







中文标题:Holmes-VAU:迈向任意粒度的长期视频异常理解
类型:VAU
发布于: CVPR2025
论文地址:[2412.06171] Holmes-VAU: Towards Long-term Video Anomaly Understanding at Any Granularity
Abstract
我们如何让模型理解在不同时间尺度和情境下发生的视频异常情况呢?传统的视频异常理解(VAU)方法主要侧重于帧级别的异常预测,往往无法解释复杂多样的现实世界中的异常情况。最近的多模态方法利用了视觉和文本数据,但缺乏能够捕捉短期和长期异常的分层注释。为了应对这一挑战,我们引入了HIVAU-70k,这是一个大规模的基准数据集,用于任意粒度的分层视频异常理解。 我们开发了一种半自动化的注释引擎,通过将手动视频分割与使用大语言模型(LLMs)进行递归自由文本注释相结合,有效地扩展了高质量注释的规模。这产生了超过70,000条多粒度注释,这些注释被组织在剪辑级别、事件级别和视频级别。为了在长视频中高效地检测异常,我们提出了异常聚焦时间采样器(ATS)。ATS将异常评分器与密度感知采样器相结合,根据异常分数自适应地选择帧,确保多模态大语言模型专注于异常丰富的区域,这显著提高了效率和准确性。 大量实验表明,我们的分层指令数据显著提高了对异常的理解。集成了ATS的视觉语言模型在处理长视频方面优于传统方法。我们的基准数据集和模型可在https://github.com/pipixin321/HolmesVAU上公开获取。
1. Introduction
视频异常理解(VAU)在诸如视频监控[46]、暴力内容分析[56]和自动驾驶[63]等应用中至关重要。检测与正常模式的偏差有助于预防危险和进行实时决策。传统方法[14, 49, 74]主要侧重于帧级别的预定义封闭集异常预测,为每一帧分配一个异常分数。然而,这些方法往往无法描述和理解现实世界中的复杂异常情况。
为了弥补这一差距,开放世界异常理解[57]涵盖了现实世界中异常情况的多样性和不可预测性。最近的研究整合了多模态方法,将视觉数据与文本描述相结合[42, 58, 62, 65],而多模态视觉语言模型(VLMs)[6, 21, 27, 29, 68]的进展则通过与异常相关的指令调整和文本生成,实现了更细致入微的理解[9, 36, 47, 67]。
尽管取得了这些进展,但模型在理解跨多个时间尺度的异常方面仍存在显著差距。例如,像爆炸或打斗这类异常情况可能在单帧中就能捕捉到,然而像盗窃或纵火这类更复杂的事件,则需要理解长期的上下文模式。现有的视频异常理解(VAU)数据集[46, 56]通常仅在单一粒度级别上提供注释,这限制了模型,使其只能理解即时感知到的异常,或者是那些需要进行扩展上下文推理的异常。缺乏包含短期和长期异常的分层注释数据集,阻碍了模型对具有不同时间特征的异常进行推理的能力。此外,构建包含这种分层复杂性的数据集在可扩展性和注释质量方面面临重大挑战。
为了解决这些问题,我们开发了一种半自动化注释引擎,通过将手动视频分割与利用大语言模型(LLMs)进行的递归自由文本注释相结合,高效地扩展高质量注释的规模。这个过程包含三个关键阶段: 1. 分层视频解耦:我们手动识别异常事件,并将其分割成更短的片段。 2. 分层自由文本注释:每个片段的字幕通过人工编写或视频字幕生成模型产生,然后利用大语言模型在事件和视频层面进行总结。 3. 分层指令构建:通过将字幕、总结与预设提示相结合,把文本数据转化为问答指令提示,从而创建一个带有丰富注释的数据集,用于训练和评估模型。
利用该注释引擎,我们推出了HIVAU70k,这是一个带有分层指令的大规模视频异常理解基准数据集。如图1所示,我们的数据集包含超过70,000条多粒度指令数据,这些数据被组织在剪辑级、事件级和视频级片段中。这种分层结构使模型能够检测即时异常情况,例如突然的爆炸或打斗,以及需要理解长期上下文的复杂事件,如盗窃或纵火。通过在多个时间级别进行注释,HIVAU - 70k在开放世界场景中提供了多样化的异常情况。
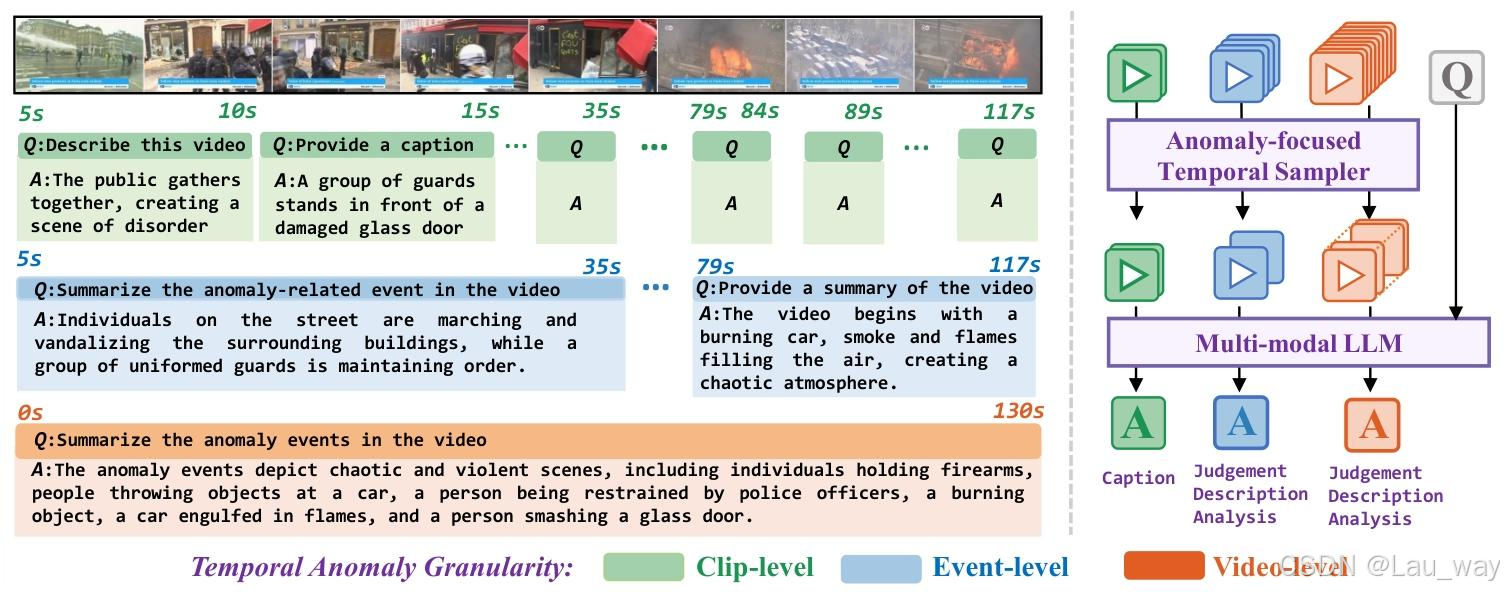
图1. 研究动机。左图:现有数据集缺乏层次结构,无法捕捉不同时间尺度上的瞬时和持续异常。我们的HIVAU-70k数据集通过提供剪辑级、事件级和视频级的多粒度注释解决了这一问题,这些注释能够在复杂的现实场景中进行详细的异常分析。右图:受夏洛克·福尔摩斯专注关键细节能力的启发,我们的Holmes-VAU方法将异常聚焦时间采样器与多模态大语言模型相结合,引导模型关注富含异常的片段,从而使模型能够高效地解读复杂的长期视频异常。
在实现长期视频异常理解(VAU)的过程中,效率仍是一个关键挑战。以往的方法[9, 47, 67]通常依赖均匀的帧采样,这可能会错过关键的异常帧,或者产生高昂的计算成本[25, 47, 67]。为了解决这个问题,我们提出了Holmes-VAU方法,该方法将所提出的异常聚焦时间采样器(ATS)与多模态视觉语言模型相结合,以实现高效的长期视频异常理解(见图1)。ATS将异常评分器与密度感知采样器相结合,根据异常分数自适应地选择帧。这种结合确保了视觉语言模型专注于异常丰富的区域,从而提高了效率和准确性。
我们的贡献主要体现在三个方面: 1. 我们引入了HIVAU-70k,这是一个大规模、多粒度的分层视频异常理解基准数据集。 2. 我们提出了Holmes-VAU方法,该方法结合了所提出的异常聚焦时间采样器(ATS),提高了对长视频进行推理的效率和准确性。 3. 我们进行了大量实验,证明了分层指令数据在增强异常理解方面的有效性,并验证了集成ATS和视觉语言模型在处理长视频时的性能提升。
2. Related Works
3. HIVAU-70k Benchmark
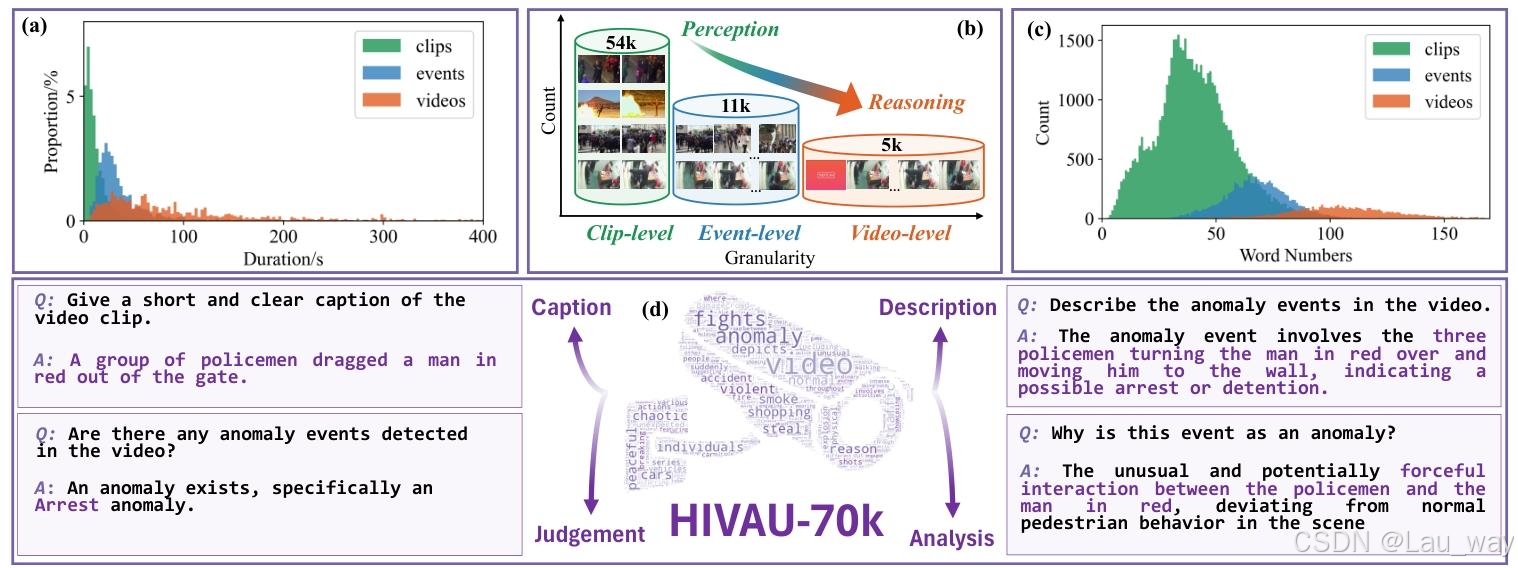
图3. HIVAU-70k数据集。(a)剪辑、事件和完整视频的时长分布,显示出短剪辑占主导地位。(b)从剪辑级别到视频级别的分层数据组织方式,有助于从感知到推理的深入理解。(c)不同注释级别下的单词数量变化情况,在视频级别有着更详细的描述。(d)示例注释涵盖了字幕说明、判断、描述以及异常分析,突出了对复杂场景中异常事件的细致理解。
4. Method: Holmes-VAU
使用大语言模型(LLMs)/视觉语言模型(VLMs)进行长期视频异常理解,传统上一直受到帧冗余的阻碍,这使得准确的异常检测变得复杂。以往的视频异常理解(VAU)方法在聚焦方面存在困难:像密集窗口采样[67]这样的方法会增加冗余,而均匀帧采样[9, 47]往往会遗漏关键异常,这将其应用限制在了短视频上。为了解决这个问题,我们引入了异常聚焦时间采样器(ATS),将其集成到视觉语言模型中,并通过在HIVAU - 70k数据集上进行指令微调,形成了我们的Holmes - VAU模型。
4.1. Pipeline Overview
视觉和文本嵌入。我们使用来自InternVL2[6]中冻结的视觉编码器,它继承了CLIP[44]的ViT结构,我们将其记为。遵循先前视频异常理解(VAU)的研究[55, 58, 67, 74],我们从输入视频中以16帧为间隔对密集的视频帧进行采样。然后,每个视频帧都通过视觉编码器进行处理,以获得相应的视觉标记。给定输入视频帧序列
,第i帧的输出特征可以表示为
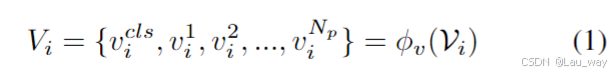
其中表示类别标记,
表示补丁标记,
代表补丁的数量。文本编码器
同样是根据文献[6]进行初始化的,它包含一个分词器和一个嵌入层。提示文本Q通过文本编码器被转换为文本标记:
。
异常聚焦时间采样器(ATS)。ATS由两个组件构成:异常评分器和密度感知采样器。异常评分器是一个基于特征的视频异常检测(VAD)网络,用于估计每一帧的异常分数。由于文献[74]中的网络架构简单且性能良好,我们采用了该架构。根据视频帧的类别标记
,可以得到异常分数:
,其中
表示第i帧的异常分数。
异常帧通常比正常帧包含更多信息,且变化更大[49]。这一观察结果促使我们在异常分数较高的区域采样更多帧,同时减少在异常分数较低区域的采样。如图4所示,为了实现非均匀采样,我们提出了密度感知采样器,从总共T个输入帧中选择性地选择N帧。具体来说,我们将异常分数视为概率质量函数,并首先沿时间维度对其进行累加,以获得累积分布函数,表示为
:
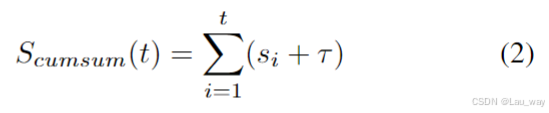
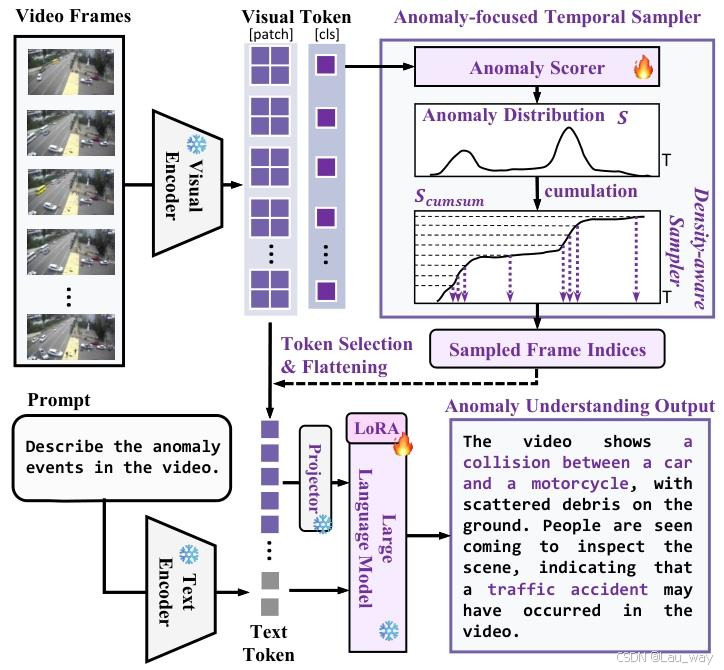
图4. Holmes-VAU:一种基于多模态大语言模型的视频异常检测框架,具有自适应异常聚焦功能。
我们在累积轴上均匀采样N个点,然后将这些点映射到累积分布上,时间轴上对应的N个时间戳被映射到最接近的帧索引,最终形成采样帧索引,记为G。
用于控制采样的均匀性。
投影器和大语言模型。我们选择与采样帧(即G)对应的标记作为视觉嵌入。然后使用投影器将视觉嵌入映射到语言特征空间。最后,我们将这些嵌入与文本嵌入连接起来,输入到预训练的大语言模型中,并计算目标答案
的概率。为了获得初始的视觉 - 语言对齐空间,我们根据文献[6]初始化投影器和大语言模型的参数,并将这些参数冻结。上述过程可以表示如下:
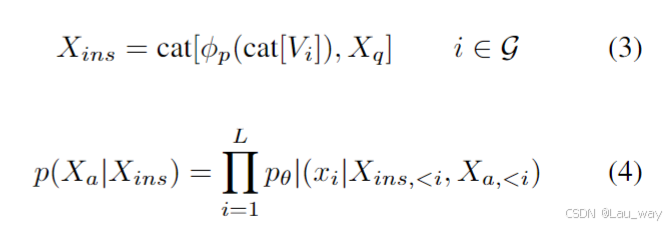
其中,cat[·] 表示拼接操作,θ 是可训练参数,、
分别是在当前预测标记
之前所有轮次中的指令标记和答案标记,L是序列长度。
4.3. Training and Testing
训练。我们分两步来训练模型。第一步,我们使用来自HIVAU-70k的视频数据以及标注的帧级标签()来训练异常评分器。与之前的无监督和弱监督方法[14, 46, 55, 74]相比,这种方式能提供更准确的异常监督。
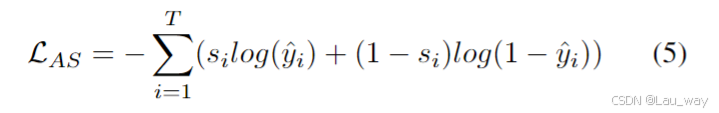
第二步,我们固定异常评分器,然后使用来自HIVAU-70k的所有指令数据来训练模型。为了在不破坏大语言模型原有能力的前提下实现更高效的微调,我们采用低秩适应(LoRA)方法[15]进行微调,优化预测标记与真实标记之间的交叉熵损失。
测试。在测试过程中,用户输入一段视频和文本提示;模型将根据用户的指令生成相应的文本回复。
5. Experiments
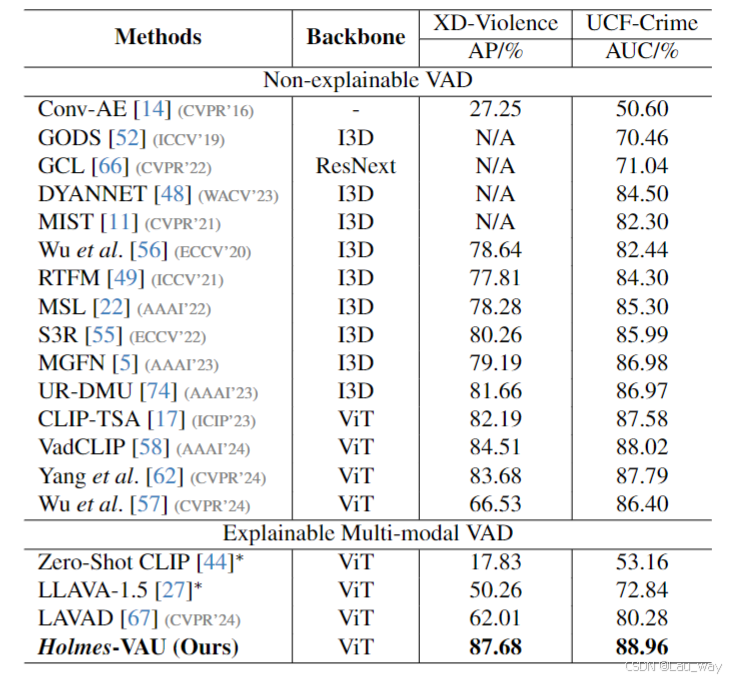
表1. 与最先进的视频异常检测方法在检测性能方面的比较。我们纳入了可解释方法和不可解释方法的结果。“∗”表示文献[67]中所报告的结果。
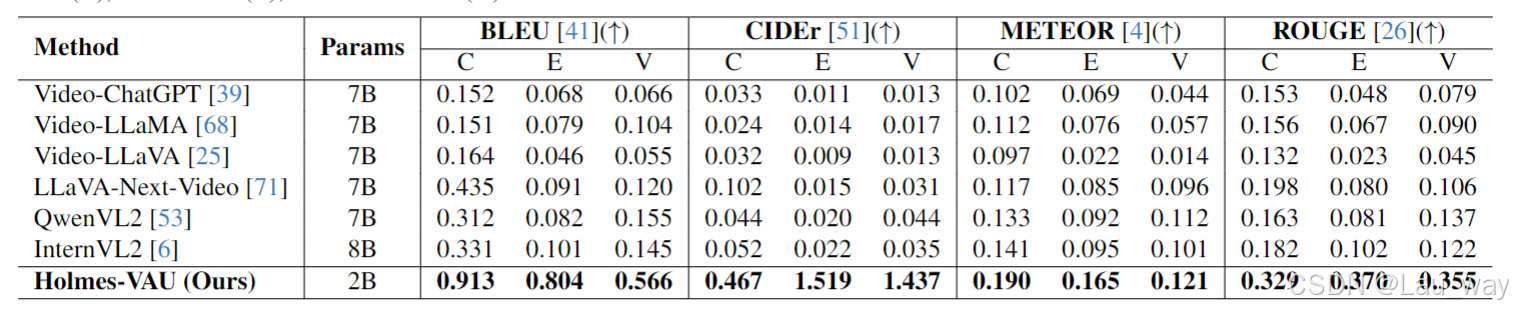
表2. 与最先进的多模态大语言模型(MLLMs)在推理性能方面的比较。“BLEU”指的是从BLEU-1到BLEU-4的累计值。我们在不同的粒度级别上评估生成文本的质量,这些粒度级别包括剪辑级别(C)、事件级别(E)和视频级别(V)。
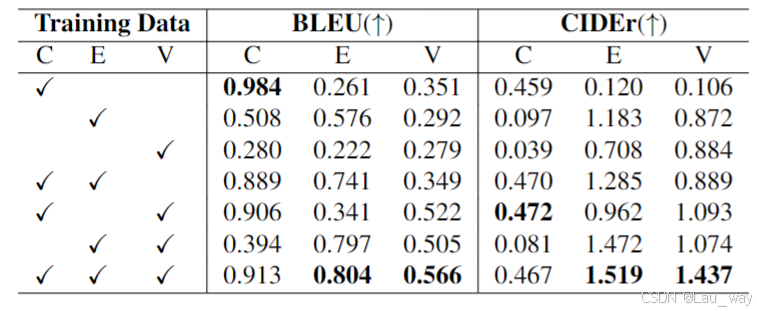
表3. 分层指令数据的消融实验。在指令微调阶段,我们将不同粒度的训练数据进行了组合,这些粒度包括剪辑(C)级别、事件(E)级别和视频(V)级别。
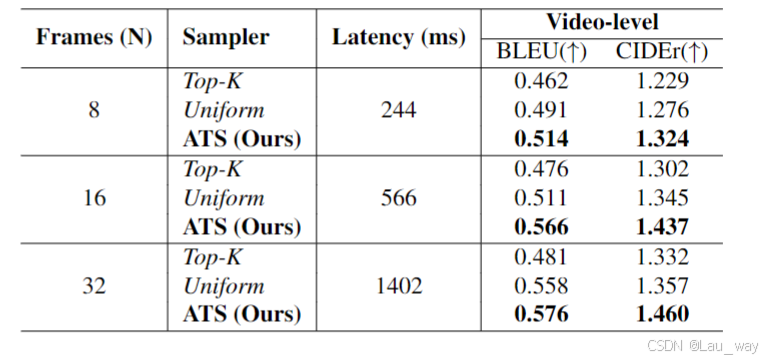
表4. 采样方法和采样帧数的消融研究。我们将所提出的异常聚焦时间采样器(ATS)与其他采样方法在不同的帧采样数量下进行比较,这些采样方法包括均匀采样(Uniform)和前K采样(Top-K)。延迟(Latency)是指生成第一个标记时的时间延迟。

图5. 异常理解解释的定性比较。与最先进的通用多模态大语言模型,即InternVL2[6]和QwenVL2[53]相比,我们提出的Holmes-VAU展现出了更准确的异常判断,以及更详细、全面的与异常相关的描述和分析。正确和错误的解释分别用绿色和红色标出。
6. Conclusion
总之,这项工作通过引入从瞬时剪辑到长时间事件等不同时间尺度的分层异常检测,拓展了视频异常理解的边界。拥有超过70,000条多级注释的HIVAU-70k基准数据集,填补了该领域的一个关键空白,能够在现实场景中进行全面的异常分析。我们的异常聚焦时间采样器(ATS)从策略上加强了对异常密集片段的关注,在长期异常检测中优化了效率和准确性。大量实验表明,我们的分层数据集和经ATS增强的视觉语言模型相较于传统方法取得了显著的性能提升,证明了其在开放世界异常理解方面的稳健性。这项工作为多粒度异常理解设定了新的标准,为实现更精细的视频异常理解铺平了道路。

















 3645
3645

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









