






字符串归根结底是一个序列,是一个像元组那样不可变的序列。
切片
既然字符串是一个序列,那么在字符串中也可以使用切片。
判断回文数。
x = "12321"
print("是回文数" if x==x[::-1] else "不是回文数")
x = "12345"
print("是回文数" if x==x[::-1] else "不是回文数")
大小字母转换
.capitalize()方法
该方法是将字符串的首字母变为大写,其他字母变为小写。其返回值并不是源字符串,因为源字符串不可改变,所以其返回值是按照此规则来生成的一个新的字符串。
x = "i love you"
print(x.capitalize())

.casefold()方法
该方法是生成一个所有字母都是小写的新字符串。
x = "I Love You"
print(x.casefold())![]()
.title()方法
该方法是将字符串的每个单词的首字母变为大写,该单词的其他字母都变成小写。
x = "i lovE yOu"
print(x.title())
![]()
.swapcase()方法
该方法是将字符串中的所有字母大小写反转。
x = "i lovE yOu"
print(x.swapcase())
![]()
.upper()方法
该方法是将字符串中所有的字母变成大写。
x = "i lovE yOu"
print(x.upper())![]()
.lower()方法
该方法是将字符串中所有的字母变成小写。
x = "i lovE yOu"
print(x.lower())
注意:lower和casefold方法存在区别。lower只能处理英文字母,而casefold除了可以处理英文之外还可以处理更多其他语言的字符。
x = "ß"
print(x.lower())
print(x.casefold()) 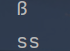
左中右对齐
所有的方法都会存在一个width参数,如果指定的宽度小于或者等于源字符串,则不存在对其,直接输出源字符串即可。
center(width,fillchar=' ')方法
根据width值,将字符串居中显示。
x = "有内鬼,停止交易!"
print(x.center(5))
print(x.center(15))
ljust(width,fillchar=' ')方法
将字符串左对齐。
rjust(width,fillchar=' ')方法
将字符串右对齐。
x = "有内鬼,停止交易!"
print(x.ljust(15))
print(x.rjust(15))

zfill(width,fillchar=' ')方法
用0去填充左侧。
x = "有内鬼,停止交易!"
print(x.zfill(15))![]()
该方法经常用于使用做数据报表。
x = "520"
y = "-1314"
print(x.zfill(7))
print(y.zfill(7))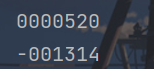
注意:fillchar的参数值默认是空格,即用空格来进行填充。
查找
count(sub[,start[,end]])方法
该方法用于查找sub参数指定的子字符串在字符串中出现的次数。start和end用于指定查找的起始和结束位置。
x = "上海自来水来自海上"
print(x.count("海"))
print(x.count("海",0,5))
find(sub[,start[,end]])方法、rfind(sub[,start[,end]])方法
该方法是用于定位sub参数指定的子字符串在字符串中的索引下标值,find是从左往右找,而rfind是从右往左找。
x = "上海自来水来自海上"
print(x.find("海"))
print(x.rfind("海"))
index(sub[,start[,end]])方法、rindex(sub[,start[,end]])方法
与find和rfind方法类似。区别是如果定位不到子字符串,那么处理方法是不一样的。find和rfind会返回-1,index和rindex会抛出异常。
x = "上海自来水来自海上"
print(x.find("龟"))
x = "上海自来水来自海上"
print(x.index("龟"))
替换
expandtabs([tabsize=n])方法
该方法的作用是使用空格来替换制表符,并且返回一个新的字符串。参数tabsize指定一个制表符被替换为几个空格。

注意:在编写代码时,不要混用制表符和空格!
replace(old,new,count=-1)方法
该方法返回一个将所有old参数指定子字符串替换为new参数指定的新字符串,count参数是指定的替换的次数,count默认值为-1,即如果不设置count,就相当于替换全部。
x = "在吗,我在你家楼下,快点下来"
print(x.replace("在吗","想你"))![]()
translate(table)方法
该方法是返回一个根据tab参数转换后的新字符串。tab表格的生成需要使用str.maketrans(x[,y[,z]])方法来获取此表格。
x = "I love you"
table = str.maketrans("ABCDEFGHIJ","0123456789")
print(x.translate(table))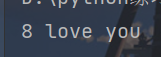
其中被匹配到的大写字母I会被替换为8。
其实在maketrans方法中还有第三个参数,其为需要忽略的字符。
x = "I love KIVEN"
table = str.maketrans("loveEFGHIJ","0123456789","love")
print(x.translate(table))![]()
判断和检测
以下的方法都是返回布尔类型的值。
startswith(prefix[.start[.end]])方法
用于判断参数指定的字符串是否出现在字符串的起始位置。
x = "I love python"
print(x.startswith("I"))
print(x.startswith("l"))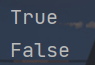
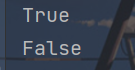
endswith(suffix[,start[,end]])方法
用于判断参数指定的字符串是否出现在字符串的结束位置。
x = "I love python"
print(x.endswith("python"))
print(x.endswith("java"))
注意:若参数带有方括号,这就相当于这是一个可选参数。
start和end参数是用来限定查找字符串的起始和结束位置的。
这两个函数的参数其实是支持以元组的形式传入多个待匹配的字符串的。即会与多个字符串元素进行匹配,若能与其中的一个或者多个字符串匹配成功,则返回True。
x = "她爱python"
if x.startswith(("你","我","她")):
print("总有人喜爱python")![]()
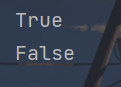
istitle()方法
该方法是判断一个字符串中所有的单词是否都是以大写字母开头,其余字母均为小写。
x = "I Love Python"
y = "i love pthon"
print(x.istitle())
print(y.istitle())
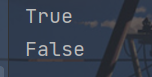
isupper()方法
该方法用于判断一个字符串中是否所有的字母都是大写字母。
x = "I LOVE PYTHON"
y = "i love pthon"
print(x.isupper())
print(y.isupper())
注意:当一个语句中连续调用多个方法,python会从左往右依次调用。
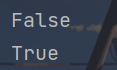
islower()方法
该方法用于判断一个字符串中是否所有的字母都是大写字母。
x = "I LOVE PYTHON"
y = "i love pthon"
print(x.islower())
print(y.islower())
isalpha()方法
该方法用于判断该字符串是否只由英文构成。
x = "ILovePython"
y = "我LovePython"
print(x.isalpha())
print(y.isalpha())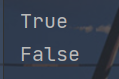
注意:空格不是字母。
isspace()方法
该方法用于判断字符串是否为空白字符串。
x = ""
y = " "
print(x.isspace())
print(y.isspace())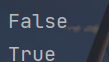
注意:空字符串并不是空白字符串。但是使用Tab和换行符等,也是空白字符串。
isprintable()方法
该方法用于判断一个字符串中是否所有字符都是可打印的。
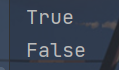
x = "python"
y = "python\n"
print(x.isprintable())
print(y.isprintable())
isdecimal()方法、isdigit()方法、isnumberic()方法
x = "12345"
print(x.isdecimal())
print(x.isdigit())
print(x.isnumeric())
print()
y = "2²"
print(y.isdecimal())
print(y.isdigit())
print(y.isnumeric())
print()
z = "ⅠⅡⅢⅣⅤ"
print(z.isdecimal())
print(z.isdigit())
print(z.isnumeric())
print()
a = "一二三四五"
print(a.isdecimal())
print(a.isdigit())
print(a.isnumeric())
print()
b = "壹贰叁肆伍"
print(a.isdecimal())
print(a.isdigit())
print(a.isnumeric())


注意:并不是接受的范围越大越好,需要根据自己的程序需要进行选择。
isalnum()方法
是前面方法的集大成者。只要是isalpha()方法、isdecimal()方法、isdigit()方法和isnumeric()方法中任意一个返回true,那么isalnum()方法就返回true。
isidentifier()方法
用于判断一个字符串是否是合法的python标识。
x = "I am a good boy"
print(x.isidentifier())
y = "I_am_a_good_boy"
print(y.isidentifier())
z = "123Kiven"
print(z.isidentifier())
a = "Kiven123"
print(a.isidentifier())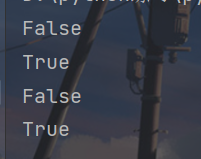
额外知识:
如果想要判断一个字符串是否为python的保留标识符(if、for等关键字),那么可以使用keyword模块中的iskeyword函数。
import keyword
x = "if"
print(keyword.iskeyword(x))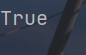
截取
lstrip()方法
该方法是让指定指定字符串左侧不留白。
x = " 左侧不留白"
print(x.lstrip())![]()
rstrip()方法
该方法是让指定指定字符串左侧不留白。
x = "右侧不留白 "
print(x.rstrip())
strip()方法
该方法是让指定指定字符串左侧右侧都不留白,strip不写l或者r。
x = " 都不留白 "
print(x.strip())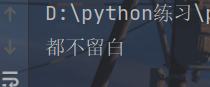
以上函数都有chars参数,其默认情况下被设置为None(空白),参数内容为需要去除的值。只要是包含在chars中的值都会被去除(按照单个字符为单位进行去除)。
x = "www.baidu.com"
print(x.lstrip("wcom."))
print(x.rstrip("wcom."))
print(x.strip("wcom.")) 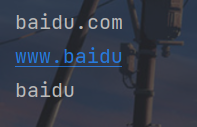
removeprefix(prefix)方法、removesuffix(suffix)方法
该方法是删除字符串中某个具体的子字符串。
x = "www.baidu.com"
print(x.removeprefix("www."))
print(x.removesuffix(".com"))
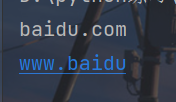
removeprefix是删除前缀子字符串,removesuffix是删除后缀子字符串。
这两个方法是删除参数指定的整个字符串,而不是单个字符。
拆分和拼接
partition(sep)方法
该方法将字符串以参数指定的分割符为依据从左到右进行切割,并且将切割后的结果返回一个三元组。
x = "www.baidu.com"
print(x.partition("."))

rpartition(sep)方法
该方法将字符串以参数指定的分割符为依据从右到左进行切割,并且将切割后的结果返回一个三元组。
x = "www.baidu.com"
print(x.rpartition("."))
split(sep=None,maxsplit=-1)方法
默认情况下切割空格,且不计切割的次数。切割后将结果打包成列表返回。第一个参数是指定分隔符,第二个参数是指定分割的参数。如果改成rsplit就是从右往左开始切割,lsplit是从左往右进行切割。
x = "苟日新,日日新,又日新"
print(x.split(",",1))
splitlines(keepends=False)方法
此方法用于切割回车的情况。在不同操作系统之间回车不一定全是\n(Unix),Mac系统为\r,Microsoft Windows是\r\n。将字符串按行进行分割,并将结果以列表的形式返回。keepends参数是指定结果是否要包含这个换行符,如果是True是包含换行符,默认是False则不包含。
x = "苟日新\n日日新\r又日新"
print(x.splitlines())
y = "苟日新\n日日新\r又日新"
print(y.splitlines(keepends=True))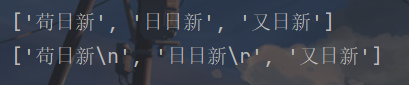
join(iterable)方法
该方法用于拼接字符串,iterable是一个可迭代对象(列表或者元组)。将可迭代对象中的元素用引用方法的字符或字符串拼接起来。
x = "."
print(x.join(["www","baidu","com"]))

注意:使用加号(+)比使用join方法的效率低很多。
格式化字符串
format(下标索引或者关键字索引:格式化选项)方法
![]()
x = "1+2={},2的平方是{},3的立方是{}"
print(x.format(1+2,2*2,3*3*3))![]()
还可以在花括号({})中写上数字,表示参数的位置。
x = "{}爱{}"
print(x.format("我","你"))
y = "{1}爱{0}"
print(y.format("我","你"))

注意:花括号中的数字是从0开始的。因为参数中的字符串被当作元组的元素来对待,所以下标索引值从0开始。
同一个索引值可以被引用多次。
y = "{0}爱{0}"
print(y.format("我","你"))
![]()
还可以用关键字来进行索引。
x = "{name1}爱{name2}"
print(x.format(name1="我",name2="你"))
位置索引和关键字索引可以组合使用。
x = "{name}爱{0}"
print(x.format("Python",name="我"))![]()
如果只想单纯的输入花括号,可以直接在参数里面写上花括号;还可以使用花括号来注释花括号。
x = "{},{},{}"
print(x.format("{}","{}","{}"))
y = "{{}},{{}},{{}}"
print(y.format())

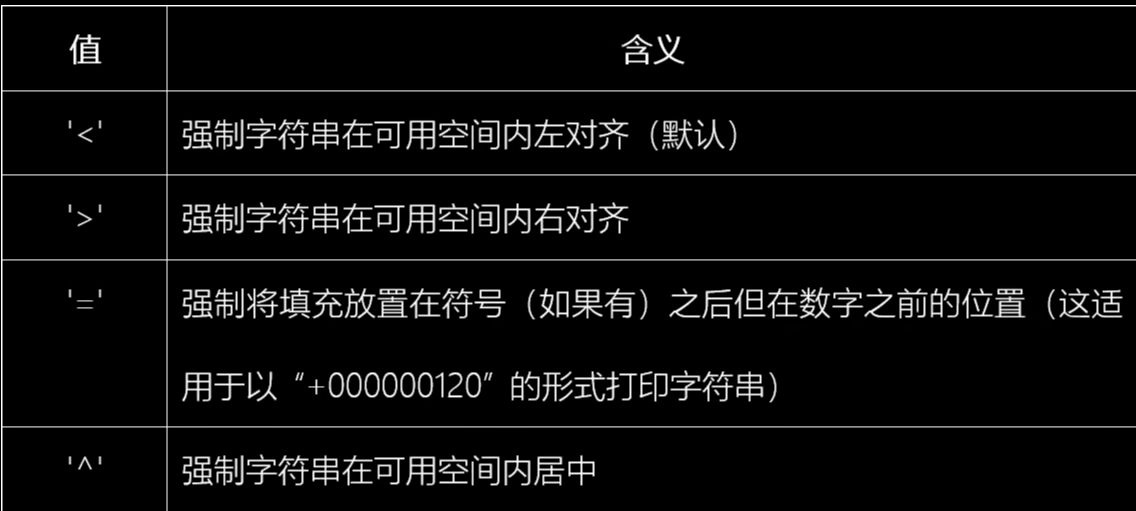
align属性(对齐属性)
wide属性(宽度)
x = "{:^10}"
print(x.format(520)) 
[0]属性(为感知正负号的0填充)
x = "{:010}"
print(x.format(-520))
![]()
注意:此属性只对数字有效。
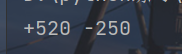
sign属性(符号选项)

x = "{:+} {:-}"
print(x.format(520,-250))
注意:此属性只对数字有效。
grouping_option属性(千分位的分割符)
此属性有两个值:逗号(,)、下划线(_)。
x = "{:,} {:_}"
print(x.format(52000,25000))![]()
注意:如果位数不足,千位分隔符是不显示的。
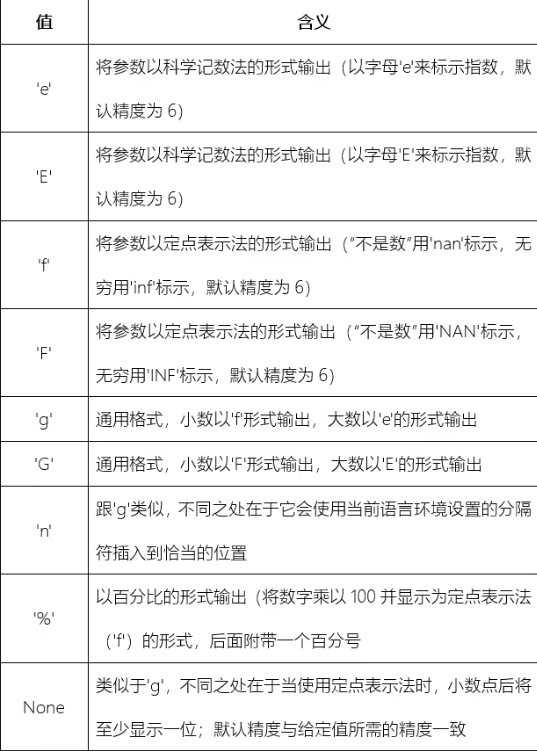
precision属性(精度属性)
对于[type]设置为'f'或'F'的浮点数来说,是限定小数点后显示多少个数位;对于[type]设置为'g'或'G'的浮点数来说,是限定小数点前后一共显示多少个数位;对于非数字类型来说,限定的是最大字段的大小;对于整数来说,则不允许使用[.precision]选项。
x = "{:.2f}"
print(x.format(3.141526))
y = "{:.2g}"
print(y.format(3.141526)) 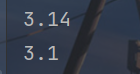
type属性
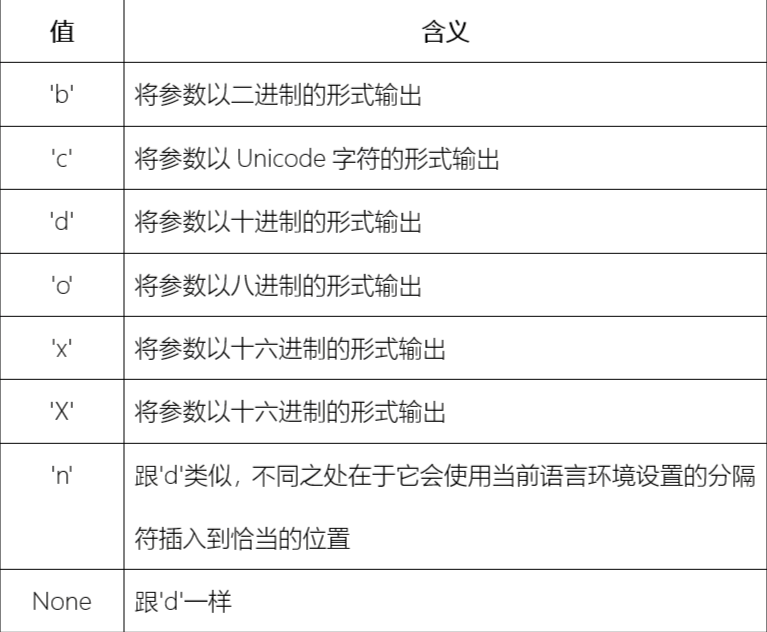
井号选项 (#)
在字符串输出的时候,会自动追加一个前缀。
x = "{:#b}"
print(x.format(80))
y = "{:#o}"
print(y.format(80))
z = "{:#x}"
print(z.format(80))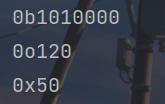
适用于复数和浮点数的类型
f-字符串
在字符串的前面加‘f’或者‘F’。是format的语法糖,进一步简化了格式化字符串的一个操作,并且带来了性能上的略微提升。
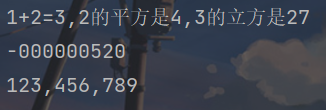
x = f"1+2={1+2},2的平方是{2*2},3的立方是{3*3*3}"
print(x)
y = f"{-520:010}"
print(y)
z = f"{123456789:,}"
print(z)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









