







一、目标
爬取QS 世界大学排名前 1000 名的数据信息,最终保存到Excel文档中,如下图:
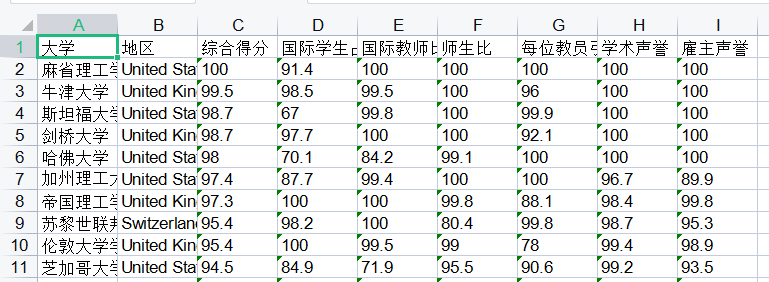
因审核问题,自行查找爬取网址,下面可参考方法!
二、爬虫的认识
1、定义
网络爬虫,是一种按照一定规则,自动抓取互联网信息的程序或脚本。由于互联网数据的多样性和资源的有限性,根据用户需求定向抓取相关网页并分析已经成为现在主流的爬取策略。
2、用途
你可以用来爬取文字信息,也可以爬取自己想看的图片、视频等等,只要你能通过浏览器访问的数据都可以通过爬虫获取。
3、本质
模拟浏览器打开网页,获取网页中我们想要的那部分数据。
三、基本流程
1、准备工作
通过浏览器查看分析目标网页,学习编程基础规范。
2、获取数据
通过HTTP库向目标站点发起请求,请求可以包含额外的header等信息,如果服务器可以正常响应,会得到一个Response,便是所要获取的页面内容。
3、解析内容
得到的内容可能是HTML,json等格式,可以用页面解析库、正则表达式等进行解析。
4、保存数据
保存样式多样,可以保存成文本,也可以保存到数据库,或者保存特定格式的文件。
四、爬取实例
首先先介绍一下所需要的python库。大家可以Ctrl+R输入cmd指令,通过pip install ×××下载。
from bs4 import BeautifulSoup #网页解析,获取数据
import re #正则表达式,进行文字匹配
import urllib.error,urllib.request #制定url,获取网页数据
import xlwt #进行excle操作
然后我们要找到所需要的指定URL网页内容。head用来模拟网页头部信息,伪装向服务器发送请求,然后封装一个request对象,经过异常处理,得到所需网页的信息。
def askURL(url):
head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"}
request = urllib.request.Request(url,headers=head)
html = ""
try:
response = urllib.request.urlopen(request)#得到网页信息
html = response.read().decode("utf-8") #读取网页信息,并重新解码,更符合html格式
except urllib.error.URLError as e:
if hasattr(e,'code'):
print(e.code)
if hasattr(e,'reason'):
print(e.reason)
return html
其次,我们使用了BeautifulSoup中python标准解析库BeautifulSoup (html, ‘html.parser’)方法解析网页,再使用CSS选择器调用select()方法获取所需数据,返回一个列表。最后利用循环和正则表达式,将前1000个大学数据封装到一个datalist列表。
#所需html内容
# <tr height="35" class="qs_bghfen">
# <td>1</td>
# <td>麻省理工学院</td>
# <td class="qsnamecolor">United States</td>
# <td>100</td>
# <td>91.4</td>
# <td>100</td>
# <td>100</td>
# <td>100</td>
# <td>100</td>
# <td>100</td>
# </tr>
mes = re.compile(r'<td>(.*)</td>')
def getData(baseurl):
datalist = []
html = askURL(baseurl)
soup = BeautifulSoup(html,'html.parser')
t_list = soup.select("tbody > tr") #选择父元素是 <tbody> 的所有 <tr> 元素。
# print(t_list)
nums = 1
for item in t_list:
if nums <= 1000:
# print(item)
data = []
item = str(item)
for j in range(1,10): #因为只需要后九项数据
m = re.findall(mes,item)[j]
data.append(m)
nums += 1
datalist.append(data)
return datalist
最后我们要做的就是运行并保存数据。先利用lxwt库创建Excel工作表,再用循环依次写入数据即可。
def saveData(datalist,savepath):
book = xlwt.Workbook(encoding="utf-8") #创建workbook对象
sheet = book.add_sheet("世界前1000大学",cell_overwrite_ok=True) #创建工作表,并使新输入数据覆盖原来数据
col = ("大学","地区","综合得分","国际学生占比","国际教师比例","师生比","每位教员引用率","学术声誉","雇主声誉")
for i in range(0,9):
sheet.write(0,i,col[i])
for i in range(1000):
print(f"第{i+1}条")
data = datalist[i]
for j in range(0,9):
sheet.write(i+1,j,data[j])
book.save(savepath)
#主程序
if __name__ == '__main__':
baseurl = "所爬取的网页"
datalist = getData(baseurl)
savepath = '世界前1000大学.xls'
saveData(datalist,savepath)
五、参考与理解
1、BeautifulSoup中HTML解析器对比
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup,“html.parser”) | Python的内置标准库;执行速度适中;文档容错能力强 | Python 2.7.3 or 3.2.2)前 的版本中文档容错能力差 |
| lxml HTML解析器 | BeautifulSoup(markup,“lxml”) | 速度快;文档容错能力强 | 需要安装C语言库 |
| lxml XML解析器 | BeautifulSoup(markup,[“lxml”,“xml”]) | 速度快;唯一支持XML的解析器 | 需要安装C语言库 |
| html5lib | BeautifulSoup(markup,“html5lib”) | 最好的容错性;以浏览器的方式解析文档;生成html5格式的文档 | 速度慢,不依靠外部扩展 |
2、统一数据类型
columns = data.columns
for i in range(2,9):
data[columns[i]] = pd.to_numeric(data[columns[i]],errors="coerce")
data = data.fillna(0)
开始我用
data['综合得分'] = data['综合得分'].astype('float64')
发现会报错,原来因为数据不纯不能用这种方法。
后来知道应该使用
pd.to_numeric(arg, errors=‘raise’, downcast=None)。
这里主要说明一下参数errors:{‘ignore’,’raise’,’coerce’},默认为raise,无效解析会发生异常;如果为ignore,无效解析返回downcast:{‘integer’,’signed’,’unsigned’,’float’},默认为None;如果为coerce,无效解析返回NaN。
3、urllib.request和requests的使用
1、urllib.request
import urllib.request
import requests
url = 'http://rankings.betteredu.net/qs/world-university-rankings/latest/2022.html'
head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"}
req = urllib.request.Request(url,headers=head)
res = urllib.request.urlopen(req)
data = res.read()
print(res)
print(data)
print(data.decode('utf-8'))
首先,urlopen()能对目标url实现最基本的访问,但一般情况下我们需要引入headers参数,可以先使用Request类进行构建。
urlopen()返回的是一个http.client.HTTPResponse对象,需要用read()方法进一步处理,再用decode()进行解码(一般为utf-8),得到我们所需的url内容。
2、requests
现在我们爬虫一般都使用requests库,它比utllib库更加便捷,requests可以直接构造get、post请求并发起,而urllib只能先构造get、post请求,再操作发起。requests是对urllib的进一步封装,更建议使用!
import urllib.request
import requests
url = 'http://rankings.betteredu.net/qs/world-university-rankings/latest/2022.html'
head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"}
res = requests.get(url,headers=head)
res.encoding='utf-8'
# res1 = requests.post(url,headers=head)
print(res)
print(res.text) #得到的是str数据类型
print(res.content)#得到的是Bytes类型,需要进行解码。作用和.text类似
print(res.json) #得到的是json数据类型
res.text得到的是str数据类型
res.content得到的是Bytes类型,需要进行解码。作用和.text类似
res.json 得到的是json数据类型
注意不要有requests.py命名的脚本,不然会报错:
AttributeError: module 'requests' has no attribute 'get'
4、空字符串处理
有时候判断空字符时,不能确定是否有空格,这种情况下还不是相等的,所以看情况处理数据。
a =""
b = " "
print(b==a)
print(b.strip()==a)
输出:
False
True
















 3634
3634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











