






正则表达式是用于匹配字符串中字符组合的模式
正则表达式是处理文本的利器
例如:
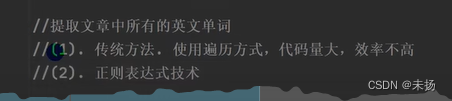

小试牛刀
public static void main(String[] args) {
String str = "再见,JAVA,你好,Golang,学好编程,program";
// 创建一个模式对象,可以理解为一个正则表达式对象
Pattern pattern = Pattern.compile("[a-zA-Z]+");
// 匹配器,按照pattern模式,到str文本中去匹配,找到返回true,否则为false
Matcher matcher = pattern.matcher(str);
while (matcher.find()){
System.out.println(matcher.group(0));
}
}正则表达式底层原理
matcher.find() 原理
1. 根据指定的规则,定位满足规则的子字符串(比如1998)
2. 找到后,将子字符串的开始索引记录到matcher对象的属性 int[] groups中,并将 groups[0] = 0 ;把该子字符串的结束的索引+1 的值记录到 groups[1] = 4
3. 同时记录oldLast的值为 子字符串的结束的 索引+1的的值,即下次执行find是,就从4开始匹配
================================================
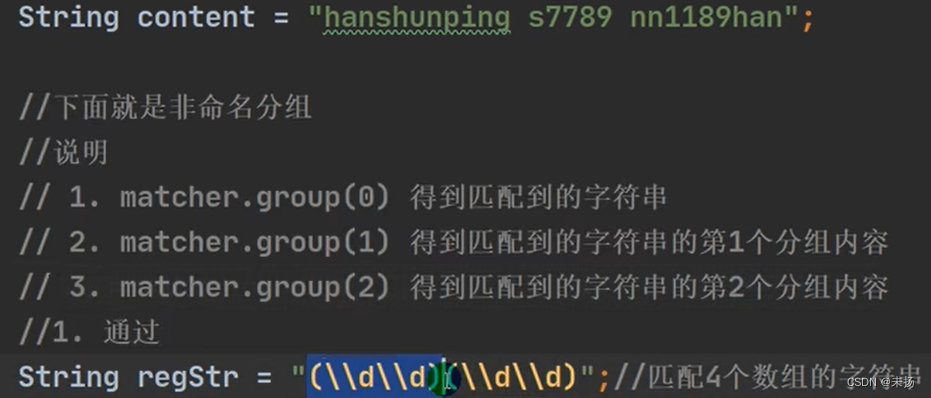
分组
比如 (\d\d)(\d\d),正则表达式中有()表示分组,第一个()表示第一组,第二个()表示第二组
1. 根据指定的规则,定位满足规则的子字符串(比如(19)98)
2. 找到后 ,将 子字符串的开始的索引记录到matcher 对象的属性 int groups;
2.1 groups[0] = 0,把该子字符串的结束索引+1的值记录到groups[1] = 4
2.2 记录1组() 匹配到的字符串 groups[2] = 0 groups[3] = 2
2.3 记录2组()匹配到的字符串groups[4] =2 groups[] = 4
2.4 如果有更多的分组,以此类推
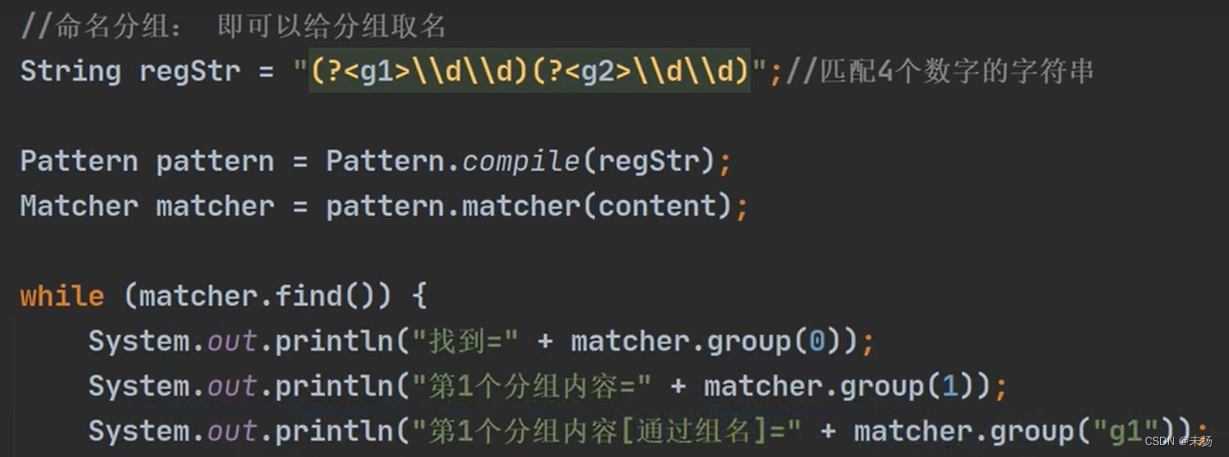
小结
1. 如果正则表达式有(),即分组
2. 取出匹配的字符串规则如下
3. group(0) 表示匹配到的子字符串
4. group(1) 表示匹配到的子字符串的第一组字符串
4. group(2) 表示匹配到的子字符串的第二组字符串
元字符功能

元字符-----> 转义号


元字符----> 元素匹配符


![]()
不区分大小写:
1. 法一

2.法二

元字符-----> 选择匹配符

元字符----->正则限定符
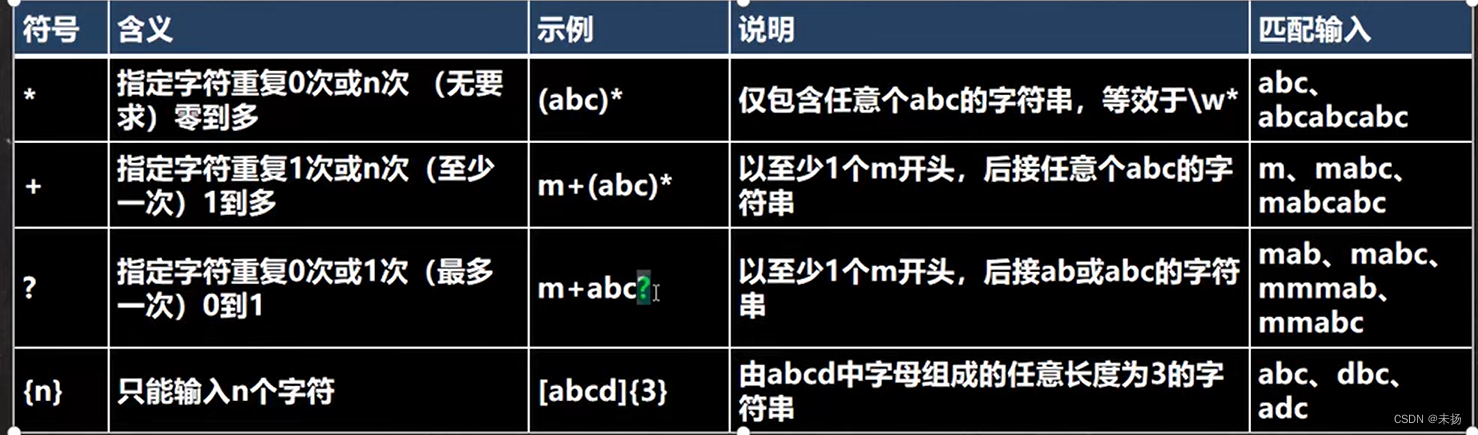

元字符---->正则定位符


分组

例题:















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









