









 本文详细介绍了R语言的基础知识,包括如何创建和操作数据,如向量、矩阵、数组、数据框和因子。接着,讨论了数据的读取、保存、随机数生成和抽样。在数据可视化部分,涵盖了R的基本绘图函数,如条形图、直方图、核密度图、箱线图等,以及更复杂的图形如马赛克图、气泡图和饼图。此外,还涉及了图形控制、颜色管理和页面布局。文章提供了丰富的代码示例,帮助读者理解和应用R进行数据处理和可视化。
本文详细介绍了R语言的基础知识,包括如何创建和操作数据,如向量、矩阵、数组、数据框和因子。接着,讨论了数据的读取、保存、随机数生成和抽样。在数据可视化部分,涵盖了R的基本绘图函数,如条形图、直方图、核密度图、箱线图等,以及更复杂的图形如马赛克图、气泡图和饼图。此外,还涉及了图形控制、颜色管理和页面布局。文章提供了丰富的代码示例,帮助读者理解和应用R进行数据处理和可视化。
第1章 R语言入门
1.1 创建R数据
1.1.1 向量 c()
1.1.2 矩阵 matrix()
1.1.3 数组 array()
dim1 <- c("男","女")
dim2 <- c("赞成","中立","反对")
dim3 <- c("东部","西部","南部","北部")
data <- round(runif(24,50,100))
array(data, c(2,3,4), dimnames=list(dim1,dim2,dim3))
1.1.4 数据框 data.frame()
| 函数 | 解释 |
|---|---|
| head() | 查看前几行 |
| tail() | 查看后几行 |
| str() | 查看数据结构 |
| class() | 查看数据类型 |
| rbind() | 按行合并 |
| cbind() | 按列合并 |
| sort() | 对向量进行排序 |
| order() | 对数据框的数据进行排序 |
1.1.5 因子 factor()
类别变量(定性变量):分为无序类别变量和有序类别变量
数值变量(定量数据):分为离散变量和连续变量
1.1.6 列表 list()
1.2 数据的其他操作
1.2.1 数据读取和保存
| 函数 | 含义 |
|---|---|
| read.csv() | 读取外部数据 |
| write.csv() | 保存数据 |
1.2.2 生成随机数
| 函数 | 含义 |
|---|---|
| set.seed() | 设定随机数种子 |
| rnorm() | 正态分布 |
| runif() | 均匀分布 |
| rchisq() | 卡方分布 |
1.2.3 数据抽样 sample()
1.3 生成频数分布表
1.3.1 一维、二维列联表 table()
注:addmargins()为列联表添加边际和
1.3.2 多维列联表
ftable("数据", exclude, row.vars, col.vars)
library(vcd)
structable("公式", "数据", direction, subset)
1.3.3 数值数据类别化
cut("数据", breaks, include.lowest, right)
library(actuar)
grouped.data()
第2章 R绘图基础
2.1 R的基本绘图函数
2.1.1 高级绘图函数:产生一副独立的图形
- plot函数
| 属性 | 含义 |
|---|---|
| type | 设置绘图类型 |
| xlim | x轴的数值范围 |
| ylim | y轴的数值范围 |
| log | 设置坐标轴是否要取对数 |
| main | 图形主标题 |
| sub | 图形副标题 |
| xlab | x轴标签 |
| ylab | y轴标签 |
| axes | 是否绘制坐标轴 |
| frame.plot | 是否绘制图形外框 |
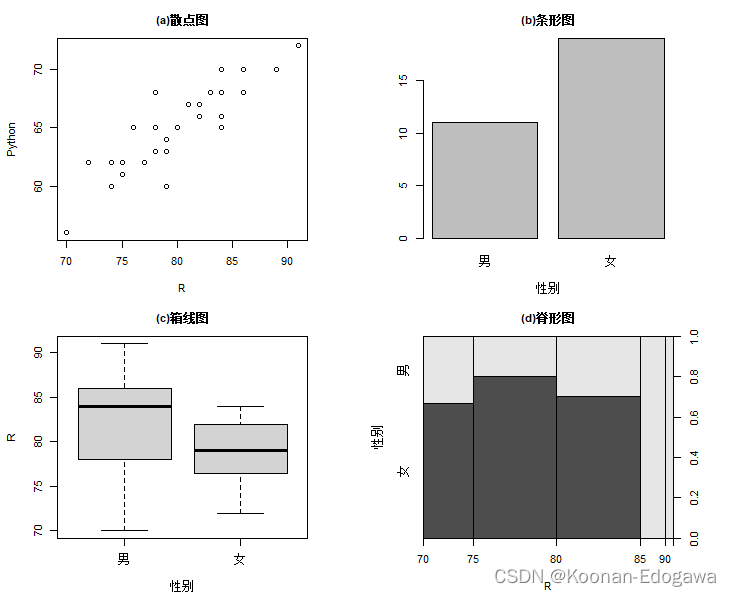
data2_1 <- read.csv("F:/data/mydata/chap02/data2_1.csv")
attach(data2_1)
par(mfrow=c(2,2), mai=c(0.6,0.6,0.4,0.6),cex=0.7,cex.main=1)
plot(R,Python,main="(a)散点图")
plot(as.factor(性别),xlab="性别",main="(b)条形图")
plot(R~as.factor(性别),xlab="性别",main="(c)箱线图")
plot(as.factor(性别)~R,ylab="性别",main="(d)脊形图")
detach(data2_1)
| 数据类型 | 图形 |
|---|---|
| 数值 | 散点图 |
| 数值、数值 | 散点图 |
| 因子 | 条形图 |
| 一维列联表 | 条形图 |
| 二维列联表 | 马赛克图 |
| 数据框 | 散点图矩阵 |
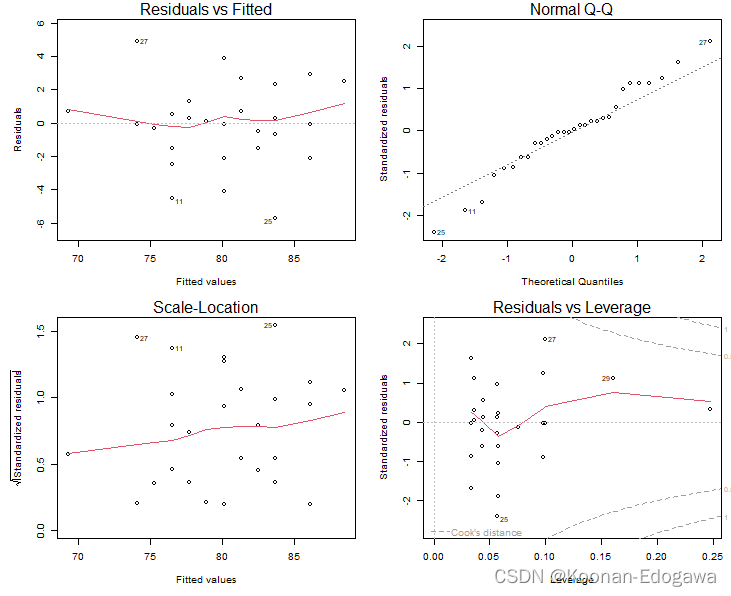
注:绘制模型的诊断图
par(mfrow=c(2,2), mai=c(0.6,0.6,0.2,0.1),cex=0.6)
model <- lm(R~Python,data=data2_1)
plot(model)
plot("数据1","数据2")
2.1.2 其他高级绘图函数
| 函数 | 数据类型 | 图形 |
|---|---|---|
| barplot() | 数值向量、矩阵、列联表 | 条形图 |
| boxplot() | 数值向量、列表、数据框 | 箱线图 |
| curve() | 表达式 | 曲线 |
| dotchart() | 数值向量、矩阵 | 点图 |
| hist() | 数值向量 | 直方图 |
| matplot() | 数值向量、矩阵 | 矩阵列图 |
| mosaicplot() | 多维列联表 | 马赛克图 |
| pairs() | 矩阵、数据框 | 散点图矩阵 |
| pie() | 数值向量、列联表 | 饼图 |
| stars() | 矩阵、数据框 | 星图 |
| stem() | 数值向量 | 茎叶图 |
2.1.3 低级绘图函数:在已有的图形上添加新元素
| 函数 | 描述 |
|---|---|
| abline() | 添加截距为a,斜率为b的直线 |
| arrows() | 两点之间绘制线段,并添加箭头 |
| segments() | 绘制线段 |
| box() | 绘制图形边框 |
| layout() | 布局图形页面 |
| legend() | 添加图例 |
| lines() | 添加直线 |
| mtext() | 添加文本 |
| text() | 添加文本 |
| points() | 添加点 |
| title() | 添加标题 |
| xspline() | 绘制x样条曲线 |
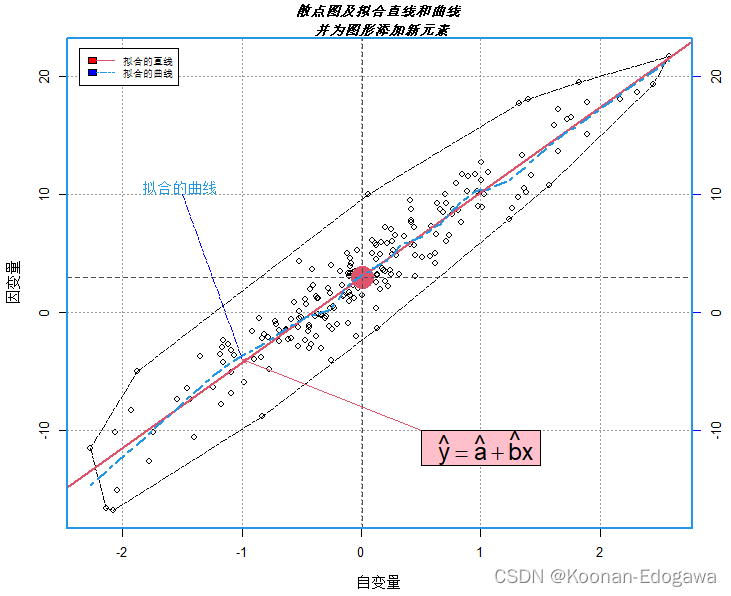
par(mai=c(0.7,0.7,0.4,0.4),cex=0.8)
set.seed(100)
x <- rnorm(200)
y <- 3 + 7*x + 2 * rnorm(200)
d <- data.frame(x, y)
plot(x, y, xlab='自变量', ylab='因变量')
grid(col='grey60') # 添加网格线
axis(side=4,col.ticks='blue',lty=1) # 添加坐标轴
polygon(d[chull(d),], lty=6, lwd=1) # 添加多边形
points(mean(x),mean(y),pch=19,cex=4,col=2) # 添加均值点
# 添加均值水平、垂直线
abline(v=mean(x),h=mean(y),lty=2,col='gray30')
abline(lm(y~x),lwd=2,col=2) # 添加回归直线
lines(lowess(y~x,f=1/6),col=4,lwd=2,lty=6) # 添加拟合曲线
segments(-1,-4,-1.5,10,lty=6,col="blue") # 添加线段
# 添加注释文本
text(-1.9,10,labels=expression('拟合的曲线'),adj=c(-0.1,0.02),col=4)
# 添加带箭头的线段
arrows(0.5,-10,-1,-4,code=2,angle=25,length=0.06,col=2)
rect(0.5,-10,1.5,-13,col='pink') # 添加矩形
mtext(expression(hat(y)==hat(a)+hat(b)*x),cex=1.5,side=1,line=-5,
adj=0.7) # 添加注释表达式
legend('topleft',legend=c('拟合的直线','拟合的曲线'),lty=c(1,6),
col=c(2,4),cex=0.8,fill=c('red','blue'),
ncol=1,inset=0.02) # 添加图例
title('散点图及拟合直线和曲线 \n 并为图形添加新元素',cex.main=1.2,
font.main=4) # 添加标题
box(col=4,lwd=2) # 添加边框
2.2 图形控制 par()
| 参数 | 描述 | 参数 | 描述 |
|---|---|---|---|
| adj | 设置文本的对齐方式 | bg | 图形的背景颜色 |
| bty | 图周围边框的类型 | cex | 控制文字和绘图符号的大小 |
| cex.axis | 坐标轴文字缩放倍数 | cex.lab | 坐标轴标签缩放倍数 |
| cex.main | 主标题缩放倍数 | cex.sub | 副标题缩放倍数 |
| col | 绘图颜色 | col.axis | 坐标轴文字颜色 |
| col.lab | 坐标轴标签颜色 | col.main | 主标题颜色 |
| col.sub | 副标题颜色 | family | 文字的字体族 |
| fg | 绘图的前景颜色 | font | 文字的字体 |
| font.axis | 坐标轴文字字体 | font.lab | 坐标轴标签字体 |
| font.main | 主标题字体 | font.sub | 副标题字体 |
| lty | 线条类型(1~6) | lwd | 线条宽度 |
| mai | 设置图形边距大小 | pch | 绘制点或符号的类型(0~25) |
| srt | 字符串的旋转角度 |
2.3 图形颜色
colors() # 查看颜色名称列表
library(RColorBrewer)
display.brewer.all(type='all') # 查看R的调色板
注:颜色集合函数
- rainbow()
- heat.colors()
- terrain.colors()
- topo.colors()
- cm.colors()
- gray.colors()
2.4 页面布局与图形组合
2.4.1 用par函数布局页面 mfrow mfcol
2.4.2 用layout函数布局页面:大小不同的区域
| 参数 | 解释 |
|---|---|
| mat | 由0或正整数组成的矩阵,用于描述绘制的图形 |
| widths | 向量,分割页面的列宽度 |
| heights | 向量,分割页面的行高度 |
| layout.show() | 预览图形的布局 |
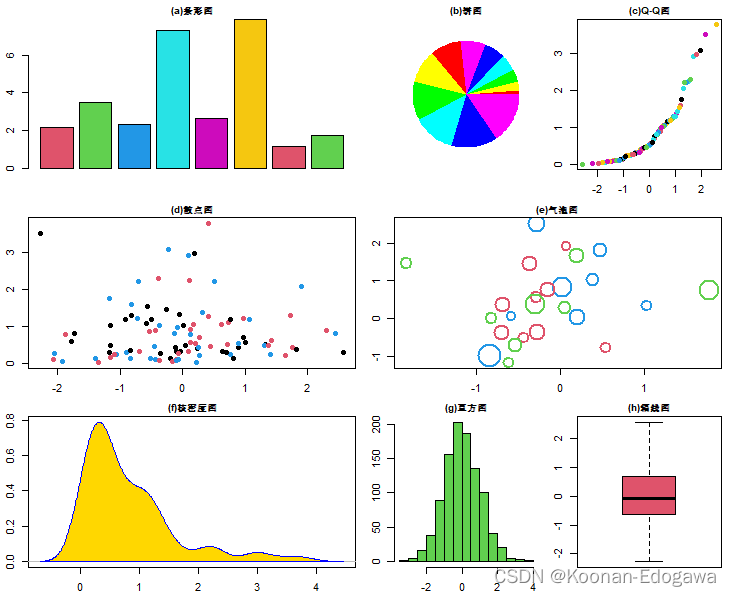
n = 100; set.seed(100); x <- rnorm(n); y <- rexp(n)
layout(matrix(c(1,2,3,4,5,5,6,7,8),3,3,byrow=T),widths=c(2:1),
heights=c(1:1))
par(mai=c(0.3,0.3,0.2,0.1),cex.main=0.9)
barplot(runif(8,1,8),col=2:7,main='(a)条形图')
pie(1:12,col=rainbow(6),labels="",border=NA,main="(b)饼图")
qqnorm(y,col=1:7,pch=19,xlab="",ylab="",main="(c)Q-Q图")
plot(x,y,pch=19,col=c(1,2,4),xlab="",ylab="",main="(d)散点图")
plot(rnorm(25),rnorm(25),cex=(y+2),col=2:4,lwd=2,xlab="",
ylab="",main="(e)气泡图")
plot(density(y),col=4,lwd=1,xlab="",ylab="",main="(f)核密度图")
polygon(density(y),col='gold',border='blue')
hist(rnorm(1000),col=3,xlab="",ylab="",main="(g)直方图")
boxplot(x,col=2,main="(h)箱线图")
2.4.3 同时打开多个绘图窗口 dev.new()
第3 章 类别数据可视化
3.1 条形图及其变种
3.1.1 简单的条形图
data3_1 <- read.csv("F://data/mydata/chap03/data3_1.csv")
library(sjPlot)
plot_frq(data=data3_1, 满意度, type="bar", show.n=T, show.prc=T)
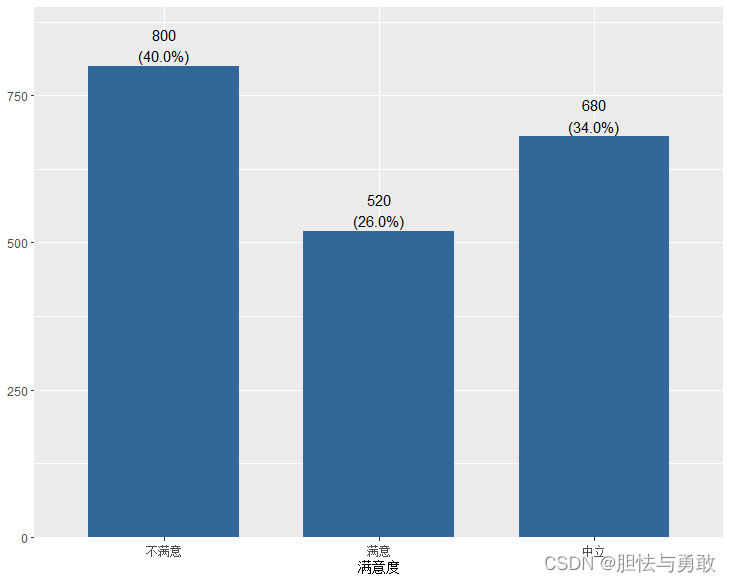
3.1.2 并列条形图和堆叠条形图
data3_1 <- read.csv("F://data/mydata/chap03/data3_1.csv")
library(sjPlot)
p1 <- plot_xtab(data3_1$满意度, data3_1$性别, bar.pos="dodge",
show.n=T, show.prc=T, show.summary=T, show.total=F,
vjust="center")
p2 <- plot_xtab(data3_1$满意度, data3_1$性别, bar.pos="stack",
show.n=T, show.prc=T, show.total=T, vjust="middle")
plot_grid(list(p1,p2), margin=c(0.3,0.3,0.3,0.3), tags=c("并列","堆叠"))
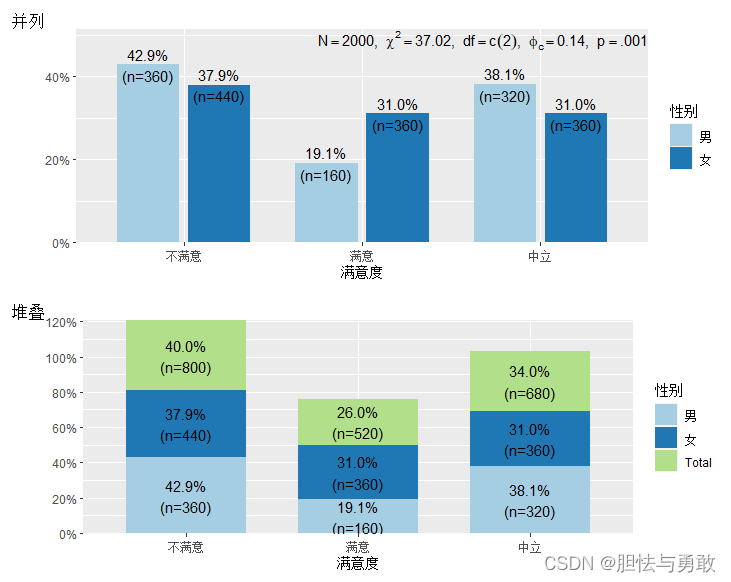
3.1.3 不等宽条形图和脊状图
library(ggiraphExtra)
library(ggplot2)
library(gridExtra)
data3_1 <- read.csv("F://data/mydata/chap03/data3_1.csv")
p1 <- ggSpine(data3_1, aes(x=满意度, fill=网购次数), position="dodge",
palette="Reds", labelsize=2.5, ggtitle("不等宽并列"))
p2 <- ggSpine(data3_1, aes(x=满意度, fill=网购次数), position="stack",
palette="Blues", labelsize=2.5, reverse = T,
ggtitle("不等宽并列"))
grid.arrange(p1, p2, ncol=1)
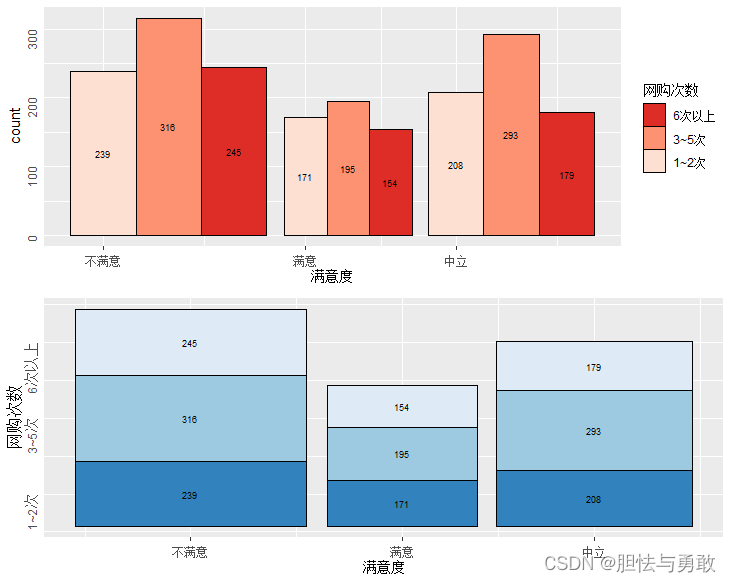
data3_1 <- read.csv("F://data/mydata/chap03/data3_1.csv")
library(ggiraphExtra)
library(ggplot2)
ggSpine(data3_1, aes(x=满意度, fill=网购次数, facet=性别),
palette="Reds", labelsize=3, reverse=T)
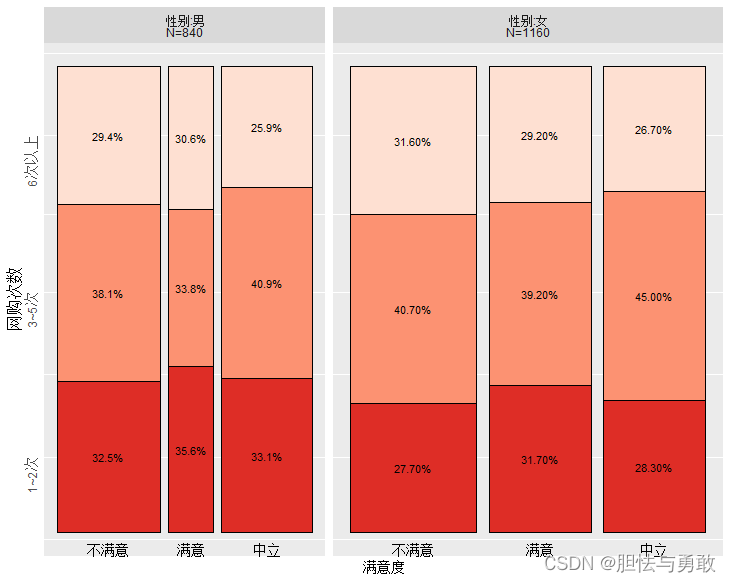
3.2 树状图
3.2.1 条形树状图
data3_1 <- read.csv("F://data/mydata/chap03/data3_1.csv")
library(plotrix)
cols = list(c("#FDD0A2","#FD8D3C"),c("#C6DBEF","#9ECAE1","#6BAED6"),
c("#C7E9C0","#A1D99B","#74C746"))
sizetree(data3_1, col=cols, showval=T, showcount=T, stacklabels=T,
border="black", base.cex=0.7)
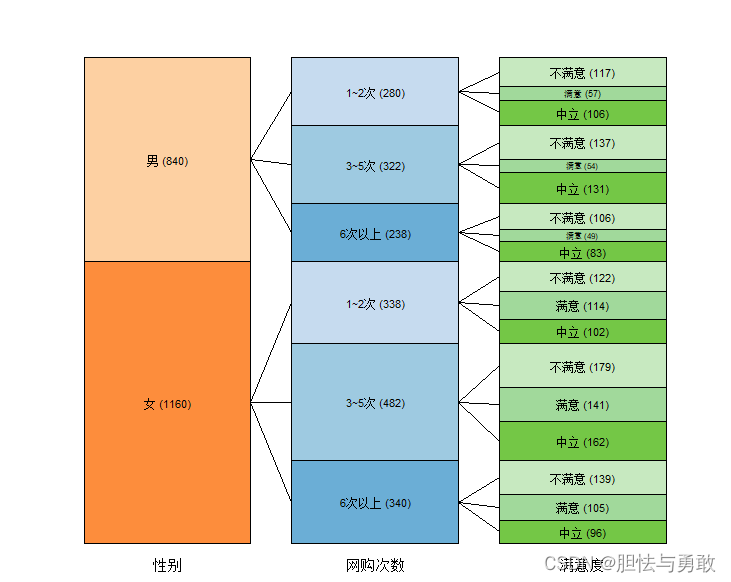
3.2.2 矩形树状图
library(treemap)
data3_1 <- read.csv("F://data/mydata/chap03/data3_1.csv")
tab <- ftable(data3_1)
d <- as.data.frame(tab)
df <- data.frame(d[,-4], 频数=d$Freq)
treemap(df, index=c("性别","网购次数","满意度"),
vSize="频数", type="index",fontsize.labels=9,
position.legend="bottom", title="")
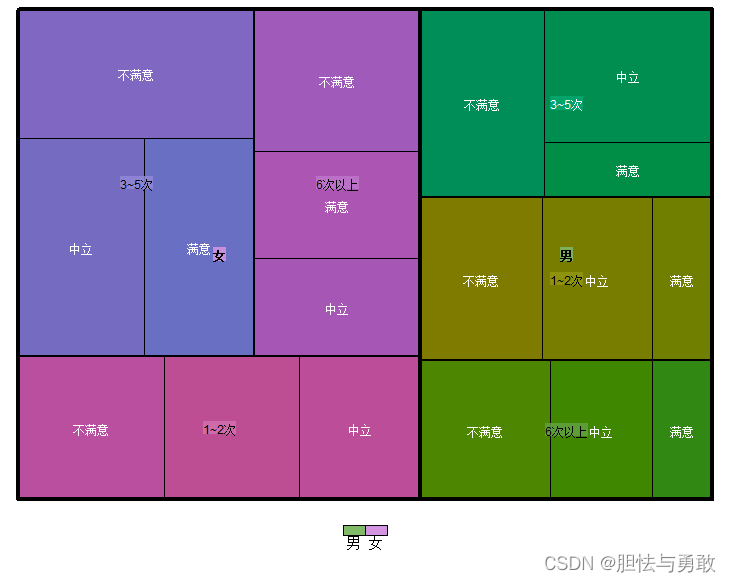
3.3 马赛克图及其变种
3.3.1 马赛克图
data3_1 <- read.csv("F://data/mydata/chap03/data3_1.csv")
par(mfrow=c(1,2), mai=c(0.3,0.3,0.2,0.1), cex.main=0.8, font.main=1)
mosaicplot(~性别+网购次数+满意度, data=data3_1, cex.axis=0.7,
col=c("#E41A1C","#377EB8","#4DAF4A"), off=8, dir=c("v","h","v"),
main="简单马赛克图")
mosaicplot(~性别+网购次数+满意度, data=data3_1, shade=T, cex.axis=0.7,
off=8, dir=c("v","h","v"), main="扩展马赛克图")
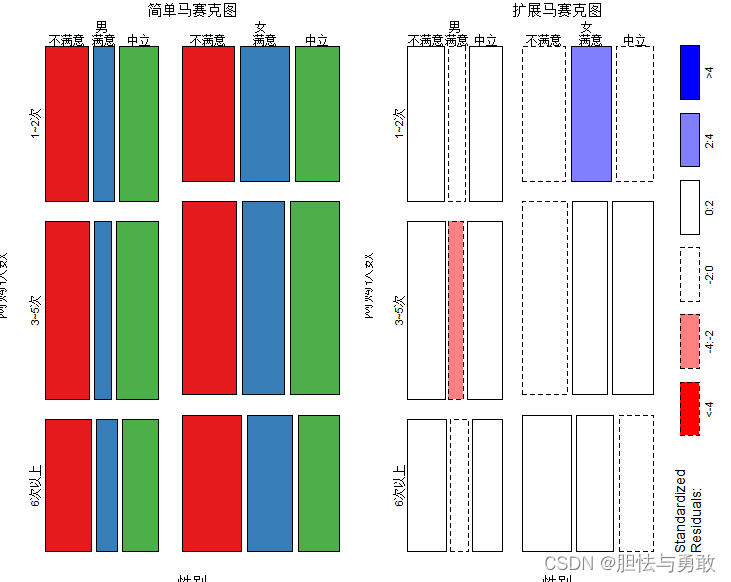
3.3.2 马赛克图的变种
library(vcd)
data3_1 <- read.csv("F://data/mydata/chap03/data3_1.csv")
tab <- structable(data3_1)
p1 <- mosaic(tab, shade=T, labeling=labeling_values, return_grob=T,
main="显示观测数")
p2 <- mosaic(tab, shade=T, labeling=labeling_values, value_type="expected",
return_grob=T, main="显示期望频数")
mplot(p1, p2, cex=0.5, layout=c(1,2))
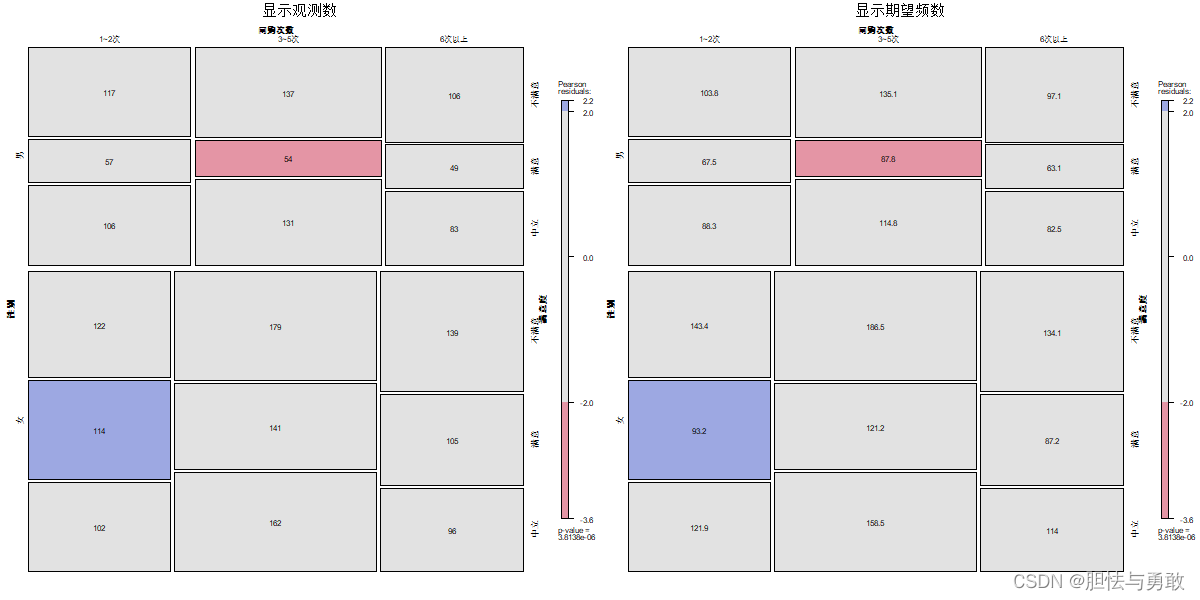
3.4 关联图和独立性检验P值图
library(vcd)
data3_1 <- read.csv("F://data/mydata/chap03/data3_1.csv")
tab <- structable(data3_1)
assoc(tab, shade=T, labeling=labeling_values)
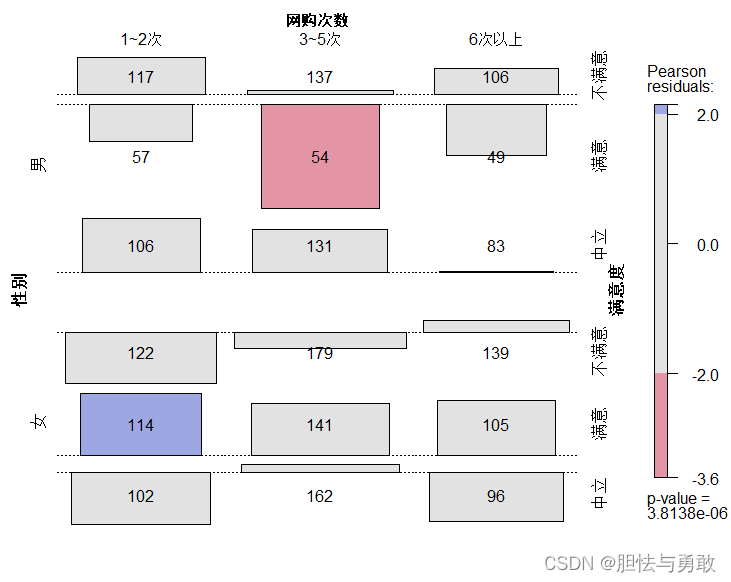
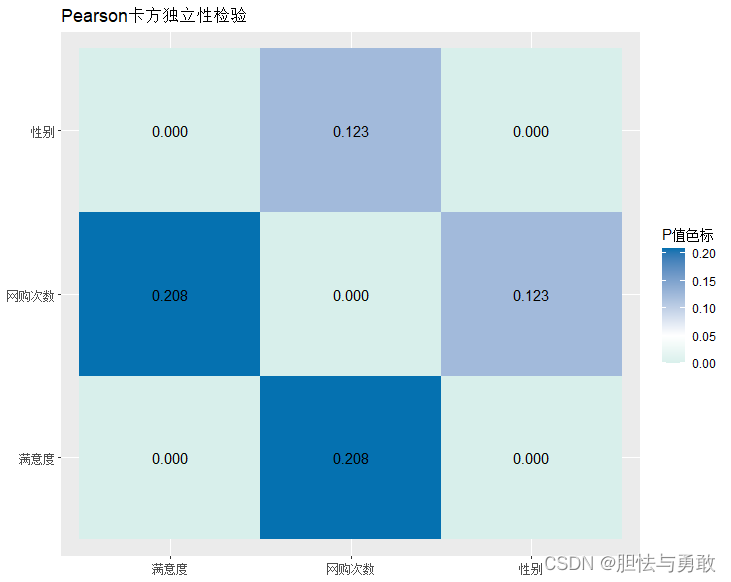
data3_1 <- read.csv("F://data/mydata/chap03/data3_1.csv")
library(sjPlot)
sjp.chi2(data3_1, show.legend=T, legend.title="P值色标",
title="Pearson卡方独立性检验")
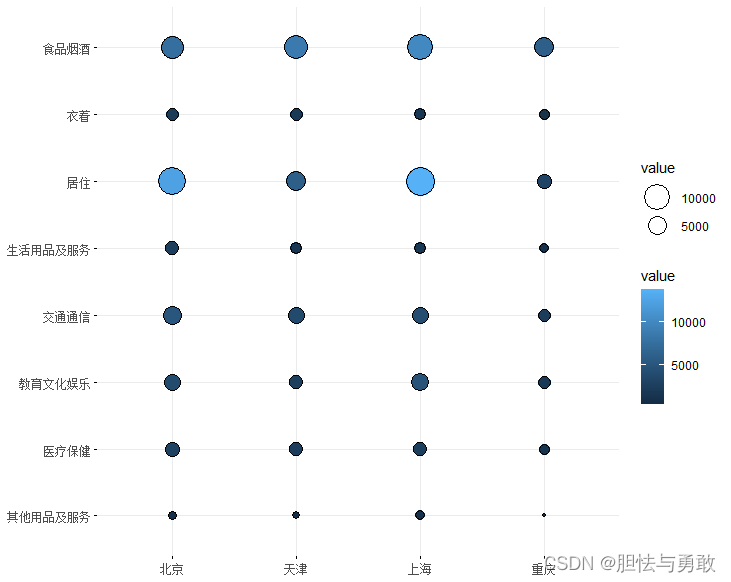
3.5 气球图和热图
library(ggplot2)
library(ggpubr)
library(RColorBrewer)
data3_2 <- read.csv("F://data/mydata/chap03/data3_2.csv")
mat <- as.matrix(data3_2[,2:5])
rownames(mat) <- data3_2[,1]
palette <- rev(brewer.pal(11, "Spectral"))
ggballoonplot(mat, fill="value", rotate.x.text=F,
scale_fill_gradientn(colors=palette))
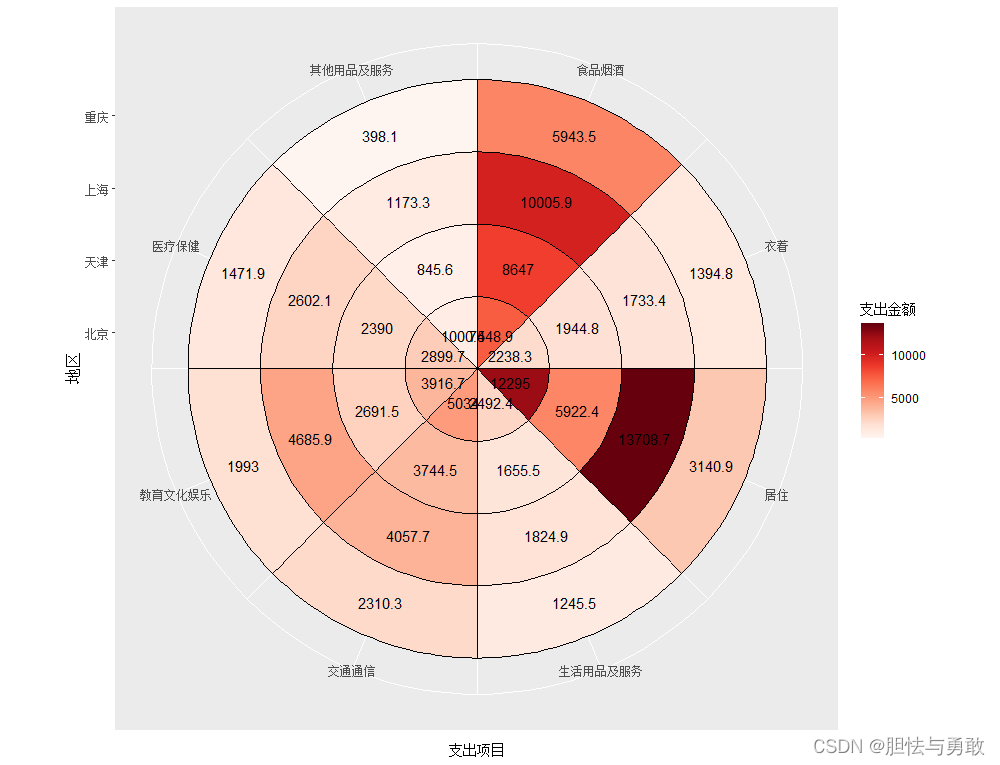
data3_1 <- read.csv("F://data/mydata/chap03/data3_1.csv")
ggiraphExtra::ggHeatmap(data3_1, aes(x=满意度,y=网购次数,facet=性别),
addlabel=T, palette="Oranges")

library(ggiraphExtra)
library(ggplot2)
data3_2 <- read.csv("F://data/mydata/chap03/data3_2.csv")
d.long <- reshape2::melt(data3_2, id.vars="支出项目",variable.name="地区",
value.name="支出金额")
f <- factor(data3_2$支出项目, ordered=T, levels=data3_2$支出项目)
df <- data.frame(支出项目=f, d.long[,2:3])
ggHeatmap(df, aes(x=支出项目,y=地区,fill=支出金额), polar=T,
addlabel=T, palette="Reds")
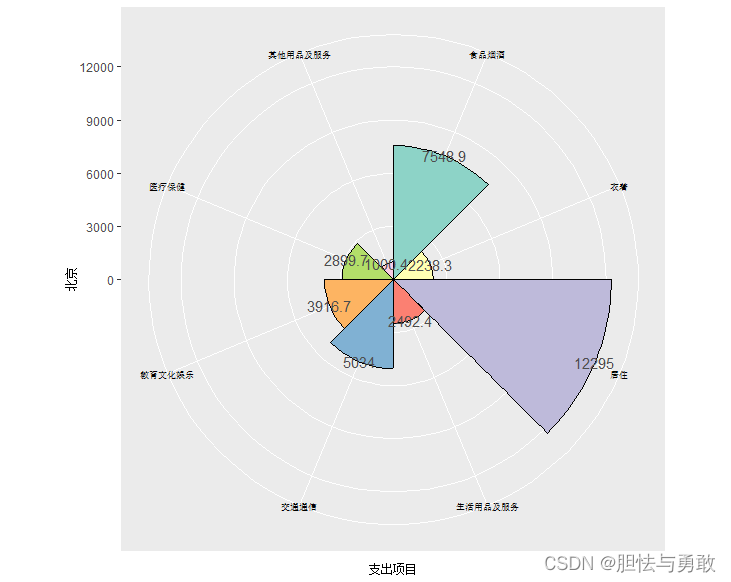
3.6 南丁格尔玫瑰图
library(RColorBrewer)
library(ggplot2)
data3_2 <- read.csv("F://data/mydata/chap03/data3_2.csv")
f <- factor(data3_2[,1], ordered=T, levels=data3_2[,1])
df <- data.frame(支出项目=f, data3_2[,2:5])
palette <- brewer.pal(8, "Set3")
ggplot(df, aes(x=支出项目, y=北京, fill=factor(北京))) +
geom_bar(width=1, stat="identity", colour="black", fill=palette) +
geom_text(aes(y=北京, label=北京), color="grey30") +
coord_polar(theta="x", start=0) +
theme(axis.title=element_text(size=8)) +
theme(axis.text.x=element_text(size=7, color="black"))
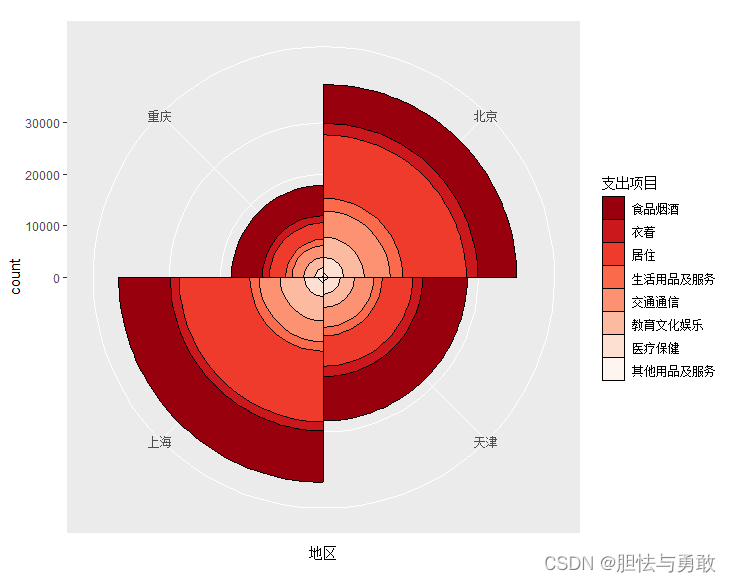
library(ggiraphExtra)
library(ggplot2)
data3_2 <- read.csv("F://data/mydata/chap03/data3_2.csv")
d.long <- reshape2::melt(data3_2, id.vars="支出项目", variable.name="地区",
value.name="支出金额")
f <- factor(data3_2[,1], ordered=T, levels=data3_2[,1])
df.rose <- data.frame(支出项目=f, d.long[,2:3])
ggRose(df.rose, aes(x=地区, fill=支出项目, y=支出金额),
stat="identity", reverse=T)
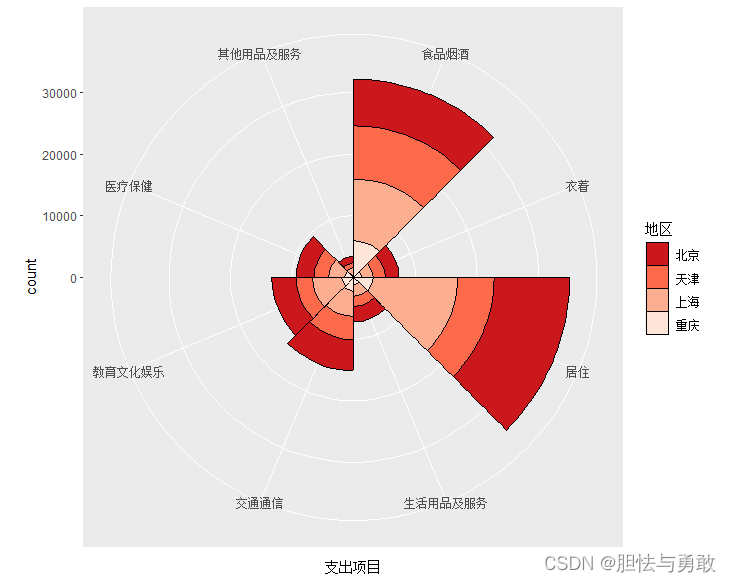
ggRose(df.rose, aes(x=支出项目, fill=地区, y=支出金额),
stat="identity", reverse=T)
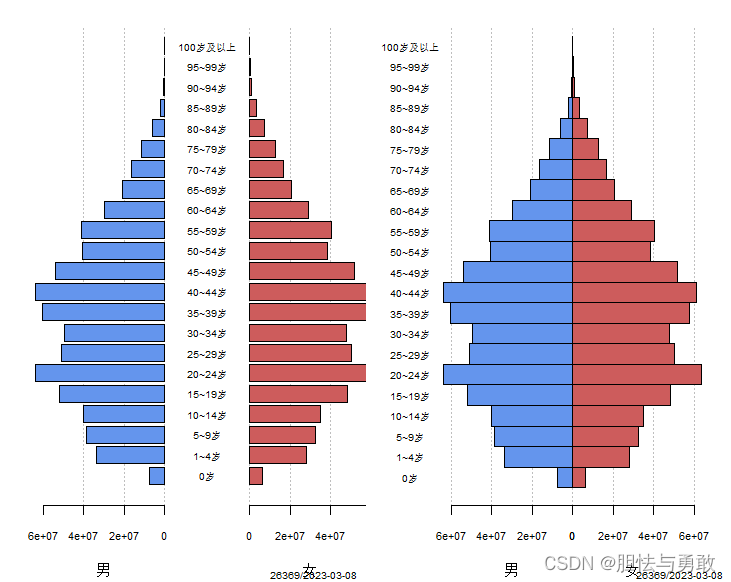
3.7 金字塔图
data3_3 <- read.csv("F://data/mydata/chap03/data3_3.csv")
library(DescTools)
par(mfrow=c(1,2), mai=c(0.8,0.7,0.3,0.2), cex.main=0.7, font.main=1)
PlotPyramid(lx=data3_3$男, rx=data3_3$女, col=c("cornflowerblue","indianred"),
lxlab="男", rxlab="女", ylab=data3_3[,1], ylab.x=0, cex.axis=0.7,
cex.names=0.6, adj=0.5)
PlotPyramid(lx=data3_3$男, rx=data3_3$女, col=c("cornflowerblue","indianred"),
lxlab="男", rxlab="女", ylab=data3_3[,1], ylab.x=-80000000,
gapwidth=0, space=0, cex.axis=0.7, cex.names=0.6, adj=0.5)
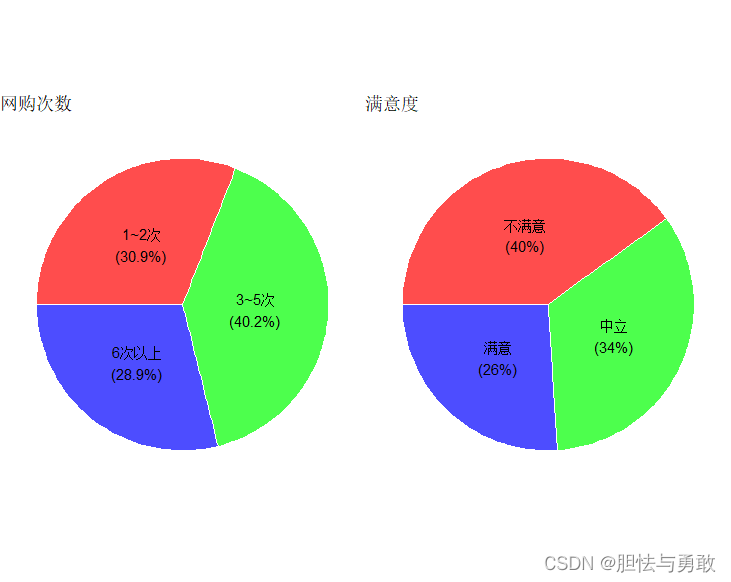
3.8 饼图及其变种
3.8.1 饼图和扇形图
library(ggiraphExtra)
library(ggplot2)
library(gridExtra)
data3_1 <- read.csv("F://data/mydata/chap03/data3_1.csv")
p1 <- ggPie(data=data3_1, aes(pies=网购次数), title="网购次数")
tab <- ftable(data3_1)
df <- as.data.frame(tab)
p2 <- ggPie(data=df, aes(pies=满意度, count=Freq), title="满意度")
grid.arrange(p1,p2,ncol=2)
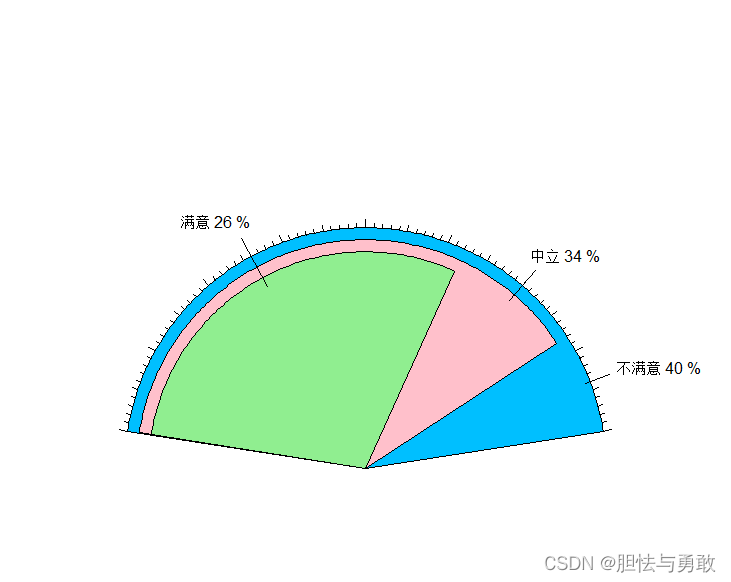
library(plotrix)
data3_1 <- read.csv("F://data/mydata/chap03/data3_1.csv")
tab <- table(data3_1$满意度)
name <- names(tab)
percent <- prop.table(tab)*100
labs <- paste(name, percent, "%", seq="")
fan.plot(tab, labels=labs, max.span=0.9*pi, shrink=0.06, radius=1.2,
label.radius=1.4, ticks=200, col=c("deepskyblue","lightgreen","pink"))
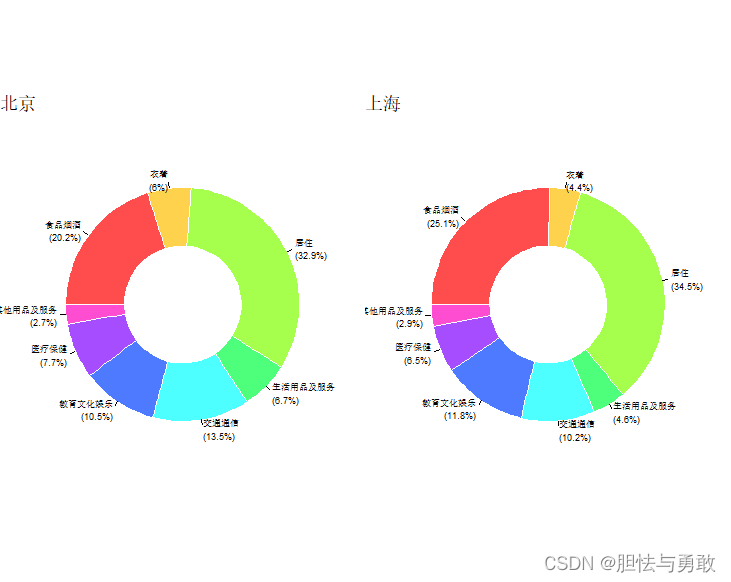
3.8.2 环状图和弧形图
library(ggiraphExtra)
library(ggplot2)
library(gridExtra)
data3_2 <- read.csv("F://data/mydata/chap03/data3_2.csv")
p1 <- ggDonut(data3_2, aes(donuts=支出项目, count=北京),
labelposition=1, labelsize=2.5, xmin=2, xmax=4,
title="北京")
p2 <- ggDonut(data3_2, aes(donuts=支出项目, count=上海),
labelposition=1, labelsize=2.5, xmin=2, xmax=4,
title="上海")
grid.arrange(p1,p2,ncol=2)
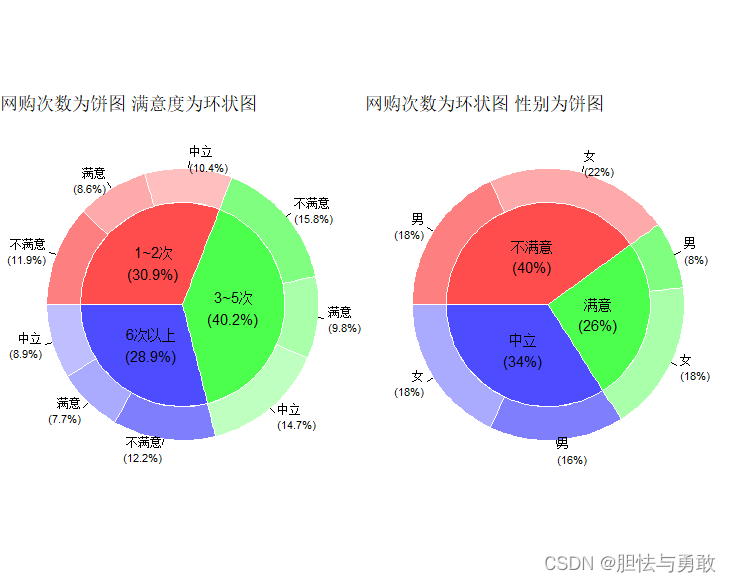
3.8.3 饼环图和旭日图
library(ggiraphExtra)
library(ggplot2)
library(gridExtra)
data3_1 <- read.csv("F://data/mydata/chap03/data3_1.csv")
p1 <- ggPieDonut(data3_1, aes(pies=网购次数, donuts=满意度),
title="网购次数为饼图 满意度为环状图")
p2 <- ggPieDonut(data3_1, aes(pies=满意度, donuts=性别),
title="网购次数为环状图 性别为饼图")
grid.arrange(p1,p2,ncol=2)
第4章 分布特征可视化
4.1 直方图
4.1.1 普通直方图
data4_1 <- read.csv("F:/data/mydata/chap04/data4_1.csv")
library(sjPlot)
plot_frq(data4_1$AQI,type="histogram",show.mean=T,
show.sd=T,geom.colors="green4")
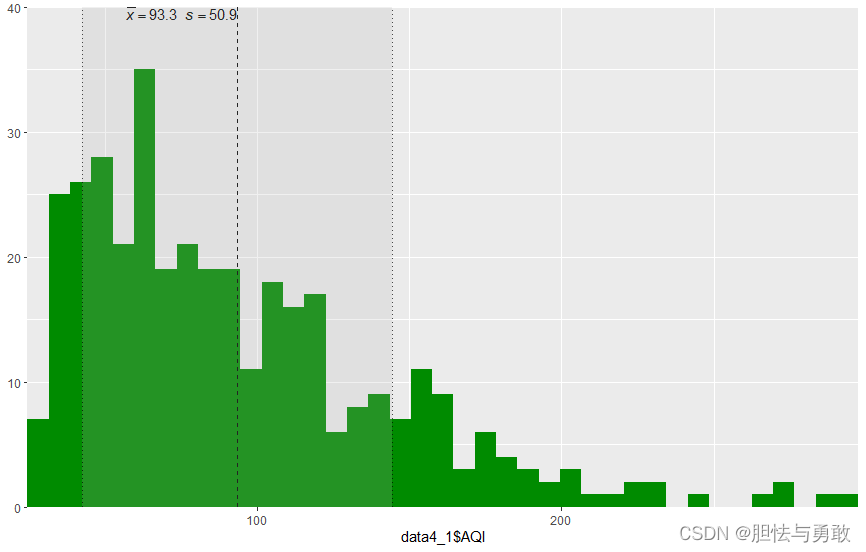
4.1.2 叠加直方图和堆叠直方图
data4_1 <- read.csv("F:/data/mydata/chap04/data4_1.csv")
labels <- c("优","良","轻度污染","中度污染","重度污染")
f <- factor(data4_1[,3],ordered=T,levels=labels)
df <- data.frame(质量等级=f,data4_1[,-3])
attach(df)
library(epade)
cols = c("green","yellow","orange","red","purple")
histogram.ade(PM2.5,group=质量等级,col=cols,wall=4,breaks=30,
bar=T,alpha=0.4)
detach(df)
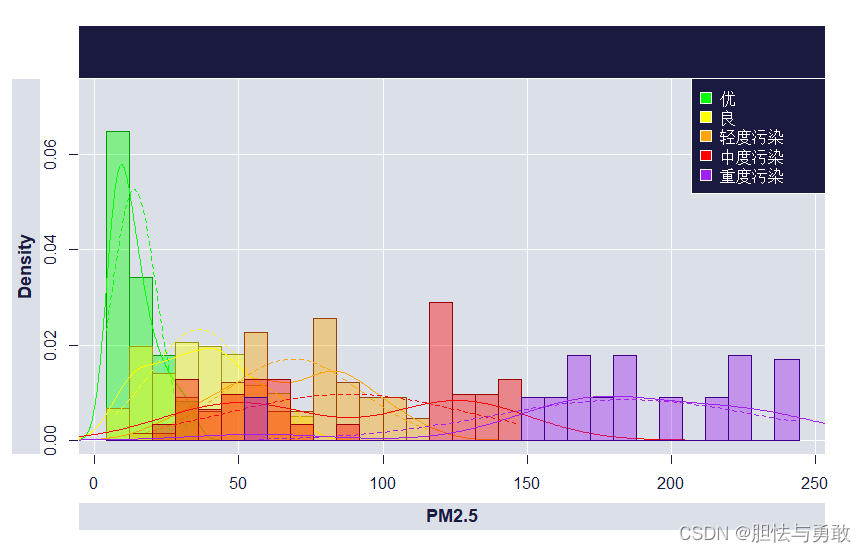
data4_1 <- read.csv("F:/data/mydata/chap04/data4_1.csv")
labels <- c("优","良","轻度污染","中度污染","重度污染")
f <- factor(data4_1[,3],ordered=T,levels=labels)
df <- data.frame(质量等级=f,data4_1[,-3])
par(mfrow=c(1,2),mai=c(0.6,0.6,0.4,0.1),cex.main=0.9,font.main=1)
library(plotrix)
cols = c("green","yellow","orange","red","purple")
histStack(PM10~质量等级,data=df,xlab="PM10",ylab="频数",ylim=c(0,80),
col=cols,legend.pos="topright",main="(a)PM10的堆叠直方图")
histStack(臭氧浓度~质量等级,data=df,xlab="臭氧浓度",ylab="频数",xlim=c(0,300),
ylim=c(0,70),col=cols,legend.pos="topright",main="(b)臭氧浓度的堆叠直方图")
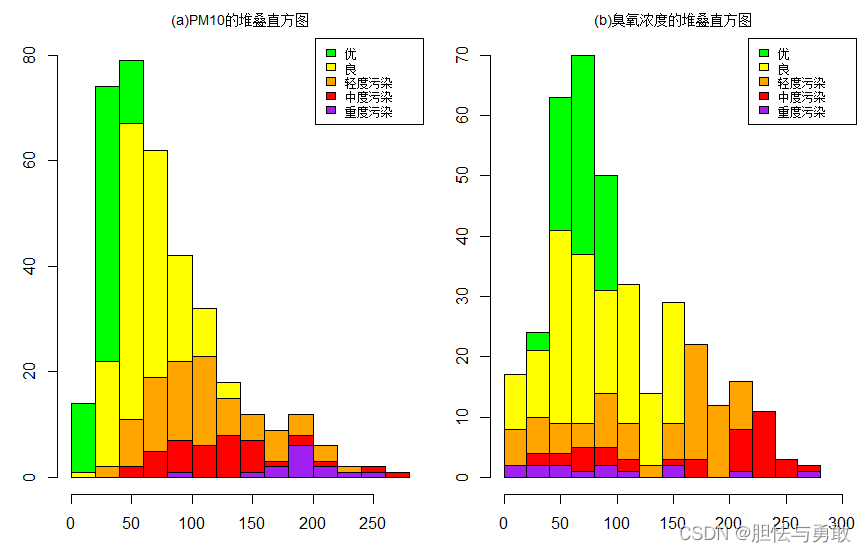
4.2 核密度图
4.2.1 核密度图和核密度比较图
data4_1 <- read.csv("F:/data/mydata/chap04/data4_1.csv")
library(sjPlot)
plot_frq(data4_1$AQI,type="density",normal.curve=T,normal.curve.size=2,
title="AQI的核密度图")
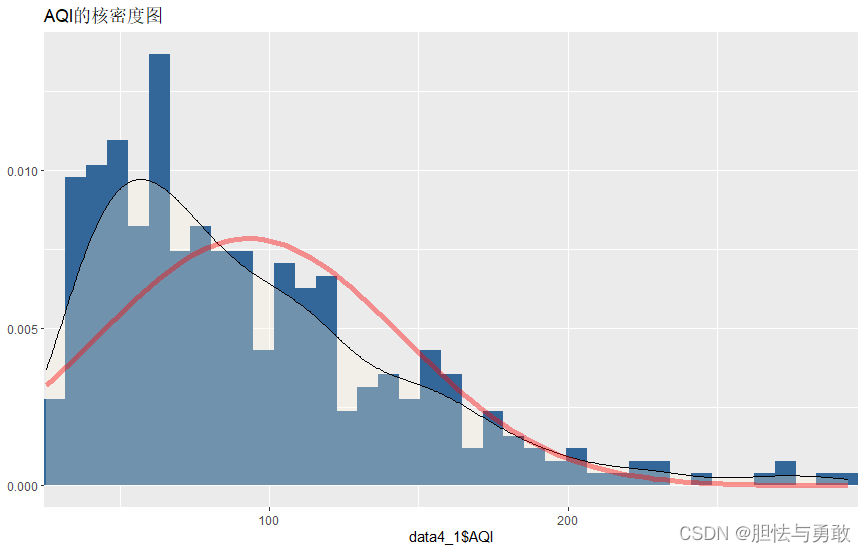
library(reshape2)
library(gridExtra)
library(ggplot2)
data4_1 <- read.csv("F:/data/mydata/chap04/data4_1.csv")
d <- data4_1[,c(1,2,3,4,5,8,9)]
df <- melt(d,id.vars=c("日期","质量等级"),variable.name="指标",
value.name="指标值")
mytheme<-theme(plot.title=element_text(size="9"), # 设置主标题字体大小
axis.title=element_text(size=9), # 设置坐标轴标签字体大小
axis.text=element_text(size=8), # 设置坐标轴刻度字体大小
legend.position="right", # 设置图例的位置
legend.text=element_text(size="7")) # 设置图例字大小
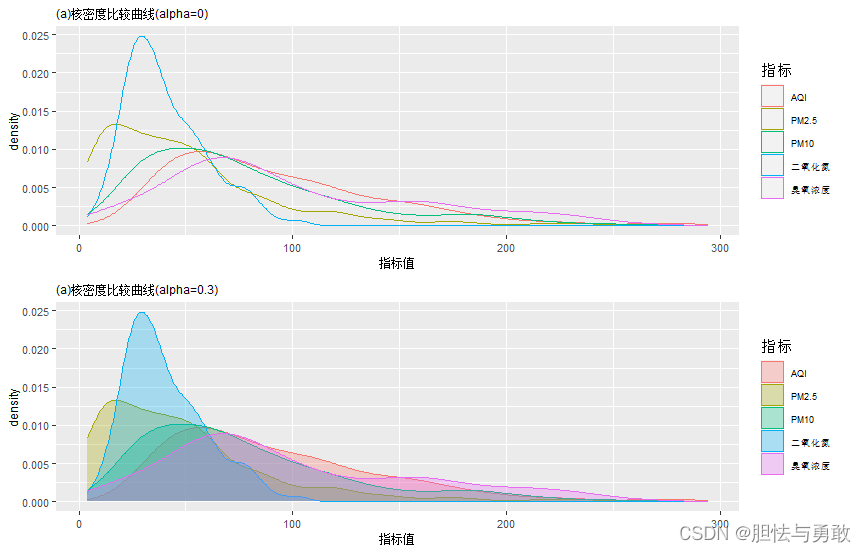
p1 <- ggplot(df) + aes(x=指标值) +
geom_density(aes(group=指标,color=指标,fill=指标),alpha=0) +
mytheme +
ggtitle("(a)核密度比较曲线(alpha=0)")
p2 <- ggplot(df) + aes(x=指标值) +
geom_density(aes(group=指标,color=指标,fill=指标),alpha=0.3) +
mytheme +
ggtitle("(a)核密度比较曲线(alpha=0.3)")
grid.arrange(p1,p2,ncol=1)
4.2.2 分类核密度图
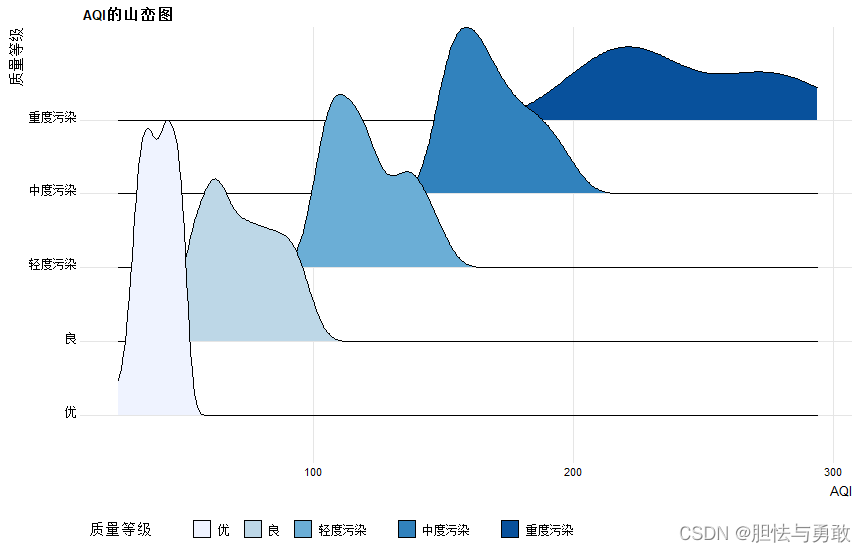
4.2.3 核密度山峦图
library(ggridges)
library(ggplot2)
data4_1 <- read.csv("F:/data/mydata/chap04/data4_1.csv")
labels <- c("优","良","轻度污染","中度污染","重度污染")
f <- factor(data4_1[,3],ordered=T,levels=labels)
df <- data.frame(质量等级=f,data4_1[,-3])
ggplot(df,aes(x=AQI,y=质量等级,fill=质量等级,height=..density..)) +
geom_density_ridges(scale=4,stat="density") +
scale_fill_brewer(palette="Blues") +
theme_ridges(font_size=10) +
theme(legend.position="bottom") +
labs(title="AQI的山峦图")
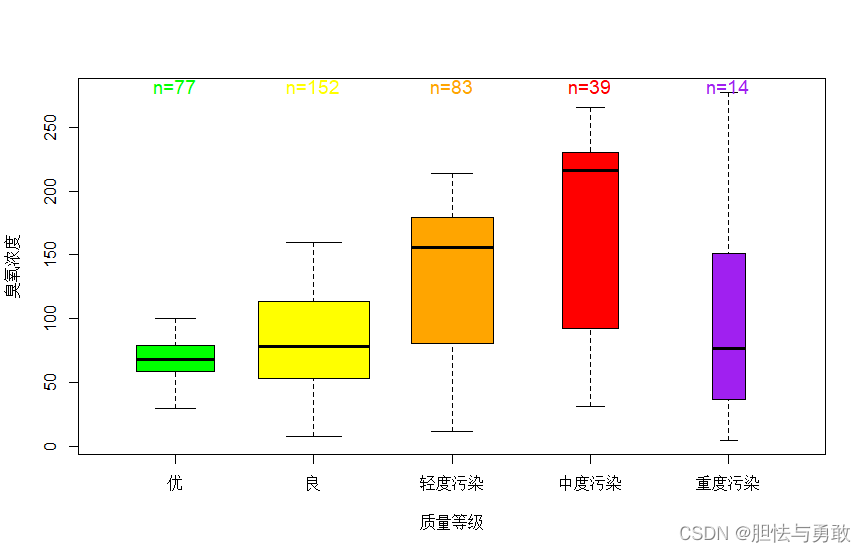
4.3 箱线图
data4_1 <- read.csv("F:/data/mydata/chap04/data4_1.csv")
labels <- c("优","良","轻度污染","中度污染","重度污染")
f <- factor(data4_1[,3],ordered=T,levels=labels)
df <- data.frame(质量等级=f,data4_1[,-3])
library(gplots)
cols = c("green","yellow","orange","red","purple")
boxplot2(data=df,臭氧浓度~质量等级,top=T,shrink=1.2,textcolor=cols,
col=cols,varwidth=T,xlab="质量等级",ylab="臭氧浓度")
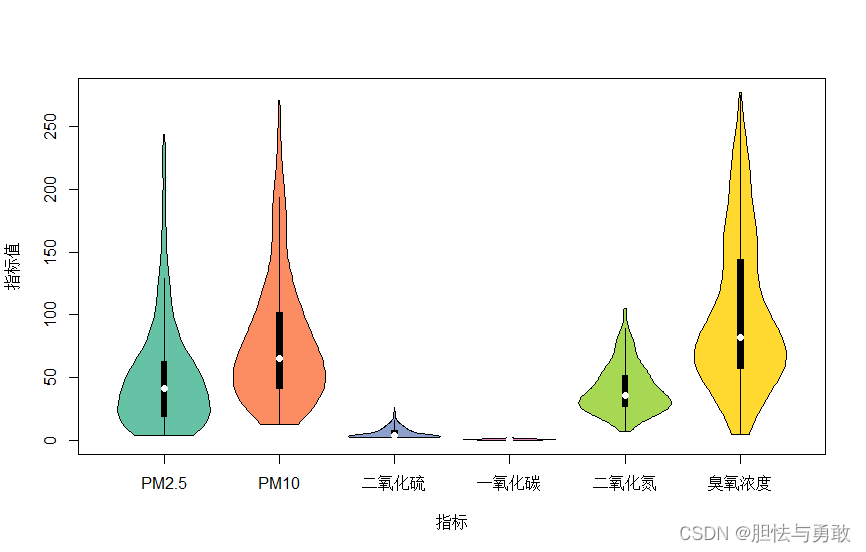
4.4 小提琴图
data4_1 <- read.csv("F:/data/mydata/chap04/data4_1.csv")
df <- data4_1[,4:9]
library(vioplot)
palette <- RColorBrewer::brewer.pal(6,"Set2")
names = c("PM2.5","PM10","二氧化硫","一氧化碳","二氧化氮","臭氧浓度")
vioplot(df,col=palette,names=names,xlab="指标",ylab="指标值")
4.5 茎叶图
4.6 点图
4.7 带状图
4.8 太阳花图
4.9 海盗图
4.10 分布概要图
# 分析一个变量
data4_1 <- read.csv("F:/data/mydata/chap04/data4_1.csv")
attach(data4_1)
library(DescTools)
PlotFdist(AQI,mar=c(0,0,0,0),main="",
args.hist=list(breaks=20,col=5),
args.rug=T,
args.dens=list(bw=6,col=4),
args.ecdf=list(cex=1.2,pch=16,lwd=2),
args.curve=list(expr="dnorm(x,mean=mean(AQI),sd=sd(AQI))",lty=6,col="grey60"),
args.curve.ecdf=list(expr="pnorm(x,mean=mean(AQI),sd=sd(AQI))",lty=6,lwd=2,col="grey60"))
detach(data4_1)
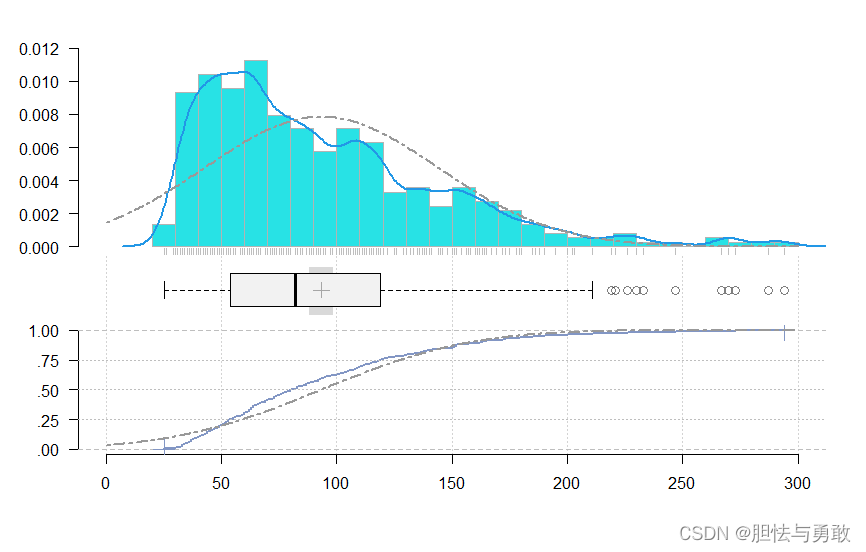
# 分析多个变量
data4_1 <- read.csv("F:/data/mydata/chap04/data4_1.csv")
library(aplpack)
plotsummary(data4_1[,4:9],
type=c("stripes","ecdf","density","boxplot"),
y.size=4:1,
design="chessboard",
mycols="RB",main="")



















 1433
1433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











