







sql语句补充和深入
WHERE
SELECT * FROM table_user
WHERE idx_name IS NULL;
找出所有姓名是空的记录
计算次第
和其他语言的运算符一样,sql语句的运算符也是有优先级之说的,例如a OR b AND c,在这里AND的优先级是高于OR的,所以sql语句先执行的会是b AND c,如果此时在你想要先执行a OR B 的话就要给a OR b套上一个更高优先级的运算符了,例如(),(a OR B)AND c,这句中,先执行的就会是(a OR b)了。下面举个例子:

假设我们想要取上面这个表中姓苏或者姓李,并且性别为女的人的名字。
SELECT sname FROM students WHERE sname LIKE '苏%' OR sname LIKE '李%' AND ssex = '女';
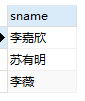
结果显然不正确,由上表我们可知,苏有朋是个男的,那么他不应该出现在结果集中才对。
SELECT sname FROM students WHERE (sname LIKE '苏%' OR sname LIKE '李%') AND ssex = '女';
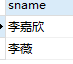
这才是正确的sql语句和结果集。
通配符
这可是个好东西,它能帮助我们描述一些无法用普通的比较运算符描述的情况,例如我上面那个sql语句就用到了通配符‘%’,它代表的含义是,任何字符出现任意次数。上面我写的‘李%’,的意思就是以李开头的所有字串,不管李后面有多少字符,都是以李开头的字串。
对了,‘%’,这个是不会匹配NULL的。
‘_’,也是匹配字符的,不过相较于‘%’,它只代表一个任意的字符。
不要过度使用通配符。如果其他操作符能达到相同的目的,应该
使用其他操作符。
在确实需要使用通配符时,除非绝对有必要,否则不要把它们用
在搜索模式的开始处。把通配符置于搜索模式的开始处,搜索起
来是最慢的。
仔细注意通配符的位置。如果放错地方,可能不会返回想要的数
据。
正则表达式
正则表达式是用来匹配文本的特殊的串(字符集合)。
正则表达式一般跟在关键字REGEXP后面
SELECT * FORM table_a WHERE idx_value REGEXP '1000';
这里用到了一个简单的正则表达式,用来在表table_a中找到idx_value列中含有1000的所有记录。
下面就是流水账了
’.'等价于通配符中的‘_’
'|’ , OR匹配,就是‘|’,数据满足左右其一就OK了。
匹配几个字符之一
在这里就是用到了[ ],作用是,匹配被这个中括号括起来的字符之一。
匹配特殊字符
上面这几个字符在正则表达式中作为特殊字符,显然,我们是不能直接用普通的sql语句找出和这几个字符匹配的正则表达式的。
好吧,这些都是废话,其实就是在这些字符前面加上\,它们就可以当做正常的字符来匹配了。
匹配字符类
sql中已经定义好的字符类,可以直接用来做正则表达式
| 类 | 说明 |
|---|---|
| [:alnum:] | 任意字母和数字(同[a-zA-Z0-9]) |
| [:alpha:] | 任意字符(同[a-zA-Z]) |
| [:blank:] | 空格和制表(同[\t]) |
| [:cntrl:] | ASCII控制字符(ASCII 0到31和127) |
| [:digit:] | 任意数字(同[0-9]) |
| [:graph:] | 与[:print:]相同,但不包括空格 |
| [:lower:] | 任意小写字母(同[a-z]) |
| [:print:] | 任意可打印字符 |
| [:punct:] | 既不在[:alnum:]又不在[:cntrl:]中的任意字符 |
| [:space:] | 包括空格在内的任意空白字符(同[\f\n\r\t\v]) |
| [:upper:] | 任意大写字母(同[A-Z]) |
| [:xdigit:] | 任意十六进制数字(同[a-fA-F0-9]) |
对匹配的数目进行更强的控制
| 元字符 | 说明 |
|---|---|
| * | 0个或多个匹配 |
| + | 1个或多个匹配(等于{1,}) |
| ? | 0个或1个匹配(等于{0,1}) |
| {n} | 指定数目的匹配 |
| {n,} | 不少于指定数目的匹配 |
| {n,m} | 匹配数目的范围(m不超过255) |
定位符
用于匹配特定位置的文本。
| 元字符 | 说明 |
|---|---|
| ^ | 文本的开始 |
| $ | 文本的结尾 |
| [[:<:]] | 词的开始 |
| [[:>:]] | 词的结尾 |















 9110
9110











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









