每一组特征表示\(Z_{m}\)和\(Z_{a}\)中各片段之间的余弦相似度。这里,\(Z_{m}=\{z_{m}^{1}, z_{m}^{2}, \ldots, z_{m}^{n_{s}}\}\)且\(Z_{a}=\{z_{a}^{1}, z_{a}^{2}, \ldots, z_{a}^{n_{s}}\}\) 。
为了从计算得到的余弦相似度中获得一组在有限范围内稳定的片段级不确定性正则化分数,我们引入如下函数。设\(S = \{s^{1}, s^{2}, \ldots, s^{n_{s}}\}\)为一组替代方差,我们将其用作片段不确定性的替代指标。替代方差的计算方式如下:

其中,\(s^{j}\)表示第\(j\)个片段的不确定性正则化分数,\(\left<z_{m}^{j}, z_{a}^{j}\right>\)表示余弦相似度,\(\tau\)表示温度参数。
3.5 Training Process
CDL步骤0:我们首先在标记数据集上分别训练主模型\(P_{m}\)和辅助模型\(P_{a}\),使用补充材料第6节中讨论的排序损失\(L_{rank}\)对这两个模型进行优化。然后,我们对已训练好的模型进行推理,以生成用于在未标记数据集\(D_{u}\)上进行训练的软片段级伪标签集合。
CDL step大于0:在为未标记数据集\(D_{u}\)生成了伪标签集合之后,我们进入一个迭代的伪标签优化阶段。在这个阶段中,我们在标记数据集\(D_{l}\)和未标记数据集\(D_{u}\)的并集\(D_{l} \cup D_{u}\)上对主模型\(P_{m}\)和辅助模型\(P_{a}\)进行多个CDL步骤的训练。每个CDL步骤包含固定数量的训练轮次(epoch)。在每一轮训练中,我们重新生成片段级不确定性正则化分数的集合。 为了实现由不确定性驱动的对外部数据的学习,与[43]类似,我们将估计得到的不确定性正则化分数集合\(S\)用作自动阈值。这是因为这样可以根据\(S\)对与外部数据相关的预测偏差进行缩放,从而动态地调整从含噪标签中进行的学习。这有助于过滤掉不可靠的预测,同时优先处理可信度高的预测。 为了促使预测方差降低(这反过来又会提高伪标签的质量),我们明确地将预测方差添加到与外部数据相对应的优化目标\(L_{ext}\)中,如下所示:
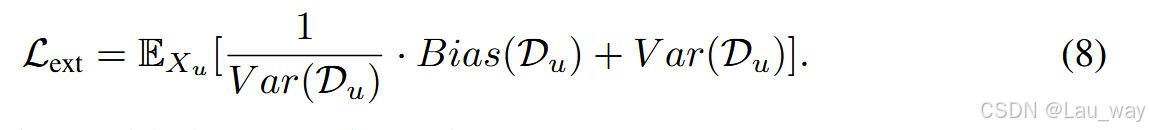
公式8用近似项改写为:
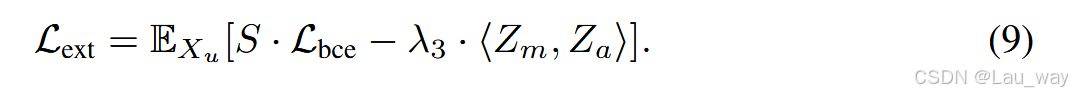
或者,公式9可以改写为:
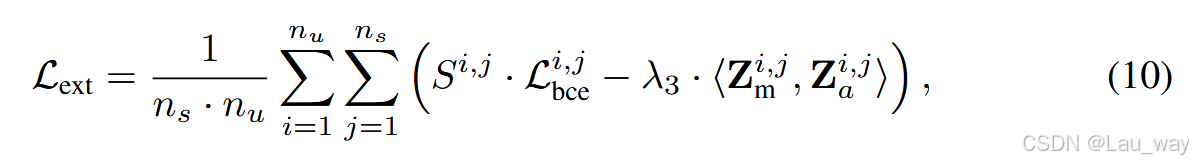
其中,\(\lambda_{3}\)是一个用于平衡损失的超参数。与CDL步骤0类似,为了优化在\(D_{l}\)上的训练,我们使用\(L_{rank }\)。在\(D_{l} \cup D_{u}\)上进行训练的总优化目标可以表示为:

其中,\(\lambda_{4}\)是\(\mathcal{L}_{ext }\)的一个权衡参数。在每个CDL步骤的每个训练轮次中,当在\(D_{l} \cup D_{u}\)上进行训练时,我们采用公式11中定义的优化目标。在每个CDL步骤完成后,我们使用在\(D_{l} \cup D_{u}\)上训练的模型重新生成软片段级伪标签集合。这个迭代优化过程重复\(k\)次,其中\(k\)是一个决定CDL步骤数量的超参数。随着每个CDL步骤的进行,由于伪标签不断迭代改进,模型的性能也会得到进一步提升。
3.6 Inference - Extending Segment-level Scores to Frame-level Scores
在推理过程中,我们使用主模型\(P_{m}\)来计算视频的片段级异常分数。由于我们会遇到帧数各不相同的未剪辑长视频,为了将片段级异常分数扩展到帧级别,对于每个视频,我们将总帧数\(n_{f}\)除以片段数\(n_{s}\),从而得到每个片段的帧数\(n_{fs}\)。我们将每个片段的异常分数分配给与其连续的帧。第一个片段对应前\(n_{fs}\)帧,依此类推,直到第\((n_{s}-1)\)个片段。对于最后一个片段,如果存在余数,其异常分数将被分配给剩余的所有帧,这些剩余帧的数量可能会超过\(n_{fs}\)。
4 Experiments
我们在主要的视频异常检测数据集,即UCF-Crime(UCF)[30]和XD-Violence(XDV)[35]上对所提出的方法进行了评估。此外,我们使用了来自HACS[42]数据集的11000个视频作为外部数据来源。我们在补充材料的第7节中提供了有关这些数据集的详细信息。在第4.1节中,我们讨论了实现细节。在第4.2节中,我们探讨了基准数据集测试标注中存在的固有噪声。接着,我们在跨域场景(第4.3.1节)和开放集场景(第4.3.2节)中,将所提出的框架与先前的研究成果进行了比较。随后,在第4.4节中,我们展示了伪标签的质量与计算出的不确定性分数之间存在很强的相关性。然后,在第4.5节中,我们通过训练过程探究了这些不确定性分数的变化情况。最后,在第4.6节中,我们进行了消融实验和超参数分析,以分析所提出框架中各个组件的影响。
4.1 Implementation Details
我们使用PyTorch实现了所提出的方法。我们以固定的30帧每秒(FPS)的帧率提取CLIP和I3D特征。CLIP特征是从已冻结的CLIP模型的图像编码器(ViT-B/32)中提取的。 对于超参数,在开放集场景中,我们根据经验将\(n_{s}\)的值设置为64,\(T\)设置为1.25,\(\lambda_{1}\)和\(\lambda_{2}\)设置为\(5\times10^{-4}\),\(\lambda_{3}\)设置为\(1\times10^{-3}\),\(\lambda_{4}\)设置为700。第4.6节中包含了对\(n_{s}\)和\(\lambda_{3}\)选择的消融实验。 我们使用权重衰减为\(1\times10^{-3}\)的Adam优化器,并且将Transformer编码器的学习率设置为\(3\times10^{-5}\),全连接层的学习率设置为\(5\times10^{-4}\)。我们使用的批量大小为64。 在主模型\(P_{m}\)和辅助模型\(P_{a}\)中,我们都使用正弦位置编码[32]在片段中显式地编码位置信息。我们在弱标记的源数据集上训练200个轮次,然后在弱标记数据集和外部数据集的并集上进行40个CDL步骤的训练,每个CDL步骤包含4个轮次。关于超参数的更多信息在补充材料的第8节“模型架构”中提供。 模型架构:主模型\(P_{m}\)和辅助模型\(P_{a}\)都由一个具有四个头的Transformer编码器层组成,后面接着四个全连接层,每层分别由4096、512、32和1个神经元组成。在这两个模型中,除了最后一层之外的所有层,我们都使用ReLU[2]激活函数,而最后一层则使用Sigmoid激活函数。 评估设置:为了减少偏差,我们使用不同的随机种子将每个实验进行三次,并对结果取平均值。在开放集实验中,我们将每个实验重复三次,每次使用不同的异常类别集合。 评估指标:遵循先前关于UCF-Crime[30]的研究工作,我们采用帧级别的受试者工作特征曲线下面积(AUC)来对UCF-Crime进行评估。与先前关于XD-Violence[35]的研究一致,我们使用帧级别的精确率-召回率曲线下面积(PRAUC),也称为平均精度(AP),来对XD-Violence进行评估。
4.2 Noise in the Test Annotations of Benchmark Datasets
我们的人工检查发现,常用于视频异常检测(VAD)模型基准测试的UCF-Crime(UCF)[30]和XD-Violence(XDV)[35]数据集的帧级测试标注存在显著的噪声。这种噪声在很大程度上源于这样一个事实,即原始标注并没有始终如一地将主要异常事件发生前的帧以及后续结果的帧标注为异常帧。 例如,在一个被标注为“枪击”的视频中,我们认为展示持枪者的帧以及展示受伤受害者的帧也应该被标记为异常帧。这一观点与视频异常检测的基本目标一致,即识别视频中的所有异常帧,而不考虑视频的主要标签是什么。 然而,也应该注意到,在原始标注中,对于一些视频,某些与视频主要异常标签相关的帧也没有被标记为异常帧。
为了解决这个问题,我们对UCF-Crime测试集进行了重新标注,将每个视频交给三位独立的标注员进行标注。然后,我们综合他们的标注结果,以生成更准确的帧级标签。与原始标注相比(在原始标注中,总帧数的7.58%被标注为异常),我们提出的标注方法将总帧数的16.55%标注为异常。我们提出的标注结果可在此处获取[3] 。我们在此处[4]对我们提出的标注结果和原始标注结果进行了比较。在本文接下来的内容中,我们将UCF-Crime数据集的重新标注后的测试集称为UCF-R。
4.3 Comparison with Prior Works
4.3.1 Cross-Domain Scenarios
虽然UCF-Crime[30]和XD-Violence[35]数据集对于什么构成异常有着相似的定义,但这种定义与诸如上海科技大学(ShanghaiTech)[20]、香港中文大学-大道(CUHK-Avenue)[21]、加州大学圣地亚哥分校行人(UCSD Pedestrian)[7]、UBnormal[1]等较小的数据集的定义有所不同,在这些较小的数据集中,异常情况更为细微。例如,在UBnormal数据集中,奔跑被视为异常行为,而在XD-Violence数据集中则不然。 由于不同数据集之间对于异常的概念存在差异,考虑到UCF-Crime和XD-Violence数据集在异常定义上更为一致,我们通过同时在这两个数据集上进行评估来开展跨域实验。
将UCF-Crime作为弱标记源数据集,XD-Violence作为跨域数据集。表2总结了这种情况下的结果。首先,我们注意到,即使不使用任何外部数据(不采用跨域学习(CDL)),所提出的方法在XD-Violence数据集和重新标注后的UCF(UCF-R)数据集上也取得了领先的成果。我们认为这是因为先前的方法对UCF-Crime数据集中含噪的标注存在归纳偏差。接下来,我们观察到,与先前的最优基线模型相比,加入外部数据集HACS和XD-Violence后,跨域数据集XD-Violence上的性能分别显著提升了11.26%和14.49%。此外,在整合外部数据集后,源数据集上的性能也有了些许提升。
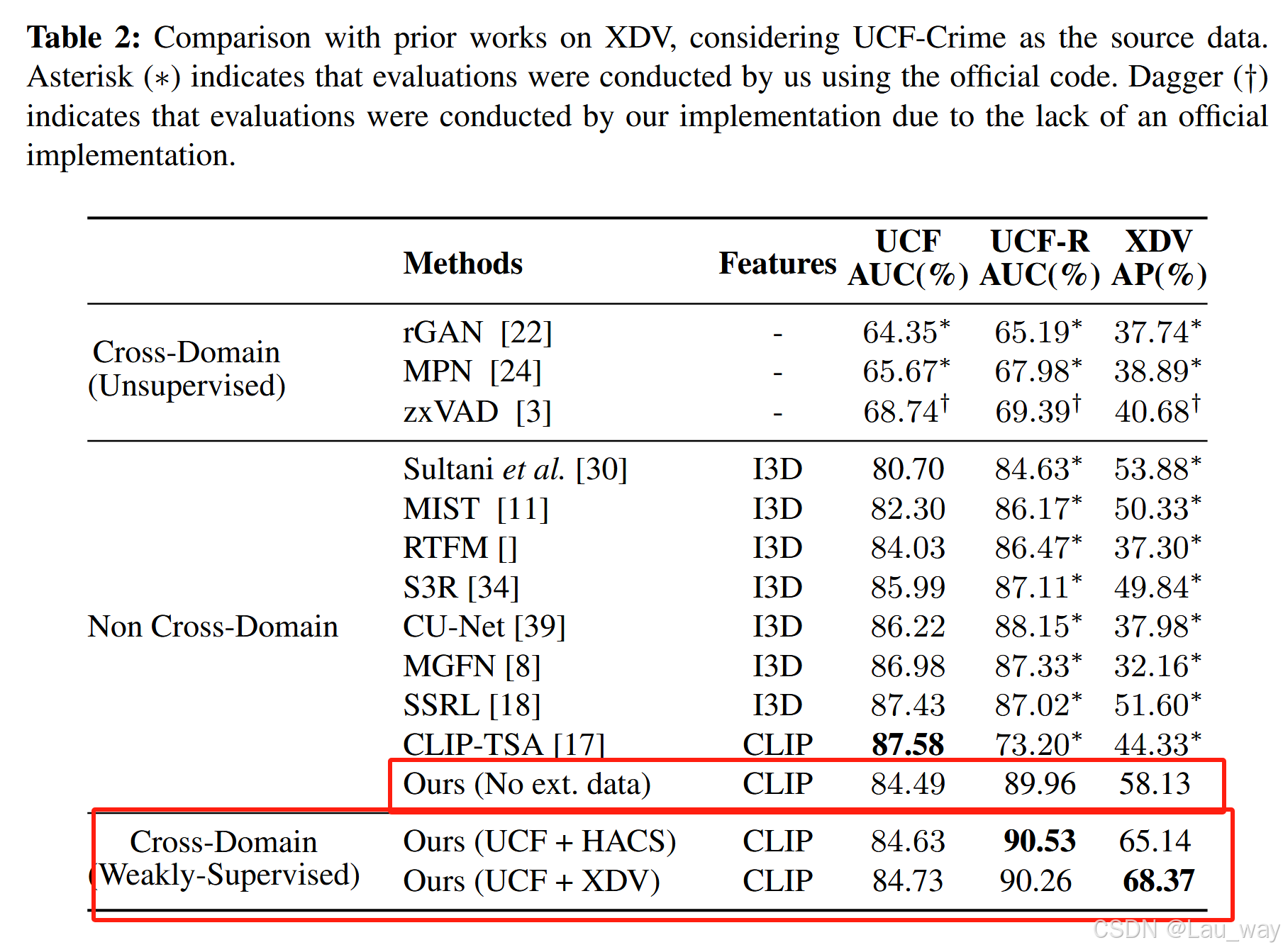
将XD-Violence作为弱标记源数据集,UCF-Crime作为跨域数据集。表3总结了这种情况下的结果。值得注意的是,即使在训练过程中不使用任何外部数据,所提出的方法在跨域数据集UCF-R上也取得了领先的性能表现。这归因于与其他基线模型相比,所提出的架构更为简单。所提出的架构避免了对源数据集的过拟合,从而提高了其对跨域数据集的泛化能力。此外,整合外部数据进一步提升了在跨域数据集和源数据集上的性能。具体而言,与先前的最优基线模型相比,利用以UCF-Crime和HACS作为外部数据集的跨域学习(CDL)框架,使UCF-R的受试者工作特征曲线下面积(AUC)分别提升了18.94%和19.39%。我们还发现,所提出的方法在XD-Violence数据集上的性能较差。我们认为这是由于XD-Violence测试集的标注存在噪声。
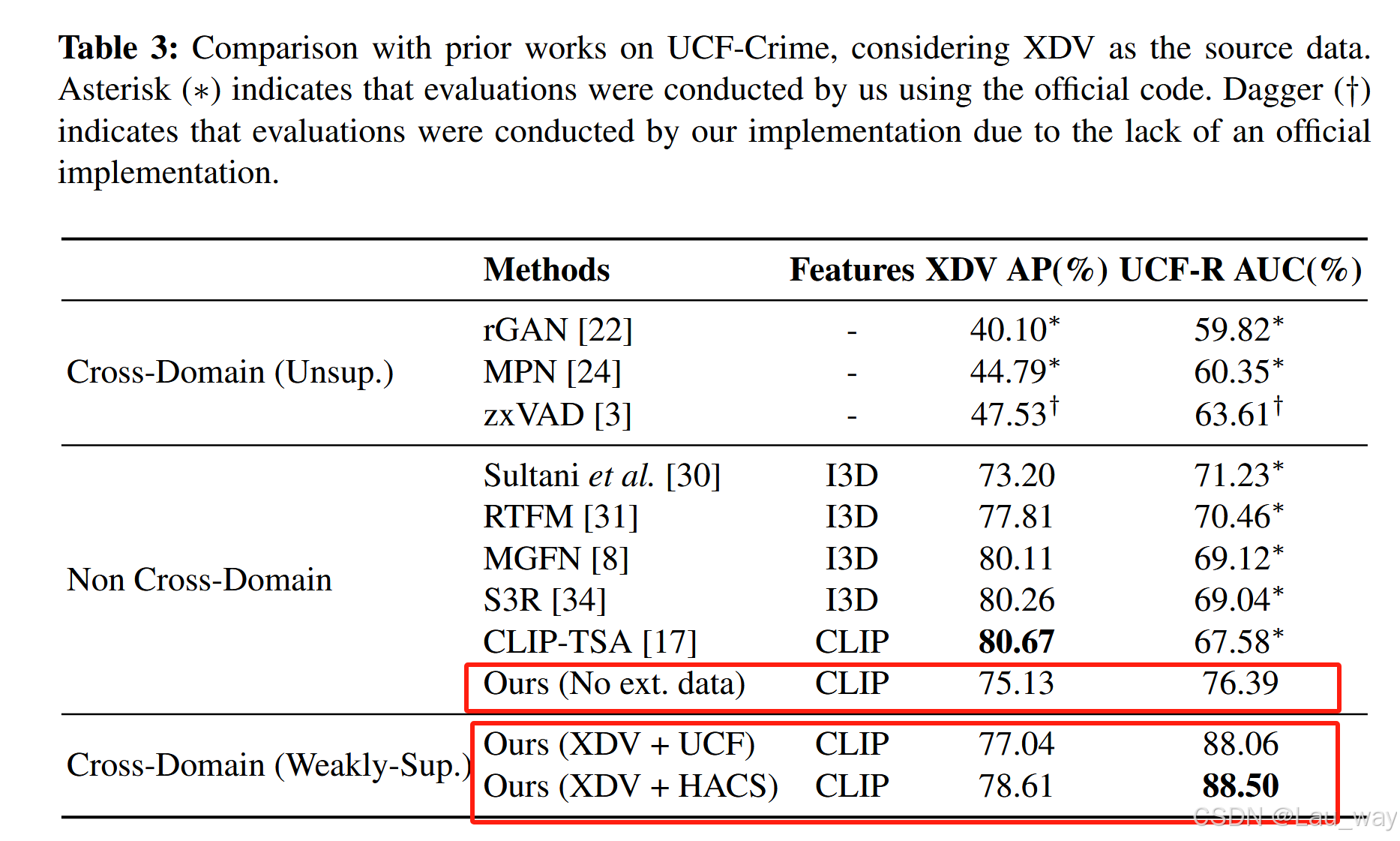
这些结果表明,所提出的跨域学习(CDL)框架能够有效地利用存在巨大领域差异的外部数据,从而实现显著的跨域泛化能力。值得注意的是,在所测试的所有数据集中,使用该CDL框架所观察到的性能提升是一致的,这表明性能的提升并不依赖于任何特定的源数据集或外部数据集。
4.3.2 Open-Set Scenarios
在表4中,我们评估了所提出的框架在现实的开放集场景下在UCF-Crime数据集上的性能,在这种场景下,模型会在之前见过的和未见过的异常类别上都进行评估。为了模拟这种场景,我们随机将\(c\)个异常类别纳入弱标记数据集中,而将其余的异常类别放入未标记数据集中。在弱监督源数据集和未标记数据集中,正常视频的数量与异常视频的数量相等。我们评估了两种模型配置;一种是仅在弱标记数据集上训练的模型(不使用跨域学习(CDL)),另一种是使用跨域学习框架在弱标记数据集和未标记数据集的并集上进行训练的模型。
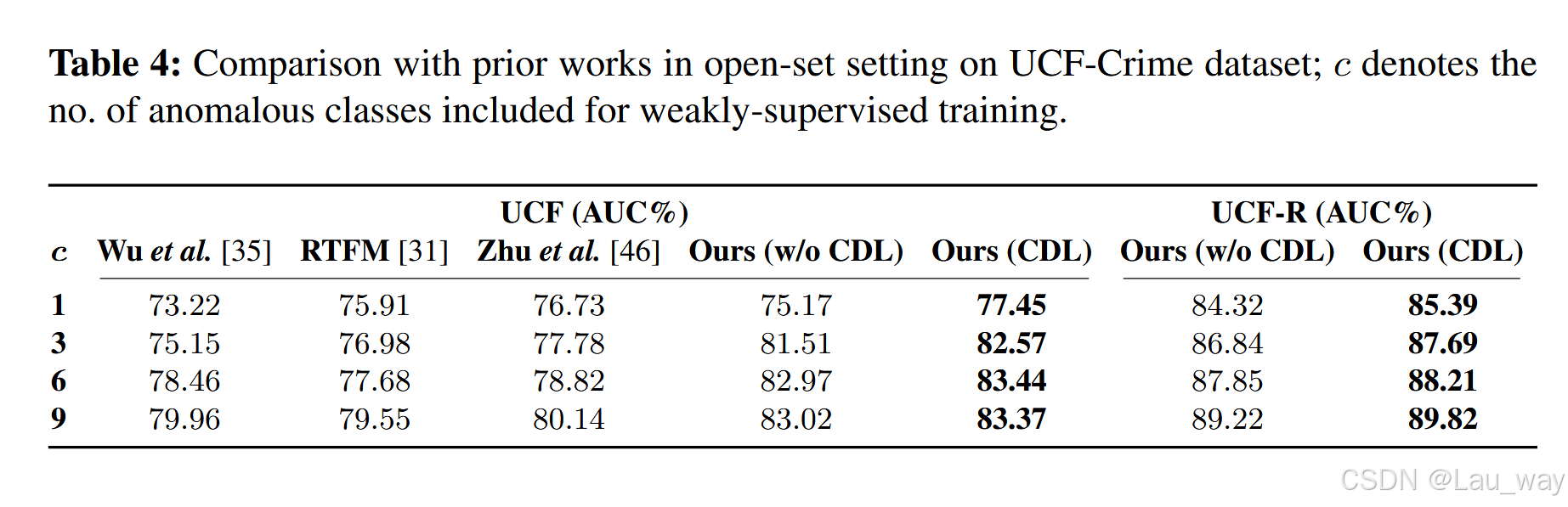
在UCF-Crime数据集上,对于\(c>1\) 的情况,所提出的不使用跨域学习(CDL)的模型超越了当前最先进的基线模型。这凸显了该模型在开放集设置下的有效性。而当使用跨域学习(CDL)时,该模型在\(c\)的所有取值情况下,都以相当大的优势超越了基线模型。
对于UCF-Crime数据集和重新标注后的UCF-R数据集而言,当纳入未标注数据时,我们观察到在\(c\)的所有取值情况下,性能都有持续的提升。这表明跨域学习(CDL)框架在不同数量的弱标注数据和未标注数据的情况下都能发挥出有效性。
4.4 Correlation between Uncertainty Scores and BCE Loss (Proxy to Label Quality)
4.5 Progression of Uncertainty Scores
4.6 Ablation Studies and Hyper-parameter Analysis
5 Conclusion
在这项工作中,我们展示了将外部未标记数据与弱标记的源数据相结合,以增强视频异常检测(VAD)模型跨域泛化能力的有效性。为了实现这种数据整合,我们提出了一种弱监督的跨域学习(CDL)框架,该框架通过利用作为不确定性正则化分数的预测方差对预测偏差进行缩放,从而自适应地最小化模型对外部数据的预测偏差。所提出的方法在跨域和开放集设置下显著优于基线模型,同时在域内设置中也保持着具有竞争力的性能。
感觉有点看不太懂,过程写的不是很清晰。重新标注测试集是我没想到的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









