






一、数据库概述
数据库(DataBase,DB):存储在磁带、磁盘、光盘或其他外存介质上、按一定结构组织在一起的相
关数据的集合。
数据库管理系统(DataBase Management System,DBMS):-种操纵和管理数据库的大型软件,用
于建立、使用和维护数据库。
数据库系统(DataBase System,DBS):通常由软件、数据库(DB)和数据库管理员组成。软件主要包
括操作系统、各种宿主语言、实用程序以及数据库管理系统(DBMS)数据库(DB)由数据库管理系统
(DBMS)统一管理,数据的插入、修改和检索均要通过数据库管理系统(DBMS)进行。数据库管理员
负责创建、监控和维护整个数据库,使数据能被任何有权使用的人有效使用。

二、数据库分类
①关系型数据库
关系型数据库模型是把复杂的数据结构归结为简单的二元关系(即二维表格形式)。通过SQL结构化
查询语句存储数据,保持数据一致性,遵循ACID理论。关系型数据库的典型产品:MySQL、
Microsoft SQL Server、Oracle、PostgreSQL、IBM DB2、Access等。非关系型数据库
②非关系型数据库
也被成为NOSQL数据库,NOSQL的本意是“NotOnly SQL'指的是非关系型数据库,而不是
“NoSQL”的意思。因此,NOSQL的产生并不是要彻底地否定关系型数据库,而是作为传统关系型
数据库的一个有效补充。NOSQL数据库在特定的场景下可以发挥出难以想象的高效率和高性能。
非关系型数据库的典型产品:Memcached、Redis、mongoDB等。
三、ACID理论
①原子性(Atomicity):事务是一个不可分割的单位,事务中的操作要么都发生要么都不发生。
②一致性(Consistency):事务前后数据的完整性必须保持一致。
③隔离性(lsolation):多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事
务的操作数据所干扰,多个并发事务之间要相互隔离。
④持久性(Durability):一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数
据库发生故障也不应该对其有任何影响。
四、MySQL数据库连接方法
1.命令行连接:[root@host]#mysql -h XXXX-u root -p
2.PHP脚本连接:mysqli connect(host,username,password,dbname,port,socket);
3.第三方软件连接
五、识别数据库
1、识别数据库方法
盲跟踪
①Web应用技术
②不同数据库SQL语句差异
2、非盲跟踪
报错、直接查询
六、默认端口号
Oracle:1521
MySQL:3306
MySQL报错信息:

SQL Server:1433
MSSQL(Microsoft SQLServer)报错信息

PostgreSQL:5432
mongoDB:27017
Redis:6379
MemcacheDB:11211
七、各数据库的版本查询方法区别
①MSSQL select @@version
②MySQL select version()/select @@version
③Oracle select banner from v$version
④PostgreSQL select version()
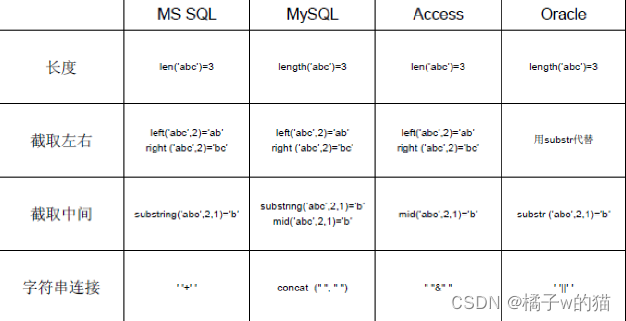
八、各数据库在字符串处理时的区别
九、各数据库与网页编程语言的搭配
常见的搭配:
①ASP和.NET:Microsoft SQL Server
②PHP:MySQL、PostgreSQL
③Java:Oracle、MySQL
十、sql语法基础
用于与关系型数据库交互的标准 SQL 命令有CREATE、SELECT、INSERT、UPDATE、
DELETE和DROP
分为三组
1.数据定义(Create、Drop)
2.数据操纵(Select、Insert、Update、 Delete)
3.数据控制(Grant、Revoke)

①SQL基本操作:CUD
C=Create 创建
CREATE DATABASE testdb;
CREATE TABLE table name (column name column type);
U=Update 更改
UPDATE table name SET field1=new-value1, field2=new-value2 [WHERE Clause]
D=Delete 删除
DELETE FROM table name [WHERE Clause]
创建数据库 create database 数据库名
show databases 显示所有数据库
创建表create table 表名
show tables 显示所有表名
向数据表中添加数据 insert into 表名(列名1,列名2...)values(列值1,列值2..);
修改数据表中某一行数据 update 表名 set 列名=列新值 where 条件
显示表信息 select * from 表名;
删除表中某行数据 delete from 表名 where 条件
SQL高级操作:排序,分组,限定条数
①排序 order by
SELECT * FROM test table ORDER BY userid;
②分组 group by
SELECT name,COUNT(*) FROM test table GROUP BY name;
SELECT username, MAX(password) AS password FROM users GROUP BY username;
错误查询语句:select product,price from orders group by product
正确査询语句:select product,sum(price)from orders GROUP BY product
③限定条数 limit
SELECT* FROM test table limit 0,10;
SELECT * FROM test table limit 1,5;
④联合查询 union select
SELECT * FROM test table UNION SELECT 1,2,3;
select * from users where username='a2' and 1=1 union select 1,password from users;
因为查询语句构造问题,可直接否认掉之前的查询,构造-全新的语句来执行,需要注意的是查询
的列应当和之前对应。知道列名后,把列名至于其中任意位置,就能在那个位置暴出列的内容来。
⑤结合其他函数
1、结合exists()函数猜解表名 and exists(select ...)exists()函数用于检查子查询是否至少会返回一行数
据。实际上不返回任何数据,而是返回True或者False


①union 结合系统函数暴数据库信息
information_schema.SCHEMATA表中的SCHEMA NAME 查看所有的数据库名:
SELECT * FROM users WHERE username='a2' AND 1=2 UNION SELECT 0, schema_name
FROM information_schema.schemata;

前提:需要足够的权限才可执行
②information schema.TABLES 表中的TABLE NAME和TABLE SCHEMA查看所有的表名和所在的
数据库:
SELECT TABLE_NAME, TABLE_SCHEMA FROM information_schema.TABLES WHERE
TABLE_SCHEMA = 'security';
2、结合load file()读取服务器文件内容
函数 LOAD FILE(file name):读取文件并将文件内容按照字符串的格式返回。
前提条件:
①文件的位置必须在服务器上,必须为文件制定路径全名,而且必须拥有FILE特许权(MVSQL配置
文件中,secure file priv不能为NULL)
②文件必须可读取,文件容量必须小于 max allowed packet 字节
③若文件不存在,或因不满足上述条件而不能被读取,则函数返回值为 NULL
load file()用在MySQL中可以在UNOIN中充当一个字段,读取Web服务器的文件。
SHOW VARIABLES LIKE 'secure_file_priv';//查看权限
设置权限:[mysqld] secure_file_priv = '',重启mysql生效
示例:
服务器上文件:"c:/test.txt",里面内容是:"i am ok",用load file读取出来
SELECT * FROM users WHERE username='a2' AND 1=2 UNION SELECT 0, LOAD_FILE("/root/桌面/1.txt") FROM users;v
注意权限(此处在usr/tmp下可以)

查看当前所属数据库 select database();
查看数据库版本:select version();
十一、执行顺序:
当查询语句同时出现了where,group by, having,order by的时候,执行顺序和编写顺序是:
1.执行where xx对全表数据做筛选,,返回第1个结果集。
2.针对第1个结果集使用group by分组,返回第2个结果集。
3.针对第2个结果集中的每1组数据执行select xx,有几组就执行几次,返回第3个结果集。
4.针对第3个结集执行having xx进行筛选,返回第4个结果集。
5.针对第4个结果集排序。















 784
784











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









