






#引入的包
import pandas as pd
import numpy as np
from numpy import nan as NA
缺失数据表示和处理方法
- pandas库的目标之一是尽量轻松处理缺失数据,例如:pandas对象的所有描述性统计都默认不包括缺失的数据
- pandas中,数值型数据用NaN(Not a Number)表示缺失数据,称为哨兵值。其他数据的缺失用NA(Not Available)表示,python的内置None值在对象数组中也为NA。
| 缺失数据处理方法 | 解释 |
|---|---|
| dropna | 根据各标签中是否存在缺失数据对轴标签进行过滤 |
| fillna | 用指定值或插值方法填充缺失数据 |
| isnull | 返回一个用布尔值表示数据是否缺失的对象 |
| notnull | isnull的否定式 |
滤除缺失数据
-
滤除Series对象的缺失数据
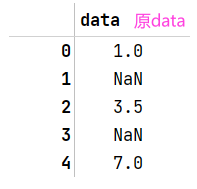
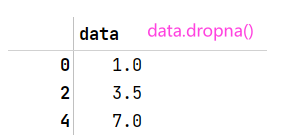
dropna方法返回一个仅含非空数据和索引的Seriesdata.dropna等价于data[data.notnull()]data = pd.Series([1,NA,3.5,NA,7]) data.dropna()
-
滤除DataFrame对象的缺失数据
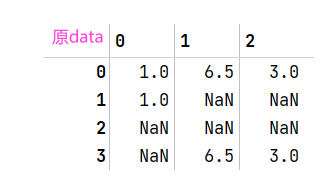
dropna方法默认丢弃任何含有缺失值的行参数
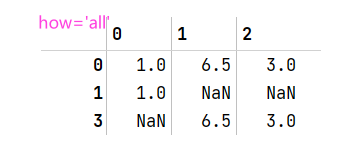
how='all'丢弃全为NA的行,传入axis=1用来丢弃列data = pd.DataFrame([[1.,6.5,3.],[1.,NA,NA],[NA,NA,NA],[NA,6.5,3.]]) cleaned = data.dropna() data.dropna(how='all') #data.dropna(how='all',axis=1)

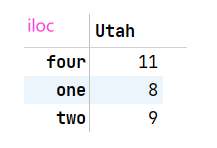
loc 和iloc是特殊的索引,分别用来标签索引和整数索引,从DataFrame中选择行和列的子集
data = pd.DataFrame(np.arange(16).reshape((4, 4)),
index=['Ohio', 'Colorado', 'Utah', 'New York'],#行标签
columns=['one', 'two', 'three', 'four'])#列标签
data.loc['Colorado',['two','three']] #索引'colorado'行的'two','three'列
data.iloc[2,[3,0,1]] #索引'2'行并按'3' '0' '1'的顺序显示列


thresh参数只留下一部分观测数据,用于指定每行(或每列)中非缺失值的最小数量,只有达到或超过这个阈值的行(或列)才会被保留。
df = pd.DataFrame(np.random.randn(7,3))
df.iloc[:4,1] = NA
df.iloc[:2,2] = NA
df.dropna(thresh=2)#非缺失值大于等于两个的行或列保留,小于的舍弃
![[)]](https://img-blog.csdnimg.cn/8b0864efe24341a2b76a55e5d511f5a5.png)
![[)]](https://img-blog.csdnimg.cn/4eef743fe26146328d4ef7dfeda8d20d.png)
填充缺失数据
如果不希望滤除缺失数据(因为有时候会丢弃跟它有关的其他数据),可以使用填充,一般用fillna
-
fillna常用参数参数 说明 value 用于填充缺失值的标量值或字典 method 插值方式,默认为ffill(forward fill,意思是使用前一个非缺失值来填充) axis 填充轴 inplace 是否在原本对象上进行修改 limit 可以连续填充的最大数量 -
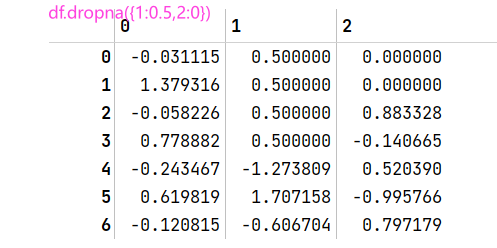
fillna函数传入常数,则用常数替换缺失值
传入字典,可以实现对不同列填充不同值
fillna默认返回新对象,参数inplace=True可以直接对原对象修改#df与上面相同 df.fillna(0) df.fillna({1:0.5,2:0})#第'1'列的NA用0.5填充,第'2'列用0填充![AppData\Roaming\Typora\typora-user-images\image-20230807101803120.png)]](https://img-blog.csdnimg.cn/49eb5b8d313842e6a44d999315bf0cac.png)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









