







UCF-Crime-DVS:一种用于基于脉冲神经网络的视频异常检测的新型事件驱动数据集
AAAI2025
https://github.com/YBQian-Roy/UCF-Crime-DVS
Abstract
视频异常检测在智能监控系统中发挥着重要作用。为了提高模型的异常识别能力,以往的研究通常涉及RGB、光流和文本特征。最近,动态视觉传感器(DVS)作为一项有前景的技术崭露头角,它将视觉信息捕捉为离散事件,具有极高的动态范围和时间分辨率。与传统相机相比,它减少了数据冗余,增强了对移动物体的捕捉能力。为了将这种丰富的动态信息引入监控领域,我们创建了首个DVS视频异常检测基准数据集,即UCF-Crime-DVS。为了充分利用这种新的数据模态,我们基于脉冲神经网络(SNNs)设计了一种多尺度脉冲融合网络(MSF)。这项工作探索了事件数据中的动态信息在视频异常检测中的潜在应用。我们的实验证明了我们的框架在UCF-Crime-DVS数据集上的有效性,以及与其他模型相比其优越的性能,为基于SNN的弱监督视频异常检测建立了新的基线。
Dataset and Code —
https://github.com/YBQian-Roy/UCF-Crime-DVS
Introduction
视频异常检测(VAD)是计算机视觉和机器学习领域的一个关键研究方向,在智能视频监控系统中发挥着重要作用(Zhou、Yu和Yang,2023年)。对于视频异常检测任务而言,内容丰富的数据集能有效地评估算法和模型的优缺点。基准数据集有助于界定可解决问题的范围。一些常见的公开视频异常检测基准数据集包括UCSD-Peds(Li、Mahadevan和Vasconcelos,2013年)、Avenue(Lu、Shi和Jia,2013年)、Street Scene(Ramachandra和Jones,2020年)、Shanghai Tech(Luo、Liu和Gao,2017年)、TAD(Lv等人,2021年)以及UCFCrime(Sultani、Chen和Shah,2018年),这些数据集涵盖了各种监控场景和异常事件。通常情况下,这些数据集首先要通过特征提取器进行处理,以获得RGB特征或光流特征。RGB特征捕捉视频的外观信息,而光流特征则侧重于运动信息。
最近,动态视觉传感器(DVS)(Lichtsteiner、Posch和Delbruck,2008年;Brandli等人,2014年),也被称为事件相机,因其高动态范围、高时间分辨率和低延迟而备受关注。DVS是一种受人类视网膜周边神经元启发的仿生视觉传感器。它采用基于差异的采样模型,仅在像素亮度变化超过阈值时生成事件数据。与传统图像不同,事件流将视觉信息编码为离散事件,极大地减少了数据冗余并保留了时间特征。这种高效的信息处理方式使事件相机在捕捉画面中的移动物体方面比传统相机表现更出色,并且能将系统级功耗降低多达100倍(Delbruck等人,2010年;Posch、Matolin和Wohlgenannt,2010年)。然而,尽管事件相机具有这些优势,但它们尚未应用于视频异常检测领域。因此,我们使用事件相机引入了该领域的首个DVS数据集,名为UCF-Crime-DVS,以探索其在视频异常检测中的潜力。
然而,由于事件数据的离散特性,人工神经网络(ANNs)并不能很好地处理事件流。与ANNs不同,脉冲神经网络(SNNs)以事件格式的数据作为输入,并使用离散的二进制脉冲信号,这使其在处理事件流方面具有天然优势(Chen等人,2023年)。因此,为了在视频异常检测(VAD)领域更好地利用事件数据,本文介绍了一种完全基于SNN的VAD框架,称为多尺度脉冲融合网络(MSF)。鉴于事件数据独特的动态特性和时间复杂性,有效处理这种复杂性至关重要。时间交互模块(TIM)(Shen等人,2024年)增强了脉冲自注意力(SSA)机制应对这些挑战的能力。因此,我们的MSF框架融入了TIM,以提升模型对事件数据的时间处理能力。
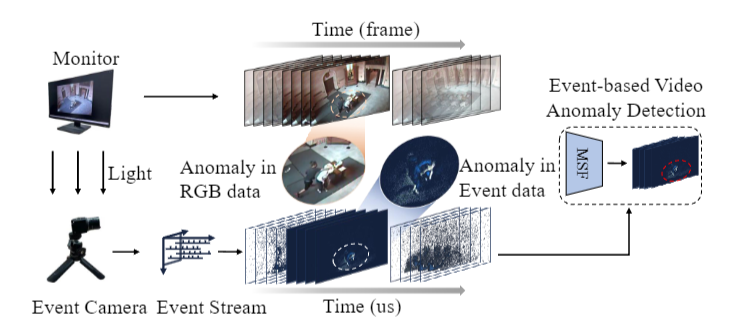
图1:我们的研究贡献概述。
据我们所知,这项工作率先探索了将事件数据应用于视频异常检测(VAD)。我们工作的概述如图1所示。首先,我们构建了一个用于视频异常检测的基于事件的数据集。有了这个数据集后,我们提出了MSF框架,这是一种完全基于脉冲神经网络的架构,旨在更好地从事件流中检测异常事件。总体而言,我们的贡献可总结如下:
- 我们提出了首个用于视频异常检测的大型动态视觉传感器(DVS)数据集,目的是将DVS丰富的动态信息和高时间分辨率应用于视频异常检测中。
- 我们提出了一种基于脉冲神经网络(SNN)的多尺度框架,用于基于动态视觉传感器(DVS)的视频异常检测。时间交互模块(TIM)被创新性地集成到基于卷积的SNN框架中,以增强脉冲特征的融合,这也证明了其在其他时间序列任务中的有效性。
Related Works
Event Camera Applications
事件相机已在计算机视觉应用中得到广泛使用。例如,时间事件频率法(TEF)(Han等人,2023年)通过将事件信号的高时间分辨率转换为精确的辐射值来重建图像信号。自注意力网络(SAN)(Zhang等人,2023年)允许灵活的输入空间缩放,并使用自监督微调来提高从图像中去除运动模糊的泛化性能。时空网络(STNet)(Zhang等人,2022年)动态地从时间和空间域中提取并融合信息,用于单目标跟踪。基于事件的精确动作识别模型(ExACT)(Zhou等人,2024年)通过采用跨模态概念化,引入了一种全新的基于事件的动作识别方法。尽管事件相机已在计算机视觉的许多领域得到应用,但它们尚未在视频异常检测中得到利用。因此,我们的工作探索了这种可能性。
Weakly Supervised Video Anomaly Detection
我们的工作是一个弱监督视频异常检测(WSVAD)任务。其主流方法是多实例学习(MIL),由Sultani、Chen和Shah在2018年提出。具体来说,多实例学习将每个视频视为一个 “包”,并将每个视频分割为等长且不重叠的片段,这些片段被称为实例。正常视频中的所有实例都被称为正包,而那些至少包含一个异常实例的包被称为负包,代表异常视频。在多实例学习中,学习过程是通过降低正包中每个实例的预测异常分数,并且只提高负包中异常分数最大的那个实例的分数来实现的。总体而言,弱监督视频异常检测可以概括为三个阶段:1)将每个视频分割成多个片段,并由预训练的编码器提取特征;2)使用多层感知器(MLP)生成异常分数;3)使用多实例学习框架对模型进行优化。
Spiking Neurons
由于事件相机将视觉输入记录为异步离散事件,它们本质上适合与脉冲神经网络(SNNs)协同工作。脉冲神经元的前向传播可概括为三个步骤:充电、发放和重置(Fang等人,2021a)。在本文中,我们选择了漏电积分发放(LIF)神经元模型(Gerstner等人,2014),该模型因其简单性以及捕捉神经元动态关键特征的能力,在脉冲神经网络中被广泛采用。LIF的动态模型可写成以下形式:
\[u^{t + 1, l}=\tau u^{t, l}+W^{l}o^{t, l - 1}, (1)\]
\[o^{t, l}=\Theta\left(u^{t, l}-V_{th}\right), \quad(2)\]
\[u^{t + 1, l}=\tau u^{t, l} \cdot(1 - o^{t, l})+W^{l}o^{t + 1, l - 1}, (3)\]
\[u^{t + 1, l}=\tau u^{t, l} \cdot(1 - o^{t, l})+W^{l}o^{t + 1, l - 1}, (3)\] 其中,\(\tau\)是漏电因子,\(u^{t, l}\)表示在时间步\(t\)时第\(l\)层神经元的膜电位,\(W^{l}\)和\(o^{i}\)分别代表权重参数和发放的脉冲。\(\Theta\)表示海维赛德阶跃函数。当\(u^{t, l} \geq V_{th}\)时,\(\Theta(u^{t, l} - V_{th})\)等于1,否则等于0。膜电位会随着输入不断积累,直到超过给定的阈值\(V_{th}\),此时神经元会发放一个脉冲,并且膜电位\(u^{t, l}\)会被重置为零。
UCF-Crime-DVS Dataset
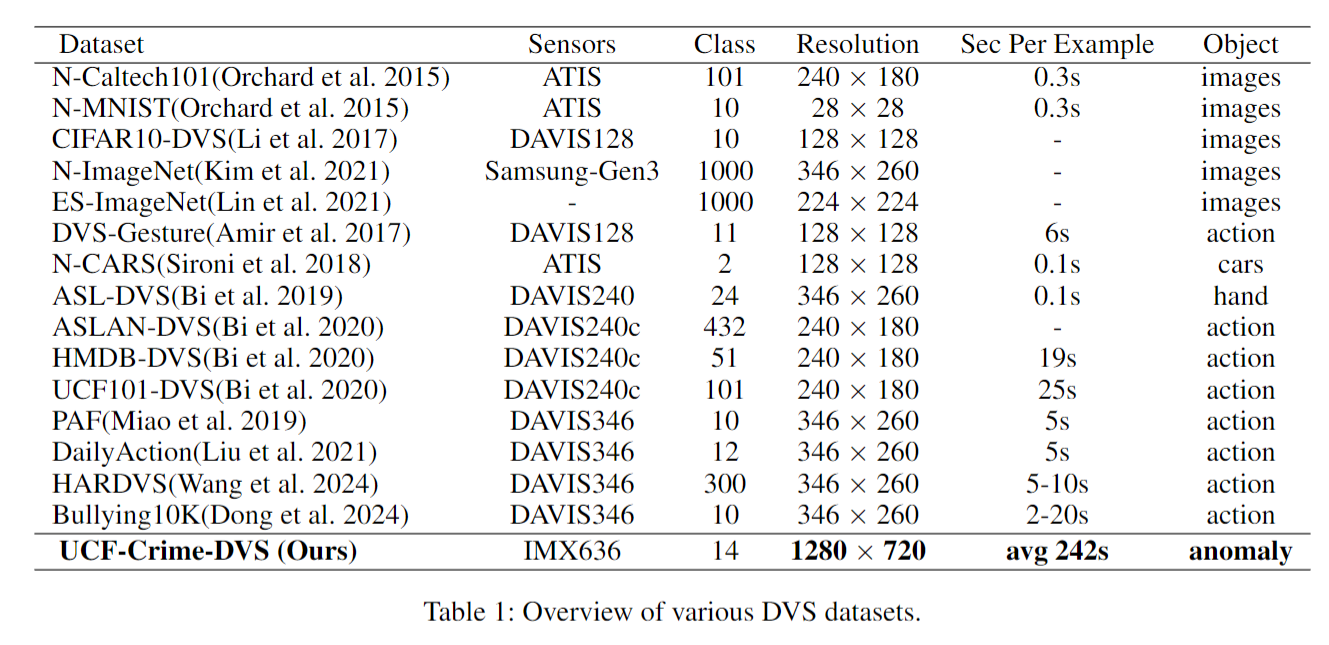
对于视频异常检测(VAD)而言,数据集与模型同样重要。在本文中,我们构建了首个基于事件的视频异常检测数据集,名为UCF-Crime-DVS。我们的数据集包含1900个事件流,涵盖13个异常类别,与原始的UCFCrime数据集(Sultani、Chen和Shah,2018年)相对应。它包括1610个带有视频级标签的训练集和290个带有帧级标签的测试集,且训练集和测试集中正常视频和异常视频的数量相等。表1将我们数据集的参数与其他DVS数据集进行了对比,突出显示我们的数据集分辨率高达1280×720,每个视频平均时长242秒,总计128小时。这远远超过了其他DVS数据集的规格。接下来,我们将展示该数据集的特征,并详细描述数据集的构建过程。
Characteristics of Event Data
与具有红、绿、蓝三个通道的RGB视频中的像素点不同,事件数据仅由两个通道(“关(OFF)”、“开(ON)”)组成。具体来说,每个事件可以用\(e=(x, y, p, t)\)来表示,其中\((x, y)\)表示位置,\(p \in \{0, 1\}\)表示极性,\(t\)表示时间戳(以微秒(µs)为单位)。亮度增加超过阈值的事件被称为“开(ON)”事件,而亮度降低的事件则被称为“关(OFF)”事件。如前所述,事件相机使用基于差异的采样模型和阈值机制来生成事件。这种机制使得事件相机相比RGB相机能够捕捉到更快的移动物体以及更多的动态信息,同时忽略了大部分静态信息。如图2所示,我们数据集中的动态主体被清晰地呈现出来,而静态背景几乎不可见。此外,像在“入店行窃031(Shoplifting031)”和“偷窃018(Stealing018)”中,画面边缘的细微事件也能够被事件相机捕捉到。

图2:我们的数据集展示以及UCF-Crime数据集的动态视觉传感器(DVS)版本和RGB版本之间的对比。
Dataset Construction
前期制作阶段。首先,我们准备了一台由Prophesee公司提供的、分辨率为1280×720且配备IMX636传感器的事件相机,以及一台32英寸的4K显示器来播放原始的UCF-Crime数据集。该数据集是在无光环境下采集的,在这种环境中,事件相机所感知到的唯一光线来自于播放视频的显示器。
数据集预处理阶段。我们将原始数据集中的视频按类别合并成单个的长视频以便播放,并记录了每个视频的帧数。
数据集拍摄阶段。使用了Metavision软件开发工具包(SDK)来控制事件相机。我们调整了光圈和焦距,以捕捉清晰的图像。为了减少背景噪声,我们在关注事件发生率和显示屏显示情况的同时,对偏置设置进行了微调,以此来评估噪声的影响。最终的拍摄设置如图3所示。

图3:最终的拍摄环境设置。
数据集后处理阶段。在记录完事件数据集后,我们根据每个视频片段的长度对长事件流进行切片,以确保与原始数据集保持一致。由于离散的事件数据不易被下游网络处理,因此需要将其转换为更便于使用的格式。主流方法是基于事件帧的数量或时长,将事件数据整合为事件帧,以便用于下游任务。同样地,我们按照指定的时间间隔,将每个事件流合并为事件帧。
每533328微秒(对应16个视频帧)内的所有事件\(e\)都被整合到一个事件帧\(E_{j}\)中,\(E_{j}\)代表第\(j\)个事件帧。将\(e_{\Delta t}=(x, y, p)\)定义为时间间隔\(\Delta t\)内的事件,其中\(\Delta t = t_{j_{r}} - t_{j_{t}}\) 。整合事件的过程可以表示为:
\[E_{j}(x, y, p)=\sum_{t=t_{j_{l}}}^{t_{j_{r}-1}} 1\left(e_{\Delta t}=\left(x_{t}, y_{t}, p_{t}\right)\right), (4)\]
在这里,\(E_{j}(x, y, p)\)表示在位置\((x, y, p)\)处的像素值,该像素值是由指定时间间隔\([t_{j_{l}}, t_{j_{r}})\)内的事件数据整合而来的,并且\(1\)是一个指示函数,仅当\(e_{\Delta t}=(x_{t}, y_{t}, p_{t})\)时,该函数的值等于\(1\)。
Methods
设\(X = \{x_{i}\}_{i = 1}^{n}\)表示包含来自所提出的UCF-Crime-DVS数据集中\(n\)个事件流视频的训练集,\(T = \{t_{i}\}_{i = 1}^{n}\)表示时间长度,其中\(t_{i}\)是第\(i\)个事件流的事件帧数。此外,我们使用\(Y = \{y_{i}\}_{i = 1}^{n}\)(其中\(y_{i} \in \{0, 1\}\))来表示视频异常标签集。在测试阶段,第\(i\)个视频的异常分数向量定义为\(s_{i} = \{s^{j}\}_{j = 1}^{t}\),其中\(s^{j} \in \{0, 1\}\),并且\(s^{j}\)是第\(j\)个事件片段的异常分数。
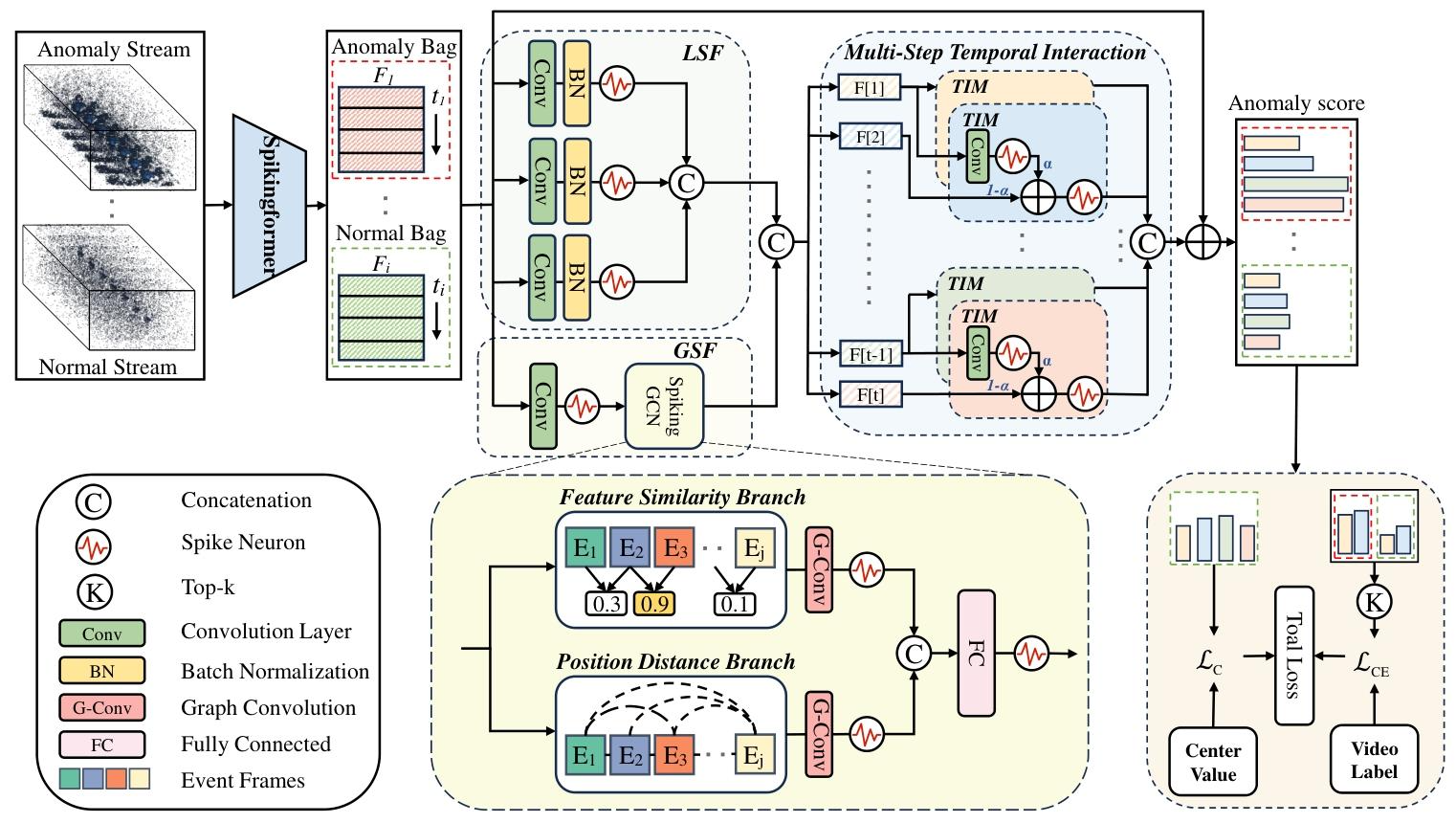
图4:我们所提出的多尺度脉冲融合模块(MSF)的框架图。局部脉冲特征提取模块(LSF)和全局脉冲特征提取模块(GSF)分别代表局部和全局的脉冲特征提取器模块。\(L_{CE}\)表示交叉熵损失,\(L_{C}\)表示中心损失。
Feature Extraction
大多数视频异常检测(VAD)任务都从特征提取开始。我们使用Hardvs数据集(Wang等人,2024年),这是一个大型的基于事件的动作识别数据集,来预训练一个脉冲变压器网络(Spikingformer)(Zhou等人,2023年),它将作为我们的特征提取器。然后,使用经过预训练的脉冲变压器网络来提取UCF-Crime-DVS数据集的特征。在此之后,我们从训练视频\(x\)中获得维度为\(t ×D\)的事件流特征\(F\),其中\(D\)是片段特征的维度。根据多实例学习原理,特征\(F\)会被输入到我们的多尺度融合模块(MSF)中。
Multi-Scale Spiking Fusion
在处理事件数据时,尤其是对于视频异常检测(VAD)而言,在发现时间依赖关系的同时,高效地提取并保留时间特征至关重要。我们提出的多尺度脉冲融合模块(MSF)既能捕捉单个事件片段内的多分辨率局部脉冲依赖关系(如图4中的浅绿色模块),又能捕捉事件片段之间的全局脉冲依赖关系(如图4中的浅黄色模块)。最后,这些依赖关系会根据脉冲特征的独特属性被无缝整合在一起(如图4中的浅蓝色模块)。
局部脉冲特征。多尺度脉冲融合模块(MSF)在时间域上使用金字塔扩张卷积\(\{P_1, P_2, P_3\}\)来学习事件片段的多尺度表示。它从特征\(F = \{f_d\}_{d = 1}^{D}\)中学习多尺度脉冲特征。给定特征\(f_d \in \mathbb{R}^t\),使用核\(W_{p, d} \in \mathbb{R}^{\omega}\)进行一维扩张卷积操作,其中\(p \in \{1, \ldots, D/4\}\),\(d \in \{1, \ldots, D\}\),\(\omega\)表示滤波器的大小,其定义为:
\[f_p = \sum_{d = 1}^{D} W_{p, d} * f_d, \quad (5)\]
其中\(*\)表示扩张卷积算子,\(f_p \in \mathbb{R}^t\)表示在时间维度上应用扩张卷积后的输出特征。由\(f_p\)拼接而成的特征\(F_p \in \mathbb{R}^{t \times D/4}\)随后会通过脉冲神经元以获得脉冲特征:
\[F_P = \text{Lif}(F_p), \quad (6)\]
其中\(\text{Lif}\)是漏电积分发放型脉冲神经元。
全局脉冲特征。尽管局部时间依赖关系很重要,但全局的时间依赖关系同样不容忽视。我们引入了一个轻量级的脉冲图卷积网络(SpikingGCN),以进一步捕捉不同事件片段之间的时间依赖关系,这在图4中以黄绿色模块展示。我们的全局时间特征提取模块首先将特征从\(F \in \mathbb{R}^{t ×D}\)下采样到\(F^{c} \in \mathbb{R}^{t ×D / 4}\),其中\(F^{c}=Conv_{1 ×1}(F)\)(即通过\(1\times1\)卷积操作得到\(F^{c}\))。然后,脉冲图卷积网络(SpikingGCN)根据特征相似度和相对距离对脉冲特征的全局时间依赖关系进行建模。
特征相似度分支使用基于事件帧的余弦相似度方法为脉冲图卷积网络(SpikingGCN)生成邻接矩阵\(M_{sim}\),其表示如下:
\[M^{sim}=\frac{F^{c} F^{c^{\top}}}{\left\| F^{c}\right\| _{2} \cdot\left\| F^{c}\right\| _{2}} .(7)\]
我们采用位置距离分支,通过测量不同事件帧中物体或场景的位置差异来捕捉它们之间的长距离关系,如下所示:
\[M^{dis}(i, j)=\frac{-|i - j|}{\sigma},(8)\]
这意味着事件帧\(i\)和\(j\)之间的接近程度仅取决于它们在时间上的相对位置,而与其他因素无关。超参数\(\sigma\)用于调整影响程度。
总体而言,改进后的脉冲图卷积网络(SpikingGCN)可总结如下:
\[F^{G}=Lif\left(\left[Soft\left(M^{sim}\right) ; Soft\left(M^{dis }\right)\right] F^{c} W\right), (9)\]
其中\(W\)是唯一的可学习权重,用于将输入特征空间转换为另一个特征空间。\(Soft\)表示Softmax归一化操作,用于确保\(M^{sim}\)和\(M^{dis}\)的每一行元素之和都等于\(1\)。
多尺度脉冲交互。我们使用残差拼接的方法来防止特征过度平滑,并将全局脉冲特征与局部脉冲特征进行拼接,这可以描述为:
\[\overline{F}=\left[F^{(l)}\right]_{l \in L} \in \mathbb{R}^{t × D}, \quad(10)\]
其中\(L = \{P_{1}, P_{2}, P_{3}, G\}\) ,\(F^{P}\)和\(F^{G}\)分别指学习得到的局部和全局时间特征。
如前所述,事件数据具有独特的动态特性和时间上的复杂性,而脉冲神经元的膜电位呈现出累积的性质。因此,最初提取的时间信息表现为膜电位而非脉冲。结果是,传统的基于人工神经网络(ANN)的时间学习方法,例如MTN(田等人,2021年),无法有效地整合事件片段的多尺度特征,导致不同时间步长的信息被大量浪费。为了挖掘不同时间步长中隐藏的信息,我们采用时间交互模块(TIM)(沈等人,2024年)将历史脉冲信息与当前脉冲信息进行融合。超参数\(\alpha\)用作权重参数,使模型在计算过程中能够平衡历史状态与当前输入的组合。这可以用以下公式数学表达:
\[F^{TIM}=\alpha Conv\left(F^{TIM}[t - 1]\right)+(1 - \alpha) \overline{F}[t] . \quad(11)\]
时间交互模块(TIM)展示了一种处理时间信息的双重机制:即时特征提取和历史状态整合。这种方法不仅能从当前输入中提取关键特征,还能有效地利用先前时间步长中的隐含状态信息。这一设计实现了短期和长期依赖关系的有机结合,使模型能够捕捉到事件数据中的复杂动态特征。
异常评分器。在经过多尺度脉冲融合模块(MSF)处理之后,使用一个全连接(FC)层和一个Sigmoid函数作为异常评分器,以生成异常评分向量\(s_{i}\):
\[s_{i}=Sigmoid\left(FC\left(F^{TIM}\right)\right) . (12)\]
Loss Function
对于我们所提出的多尺度脉冲融合模块(MSF),采用了经典的动态多实例学习(DMIL)损失函数和中心损失函数。
动态多实例学习(DMIL)损失。动态多实例学习损失旨在扩大实例之间的类间距离,其可以表示如下:
\[\begin{aligned} \mathcal{L}_{DMIL } & =\frac{1}{k_{i}} \sum_{s_{i}^{j} \in S_{i}}\left[-y_{i} \log \left(s_{i}^{j}\right)\right. \\ & \left.+\left(1 - y_{i}\right) \log \left(1 - s_{i}^{j}\right)\right] \end{aligned},\]
其中,\(s_{i}^{j}\)是第\(i\)个视频按降序排列的异常评分向量,\(S_{i} = \{s_{i}^{j} | j = 1, 2, \ldots, k_{i}\}\)由\(s_{i}\)中排名前\(k_{i}\)的元素组成,并且\(y_{i} \in \{0, 1\}\)是该视频的异常标签。
中心损失。用于异常评分回归的中心损失会收集正常事件片段的异常评分,从而减小类内距离。它可以表示为:
\[\mathcal{L}_{c}=\left\{\begin{array}{ll} \frac{1}{t_{i}} \sum_{j=1}^{t_{i}}\left\| s_{i}^{j}-c_{i}\right\| _{2}^{2}, & if y_{i}=0 \\ 0, & otherwise \end{array}, \quad(14)\right.\]
\[c_{i}=\frac{1}{t_{i}} \sum_{j=1}^{t_{i}} s_{i}^{j}, \quad(15)\]
其中\(c_{i}\)是异常评分向量\(s_{i}\)的中心。总体而言,我们的多尺度脉冲融合(MSF)模型的总损失函数由下式给出:
\[\mathcal{L}=\mathcal{L}_{DMIL}+\lambda \mathcal{L}_{c} . \quad(16)\]
Experiments
我们通过一项视频异常检测(VAD)任务对我们的UCF-Crime-DVS数据集和多尺度脉冲融合(MSF)框架进行了验证。此外,我们还通过消融实验测试了每个模块的性能。
Experiments Setup
训练数据集。我们使用我们的UCF-Crime-DVS数据集来测试和验证我们提出的方法。我们的UCF-Crime-DVS数据集与UCF-Crime数据集相对应,涵盖了1610个带有视频级别标签的训练视频中的13类异常情况,以及290个带有帧级别标签的测试视频。
训练细节。参照(苏尔塔尼、陈和沙阿,2018年)的方法,每个事件流都被划分为不重叠的片段。根据经验,对于我们的数据集,我们将\(k\)设置为\(4\)。我们使用Adam优化器,权重衰减为\(0.0005\),学习率为\(0.0001\)。对于公式8中的\(\sigma\)和公式16中的\(\lambda\),我们分别将它们设置为\(1\)和\(20\)。每一批包含\(60\)个样本,这些样本在正常和异常视频序列中平均分配,且均从训练集中随机选取。进行实验的模型是基于PyTorch(帕兹克等人,2019年)、SpikingJelly(方等人,2023年)以及一台配备单块RTX4090 GPU的服务器来实现的。
评估指标。我们使用两项标准化的性能指标来评估模型的异常检测能力:帧级别受试者工作特征曲线(ROC)下的面积(AUC),以及阈值为\(0.5\)时的误报率(FAR)。对这两项指标的综合评估,不仅反映了模型的整体判别能力,还体现了其在实际应用场景中的可靠性和稳定性。
Performance Analysis
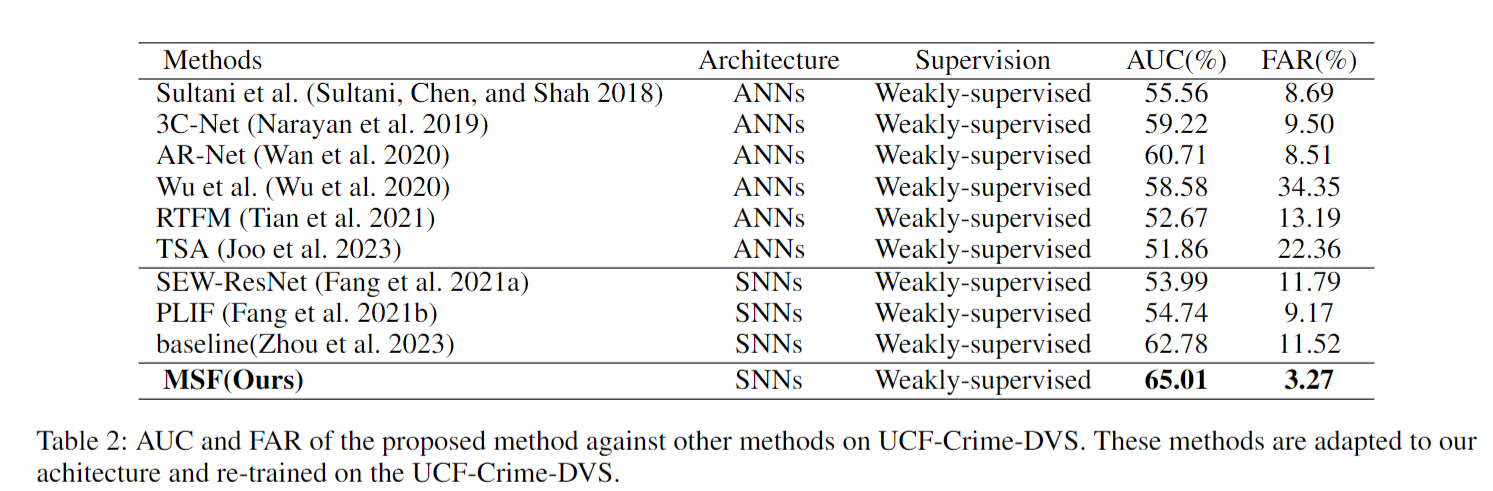
表2展示了我们的方法与其他方法在UCF-Crime-DVS数据集上的对比情况。可以看出,相比之下,经典的视频异常检测(VAD)框架在这个数据集上表现不佳。一些方法的误报率(FAR)超过了20%,这表明它们无法有效地处理事件数据。其他基于脉冲神经网络(SNN)且网络层更深的架构也未能同时实现较高的受试者工作特征曲线下面积(AUC)和较低的误报率,这说明仅仅增加网络的复杂性并不能提升视频异常检测的性能。另一方面,我们的多尺度脉冲融合(MSF)方法在异常检测方面实现了65.01%的AUC,且误报率仅为3.27%,与我们的基线方法相比,AUC高出3%,误报率低8%。它为基于事件的广域场景视频异常检测(WSVAD)建立了一个新的基线。
Ablation Study
表3中展示的一系列消融研究表明,当三个模块全部组合使用时,能够实现最佳性能。相比之下,局部脉冲特征(LSF)和全局脉冲特征(GSF)组合的性能,以及每个模块单独使用时的性能,都不够理想。这可以归因于这样一个事实:局部脉冲特征(LSF)和全局脉冲特征(GSF)都在时间域上扩展了特征表示,局部脉冲特征(LSF)缺乏不同部分之间的相互连接,而全局脉冲特征(GSF)会对特征进行平滑处理,这给异常定位带来了挑战。然而,将时间交互模块(TIM)与局部脉冲特征(LSF)和全局脉冲特征(GSF)相结合,显著提升了性能,这凸显了时间交互模块(TIM)在有效整合不同时间步长信息方面的关键作用。
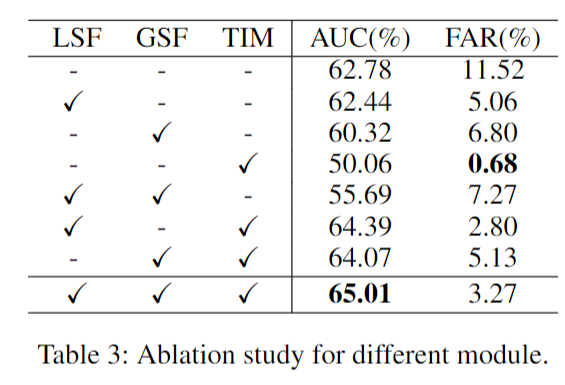
时间交互模块(TIM)的消融实验。如图5左侧所示,我们进行了消融实验,以研究时间交互模块(TIM)放置位置所产生的影响。结果显示,两种放置位置之间存在超过10%的精度差异,这表明时间交互模块(TIM)的最佳放置位置是在多尺度脉冲融合(MSF)模块内。将时间交互模块(TIM)整合到多尺度脉冲融合(MSF)模块中,能够在多个时间步长上无缝融合时间特征,确保准确捕捉时间依赖关系,并提高异常检测性能。此外,如图5右侧所示,超参数\(\alpha\)取任何非零值时所得到的结果都比将\(\alpha\)设置为零要好。当\(\alpha\)设置为\(0.6\)时,多尺度脉冲融合(MSF)模块达到其最佳性能,这表明时间交互作用的引入显著提升了性能。
Visualization
图6展示了一组可视化结果。需要注意的是,某些场景转换以及片头或片尾字幕展示的特征与爆炸事件的特征相似,例如闪烁的画面以及事件发生数量的激增。这使得在我们的数据集中检测爆炸事件极具挑战性。然而,我们的模型仍成功识别出了诸如“Explosion022”这样的爆炸事件,突显了其鲁棒性。此外,对于像偷窃这类在视觉上难以察觉的细微异常事件,我们的模型在一定程度上能够识别出这些微弱的异常情况,“Stealing036”这个例子就说明了这一点。尽管可视化的异常分数在异常片段中并非始终超过异常阈值,但这是因为一些异常事件包含相对静止的片段,这些片段并未触发动态视觉传感器(DVS),从而导致这些事件的部分信息缺失。
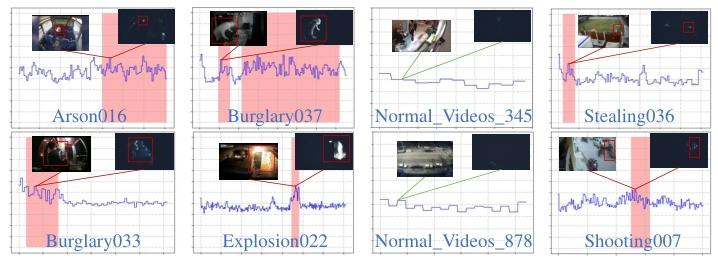
图6:我们的方法在UCF-CrimeDVS数据集上的异常分数情况。粉色区域表示人工标注的异常事件,紫色线条代表异常分数,红色方框则指出了屏幕上的异常事件。
Conclusion
在本文中,我们提出了首个基于事件的视频异常检测(VAD)数据集,并介绍了用于基于脉冲神经网络(SNN)的视频异常检测的多尺度脉冲融合(MSF)框架。大量实验表明,我们的方法在UCF-Crime-DVS数据集上的表现优于其他方法,突显了其在实际应用中的潜力。尽管我们的方法在RGB数据集上尚未达到传统方法那样的高精度,但它为视频异常检测提供了一个全新的视角,并为未来的研究奠定了基础。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









