






JLU-数据结构荣誉课-第二次实验-解题报告
一、数列查询
题目
已知数列的通项公式为:f(n) = f(n-1)×11/10,f(1)=10.
通项从左向右计算,×和/分别表示整数乘法和除法。 现在,要多次查询数列项的值。
输入格式:
第1行,1个整数q,表示查询的次数, 1≤q≤10000. 第2至q+1行,每行1个整数i,表示要查询f(i)的值。
输出格式:
q行,每行1个整数,表示f(i)的值。查询的值都在32位整数范围内。
输入样例:
- 3
- 1
- 2
- 3
输出样例:
- 10
- 11
- 12
题意:
根据递推式求出某项的值。
思路
本题编写难度不大,根据递推式可以写出一个求任意项值的递归函数,但是递归必定会造成程序超时,因此本题的关键是如何尽可能地缩短时间。
方法一:[记忆化搜索]
递归造成时间浪费地原因主要是每次计算第n项的值都要重头(第一项)开始算,而有些项之前已经计算过了,只是没有记录,因此我们可以把之前已经计算出来的值记录下来,当所要求的值已经计算出来,便直接输出,遇到未计算出来的值再从第一个未计算出来的位置开始向后递推。
方法二:[打表]
本题中,每项的数值是以指数增长的,而题目又说所求的值不会超过32位整数的值,因此真正可以计算的项数并不是很多,我们可以将这些不超过32位整数的项提前计算出来,最后直接输出要求的项值。
参考代码
方法一:[记忆化搜索]
#include "iostream"
//由于C++中的endl等于\n+flush,多次使用效率较低,因此需要尽量减少endl的使用,当然也可以直接使用C语言编写
#define endl "\n"
using namespace std;
int ff[10001];//记录每项的值
int v[10001];//记录每项是否已经被计算出来
int N;
int f(int n)
{
if(v[n])//如果第n项已经被计算出来
return ff[n];
else
{
for(int i=1;i<=n;i++)//从第一个未被计算出来的位置开始向后递推
if(!v[i])
{
ff[i]=ff[i-1]*11/10;
v[i]=1;
}
return ff[n];
}
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(0);
//初始化
ff[1]=10;
v[1]=1;
cin>>N;
int index;
for(int i=0;i<N;i++)
{
cin>>index;
cout<<f(index)<<endl;
}
}
方法二:[打表]
#include "iostream"
#define endl "\n"
using namespace std;
int ff[10001];
int N;
int f(int n)
{
if(n==1)
return 10;
return f(n-1)*11/10;
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(0);
for(int i=1;i<=10000;i++)
{
ff[i]=f(i);
if(ff[i]<0)//超过32位整数范围,直接退出循环
break;
}
cin>>N;
int index;
for(int i=0;i<N;i++)
{
cin>>index;
cout<<ff[index]<<endl;
}
}
提高C++输入输出效率的方法:
具体原理我也不懂,但是想要提高效率可以写上下面三句代码:
- ios::sync_with_stdio(false):解除与stdio同步
- #define endl “\n”:endl=’\n’+flush,会有额外耗时
- cin.tie(0):解除cin和cout的绑定
想要具体了解可以移步
二、稀疏矩阵之和
题目
矩阵A和B都是稀疏矩阵。请计算矩阵的和A+B.如果A、B不能做和,输出“Illegal!”
输入格式:
矩阵的输入采用三元组表示,先A后B。对每个矩阵:
第1行,3个整数N、M、t,用空格分隔,分别表示矩阵的行数、列数和非0数据项数,10≤N、M≤50000,t≤min(N,M).
第2至t+1行,每行3个整数r、c、v,用空格分隔,表示矩阵r行c列的位置是非0数据项v, v在32位有符号整型范围内。三元组默认按行列排序。
输出格式:
矩阵A+B,采用三元组表示,默认按行列排序,非零项也在32位有符号整型范围内。
输入样例:
- 10 10 3
- 2 2 2
- 5 5 5
- 10 10 20
- 10 10 2
- 2 2 1
- 6 6 6
输出样例:
- 10 10 4
- 2 2 3
- 5 5 5
- 6 6 6
- 10 10 20
题意:
计算三元组表示的稀疏矩阵之和。
思路
- 每个三元组可以用一个结构体来表示,row为行标,col为列标,val为值。分别读入两个矩阵,遍历两个矩阵中的元素,将其合并成为一个矩阵。
- 也可以先将A,B矩阵都放在一个结构体中,之后排序,然后合并相邻的行列相同的元素值,同时记录将要输出的项的下标。
参考代码
方法一:(直接合并)
#include "iostream"
#define endl "\n"
using namespace std;
struct Cell
{
int row;//行
int col;//列
int val;//值
};
Cell Array1[50001];//矩阵A
Cell Array2[50001];//矩阵B
Cell Array3[50001];//矩阵C
int Row1;
int Col1;
int Num1;
int Row2;
int Col2;
int Num2;
int main()
{
ios::sync_with_stdio(false);
cin.tie(0);
//读入矩阵A
cin>>Row1>>Col1>>Num1;
for(int i=0;i<Num1;i++)
cin>>Array1[i].row>>Array1[i].col>>Array1[i].val;
//读入矩阵B,并检测加法是否合法
cin>>Row2>>Col2>>Num2;
if(!(Row1==Row2&&Col1==Col2))
{
cout<<"Illegal!";
return 0;
}
for(int i=0;i<Num2;i++)
cin>>Array2[i].row>>Array2[i].col>>Array2[i].val;
int n1=0,n2=0,Num3=0;
while(n1<Num1&&n2<Num2)//遍历A,B两个矩阵
{
if(Array1[n1].row==Array2[n2].row)//矩阵A行标等于矩阵B
if(Array1[n1].col<Array2[n2].col)//矩阵A列标小于矩阵B
{
Array3[Num3].row=Array1[n1].row;
Array3[Num3].col=Array1[n1].col;
Array3[Num3].val=Array1[n1].val;
n1++;
Num3++;
}
else if(Array1[n1].col>Array2[n2].col)//矩阵A列标大于矩阵B
{
Array3[Num3].row=Array2[n2].row;
Array3[Num3].col=Array2[n2].col;
Array3[Num3].val=Array2[n2].val;
n2++;
Num3++;
}
else//矩阵A列标等于矩阵B
{
int sum=Array1[n1].val+Array2[n2].val;//检测值是否为零
if(sum)//和不为零,加入矩阵C
{
Array3[Num3].row=Array2[n2].row;
Array3[Num3].col=Array2[n2].col;
Array3[Num3].val=sum;
Num3++;
}
n1++;
n2++;
}
else if(Array1[n1].row>Array2[n2].row)//矩阵A行标大于矩阵B
{
Array3[Num3].row=Array2[n2].row;
Array3[Num3].col=Array2[n2].col;
Array3[Num3].val=Array2[n2].val;
n2++;
Num3++;
}
else if(Array1[n1].row<Array2[n2].row)//矩阵A行标小于矩阵B
{
Array3[Num3].row=Array1[n1].row;
Array3[Num3].col=Array1[n1].col;
Array3[Num3].val=Array1[n1].val;
n1++;
Num3++;
}
}
//将矩阵A或矩阵B中剩余的元素移动到矩阵C中
while(n1!=Num1)
{
Array3[Num3].row=Array1[n1].row;
Array3[Num3].col=Array1[n1].col;
Array3[Num3].val=Array1[n1].val;
n1++;
Num3++;
}
while(n2!=Num2)
{
Array3[Num3].row=Array2[n2].row;
Array3[Num3].col=Array2[n2].col;
Array3[Num3].val=Array2[n2].val;
n2++;
Num3++;
}
cout<<Row1<<" "<<Col1<<" "<<Num3<<endl;
for(int i=0;i<Num3;i++)
cout<<Array3[i].row<<" "<<Array3[i].col<<" "<<Array3[i].val<<endl;
}
方法二:(先排序再合并)
#include "iostream"
#include "algorithm"
#include "queue"
#define endl "\n"
using namespace std;
queue<int> d;
struct cell
{
int row;
int col;
int val;
};
cell Array[500000];
class MyCompare//自定义仿函数,用于sort()中提供排序标准
{
public:
bool operator()(cell &A,cell &B)const
{
if(A.row==B.row)
return A.col<B.col;
return A.row<B.col;
}
};
int main()
{
ios::sync_with_stdio(false);
cin.tie(0);
//按要求读入数据
int Row1,Col1,Num1;
cin>>Row1>>Col1>>Num1;
for(int i=0;i<Num1;i++)
cin>>Array[i].row>>Array[i].col>>Array[i].val;
int Row2,Col2,Num2;
cin>>Row2>>Col2>>Num2;
if(!(Row1==Row2&&Col1==Col2))//检测加法是否合法
{
cout<<"Illegal!";
return 0;
}
for(int i=Num1;i<Num1+Num2;i++)
cin>>Array[i].row>>Array[i].col>>Array[i].val;
sort(Array,Array+Num1+Num2,MyCompare());//排序
int n=Num1+Num2;
//由于本题要求先输出和矩阵的元素个数,所以我只能先合并元素,求得最终和矩阵的元素个数,再依次输出元素个数了
//因为害怕两次遍历会超时,因此采用了队列储存和矩阵元素的下标
//如果脱离题目的话,可以边合并边输出,最后再输出和矩阵元素个数
for(int i=0;i<Num1+Num2;i++)
{
if(Array[i].row==Array[i+1].row&&Array[i].col==Array[i+1].col)//因为已经排序好,因此只需要比较本项和下一项行列是否都相等即可
{
Array[i+1].val+=Array[i].val;//这里选择将相同行列的最后一个元素作为和矩阵的元素
Array[i].val=0;//将本位的值置为0
n--;//和矩阵元素个数-1
}
else if(!Array[i].val)//如果当前元素值为0
n--;//和矩阵元素个数-1
else//下标值入队
d.push(i);
}
cout<<Row1<<" "<<Col1<<" "<<n<<endl;
int index;
while(!d.empty())
{
index=d.front();
d.pop();
cout<<Array[index].row<<" "<<Array[index].col<<" "<<Array[index].val<<endl;
}
}
方法三:(此方法虽然超时,但是我觉得是一个不错的想法,用map<pair<int,int>,int>来储存矩阵的三元组,其中map的键值为行列标,实值为元素值)
#include "iostream"
#include "map"
#define endl "\n"
using namespace std;
map<pair<int,int>,int> m;//矩阵A
int Row1;
int Col1;
int Row2;
int Col2;
int Num1;
int Num2;
int main()
{
ios::sync_with_stdio(false);
cin.tie(0);
//读入矩阵A
cin>>Row1>>Col1>>Num1;
int row,col,val;
for(int i=0;i<Num1;i++)
{
cin>>row>>col>>val;
m.insert(make_pair(make_pair(row,col),val));
}
cin>>Row2>>Col2>>Num2;
map<pair<int,int>,int>::iterator it;
if(Row2==Row1&&Col1==Col2)
{
for(int i=0;i<Num2;i++)
{
cin>>row>>col>>val;
it=m.find(make_pair(row,col));//检测矩阵A中是否有该行列值
if(it==m.end())//没找到,直接加进去
{
Num1++;
m.insert(make_pair(make_pair(row,col),val));
}
else//找到了,进行加法
{
it->second=it->second+val;
if(it->second==0)//相加之后值为0,删除该节点
m.erase(it);
}
}
}
else//不合法的加法
{
cout<<"Illegal!";
return 0;
}
cout<<Row1<<" "<<Col1<<" "<<m.size()<<endl;
for(it=m.begin();it!=m.end();it++)
cout<<it->first.first<<" "<<it->first.second<<" "<<it->second<<endl;
}
三、文字编辑
题目
一篇文章由n个汉字构成,汉字从前到后依次编号为1,2,……,n。 有四种操作:
A i j表示把编号为i的汉字移动编号为j的汉字之前;
B i j表示把编号为i的汉字移动编号为j的汉字之后;
Q 0 i为询问编号为i的汉字之前的汉字的编号;
Q 1 i为询问编号为i的汉字之后的汉字的编号。
规定:1号汉字之前是n号汉字,n号汉字之后是1号汉字。
输入格式:
第1行,1个整数T,表示有T组测试数据, 1≤T≤9999.
随后的每一组测试数据中,第1行两个整数n和m,用空格分隔,分别代表汉字数和操作数,2≤n≤9999,1≤m≤9999;第2至m+1行,每行包含3个常量s、i和j,用空格分隔,s代表操作的类型,若s为A或B,则i和j表示汉字的编号,若s为Q,i代表0或1,j代表汉字的编号。
输出格式:
若干行,每行1个整数,对应每个询问的结果汉字编号。
输入样例:
- 1
- 9999 4
- B 1 2
- A 3 9999
- Q 1 1
- Q 0 3
输出样例:
- 4
- 9998
题意:
按照要求将某个汉字移动到另一个汉字的前面或后面。
输出一个汉字前面或后面的汉字。
思路
涉及到元素的移动,首先考虑的就是链表。但是本题测试数不仅一组,若选择链表,对于每组测试数据都要重新构建链表,一想就很费时间。为此我们可以选择“静态链表”——用数组去模拟链表,用一个数组Next[]来保存某个结点的后继节点的下标,用另一个数组Pre[]来保存某个节点前驱节点的下标,这样就可以省去了用链表每次创建节点所用的时间。
参考代码
#include "iostream"
#define endl "\n"
using namespace std;
int Next[10000];//保存后继节点的下标
int Pre[10000];//保存前驱节点的下标
int main()
{
ios::sync_with_stdio(false);
cin.tie(0);
int Num;
cin>>Num;
int s,n;
for(int i=0;i<Num;i++)
{
for(int j=0;j<10000;j++)//重置前驱和后继结点下标
{
Next[j]=j+1;
Pre[j]=j-1;
}
cin>>s>>n;
Next[s]=1;//尾的后继为头
Pre[1]=s;//头的前驱为尾
char ch;
int index1,index2;
for(int k=0;k<n;k++)
{
cin>>ch>>index1>>index2;
if(ch=='A')//index1到index2之前
{
Next[Pre[index1]]=Next[index1];//摘下index1
Pre[Next[index1]]=Pre[index1];
Next[Pre[index2]]=index1;//挂上index1
Next[index1]=index2;
Pre[index1]=Pre[index2];
Pre[index2]=index1;
}
else if(ch=='B')//index1到index2之后
{
Next[Pre[index1]]=Next[index1];//摘下index1
Pre[Next[index1]]=Pre[index1];
Next[index1]=Next[index2];//挂上index1
Next[index2]=index1;
Pre[index1]=index2;
Pre[Next[index1]]=index1;
}
else if(ch=='Q')
if(index1==0)//访问i前
cout<<Pre[index2]<<endl;
else//访问i后
cout<<Next[index2]<<endl;
}
}
}
静态链表是一种高效的存储结构,因为他不仅克服了数组移动费时的缺点,还克服了链表遍历费时的缺点。但对于静态链表来说,对空间的浪费比较严重。
四、幸福指数
题目
人生中哪段时间最幸福?幸福指数可能会帮你发现。幸福指数要求:对自己每天的生活赋予一个幸福值,幸福值越大表示越幸福。一段时间的幸福指数就是:这段时间的幸福值的和乘以这段时间的幸福值的最小值。幸福指数最大的那段时间,可能就是人生中最幸福的时光。
输入格式:
第1行,1个整数n,1≤n≤100000,表示要考察的天数。
第2行,n个整数Hi,用空格分隔,Hi表示第i天的幸福值,0≤Hi≤1000000。
输出格式:
第1行,1个整数,表示最大幸福指数。
第2行,2个整数l和r,用空格分隔,表示最大幸福指数对应的区间[l,r]。如果有多个这样的区间,输出最长最左区间。
输入样例:
- 7
- 6 4 5 1 4 5 6
输出样例:
- 60
- 1 3
题意:
求某区间 ( 最小值 × 区间值之和 ) 的最大值。
思路
- 计算某区间内的和值,可以采用先记录前缀和,在将对应前缀和相减的方法。
- 记录区间最小值,则需要一种容器,这里选择了单调栈。
单调栈
- 单调栈是一种特殊的栈,栈中元素保持单调递增或单调递减。以下以单调递增为例。
- 当当前元素小于栈顶元素时,以栈顶元素为最小值的区间右端点已经找到(即当前位置),而由于栈中元素保持单调递增,所以以栈顶元素为最小值的区间左端点其实早就已经存在(即栈中第一个小于栈顶元素的位置,此时可以不断弹出栈顶等于栈顶元素的结点,找到区间左端点)。因此当当前元素小于栈顶元素时,以栈顶元素为最小值的某个区间已经找到,可以对题目进行求解。
参考代码
#include "iostream"
#include "stack"
using namespace std;
stack<int> s;
long long Now;//记录当前区间最小值×区间和的值
long long Max=-1;//记录最大值
int top=1;//左区间
int rear=1;//右区间
int len=-1;//区间长度
long long a[100001];//记录每一项的值
long long S[100001];//记录区间的前n项和(前缀和)
int main()
{
int Num;
cin>>Num;
s.push(0);//压栈下标
a[0]=-1;//由于输入的值全非负,因此压栈元素选一负值即可
for(int i=1;i<=Num;i++)
{
cin>>a[i];
S[i]=S[i-1]+a[i];
int index;
index=s.top();
if(a[index]<=a[i])//如果栈顶元素不大于当前元素,当前元素下标入栈
s.push(i);
else
{
//若栈顶元素大于当前元素,说明栈顶元素已经找到了区间右端点(当前位置)
//又因为之前栈中元素是按照非递减顺序排列的,因此栈顶元素其实早就已经找到了区间左端点(此时的栈顶元素下标),由此说明此时以栈顶元素为最小值,与区间和的乘积已经可以计算了
while(a[s.top()]>a[i])//不断处理栈顶元素,直到栈顶元素不大于当前元素
{
int tmp=a[index];
while(a[index]==tmp)//弹出与栈顶元素相等的元素,找到区间左端点
{
s.pop();
index=s.top();
}
Now=tmp*(S[i-1]-S[s.top()]);//计算当前的乘积
if(Now>Max||(Now==Max&&i-1-s.top()-1>len))//检测是否更新最大值
{//①最大值小于当前值②最大值等于当前值,但区间长度比当前长度小
Max=Now;
top=s.top()+1;
rear=i-1;
len=rear-top;
}
index=s.top();
}
s.push(i);//当前元素下标入栈
}
}
int index=s.top();//处理栈中剩余的所有元素
while(s.top()!=0)
{
s.pop();
Now=a[index]*(S[Num]-S[s.top()]);
if(Now>Max||(Now==Max&&Num-s.top()-1>len))
{
Max=Now;
top=s.top()+1;
rear=Num;
len=rear-top;
}
index=s.top();
}
cout<<Max<<endl;
cout<<top<<" "<<rear<<endl;
return 0;
}
拓展题目
单调栈还有很多神奇的应用,主要求解的问题便是(区间和×区间区间最小值)的最大值。
(以下题目均为转载,由于没有具体测试案例,所以只提供求解思路)
1.求一段区间内的最小值
对N个非负整数的序列,查询元素Ai左侧最近的小于Ai的整数(1≤i≤N),如果不存在,输出 -1。
输入格式:
第1行,1个整数N,表示整数的个数,(1≤N≤100000)。
第2行,N个整数,每个整数x 都满足 0 ≤ x ≤2000000000。
输出格式:
1行,N个整数,表示每个元素Ai左侧最近的小于Ai的整数(1≤i≤N)。
输入样例:
- 6
- 1 2 5 3 4 6
输出样例:
- -1 1 2 2 3 4
思路:
本题为单调栈最简单的应用,就不解释了。
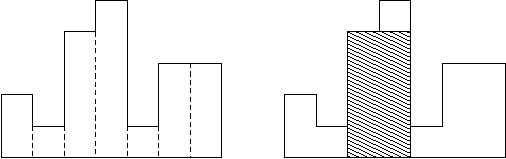
2.求最大子矩形面积
如图所示,在一条水平线上有 n 个宽为 1 的矩形,求包含于这些矩形的最大子矩形面积(图中的阴影部分的面积即所求答案)。
输入格式:
多组测试数据,每组数据占一行。输入0时读入结束。
每行开头为一个数字n(1≤n≤105),接下来在同一行给出n个数字h1,h2,…,hn(0≤hi≤109),表示每个矩形的高度。
输出格式:
对每组数据,输出最大子矩形面积,一组数据输出一行。
输入样例:
- 7 2 1 4 5 1 3 3
- 4 1000 1000 1000 1000
- 0
输出样例:
- 8
- 4000
思路:
本题和“幸福指数”属于一类题目,都是求(区间最小值×区间和)的最大值,只是本题区间和即为区间长度。
3.求最大的1子矩阵
给定一个仅由0,1构成的矩阵,求其所有 仅由1构成的 子矩阵中,面积最大的子矩阵的元素个数。
输入格式:
输入包含多个测试案例。每个测试案例以 m 和 n (1 ≤ m,n ≤ 2000) 开头。 然后是 m 行n列由0,1 组成的矩阵。
输出格式:
对于每个测试案例,输出一行其仅由1构成的所有子矩阵中元素个数最多的元素个数,如果所给的矩阵是零矩阵,则输出0。
输入样例:
- 2 2
- 0 0
- 0 0
- 4 4
- 0 0 0 0
- 0 1 1 0
- 0 1 1 0
- 0 0 0 0
输出样例:
- 0
- 4
思路:
本题是上一题的进阶版,把一维操作变为二维操作即可。这里有一个很巧妙的转换问题的方法:
先给定一个5×5的矩阵
- 0 0 0 0 0
- 0 1 1 0 0
- 0 1 1 1 1
- 0 1 1 1 1
- 1 0 1 0 0
我们来进行一些转换,将每行1的值换成上一行的值+1,即该矩阵可以转换成:
- 0 0 0 0 0
- 0 1 1 0 0
- 0 2 2 0 1
- 0 3 3 1 2
- 1 0 4 0 0
这样,对于前二排,问题就转换成了求高度按"0 1 1 0 0"排列的矩形中,最大子矩形面积;对于前三排,问题就转换成了求高度按"0 2 2 0 1"排列的矩形中,最大子矩形的面积…以此类推。于是本题便只需要在求解最大子矩形面积的代码中加一层for循环即可(循环求前n行矩形的最大面积)。















 265
265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









