






目录
一、MP入门
1. MP是什么
MybatisPlus,简称MP,是一个 Mybatis 的增强工具,在 Mybatis 的基础上只做增强不做改变。MP为简化开发、提高效率而生。它已经封装好了单表curd方法,我们直接调用这些方法就能实现单表CURD。
注意:MP仅仅提供了单表的CURD。如果要实现多表联查,就只能自己动手实现了,按Mybatis的方式写
官网地址:MyBatis-Plus


2. MP使用入门
1 说明
1 使用步骤说明
MP是dao层操作数据库的框架,它的使用步骤和Mybatis类似但要简单的多。
MP的使用步骤:
-
准备数据库表
-
创建一个SpringBoot工程,准备MybatisPlus环境:
添加依赖:MybatisPlus的依赖坐标、数据库驱动包
修改配置:配置数据库连接地址
准备引导类
-
使用MybatisPlus
准备实体类,对应数据库表
创建一个空的Mapper接口,继承
BaseMapper<实体类>,并添加注解@Mapper -
测试MybatisPlus
2 准备数据库表
连接本机的MySQL,执行《资料/mp_db.sql》,或者执行以下脚本代码:
create database if not exists mp_db character set utf8mb4;
use mp_db;
drop table if exists user;
CREATE TABLE user
(
id bigint(20) primary key auto_increment,
user_name varchar(32) not null,
password varchar(32) not null,
age int(3) not null,
tel varchar(32) not null,
sex char(1) not null
);
insert into user values (null, 'tom', '123456', 12, '12345678910', '男');
insert into user values (null, 'jack', '123456', 8, '12345678910', '男');
insert into user values (null, 'jerry', '123456', 15, '12345678910', '女');
insert into user values (null, 'rose', '123456', 9, '12345678910', '男');
insert into user values (null, 'snake', '123456', 28, '12345678910', '女');
insert into user values (null, '张益达', '123456', 22, '12345678910', '男');
insert into user values (null, '张大炮', '123456', 16, '12345678910', '男');alter table user auto_increment = 8;
2 准备MP项目环境
这里准备了两种方式,在实际开发中都可能会使用。大家习惯哪一种就用哪一种
建议使用手动创建方式
使用idea创建一个maven工程,不用选择任何Artifact骨架,设置好工程坐标即可。然后按照如下步骤准备MP的开发环境:
1) 添加依赖
在工程的pom.xml里添加依赖:
<parent>
<!--SpringBoot父工程坐标-->
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.3</version>
</parent>
<dependencies>
<!--MybatisPlus的起步依赖-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.1</version>
</dependency>
<!--MySQL数据库驱动包-->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<version>8.0.33</version>
</dependency>
<!--SpringBoot测试起步依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>2) 创建配置文件
在工程的resources文件夹里创建配置文件application.yaml,内容如下:
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/mp_db
username: root
password: root
3) 创建引导类
在工程的java文件夹里创建引导类 com.itheima.MpApplication,代码如下:
@SpringBootApplication
public class MpApplication {
public static void main(String[] args) {
SpringApplication.run(MpApplication.class, args);
}
}
3 MP使用入门
1 创建实体类
在工程的java文件夹里创建实体类com.itheima.pojo.User,对应数据库里的user表:
package com.itheima.pojo;
import lombok.Data;
@Data
public class User {
private Long id;
private String userName;
private String password;
private Integer age;
private String tel;
private String sex;
}
2 创建Mapper
在com.itheima.mapper包里创建一个接口UserMapper,要求:
-
接口要继承
BaseMapper<实体类>。我们的实体类是User,所以要继承的是BaseMapper<User> -
接口上添加注解
@Mapper
@Mapper
public interface UserMapper extends BaseMapper<User> {
}
3 使用测试
创建一个单元测试类,测试MP的功能,代码如下:
package com.itheima;
import com.itheima.mapper.UserMapper;
import com.itheima.pojo.User;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
public class Demo01MpTest {
@Autowired
private UserMapper userMapper;
@Test
public void test1(){
User user = userMapper.selectById(1);
System.out.println(user);
}
}3. 小结
-
准备基本环境:添加坐标依赖,修改配置,引导类,准备实体类
-
创建空的Mapper接口,继承
BaseMapper<实体类>,接口上加@Mapper
二、MP简单CURD【重点】
- 掌握MP的简单CURD操作
1. 说明
MP内置了强大的BaseMapper,它已经提供好了单表CURD功能:只要我们的Mapper接口继承了BaseMapper,就可以直接使用整套的单表CURD功能了。
常用的基本curd方法有:
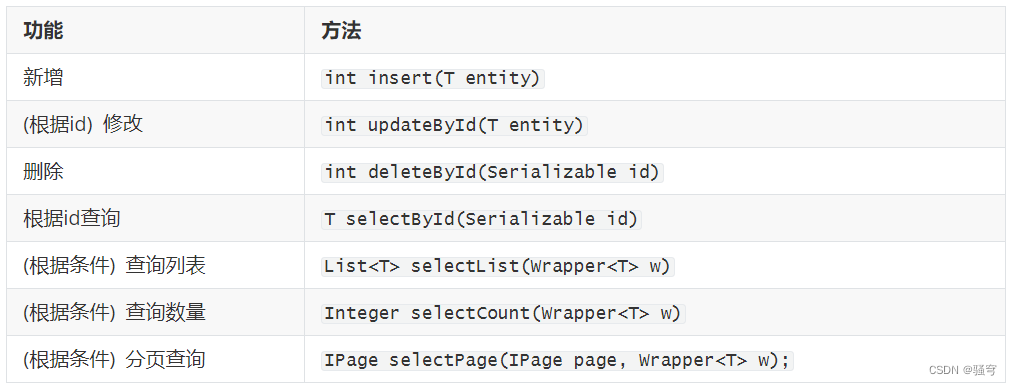
2. 示例
package com.itheima;
import com.itheima.mapper.UserMapper;
import com.itheima.pojo.User;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.List;
@SpringBootTest
public class Demo02MpCurdTest {
@Autowired
private UserMapper userMapper;
/**
* 查询数据的方法示例
*/
@Test
public void testSelect(){
//1. 根据id查询一个
User user = userMapper.selectById(1);
System.out.println(user);
//2. 查询列表(查询全部)
List<User> userList = userMapper.selectList(null);
for (User u : userList) {
System.out.println(u);
}
//3. 查询数量
Integer count = userMapper.selectCount(null);
System.out.println("总数量:" + count);
}
/**
* 插入数据的示例
*/
@Test
public void testInsert(){
User user = new User();
user.setUserName("老王");
user.setAge(40);
user.setPassword("heihei");
user.setTel("13800138000");
user.setSex("男");
System.out.println("插入之前的user没有id:" + user);
int i = userMapper.insert(user);
System.out.println("影响的行数是:" + i);
System.out.println("插入之后的user有id了:" + user);
}
/**
* 修改数据的示例
*/
@Test
public void testUpdate(){
User user = new User();
user.setId(1L);
user.setPassword("666666");
//注意:方法是根据id修改的,所以传入的对象里必须有主键id的值
int i = userMapper.updateById(user);
System.out.println("影响的行数是:" + i);
}
/**
* 删除数据的示例
*/
@Test
public void testDelete(){
int i = userMapper.deleteById(1);
System.out.println("影响的行数是:" + i);
}
}3. 小结
MP本身提供了一批单表CURD的方法
查询方法:都以select开头
-
selectById:根据id查询一个
-
selectCount:根据条件查询数量
-
selectList:根据条件查询列表
新增方法:都以insert开头
-
insert:新增数据,并且MP会自动帮我们生成主键值。方法返回值是影响行数
修改方法:都以update开头
-
updateById:根据id修改。方法返回值是影响行数
删除方法:都以delete开头
-
deleteById:根据id删除。方法返回值是影响行数
三、MP的实体类注解[重点]
MP对实体类的写法是有一些要求的:
-
实体类名:和表名要符合 下划线与驼峰命名的映射规则
-
实体类里的属性:
-
属性:与字段必须一一对应。每个属性都必须有一个对应的字段
-
命名:属性名与字段名,要符合 下划线与驼峰命名的映射规则
-
如果实体类确实不符合以上规则,MP提供了一些注解用于特殊设置:
-
表名与实体类名的映射:
@TableName:用于设置 实体类名 与 数据库表名 的对应关系。当表名和实体类名不对应时需要设置 -
字段与属性的映射:
@TableField:用于非主键字段。设置非主键字段与属性对应关系。当表字段名与属性名不对应时设置@TableId:用于主键字段。设置主键字段与属性对应关系,还可以设置主键生成策略
1. @TableName表名映射
问题说明
我们在使用MP查询的过程中,并没有指定要查询的表。例如:我们调用了UserMapper的selectList方法,MP就从user表里查询数据了。那么MP是怎么知道要查询哪张表呢?
实际上MP默认会把实体类名与表名做映射,不过是按照下划线命名与大驼峰命名的映射方式:
-
表名称:以下划线式命名。例如:
tb_order,tb_order_detail -
实体类名称:以大驼峰式命名。例如:
TbOrder,TbOrderDetail
所以我们调用UserMapper时继承的BaseMapper<User>,MP就知道要查询 实体类User对应的表user
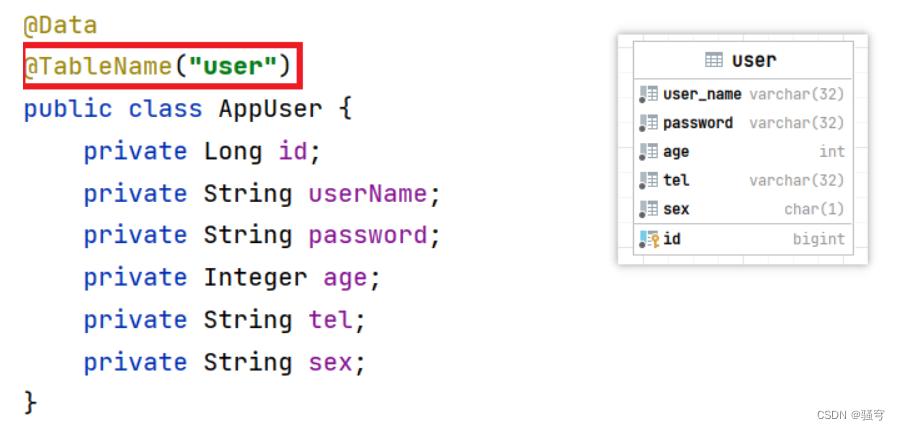
但是,如果实体类名与表名不匹配的时候,MP就会报错 “表不存在”。例如实体类名为AppUser,表名为user时,报错如下图示例:

解决方案
-
有实体类AppUser如下图。在类上添加注解
@TableName("表名称")
再次查询用户列表,可以正常查询
2. @TableField字段映射
@TableField用在JavaBean里的属性上,用于设置属性与数据库字段的映射关系。
这个注解提供了很多参数,我们这里介绍3个常用的:
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.FIELD, ElementType.ANNOTATION_TYPE})
public @interface TableField {
//=====常用参数这里只列出以下几个,其它都省略掉了====
//该属性对应的字段名称,用于解决 JavaBean属性名 与 字段名不匹配的情况
String value() default "";//该属性是否存在对应的字段,如果不存在,就要设置为false,否则操作数据库会报错
boolean exist() default true;//查询时是否查询此属性对应的字段
boolean select() default true;
}
1 属性名与字段名不匹配的情况
问题说明
默认情况下,MP会把数据库表的字段名 自动与 JavaBean属性名进行映射,而映射的规则是:
-
表的字段名:要求采用下划线式命名,单词之间使用
_连接。例如:user_name,order_id -
JavaBean的属性名:采用小驼峰式命名,首字母小字,后续每个单词首字母大写。例如:
userName,orderId
MP在操作数据库时,如果有任何属性找不到对应的字段,就会报错“找不到字段”,如下图示例:
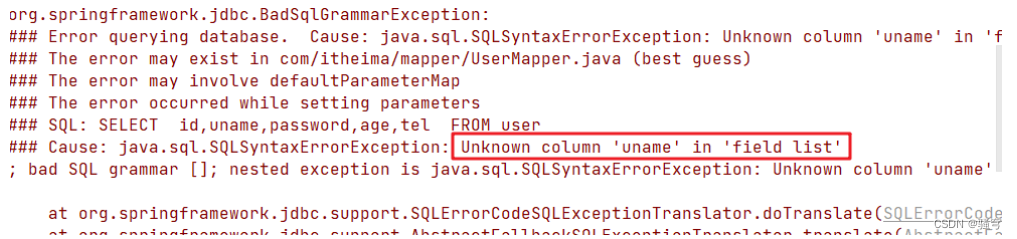
这时候,我们就必须使用@TableField(value="字段名")来手动设置属性与字段的映射关系。
解决方案
-
有实体类如下图。
其中一个属性名称为uname与字段名user_name不匹配。就在属性上加注解
@TableField(value="字段名")
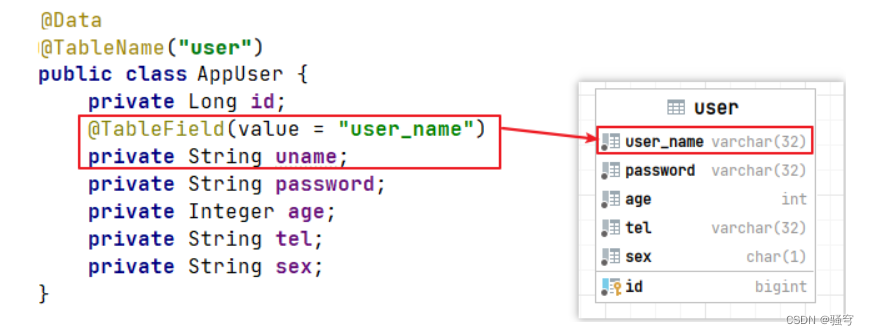
2.查询用户列表,发现user_name字段的值也查询出来了
@SpringBootTest
public class Demo03MpTest {
@Autowired
private UserMapper userMapper;@Test
public void test(){
List<AppUser> users = userMapper.selectList(null);
for (AppUser user : users) {
System.out.println(user);
}
}
}
2 自定义属性没有对应字段的情况
问题说明
有时候,我们会在JavaBean中添加一些自定义的属性,而这些属性 是没有任何字段与之对应的。
MP在操作数据库时,如果有任何属性找不到对应的字段,就会报错“找不到字段”。如下图示例:
这时候我们可以通过添加@TableField(exist=false),告诉MP,这个属性没有对应的字段,MP就不会报错了
解决方案
-
有实体类User如下图。
其中有属性
address,数据库里是没有对应的字段的。所以在属性上加注解@TableField(exist=false)
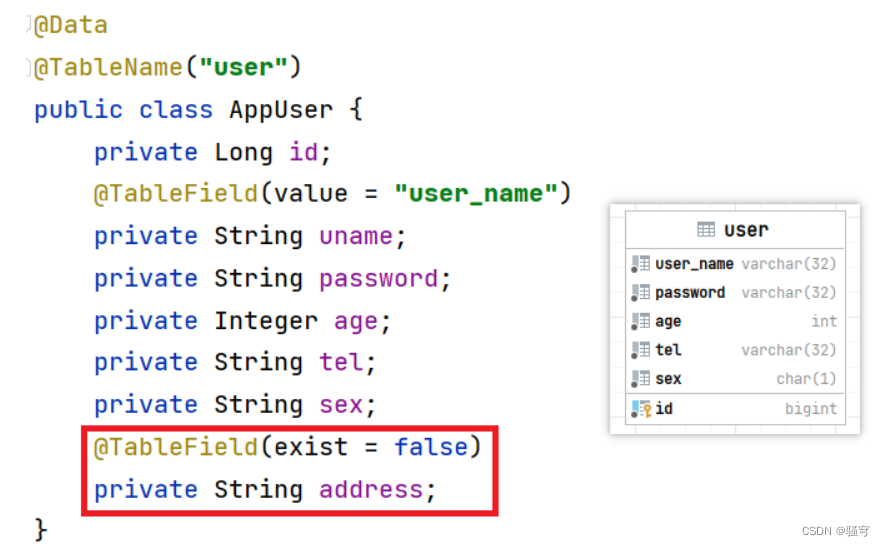
2.再次执行查询用户列表,发现不报错了
3 某字段不需要查询的情况
问题说明
默认情况,MP会查询表里所有字段的值,封装到JavaBean对象中。但是实际开发中,可能某些字段并不需要查询,这时候我们可以使用@TableField(select=false)
解决方案
-
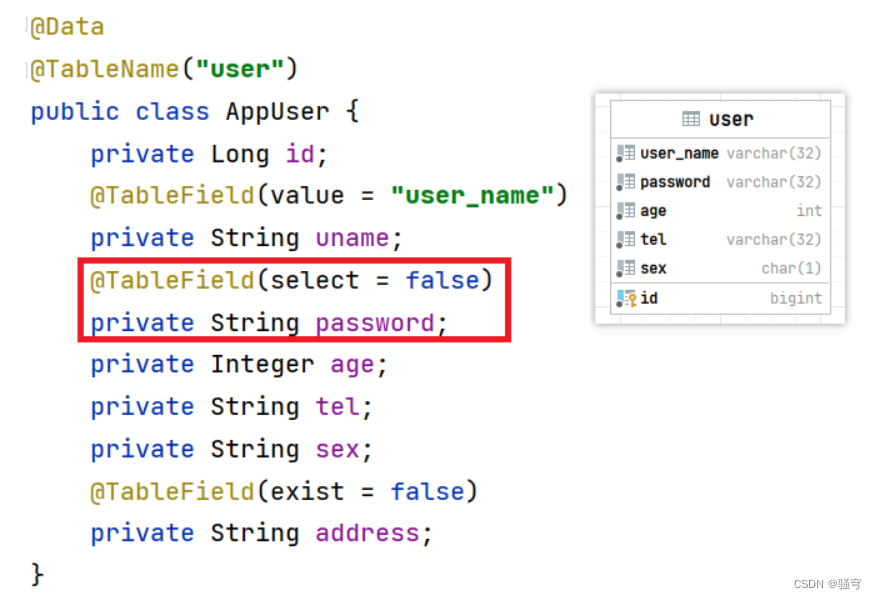
有实体类User如下图。
其中的
password属性我们不要查询,就在属性上添加注解@TableField(select=false)
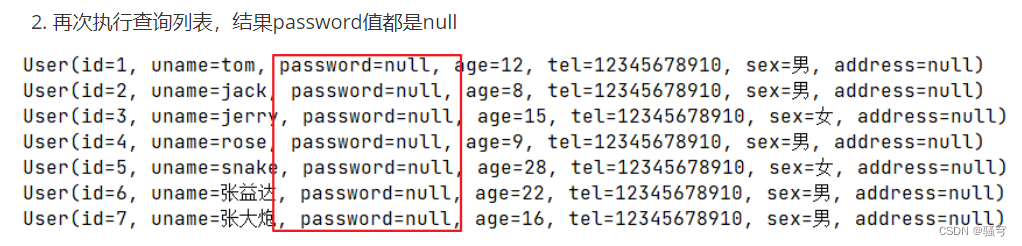
3. @TableId主键策略
说明
当我们调用了Mapper的insert方法,插入数据时,并不需要指定id值,MP会按照既定的主键生成策略帮我们生成好主键值。
使用方法:修改实体类,在主键对应的属性上添加注解@TableId(type=主键策略)
其中的“主键策略”,MP提供了多种策略供我们使用:
-
IdType.NONE:不设置,跟随全局 -
IdType.AUTO:数据库主键自增 -
IdType.INPUT:MP不生成主键值,在插入数据时由我们提供一个主键值 -
IdType.ASSIGN_ID:由MP使用雪花算法生成一个id值,可兼容数值型(long类型)和字符串型 -
IdType.ASSIGN_UUID:由MP使用UUID算法生成一个id值
示例
-
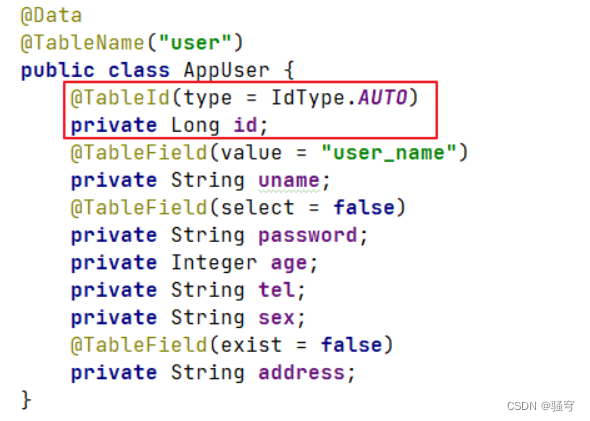
有实体类AppUser,其主键属性id是Long类型,要设置主键策略为自增。就在id属性上添加注解
@TableId(type=IdType.AUTO)
2.重新执行一下今天资料里的SQL脚本,恢复一下数据库表和其中的数据。
3.在测试类里增加下测试代码,执行后发现数据库里新的数据id是自增的
@Test
public void test2(){
AppUser user = new AppUser();
user.setUname("小张");
user.setPassword("12345");
user.setAge(20);
user.setSex("男");
user.setTel("13800138000");
userMapper.insert(user);
}
4. 小结
实体类与表名规则要求:
-
MP默认情况下,要求:实体类和表名 要符合 下划线与驼峰的映射规则;
-
如果不符合:就需要在实体类上加
@TableName("表名")
实体类里属性与字段的规则要求:
-
默认情况下,要求每个属性都必须有一个对应的字段,属性名和字段名要符合 驼峰与下划线映射规则
-
非主键字段:
-
如果一个属性名,和字段名不对应,怎么办?加
@TableField(value="字段名") -
如果一个属性,没有对应的字段存在,怎么办?加
@TableField(exists=false) -
如果一个属性,不想查询对应字段的值,怎么办?加
@TableField(select=false)
-
-
主键字段:
-
要使用@TableId(value="字段名", type=主键生成策略)
-
主键生成策略,设置的方式:实体类里主键属性上加 @TableId(type=IdType.策略名)
NONE:不设置,跟随全局
AUTO:主键值自增,前提是主键支持自增
INPUT:由我们的代码设置主键值,不让MP生成主键值
ASSIGN_ID:雪花算法。根据时间戳+机器码+序列号生成最终的Long类型的数字,特点是单调递增的
ASSIGN_UUID:UUID算法。不推荐,因为UUID值是乱序的,会影响主键字段上的索引
-
练习:
-
把实体类重命名成AppUser (重命名快捷键 Shift + F6),实体类名与表名不对应了,怎么办?
-
把实体类里userName重命名成uname( Shift + F6),属性名和字段名不对应了,怎么办?
-
在实体类里增加address属性,没有对应的字段,怎么办?
-
设置主键生成策略为雪花算法,再测试新增。
四、MP条件查询【重点】
- 能够使用QueryWrapper或者LambdaQueryWrapper实现条件查询
1.介绍
1 条件查询介绍
以前使用Mybatis开发时,遇到动态条件的查询,就需要我们在xml文件里使用各种标签实现SQL语句的动态拼接。而MP把这些封装成了Java的API,我们可以以编程的形式完成SQL语句的构建并实现复杂的多条件查询。
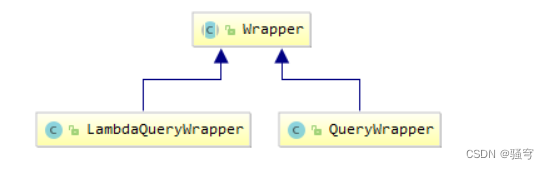
而复杂的多条件查询的关键在于查询条件的构造,为此MP提供了查询条件抽象类:Wrapper,用于封装查询相关的所有条件和其它查询信息。
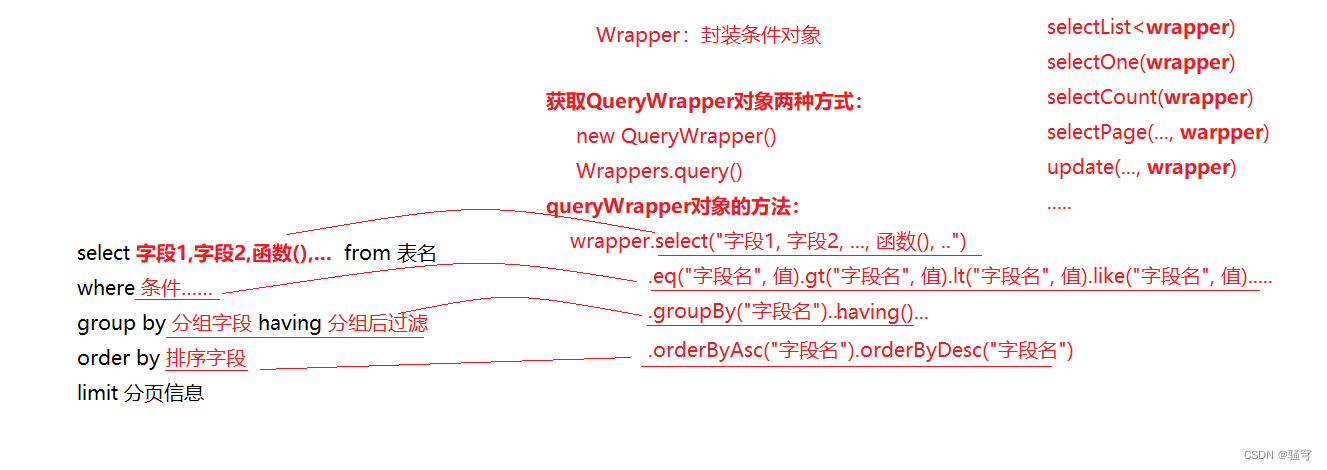
MP提供的所有条件式的操作,都需要传入这个类型的参数。比如:
-
selectList(Wrapper w):根据条件查询列表 -
selectOne(Wrapper w):根据条件查询一条数据 -
selectCount(Wrapper w):根据条件查询数量 -
selectPage(Page p, Wrapper w):根据条件分页查询 -
……
Wrapper有两个常用的子类可以封装where条件
-
QueryWrapper:使用时容易写错,但使用更灵活 -
LambdaQueryWrapper:没有QueryWrapper灵活,但是不易写错。使用的更多一些
在实际开发中,有时候会把QueryWrapper转换成LambdaQueryWrapper,两者混合使用。
2 开发环境准备
为了避免前边代码的干扰,我们准备一个新的工程,步骤略
实体类:User
@Data
@TableName("user")
public class User {
@TableId(type = IdType.AUTO)
private Long id;
private String userName;
private String password;
private Integer age;
private String tel;
private String sex;
}
UserMapper
@Mapper
public interface UserMapper extends BaseMapper<User> {
}
2. QueryWrapper的使用
1 使用入门
需求
查询年龄大于20岁的用户,只查询用户的id、姓名、年龄,结果按年龄降序排列
示例
package com.itheima;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.itheima.mapper.UserMapper;
import com.itheima.pojo.AppUser;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.List;
@SpringBootTest
public class Demo04QueryTest {
@Autowired
private UserMapper userMapper;
/**
* 查询所有年龄大于20岁的用户
* 只查询id、姓名、年龄
* 结果按年龄降序排列
*/
@Test
public void test1(){
//创建一个QueryWrapper对象,泛型是实体类
QueryWrapper<User> wrapper = new QueryWrapper<>();
// 设置查询条件:age > 20
wrapper.select("id", "user_name", "age")
.gt("age", 20)
.orderByDesc("age");
//调用selectList方法,根据条件查询列表
List<User> users = userMapper.selectList(wrapper);
for (User user : users) {
System.out.println(user);
}
}
}2 设置查询条件
说明
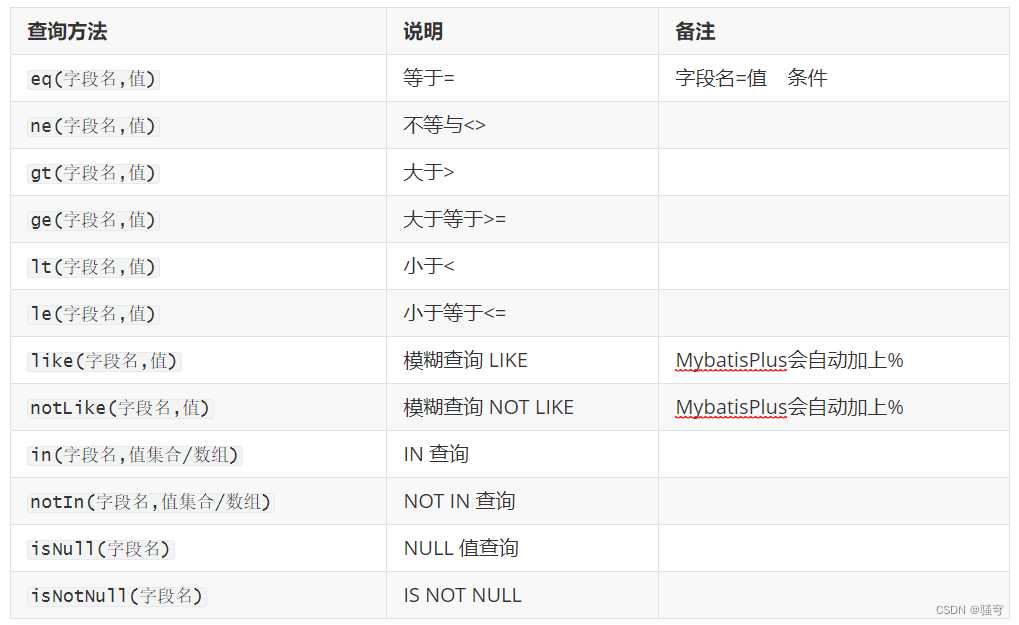
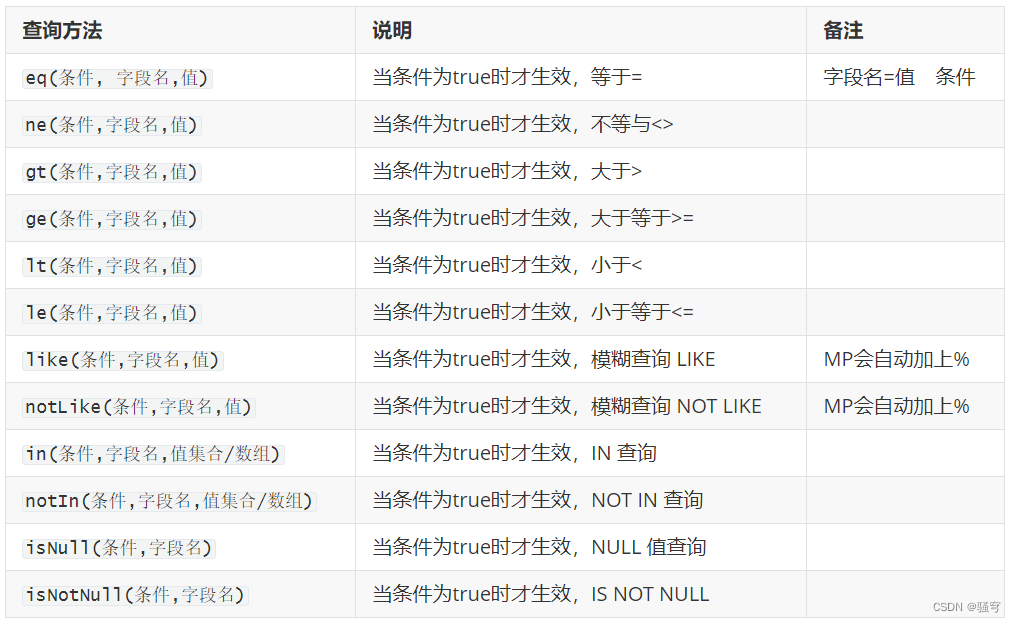
如果要使用QueryWrapper进行条件查询,常用的查询条件方法有:
示例
@Test
public void test2(){
//QueryWrapper<AppUser> wrapper = new QueryWrapper<>();
//wrapper.gt("age", 15);
//wrapper.lt("age", 25);
QueryWrapper<AppUser> wrapper = new QueryWrapper<>();
wrapper.gt("age", 15).lt("age", 25);List<AppUser> users = userMapper.selectList(wrapper);
for (AppUser user : users) {
System.out.println(user);
}
}
3.or连接条件
在QueryWrapper的条件连接中,所有查询条件默认都是使用and连接的。如果想要多个条件使用or,可以使用它的or()方法
注意:SQL语句中or的优先级低于and
@Test
public void test3(){
QueryWrapper<AppUser> wrapper = new QueryWrapper<>();
// user_name = ? AND password = ? OR age > ?
wrapper.eq("user_name", "jack").eq("password", "123456")
.or()
.gt("age", 15);
List<AppUser> users = userMapper.selectList(wrapper);
for (AppUser user : users) {
System.out.println(user);
}
}
4 动态条件拼接
说明
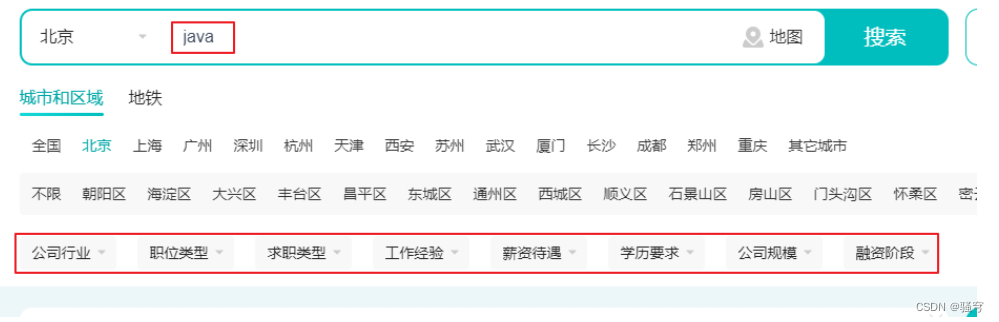
在实际的数据查询中,通常可能有多个条件组合查询,并且条件的数量是动态变化的。如下图所示,用户可以选择任意1个、2个、多个条件进行组合查询
如果用户没有选择某个条件,那么SQL语句中就不能添加这个查询条件,这就需要使用SQL语句的动态拼接了
MP的所有查询条件的方法都有重载:
示例
@Test
public void test4(){
//模拟:客户端提交过来的两个查询条件,最小年龄minAge,最大年龄maxAge
Integer minAge = 15;
Integer maxAge = null;
QueryWrapper<AppUser> wrapper = new QueryWrapper<>();
//动态拼接查询条件: 如果minAge不为空,才会拼接 age > minAge值
wrapper.gt(minAge!=null, "age", minAge)
// 如果maxAge不为空,才会拼接 age < maxAge值
.lt(maxAge!=null, "age", maxAge);
List<AppUser> users = userMapper.selectList(wrapper);
for (AppUser user : users) {
System.out.println(user);
}
}5 查询投影[了解]
说明
所谓查询投影,指的就是SQL语句select .... from ...中,select的内容。MP允许我们自定义要select的字段,只要直接调用QueryWrapper对象的select()方法即可
示例
@Test
public void test5(){
QueryWrapper<User> wrapper = new QueryWrapper<>();
//select id, user_name, tel from user where age > 15 order by age desc
wrapper.select("id, user_name, tel")
.gt("age", 15)
.orderByDesc("age");
List<User> users = userMapper.selectList(wrapper);
for (User user : users) {
System.out.println(user);
}
}
@Test
public void test6(){
QueryWrapper<User> wrapper = new QueryWrapper<>();
// select sex, count(*) as cnt from user group by sex;
wrapper.select("sex, count(*) as cnt")
.groupBy("sex");
List<Map<String, Object>> maps = userMapper.selectMaps(wrapper);
for (Map<String, Object> map : maps) {
System.out.println(map);
}
}3. LambdaQueryWrapper的使用
1 使用入门
在刚刚使用QueryWrapper进行条件操作时,所有的条件都写的是数据库的字段名,这种方式很容易写错,而且不方便。所以MP提供了LambdaQueryWrapper解决这个问题。
使用LambdaQueryWrapper封装条件时,所有的条件不再写数据库字段,而是写字段对应的属性。
需求
查询年龄大于20岁的用户,只查询用户的id、姓名、年龄,结果按年龄降序排列
示例
package com.itheima;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.itheima.mapper.UserMapper;
import com.itheima.pojo.User;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.List;
@SpringBootTest
public class Demo05LambdaQueryTest {
@Autowired
private UserMapper userMapper;
@Test
public void test01(){
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();
wrapper.select(User::getId, User::getUserName, User::getAge)
.gt(User::getAge, 20)
.orderByDesc(User::getAge);
List<User> users = userMapper.selectList(wrapper);
for (User user : users) {
System.out.println(user);
}
}
}2 设置查询条件
说明
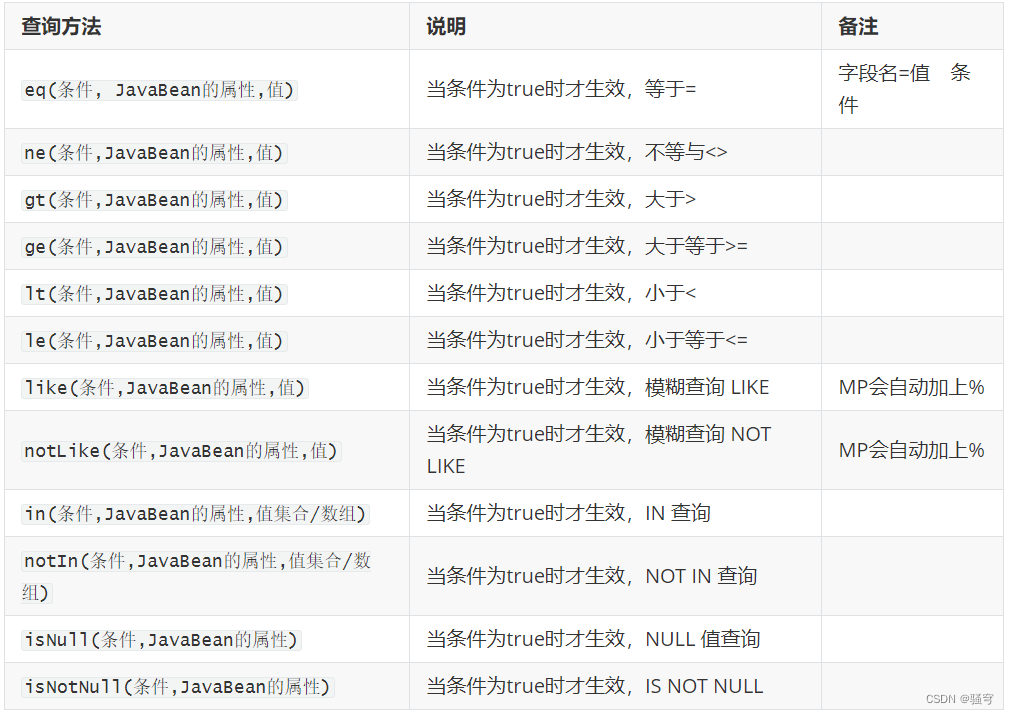
如果要使用LambdaQueryWrapper进行条件查询,常用的查询条件方法有:

示例
@Test
public void test02(){
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();
wrapper.gt(User::getAge, 15).lt(User::getAge, 25);
List<User> users = userMapper.selectList(wrapper);
for (User user : users) {
System.out.println(user);
}
}拓展了解:or连接条件
说明
在LambdaQueryWrapper的条件连接中,所有查询条件默认都是使用and连接的。如果想要多个条件使用or,可以使用它的or()方法
注意:SQL语句中or的优先级低于and
示例
@Test
public void test03(){
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();
// user_name = ? AND password = ? OR age > ?
wrapper.eq(User::getUserName, "jack").eq(User::getPassword, "123456")
.or()
.gt(User::getAge, 15);
List<User> users = userMapper.selectList(wrapper);
for (User user : users) {
System.out.println(user);
}
}3 动态条件拼接
说明
MP的所有查询条件的方法都有重载:
示例
@Test
public void test04(){
//模拟:客户端提交过来的两个查询条件,最小年龄minAge,最大年龄maxAge
Integer minAge = 15;
Integer maxAge = null;
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();
//动态拼接查询条件: 如果minAge不为空,才会拼接 age > minAge值
wrapper.gt(minAge!=null, User::getAge, minAge)
// 如果maxAge不为空,才会拼接 age < maxAge值
.lt(maxAge!=null, User::getAge, maxAge);
List<User> users = userMapper.selectList(wrapper);
for (User user : users) {
System.out.println(user);
}
}4 查询投影[了解]
说明
LambdaQueryWrapper有它的局限:它只能将表里的字段替换成Lambda方法引用的形式,但是非表字段的内容,LambdaQueryWrapper就无能为力了。
这时候,只能先使用QueryWrapper设置好非表字段的内容,再将QueryWrapper转换成LambdaQueryWrapper
示例
@Test
public void test05(){
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();
//select id, user_name, tel from user where age > 15 order by age desc
wrapper.select(User::getId, User::getUserName, User::getTel)
.gt(User::getAge, 15)
.orderByDesc(User::getAge);
List<User> users = userMapper.selectList(wrapper);
for (User user : users) {
System.out.println(user);
}
}
@Test
public void test06(){
QueryWrapper<User> wrapper = new QueryWrapper<>();
// 要查询的内容不是表里的字段,就不能使用LambdaQueryWrapper的方式了
// 先使用QueryWrapper,它更灵活,可以设置非表字段的内容
wrapper.select("sex, count(*) as cnt")
//然后把QueryWrapper转换成LambdaQueryWrapper
.lambda()
.groupBy(User::getSex);
List<Map<String, Object>> maps = userMapper.selectMaps(wrapper);
for (Map<String, Object> map : maps) {
System.out.println(map);
}
}4. 小结
使用MP做条件性操作时,需要构造条件对象。Wrapper有两个子类:QueryWrapper, LambdaQueryWrapper
QueryWrapper的用法:
//直接new的方式。
QueryWrapper<实体类> wrapper = new QueryWrapper<实体类>()
.select("字段1,字段2,字段3 as 别名, ifnull(...) as xx")
//条件方法:eq, ne, gt, ge, lt, le, like, notLike, in, notIn, isNull, isNotNull....
.条件方法(字段名,值)
.条件方法(是否要拼接此条件, 字段名,值)
.orderByAsc("字段名...").orderByDesc("字段名...")
//直接Wrappers的静态方法方式。
QueryWrapper<实体类> wrapper = Wrappers.<实体类>query()
.select("字段1,字段2,字段3 as 别名, ifnull(...) as xx")
//条件方法:eq, ne, gt, ge, lt, le, like, notLike, in, notIn, isNull, isNotNull....
.条件方法(字段名,值)
.条件方法(是否要拼接此条件, 字段名,值)
.orderByAsc("字段名...").orderByDesc("字段名...")
List list = xxxMapper.selectList(wrapper);LambdaQueryWrapper的用法:
//直接new
LambdaQueryWrapper<实体类> wrapper = new LambdaQueryWrapper<实体类>()
.select(实体类::get属性, ....)
.条件方法(实体类::get属性,值)
.条件方法(是否要拼接此条件, 实体类::get属性,值)
.orderByAsc(实体类::get属性,..).orderByDesc(实体类::get属性,...)
//使用Wrappers的静态方法
LambdaQueryWrapper<实体类> wrapper = Wrappers.<实体类>lambdaQuery()
.select(实体类::get属性, ....)
.条件方法(实体类::get属性,值)
.条件方法(是否要拼接此条件, 实体类::get属性,值)
.orderByAsc(实体类::get属性,..).orderByDesc(实体类::get属性,...)五、MP分页查询【重点】
- 掌握MP的分页查询步骤和查询方法
1. 介绍
之前我们要实现分页查询,要么在mybatis中引入pageHelper插件,要么完全手动实现分页查询。
而MybatisPlus本身就内置分页插件,直接配置即可,不需要再额外导入任何插件,也不需要我们再手动实现了。
1 使用步骤
-
配置分页插件:创建一个配置类,在配置类中增加MP的分页插件
-
实现分页查询:调用Mapper的selectPage方法实现分页查询功能
2 分页API
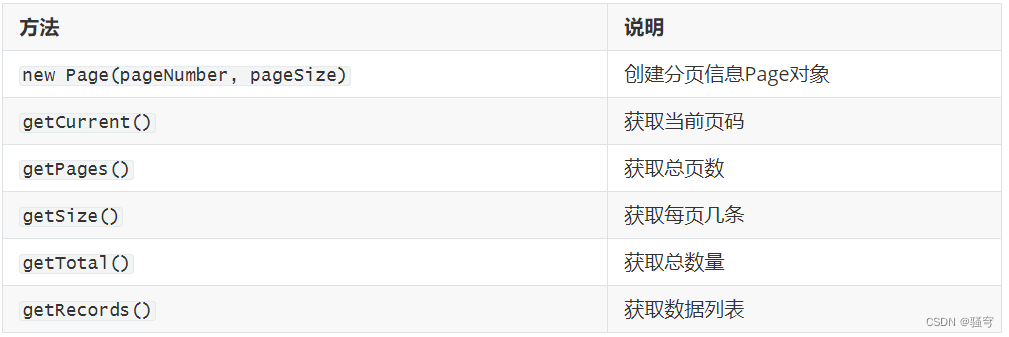
MP的Mapper提供的分页查询方法是:IPage selectPage(IPage page, Wrapper wrapper)
-
参数page:用于封装分页条件,包括页码和查询数量
-
参数wrapper:用于封装查询条件,实现条件查询并分页
-
返回值Page:分页查询的结果
IPage:是一个接口;Page是它的实现类;是分页信息对象
-
在执行分页查询前,把分页参数封装成Page对象
-
当执行分页查询后,MP会把查询结果封装到这个Page对象中
-
常用方法有
2. 示例
1 配置分页插件
package com.itheima.config;
import com.baomidou.mybatisplus.annotation.DbType;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MpConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
//创建拦截器对象MybatisPlusInterceptor
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
//添加分页插件PaginationInnerInterceptor,注意数据库的类型。如果数据库是MySQL,就设置DbType.MYSQL
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}2 执行分页查询
package com.itheima;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.itheima.mapper.UserMapper;
import com.itheima.pojo.User;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.List;
@SpringBootTest
public class Demo06PageTest {
@Autowired
private UserMapper userMapper;
@Test
public void testPage(){
//准备查询条件:性别为男的
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(User::getSex, "男");
//执行分页查询
Page<User> page = userMapper.selectPage(new Page<>(1, 3), wrapper);
//得到分页查询结果
System.out.println("总数量:" + page.getTotal());
System.out.println("总页数:" + page.getPages());
System.out.println("每页几条:" + page.getSize());
System.out.println("当前页码:" + page.getCurrent());
List<User> list = page.getRecords();
list.forEach(System.out::println);
}
}3. 小结
MP的分页查询:
-
先配置分页插件。在配置类或者在引导类里添加
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));//如果配置多个插件,切记分页最后添加
return interceptor;
}
2.调用mapper接口的selectPage方法
Page<实体类> page = xxxMapper.selectPage( new Page(页码,每页几条), wrapper对象 );
page.getTotal(); //获取总数量
page.getPages(); //获取总页数
page.getRecords();//获取数据列表
六、MP的DML操作
- 掌握MP的批量操作
- 了解MP的逻辑删除
- 了解MP的乐观锁
1. MP的批量操作
1 说明
在实际开发中,通常需要批量操作。例如:批量删除、批量下单等等,如果下图所示
MP提供了批量操作的一些方法,常用的有:
-
deleteBatchIds(Collection idList):根据id集合,批量删除 -
selectBatchIds(Collection idList):根据id集合,批量查询
2 示例
package com.itheima;
import com.itheima.mapper.UserMapper;
import com.itheima.pojo.User;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.ArrayList;
import java.util.List;
@SpringBootTest
public class Demo07BatchTest {
@Autowired
private UserMapper userMapper;
@Test
public void testBatchDelete(){
List<Long> ids = new ArrayList<>();
ids.add(1L);
ids.add(2L);
ids.add(3L);
userMapper.deleteBatchIds(ids);
}
@Test
public void testBatchSelect(){
List<Long> ids = new ArrayList<>();
ids.add(1L);
ids.add(2L);
ids.add(3L);
List<User> users = userMapper.selectBatchIds(ids);
for (User user : users) {
System.out.println(user);
}
}
}2. MP的逻辑删除
1 说明
什么是逻辑删除
如果需要删除一条数据,开发中往往有两种方案可以实现:
-
物理删除:真正的从数据库中把数据删除掉
-
逻辑删除:有一个字段用于标识数据是否删除的状态。删除时仅仅是把字段设置为“已删除”状态,数据还在数据库里,并非真正的删除
在实际开发中,逻辑删除使用的更多一些。所以MP也提供了逻辑删除的支持,帮助我们更方便的实现逻辑删除
MP的逻辑删除用法
使用步骤:
-
修改数据库表,增加一个字段
deleted。字段名称可以随意,仅仅是用于存储数据的状态的 -
修改实体类,增加对应的属性,并在属性上添加注解
@TableLogic -
修改配置文件
application.yaml,声明删除与未删除的字面值
MP逻辑删除的本质是:
-
当执行删除时,MP实际上执行的是update操作,把状态字段修改为“已删除状态”
-
当执行查询时,MP会帮我们加上一个条件
状态字段 = 未删除,从而只查询未删除的数据
2 示例
1 增加状态字段
执行SQL语句:
use mp_db;
alter table user add deleted int default 0;
2 增加属性并加@TableLogic注解
@Data
@TableName("user")
public class User {
@TableId(type = IdType.AUTO)
private Long id;
private String userName;
private String password;
private Integer age;
private String tel;
private String sex;
//增加@TableLogic注解,这个字段被声明为 逻辑删除状态字段
@TableLogic
private int deleted;
}
3 修改配置文件
mybatis-plus:
global-config:
db-config:
#logic-delete-field: deleted #全局的默认逻辑删除字段名,即 状态字段名。
logic-delete-value: 1 #已删除状态的值
logic-not-delete-value: 0 #未删除状态的值
4 测试
@Test
public void testLogicDelete(){
//删除id为5的数据
userMapper.deleteById(5L);//查询所有数据,查询结果中没有id为5的数据。但是数据库里id为5的数据还在,只是deleted为1(已删除状态)
List<User> users = userMapper.selectList(null);
for (User user : users) {
System.out.println(user);
}
}
3. MP的乐观锁

1 说明
随着互联网的发展,特别是国内互联网人数的增加,数据量、并发量也随之增加,并发访问控制的问题也越发凸显,例如:秒杀。如果一条数据被多个线程并发修改数据,就需要对数据加锁,避免其它线程修改这条数据。
MP已经帮我们实现了乐观锁,它的使用步骤非常简单:
-
修改数据库表,增加一个字段
version。字段名称随意,仅仅是用于记录数据版本号 -
修改实体类,增加对应的属性,并在属性上增加注解
@Version -
创建配置类,在配置类里设置好乐观锁插件
-
修改数据时乐观锁就生效了:但是要先查询数据,再修改数据,乐观锁才会生效;直接修改数据是不生效的
MP的乐观锁实现逻辑也非常简单:
-
先查询数据,得到这条数据的version版本号。假如是0
-
在修改数据时,带上这个version版本号
MP执行update时,会加上
set version = version + 1 where version = 这个version版本号如果数据库里的数据的version,和带上的这个version不一致,就放弃修改
2 示例
1 增加版本号字段
执行以下SQL语句
use mp_db;
alter table user add version int default 0;
2 修改实体类
package com.itheima.pojo;
import com.baomidou.mybatisplus.annotation.*;
import lombok.Data;
@Data
@TableName("user")
public class User {
@TableId(type = IdType.AUTO)
private Long id;
private String userName;
private String password;
private Integer age;
private String tel;
private String sex;
@TableLogic
private int deleted;
//增加对应的属性,并添加@Version注解
@Version
private int version;
}3 配置乐观锁插件
在配置类(MpConfig)里,并在配置类里配置好乐观锁插件

@Configuration
public class MpConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
//创建拦截器对象MybatisPlusInterceptor
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
//添加分页插件PaginationInnerInterceptor,注意数据库的类型。如果数据库是MySQL,就设置DbType.MYSQL
//interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
//添加乐观锁插件OptimisticLockerInnerInterceptor
interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor());
return interceptor;
}
}4 测试
@Test
public void testLock(){
//先查询数据。假如查询到的version版本号是0
User user = userMapper.selectById(6L);
System.out.println(user);
user.setAge(19);
//再更新数据。MP会带上版本号0,
// 如果数据库里的id为6的数据版本号也是0,就能修改成功,然后版本号+1变成1
// 如果数据库里的id为6的数据版本号不是0,就放弃修改(MP会认为数据被其它线程修改了)
userMapper.updateById(user);
}4. 小结
MP的逻辑删除:
-
什么是逻辑删除?并不是真正的删除数据,而是把数据的状态字段值设置为“已删除”状态;查询数据时,不查询“已删除”状态的数据
-
如何实现逻辑删除?
-
修改表,增加一个状态字段,用于存储数据是否删除的状态
-
修改实体类,增加对应的属性,并给属性上加@TableLogic
-
修改配置文件,告诉MP,状态字段值为几的时候是已删除,状态是几的时候是未删除
-
-
逻辑删除的效果是?
-
调用delete方法,底层实际执行的是update语句,把状态设置为“已删除”状态
-
调用select、update等等方法时,底层会自动给SQL增加where条件
状态=未删除
-
悲观锁:
-
在自己操作资源数据期间,认为总有其它线程来干扰,所以要添加排他性的、独占性的锁。
在我加锁操作期间,其它所有线程都要阻塞排队。直到我释放锁,其他线程才可以再抢锁操作
-
特点:
-
安全性高,因为把多线程并发变成了串行
-
性能较低,因为同一时间只有一个线程能操作,其它线程都是阻塞排队状态
-
-
适用:写多读少的情况
-
技术:
-
synchronized关键字
-
Lock对象
-
乐观锁
-
在自己操作资源数据期间,其它线程很少来干扰,所以并不需要真正添加锁,可以有更好的性能
自己在每次操作数据时,都先校验感知一下,数据是否被其它线程修改过了
如果被其它线程修改过了:就放弃操作或者报错
如果没有被其它线程修改:就直接执行操作
-
特点:
-
安全性足够
-
性能比较好。因为没有真正加锁,在当前线程操作期间,可以有其它线程执行读操作,不会有任何影响
-
-
适合:读多写少的情况
-
思想:
-
CAS思想:Compare And Swap 对比并交换设置。比如:Java里的AtomicInteger底层使用了CAS思想,并不需要真正加锁,也能实现多线程操作时的线程安全性
-
版本号:给数据设置版本号,每次变动数据时都要把版本号+1。修改数据就可以感知,数据是否被其它线程修改了
-
MP的乐观锁:采用的是版本号方式
-
给表里增加一个版本号字段
-
给实体类里增加对应的属性,并添加@Version
-
给配置类或引导类里,配置 乐观锁插件
七、MP代码生成器
- 了解MP代码生成器的用法
1. 说明
MP可以帮我们有效的减轻开发中的工作量:所有的单表CURD完全不用自己编写了,直接使用MP就行。但是这还不够,因为我们还需要编写实体类、Mapper接口、Service、Controller代码。
为了更进一步的减轻我们的工作量,MP提供了代码生成器,可以根据数据库表,直接生成好实体类、Mapper接口,甚至Service和Controller。
可以给idea安装 MybatisPlus 插件,它可以直接生成代码。不需要我们自己编写代码生成器代码了
1.安装MybatisPlus插件
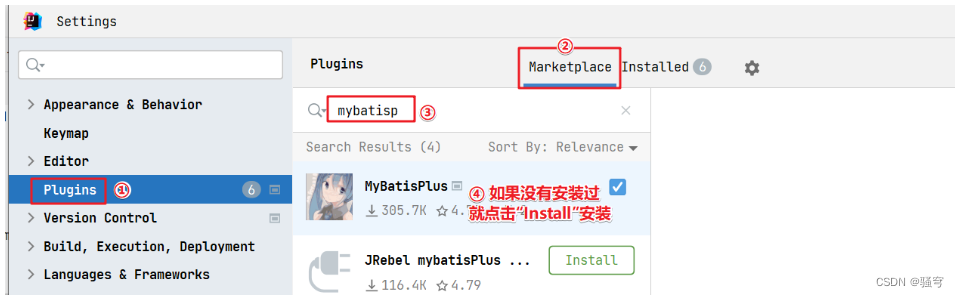
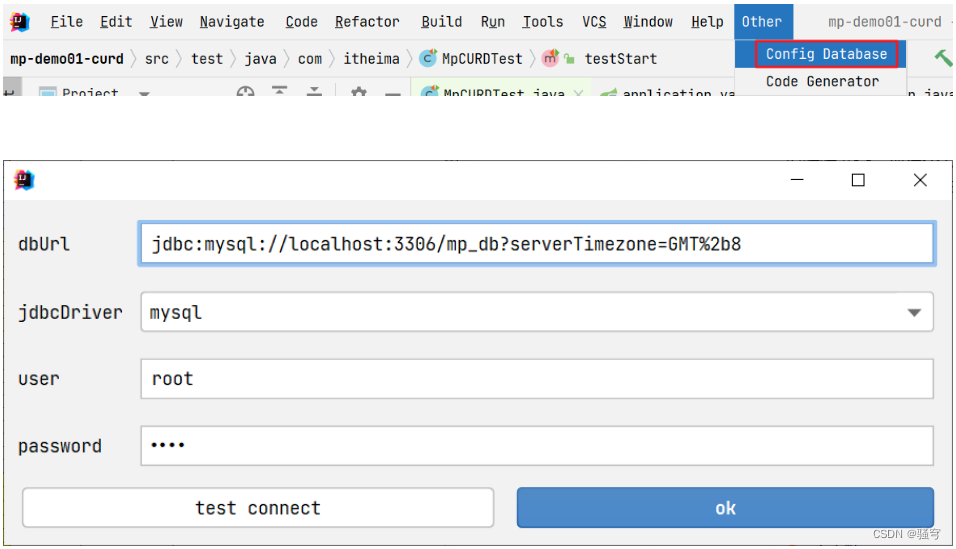
2.使用MybatisPlus插件生成代码:配置数据库信息
3.使用MybatisPlus插件生成代码:选择表,给指定表生成代码
按下图配置,实体类会生成到 com.itheima.pojo包里;Mapper接口会生成到 com.itheima.mapper包里
最后点击按钮 “Code Generatro” 生成代码

2. 示例
1 新建一个project
创建一个新的project:
-
pom.xml内容如下,注意:必须有MybatisPlus相关的起步依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.3</version>
</parent>
<dependencies>
<!--MybatisPlus的起步依赖-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.1</version>
</dependency>
<!-- MySQL驱动包 -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<version>8.0.33</version>
</dependency>
<!-- Lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.16</version>
</dependency>
</dependencies>
2 编写代码生成器
1 添加依赖
<!-- MP生成器 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>3.4.1</version>
</dependency>
<!-- MP生成代码需要的模板引擎 -->
<dependency>
<groupId>org.apache.velocity</groupId>
<artifactId>velocity-engine-core</artifactId>
<version>2.3</version>
</dependency>2 编写生成器代码
精简版
package com.itheima;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.generator.AutoGenerator;
import com.baomidou.mybatisplus.generator.config.DataSourceConfig;
import com.baomidou.mybatisplus.generator.config.GlobalConfig;
import com.baomidou.mybatisplus.generator.config.PackageConfig;
import com.baomidou.mybatisplus.generator.config.StrategyConfig;
public class MpCodeGenerator {
public static void main(String[] args) {
// 代码生成器
AutoGenerator mpg = new AutoGenerator();
// 数据源配置
DataSourceConfig dsc = new DataSourceConfig();
dsc.setUrl("jdbc:mysql://localhost:3306/mp_db?useUnicode=true&useSSL=false&characterEncoding=utf8");
dsc.setDriverName("com.mysql.cj.jdbc.Driver");
dsc.setUsername("root");
dsc.setPassword("root");
mpg.setDataSource(dsc);
//开始执行
mpg.execute();
}
}详细版两个
package com.itheima;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.generator.AutoGenerator;
import com.baomidou.mybatisplus.generator.config.DataSourceConfig;
import com.baomidou.mybatisplus.generator.config.GlobalConfig;
import com.baomidou.mybatisplus.generator.config.PackageConfig;
import com.baomidou.mybatisplus.generator.config.StrategyConfig;
public class MpCodeGenerator {
public static void main(String[] args) {
// 代码生成器
AutoGenerator mpg = new AutoGenerator();
// 全局配置
GlobalConfig gc = new GlobalConfig();
// 代码文件生成到哪:当前工程的src/main/java里
gc.setOutputDir("src/main/java");
// 代码作者
gc.setAuthor("liuyp");
// 生成后是否直接打开文件夹
gc.setOpen(false);
// 是否覆盖原代码文件
gc.setFileOverride(true);
// 主键生成策略
gc.setIdType(IdType.AUTO);
mpg.setGlobalConfig(gc);
// 数据源配置
DataSourceConfig dsc = new DataSourceConfig();
dsc.setUrl("jdbc:mysql://localhost:3306/mp_db?useUnicode=true&useSSL=false&characterEncoding=utf8");
dsc.setDriverName("com.mysql.cj.jdbc.Driver");
dsc.setUsername("root");
dsc.setPassword("root");
mpg.setDataSource(dsc);
// 包配置
PackageConfig pc = new PackageConfig();
// 设置父包名。与代码所在文件夹不冲突
pc.setParent("com.itheima");
// 设置实体类所在包名。父包名+此包名,即是实体类所在位置
pc.setEntity("pojo");
// 设置Mapper所在包名。父包名+此包名,即是Mapper接口所在位置
pc.setMapper("mapper");
mpg.setPackageInfo(pc);
// 策略配置
StrategyConfig strategy = new StrategyConfig();
// 实体类是否使用Lombok
strategy.setEntityLombokModel(true);
// 是否生成Rest风格的Controller类
strategy.setRestControllerStyle(true);
mpg.setStrategy(strategy);
mpg.execute();
}
}public class CodeGenerator {
public static void main(String[] args) {
//1.获取代码生成器的对象
AutoGenerator autoGenerator = new AutoGenerator();
//设置数据库相关配置
DataSourceConfig dataSource = new DataSourceConfig();
dataSource.setDriverName("com.mysql.cj.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://localhost:3306/mybatisplus_db?serverTimezone=UTC");
dataSource.setUsername("root");
dataSource.setPassword("root");
autoGenerator.setDataSource(dataSource);
//设置全局配置
GlobalConfig globalConfig = new GlobalConfig();
globalConfig.setOutputDir(System.getProperty("user.dir")+"/mybatisplus_04_generator/src/main/java"); //设置代码生成位置
globalConfig.setOpen(false); //设置生成完毕后是否打开生成代码所在的目录
globalConfig.setAuthor("黑马程序员"); //设置作者
globalConfig.setFileOverride(true); //设置是否覆盖原始生成的文件
globalConfig.setMapperName("%sDao"); //设置数据层接口名,%s为占位符,指代模块名称
globalConfig.setIdType(IdType.ASSIGN_ID); //设置Id生成策略
autoGenerator.setGlobalConfig(globalConfig);
//设置包名相关配置
PackageConfig packageInfo = new PackageConfig();
packageInfo.setParent("com.aaa"); //设置生成的包名,与代码所在位置不冲突,二者叠加组成完整路径
packageInfo.setEntity("domain"); //设置实体类包名
packageInfo.setMapper("dao"); //设置数据层包名
autoGenerator.setPackageInfo(packageInfo);
//策略设置
StrategyConfig strategyConfig = new StrategyConfig();
strategyConfig.setInclude("tbl_user"); //设置当前参与生成的表名,参数为可变参数
strategyConfig.setTablePrefix("tbl_"); //设置数据库表的前缀名称,模块名 = 数据库表名 - 前缀名 例如: User = tbl_user - tbl_
strategyConfig.setRestControllerStyle(true); //设置是否启用Rest风格
strategyConfig.setVersionFieldName("version"); //设置乐观锁字段名
strategyConfig.setLogicDeleteFieldName("deleted"); //设置逻辑删除字段名
strategyConfig.setEntityLombokModel(true); //设置是否启用lombok
autoGenerator.setStrategy(strategyConfig);
//2.执行生成操作
autoGenerator.execute();
}
}














 913
913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









