







深度学习day03 梯度下降算法
梯度下降算法通过不断改变权重的值,找到使损失函数最小时的权重,权重每次改变的方向是梯度的反方向,也是函数下降最快的方向,每次改变的大小是权重=当前权重-学习率*当前梯度。所以进行梯度下降时需要知道损失函数关于当前权重的偏导数。
穷举法和分治法的局限性
- 使用穷举法需要的数据测试量是巨大的,未知量多了就会计算力不够
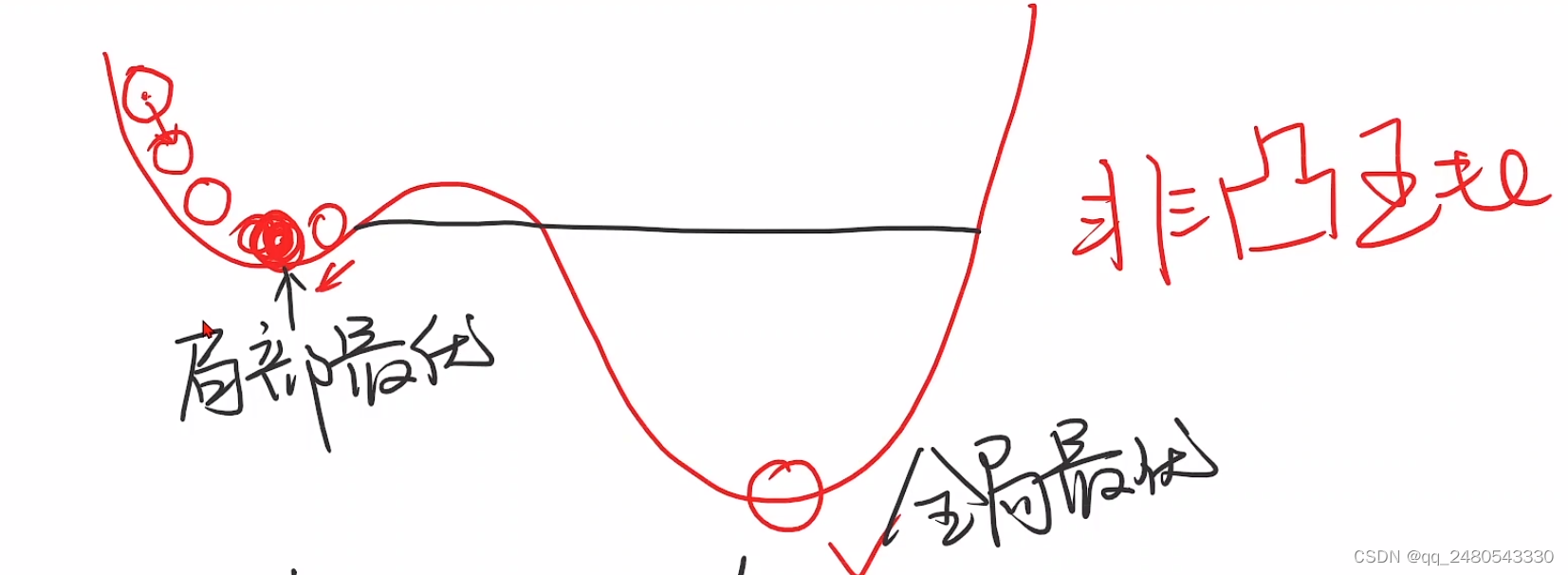
- 使用分治法要求数据分布单调(凸函数),否则容易陷入局部最优解
所以我们需要另外一种寻找目标函数最小值的权重组合的优化算法-梯度下降算法(贪心思想)
梯度和学习率
梯度:在每一次学习迭代中使用反向传播算法计算损失函数对每一个权重或偏置的导数
从权重或偏置中减去这个梯度方向的标量值以降低网络的损失。由于梯度的反方向是函数下降最快的方向,为了控制参数调整的速度,算法使用梯度乘以一个步长来当作参数的修正量,这个步长又叫做学习率,即梯度 * 学习率作为参数的修正量
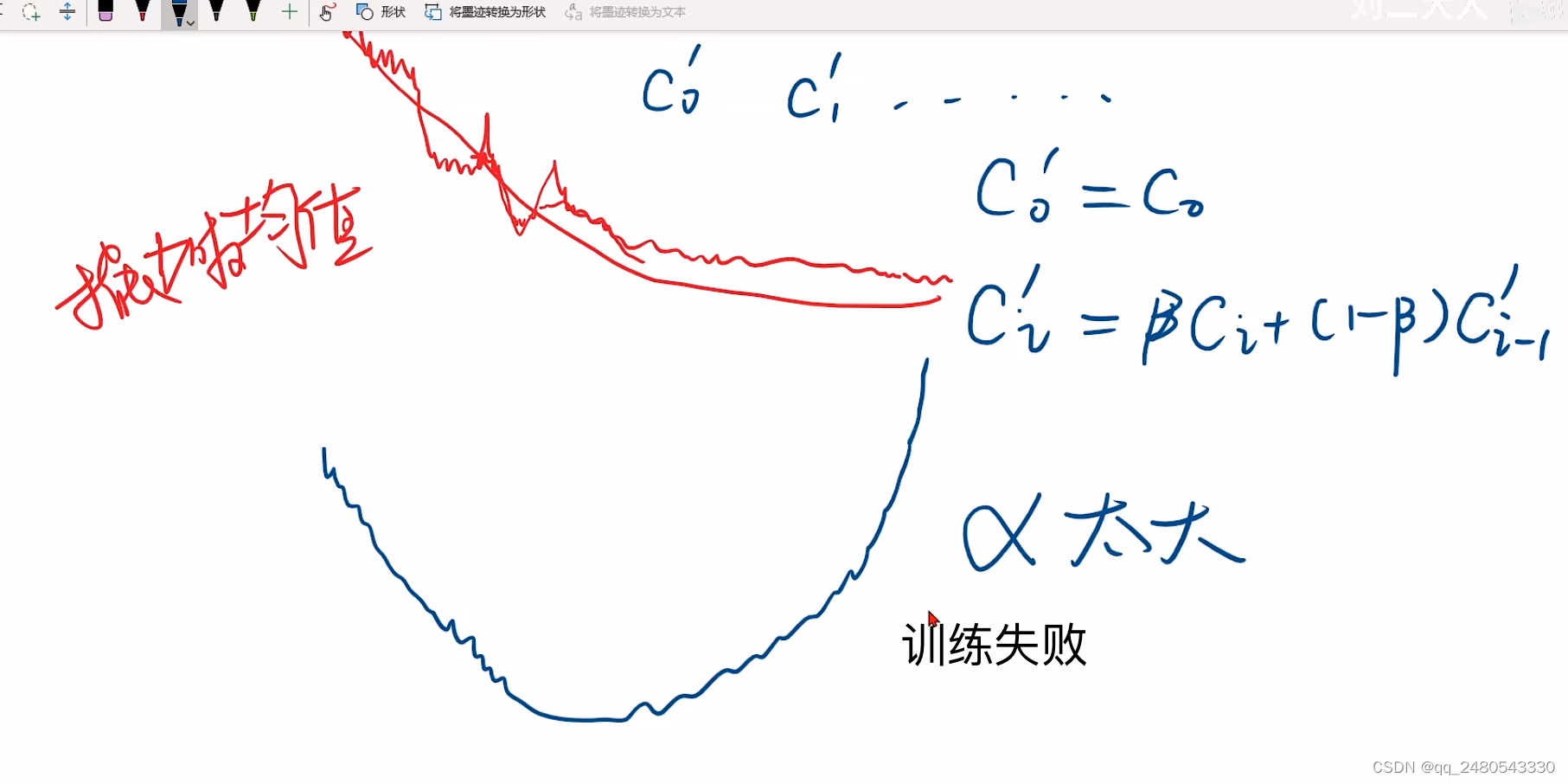
学习率作为控制网络学习速度的超参数,设置过小则模型的收敛速度就会变得很慢,设置过大则会发生振荡导致网络无法收敛。因此通常在训练开始时使用较大的学习率以加快训练速度,等逐渐接近损失最小值点时再采用较小的学习率使网络收敛
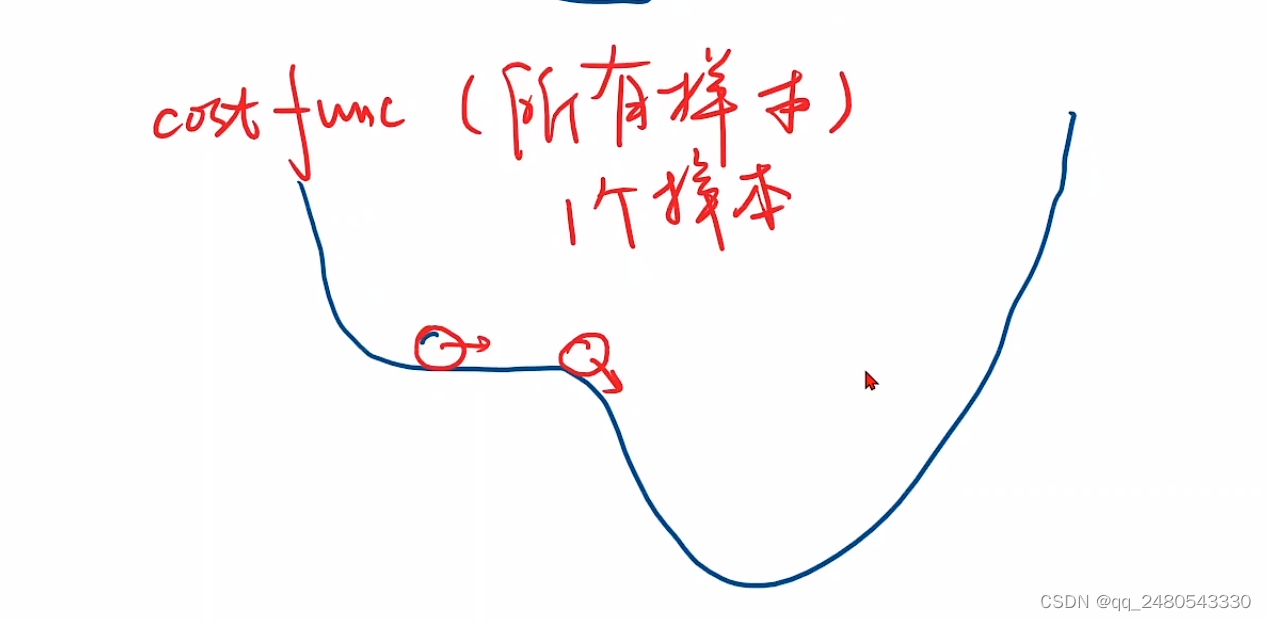
局部最优点和鞍点
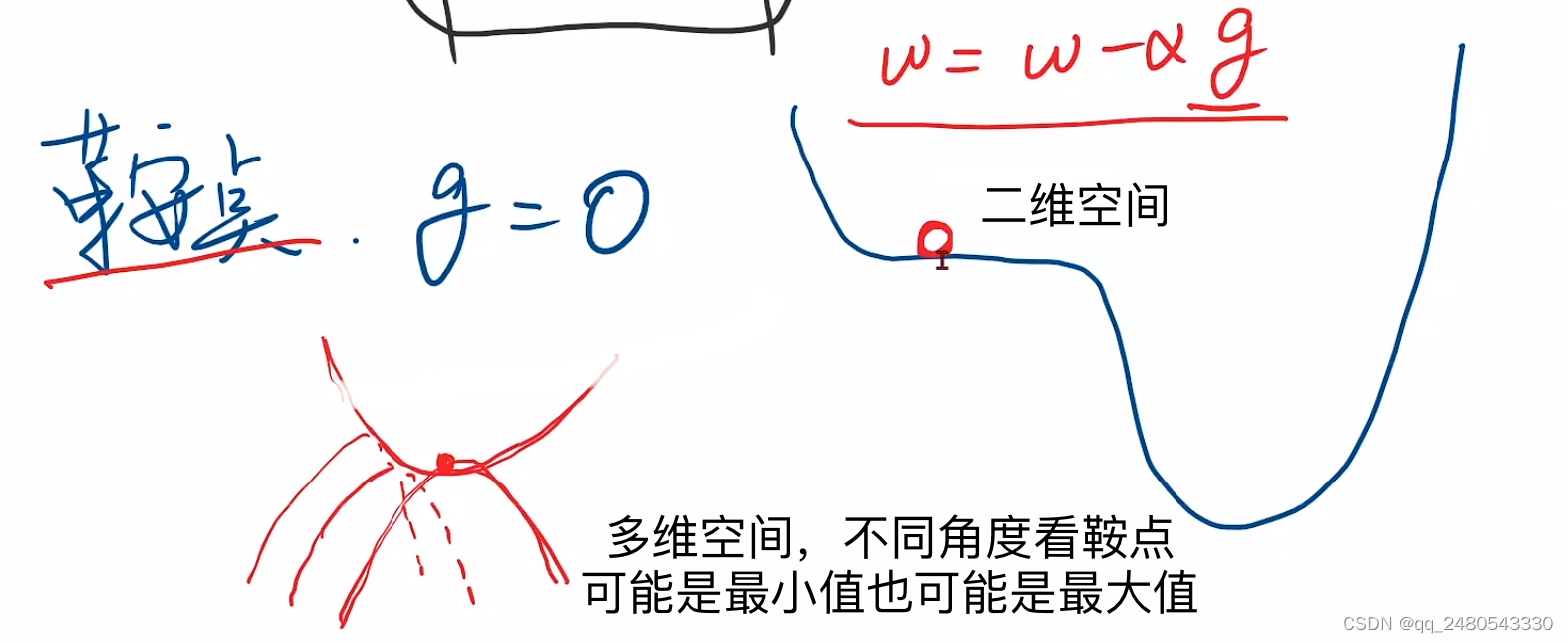
梯度下降算法数学原理

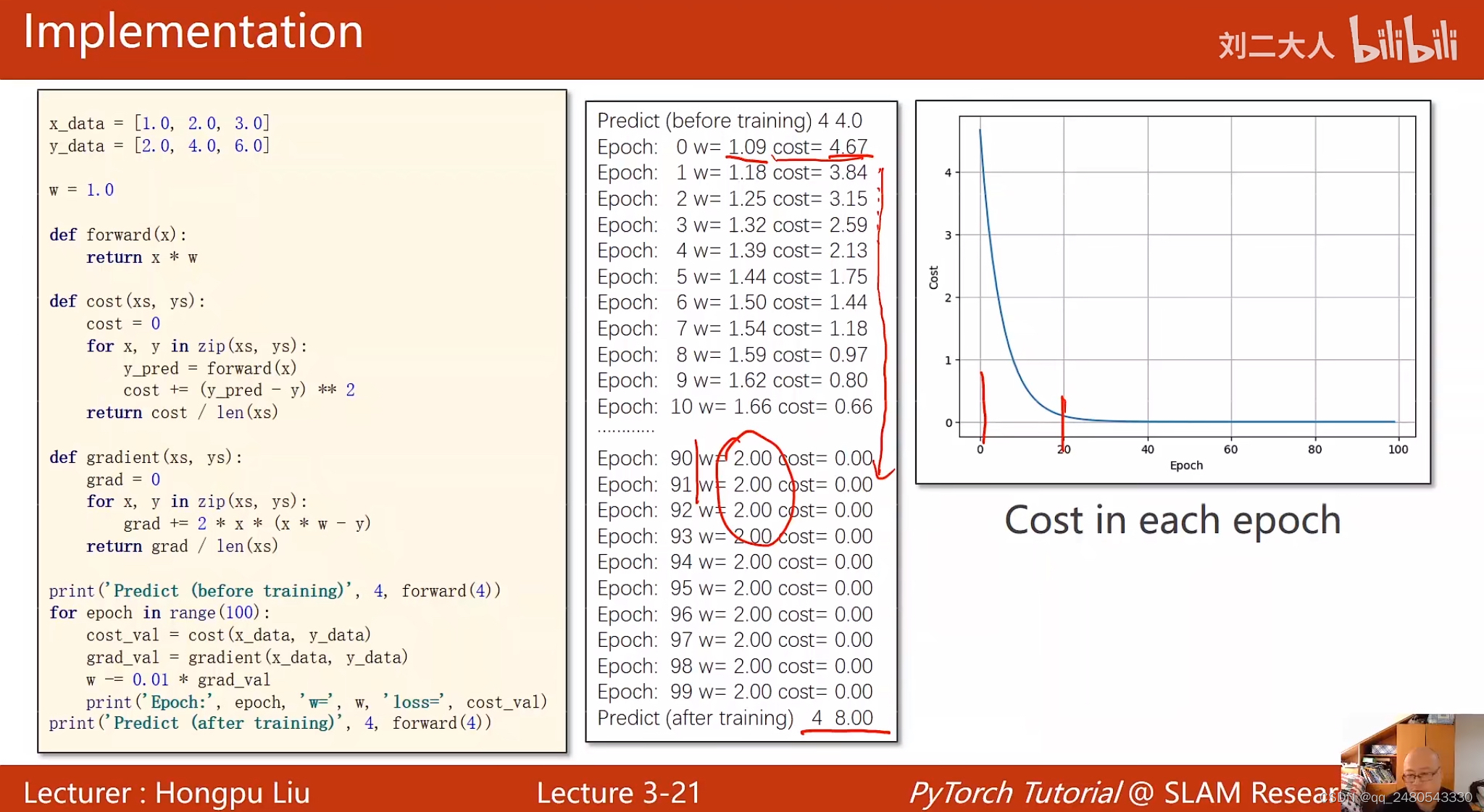
梯度下降算法代码实现
常见的问题
随机梯度下降
梯度下降的损失函数是一次性选取所有样本的损失的均值,而随机梯度下降的损失函数,是每次随机从所有样本中选取出一个样本的损失。
核心:要求出最终的损失关于每一个权重的导数(梯度),然后对每一个权重进行更新

梯度下降的梯度是根据所有数据计算好的,不会变化,碰到鞍点一直是0,不论怎么增加更新次数,w的值不会变化,而随机梯度下降引入了随机噪声,梯度是根据每个数据实时更新的,会变化,可能会跨越鞍点,在神经网络中已经被证实十分有效。
随机梯度下降代码

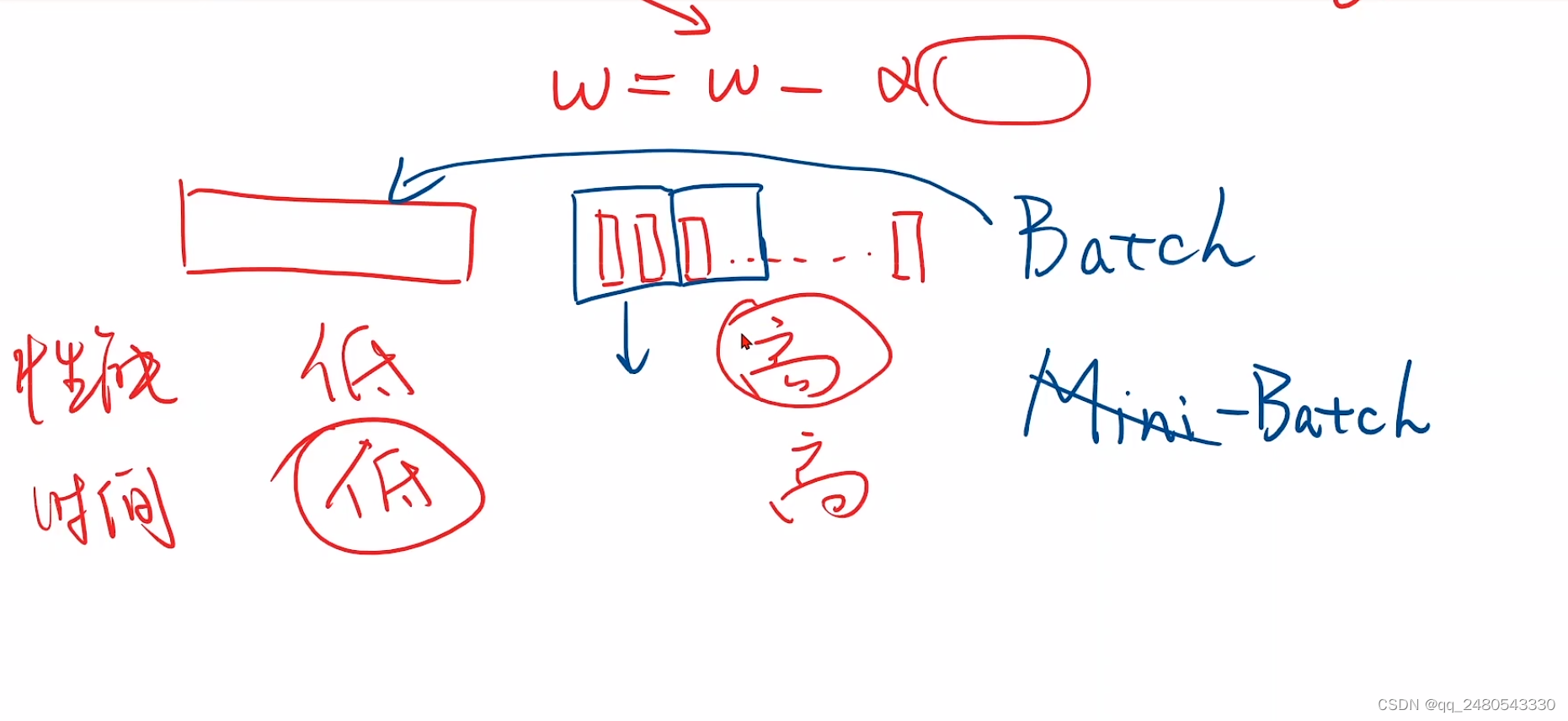
小批量随机梯度下降
若干个样本一组,每次用一组样本的平均损失函数去更新权重
结合梯度下降和随机梯度下降的优缺点,提出了批量梯度下降算法,即节省时间,计算也较准确。批量梯度下降算法也是目前神经网络中的主流优化算法。















 416
416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









