








前言
因为大数据的大作业是整理这个学期所学的东西,还要求最低字数不低于3000字,不然就不及格,并且要求用md文件格式,我写好了之后,就是翻来覆去不知道咋统计这个字数,下来VScode统计字数的插件,发现对中文的字没用,并且我感觉代码应该不会被算到字数里吧,因此网上搜了好久,未果,于是才想起来,为啥这东西不能自己来做呢?
使用Python统计Markdown文件字数
md其实也相当于一中文本文件,就跟txt一样操作就行了,那么应该懂了:
import codecs
result = []
skips = ["https:", ".png", "```", "div"]
# 去除代码
flag_code = 0
sum = 0
with codecs.open("期末大作业.md", "rb", 'utf-8', errors='ignore') as txtfile:
for line in txtfile:
flag = 0
line = line.replace("\r", "") # 去除\r
line = line.replace("\n", "") # 去除\n
line = line.replace("## ", "")
line = line.replace("#", "")
if "```" in line:
flag_code = 1 - flag_code
if flag_code == 1:
continue
for skip in skips:
if skip in line:
flag = 1
if flag == 1:
continue
if line == "":
continue
result.append(line)
remove = [" ", "[", "]", "<", ">", "-", "*", ".", ":"]
figue_n = 0
pure_chinese = []
for line in result:
for rem in remove:
line = line.replace(rem, "")
new_line = line
for n in line:
if n >= "a" and n <= "z":
figue_n += 1
new_line = new_line.replace(n, "")
if n >= "A" and n <= "Z":
figue_n += 1
new_line = new_line.replace(n, "")
sum += len(new_line)
pure_chinese.append(new_line)
print("总字数", sum)
print(result)
print("字母数", figue_n)
print("纯中文字数", sum - figue_n)
print(pure_chinese)
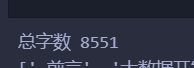
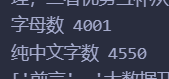
这是抠出图片、代码、各种字母后基本就剩下中文了,有4000+,内心狂喜:交作业了~


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











