






研究过程
使用json库的lodas方法转换
首先来看一个没有变量的字符串的用法
import json
print(json.loads('{"code":500,"message":"请求失败!"}'))正常转换没有问题

然后看一个拼接转换的例子
import json
def test():
return "1"
a=test()
print(json.loads('{"code":500,"message":'+a+'}'))
来看看转换结果

也是没有问题的,但是如果我们把test的返回值该成带中英文字符的呢?
import json
def test():
return "a"
a=test()
print(json.loads('{"code":500,"message":'+a+'}'))
来看下结果
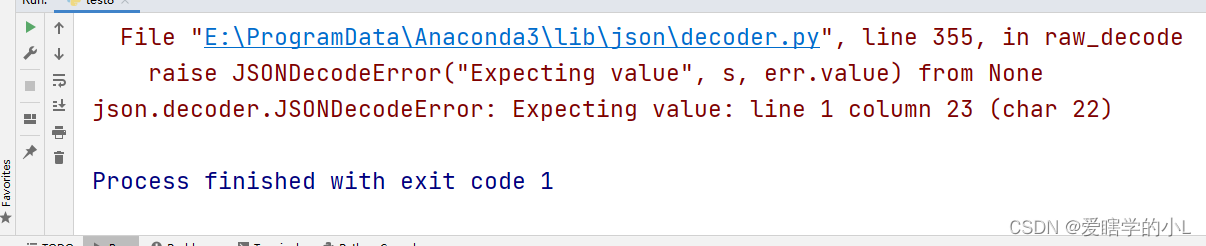
不出意外它报错了
解决
需要把这个返回的中英文字符处理一下
a=json.dumps(a, ensure_ascii=False)
print(json.loads('{"code":500,"message":'+a+'}'))查看结果

成功解决!!!
说一下为啥报错,在使用json.loads这个方法时json.dumps() 函数中的 ensure_ascii默认值是为True的,它会把所有非ASCII字符将被转义为形式如\uXXXX的Unicode转义序列,所以会出现错误。如果将 ensure_ascii 参数设置为 False,则 json.dumps() 将保留非ASCII字符的原始表示,而不进行转义。这在需要保留原始非ASCII字符时非常有用,比如处理包含多种语言字符的文本数据。















 757
757











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









