







文章目录
- Linux常用基础命令
- ls命令
- pwd命令
- cd命令
- touch命令
- mkdir命令
- rm命令
- cp命令
- mv命令
- cat命令
- tac命令
- more命令
- less命令
- head命令
- tail命令
- cut命令
- sort命令
- uniq命令
- wc命令
- tr命令
- stat命令
- find命令
- xargs命令
- file命令
- which命令
- whereis命令
- tar命令
- gzip命令
- zip命令
- unzip命令
- date命令
- shred命令
- useradd命令
- usermode命令
- userdel命令
- groupadd命令
- groupdel命令
- passwd命令
- id命令
- whoami、who、w、last、lastlog
- su命令
- visudo命令
- sudo命令
- chmod命令
- chown命令
- chgrp命令
- umask命令
- chatter命令
- lsattr命令
- history命令
- Linux常见通配符
- 特殊通配符
- 基本正则表达式符号
- 扩展正则表达式符号
- grep命令
- sed命令
- awk命令
- crontab命令
- fdisk命令
- ln命令
- mount命令
- mdadm命令
- rpm命令
- netstat命令
- ss命令
- ping命令
- telnet命令
- ssh命令
- wget命令
- nslookup命令
- nmap命令
- ps命令
- pstree命令
- pgrep命令
- kill命令
- killall命令
- pkill命令
- top命令
- nohup命令
- bg命令
- runlevel命令
- init命令
- service命令
- htop命令
- 调整htop的风格
- glances命令
- glances运行web服务
- glances服务器/客户端模式
- glances命令
- glances运行web服务
- glances服务器/客户端模式
Linux常用基础命令
ls命令
显示目录内容列表
ls命令,用来显示目标列表,在Linux中使用率最高的命令,ls命令的输出嘻嘻可以进行彩色加亮显示,以区分不同类型的文件
语法
ls [选项] [文件名]
选项
-C # 多列输出,纵向排序。
-F # 每个目录名加 "/" 后缀,每个 FIFO 名加 "|" 后缀, 每个可运行名加“ * ”后缀。
-R # 递归列出遇到的子目录。
-a # 列出所有文件,包括以 "." 开头的隐含文件。
-c # 使用“状态改变时间”代替“文件修改时间”为依据来排序(使用“-t”选项时)或列出(使用“-l”选项时)。
-d # 将目录名像其它文件一样列出,而不是列出它们的内容。
-i # 输出文件前先输出文件系列号(即 i 节点号: i-node number)。 -l 列出(以单列格式)文件模式
# (file mode),文件的链接数,所有者名,组名,文件大小(以字节为单位),时间信息,及文件名。
# 缺省时,时间信息显示最近修改时间;可以以选项“-c”和“-u”选择显示其它两种时间信息。对于设备文件,
# 原先显示文件大小的区域通常显示的是主要和次要的信号(majorand minor device numbers)。
-q # 将文件名中的非打印字符输出为问号。(对于到终端的输出这是缺省的。)
-r # 逆序排列。
-t # 按时间信息排序。
-u # 使用最近访问时间代替最近修改时间为依据来排序(使用“-t”选项时)或列出(使用“-l”选项时)。
-1 # 单列输出。
-1, --format=single-column # 一行输出一个文件(单列输出)。如标准输出不是到终端,此选项就是缺省选项。
-a, --all # 列出目录中所有文件,包括以“.”开头的文件。
-b, --escape # 把文件名中不可输出的字符用反斜杠加字符编号(就像在 C 语言里一样)的形式列出。
-c, --time=ctime, --time=status
# 按文件状态改变时间(i节点中的ctime)排序并输出目录内
# 容。如采用长格式输出(选项“-l”),使用文件的状态改
# 变时间取代文件修改时间。【译注:所谓文件状态改变(i节
# 点中以ctime标志),既包括文件被修改,又包括文件属性( 如所有者、组、链接数等等)的变化】
-d, --directory
# 将目录名像其它文件一样列出,而不是列出它们的内容。
-f # 不排序目录内容;按它们在磁盘上存储的顺序列出。同时启 动“ -a ”选项,如果在“ -f ”之前存在“ -l”、
# “ - -color ”或“ -s ”,则禁止它们。
-g # 忽略,为兼容UNIX用。
-i, --inode
# 在每个文件左边打印 i 节点号(也叫文件序列号和索引号: file serial number and index num‐
# ber)。i节点号在每个特定的文件系统中是唯一的。
-k, --kilobytes
# 如列出文件大小,则以千字节KB为单位。
-l, --format=long, --format=verbose
# 除每个文件名外,增加显示文件类型、权限、硬链接数、所 有者名、组名、大小( byte
# )、及时间信息(如未指明是 其它时间即指修改时间)。对于6个月以上的文件或超出未来 1
# 小时的文件,时间信息中的时分将被年代取代。
# 每个目录列出前,有一行“总块数”显示目录下全部文件所 占的磁盘空间。块默认是 1024
# 字节;如果设置了 POSIXLY_CORRECT 的环境变量,除非用“ -k ”选项,则默认块大小是 512 字
# 节。每一个硬链接都计入总块数(因此可能重复计数),这无 疑是个缺点。
# 列出的权限类似于以符号表示(文件)模式的规范。但是 ls
# 在每套权限的第三个字符中结合了多位( multiple bits ) 的信息,如下: s 如果设置了 setuid
# 位或 setgid 位,而且也设置了相应的可执行位。 S 如果设置了 setuid 位或 setgid
# 位,但是没有设置相应的可执行位。 t 如果设置了 sticky 位,而且也设置了相应的可执行位。 T
# 如果设置了 sticky 位,但是没有设置相应的可执行位。 x
# 如果仅仅设置了可执行位而非以上四种情况。 - 其它情况(即可执行位未设置)。
-m, --format=commas
# 水平列出文件,每行尽可能多,相互用逗号和一个空格分隔。
-n, --numeric-uid-gid
# 列出数字化的 UID 和 GID 而不是用户名和组名。
-o # 以长格式列出目录内容,但是不显示组信息。等于使用“ --format=long --no-group
# ”选项。提供此选项是为了与其它版本的 ls 兼容。
-p # 在每个文件名后附上一个字符以说明该文件的类型。类似“ -F ”选项但是不 标示可执行文件。
-q, --hide-control-chars
# 用问号代替文件名中非打印的字符。这是缺省选项。
-r, --reverse
# 逆序排列目录内容。
-s, --size
# 在每个文件名左侧输出该文件的大小,以 1024 字节的块为单位。如果设置了 POSIXLY_CORRECT
# 的环境变量,除非用“ -k ”选项,块大小是 512 字节。
-t, --sort=time
# 按文件最近修改时间( i 节点中的 mtime )而不是按文件名字典序排序,新文件 靠前。
-u, --time=atime, --time=access, --time=use
# 类似选项“ -t ”,但是用文件最近访问时间( i 节点中的 atime )取代文件修
# 改时间。如果使用长格式列出,打印的时间是最近访问时间。
-w, --width cols
# 假定屏幕宽度是 cols ( cols 以实际数字取代)列。如未用此选项,缺省值是这
# 样获得的:如可能先尝试取自终端驱动,否则尝试取自环境变量 COLUMNS (如果设
# 置了的话),都不行则取 80 。
-x, --format=across, --format=horizontal
# 多列输出,横向排序。
-A, --almost-all
# 显示除 "." 和 ".." 外的所有文件。
-B, --ignore-backups
# 不输出以“ ~ ”结尾的备份文件,除非已经在命令行中给出。
-C, --format=vertical
# 多列输出,纵向排序。当标准输出是终端时这是缺省项。使用命令名 dir 和 d 时, 则总是缺省的。
-D, --dired
# 当采用长格式(“-l”选项)输出时,在主要输出后,额外打印一行: //DIRED// BEG1 END1 BEG2
# END2 ...
# BEGn 和 ENDn 是无符号整数,记录每个文件名的起始、结束位置在输出中的位置(
# 字节偏移量)。这使得 Emacs 易于找到文件名,即使文件名包含空格或换行等非正
# 常字符也无需特异的搜索。
#
# 如果目录是递归列出的(“ -R ”选项),每个子目录后列出类似一行:
# //SUBDIRED// BEG1 END1 ... 【译注:我测试了 TurboLinux4.0 和 RedHat6.1 ,发现它们都是在 “
# //DIRED// BEG1... ”之后列出“ //SUBDIRED// BEG1 ... ”,也即只有一个
# 而不是在每个子目录后都有。而且“ //SUBDIRED// BEG1 ... ”列出的是各个子目 录名的偏移。】
-F, --classify, --file-type
# 在每个文件名后附上一个字符以说明该文件的类型。“ * ”表示普通的可执行文件; “ / ”表示目录;“
# @ ”表示符号链接;“ | ”表示FIFOs;“ = ”表示套接字 (sockets) ;什么也没有则表示普通文件。
-G, --no-group
# 以长格式列目录时不显示组信息。
-I, --ignorepattern
# 除非在命令行中给定,不要列出匹配shell文件名匹配式(pattern ,不是指一般
# 表达式)的文件。在shell中,文件名以"."起始的不与在文件名匹配式(pattern)
# 开头的通配符匹配。
-L, --dereference
# 列出符号链接指向的文件的信息,而不是符号链接本身。
-N, --literal
# 不要用引号引起文件名。
-Q, --quote-name
# 用双引号引起文件名,非打印字符以 C 语言的方法表示。
-R, --recursive
# 递归列出全部目录的内容。
-S, --sort=size
# 按文件大小而不是字典序排序目录内容,大文件靠前。
-T, --tabsize cols
# 假定每个制表符宽度是 cols 。缺省为 8。为求效率, ls 可能在输出中使用制表符。 若 cols 为
0,则不使用制表符。
-U, --sort=none
# 不排序目录内容;按它们在磁盘上存储的顺序列出。(选项“-U”和“-f”的不
# 同是前者不启动或禁止相关的选项。)这在列很大的目录时特别有用,因为不加排序
# 能显著地加快速度。
-X, --sort=extension
# 按文件扩展名(由最后的 "." 之后的字符组成)的字典序排序。没有扩展名的先列 出。
--color[=when]
# 指定是否使用颜色区别文件类别。环境变量 LS_COLORS 指定使用的颜色。如何设置 这个变量见 dir‐
# colors(1) 。 when 可以被省略,或是以下几项之一:
none # 不使用颜色,这是缺省项。
# auto 仅当标准输出是终端时使用。 always 总是使用颜色。指定 --color 而且省略 when 时就等同于
# --color=always 。
--full-time
# 列出完整的时间,而不是使用标准的缩写。格式如同 date(1) 的缺省格式;此格式
# 是不能改变的,但是你可以用 cut(1) 取出其中的日期字串并将结果送至命令 “ date -d ”。
# 输出的时间包括秒是非常有用的。( Unix 文件系统储存文件的时间信息精确到秒,
# 因此这个选项已经给出了系统所知的全部信息。)例如,当你有一个 Makefile 文件
# 不能恰当地生成文件时,这个选项会提供帮助。
pwd命令
查看当前所在目录
cd命令
作用:
切换文件夹
语法
cd 目录名
touch命令
创建新的空文件
语法
touch 文件名
mkdir命令
用来创建目录
语法
mkdir 目录名
选项
-Z:设置安全上下文,当使用SELinux时有效;
-m<目标属性>或--mode<目标属性>建立目录的同时设置目录的权限;
-p或--parents 若所要建立目录的上层目录目前尚未建立,则会一并建立上层目录;
--version 显示版本信息。
rm命令
用于删除指定的文件和目录
语法
rm [选项] [参数]
选项
-d:直接把欲删除的目录的硬连接数据删除成0,删除该目录;
-f:强制删除文件或目录;
-i:删除已有文件或目录之前先询问用户;
-r或-R:递归处理,将指定目录下的所有文件与子目录一并处理;
--preserve-root:不对根目录进行递归操作;
-v:显示指令的详细执行过程。
cp命令
用法:cp [选项]... [-T] 源文件 目标文件
或:cp [选项]... 源文件... 目录
或:cp [选项]... -t 目录 源文件...
将源文件复制至目标文件,或将多个源文件复制至目标目录。
-r 递归式复制目录,即复制目录下的所有层级的子目录及文件 -p 复制的时候 保持属性不变
-d 复制的时候保持软连接(快捷方式)
-a 等于-pdr
-p 等于--preserve=模式,所有权,时间戳,复制文件时保持源文件的权限、时间属性
-i, --interactive 覆盖前询问提示
mv命令
mv命令就是move的缩写,作用是移动或是重命名文件
用法:mv [选项]... [-T] 源文件 目标文件
或:mv [选项]... 源文件... 目录
或:mv [选项]... -t 目录 源文件...
将源文件重命名为目标文件,或将源文件移动至指定目录。
-f, --force 覆盖前不询问
-i, --interactive 覆盖前询问
-n, --no-clobber 不覆盖已存在文件如果您指定了-i、-f、-n 中的多个,仅最后一个生效。
-t, --target-directory=DIRECTORY 将所有参数指定的源文件或目录移动至 指定目录
-u, --update 只在源文件文件比目标文件新,或目标文件不存在时才进行移动
linux帮助帮助命令
man帮助命令当你不知道Linux命令如何使用的时候,使用man命令帮助
语法
man 命令
如:
man ls
进入man帮助文档后,按下q退出
cat命令
cat命令用于查看纯文本文件(常用于内容较少的),指的是可以连接多个文件且打印到屏幕,或是重定向到文件中
用法:cat [选项] [文件]...
将[文件]或标准输入组合输出到标准输出。
清空文件内容,慎用
> 文件名
-A, --show-all 等价于 -vET
-b, --number-nonblank 对非空输出行编号
-e 等价于 -vE
-E, --show-ends 在每行结束处显示 $
-n, --number 对输出的所有行编号
-s, --squeeze-blank 不输出多行空行
-t 与 -vT 等价
-T, --show-tabs 将跳格字符显示为 ^I
-u (被忽略)
-v, --show-nonprinting 使用 ^ 和 M- 引用,除了 LFD 和 TAB 之外
--help 显示此帮助信息并退出
--version 输出版本信息并退出
如果[文件]缺省,或者[文件]为 - ,则读取标准输入。
tac命令
与cat命令作用相反,反向读取文件内容
more命令
More是一个过滤器, 用于分页显示 (一次一屏) 文本,以当前屏幕窗口尺寸为准
语法
more 参数 文件
-num 指定屏幕显示大小为num行
+num 从num行开始显示
交互式more的命令:
空格 向下滚动一屏
Enter 向下显示一行
= 显示当前行号
q 退出
less命令
less命令是more的反义词
语法:
less 参数 文件
-N 显示每行编号
-e 到文件结尾自动退出,否则得手动输入q退出
子命令
整个的翻页
b 向前一页
f 向后一页
空格 查看下一行,等于 ↓
y 查看上一行,等于↑
q退出
head命令
用于显示文件内容头部,默认显示开头10行
用法:head [选项]... [文件]...
将每个指定文件的头10 行显示到标准输出。
如果指定了多于一个文件,在每一段输出前会给出文件名作为文件头。
如果不指定文件,或者文件为"-",则从标准输入读取数据。
-c, --bytes=[-]K 显示每个文件的前K 字节内容;
如果附加"-"参数,则除了每个文件的最后K字节数据外
显示剩余全部内容
-n, --lines=[-]K 显示每个文件的前K 行内容;
如果附加"-"参数,则除了每个文件的最后K 行外显示
剩余全部内容
-q, --quiet, --silent 不显示包含给定文件名的文件头
-v, --verbose 总是显示包含给定文件名的文件头
--help 显示此帮助信息并退出
--version 显示版本信息并退出
tail命令
显示文件内容的末尾,默认输出后10行
-c 数字 指定显示的字节数
-n 行数 显示指定的行数
-f 实时刷新文件变化
-F 等于 -f --retry 不断打开文件,与-f合用
--pid=进程号 进程结束后自动退出tail命令
-s 秒数 检测文件变化的间隔秒数
cut命令
cut - 在文件的每一行中提取片段
在每个文件file的各行中,把提取片段显示在标准输出
语法
cut 参数 文件
-b 以字节为单位分割
-n 取消分割多字节字符,与-b一起用
-c 以字符为单位
-d 自定义分隔符,默认以tab为分隔符
-f 与-d一起使用,指定显示哪个区域
N 第 N 个 字节, 字符 或 字段, 从 1 计数 起
N- 从 第 N 个 字节, 字符 或 字段 直至 行尾
N-M 从 第 N 到 第 M (并包括 第M) 个 字节, 字符 或 字段
-M 从 第 1 到 第 M (并包括 第M) 个 字节, 字符 或 字段
sort命令
sort命令将输入的文件内容按照顺序规则排序,然后输出结构
用法:sort [选项]... [文件]...
或:sort [选项]... --files0-from=F
串联排序所有指定文件并将结果写到标准输出。
-b, --ignore-leading-blanks 忽略前导的空白区域
-n, --numeric-sort 根据字符串数值比较
-r, --reverse 逆序输出排序结果
-u, --unique 配合-c,严格校验排序;不配合-c,则只输出一次排序结果
-t, --field-separator=分隔符 使用指定的分隔符代替非空格到空格的转换
-k, --key=位置1[,位置2] 在位置1 开始一个key,在位置2 终止(默认为行尾)
uniq命令
uniq命令可以输出或者忽略文件中的重复行,常与sort排序结合使用
用法:uniq [选项]... [文件]
从输入文件或者标准输入中筛选相邻的匹配行并写入到输出文件或标准输出。
不附加任何选项时匹配行将在首次出现处被合并。
-c, --count 在每行前加上表示相应行目出现次数的前缀编号
-d, --repeated 只输出重复的行
-u, --unique 只显示出现过一次的行,注意了,uniq的只出现过一次,是针对-c统计之后的结果
wc命令
wc命令用于统计文件的行数,单词,字节数
-c, --bytes打印字节数
-m, --chars 打印字符数
-l, --lines 打印行数
-L, --max-line-length 打印最长行的长度
-w, --words 打印单词数
tr命令
tr命令从标准输入替换,所见或删除字符,将结果写入到标准输出
用法:tr [选项]... SET1 [SET2]
从标准输入中替换、缩减和/或删除字符,并将结果写到标准输出。
字符集1:指定要转换或删除的原字符集。
当执行转换操作时,必须使用参数“字符集2”指定转换的目标字符集。
但执行删除操作时,不需要参数“字符集2”;
字符集2:指定要转换成的目标字符集。
-c或——complerment:取代所有不属于第一字符集的字符;
-d或——delete:删除所有属于第一字符集的字符;
-s或--squeeze-repeats:把连续重复的字符以单独一个字符表示;
-t或--truncate-set1:先删除第一字符集较第二字符集多出的字符。
stat命令
stat命令用于显示文件的状态信息,stat命令输出信息比ls命令的输出更加详细
语法
stat(选项)(参数)
选项
-L, --dereference 跟随链接
-f, --file-system 显示文件系统状态而非文件状态
-c --format=格式 使用指定输出格式代替默认值,每用一次指定格式换一新行
--printf=格式 类似 --format,但是会解释反斜杠转义符,不使用换行作
输出结尾。如果您仍希望使用换行,可以在格式中
加入"\n"
-t, --terse 使用简洁格式输出
--help 显示此帮助信息并退出
--version 显示版本信息并退出
有效的文件格式序列(不使用 --file-system):
%a 八进制权限
参数
文件:指定要显示信息的普通文件或者文件系统对应的设备文件名。
stat的时间戳
Access: 2019-10-18 14:58:59.465647961 +0800
Modify: 2019-10-18 14:58:57.799636638 +0800
Change: 2019-10-18 14:58:57.799636638 +0800
access、最近访问,文件每次被cat之后,时间变化,由于操作系统特性,做了优化,频繁访问,时间不变
modify,最近更改,更改文件内容,vim等
change,最近改动,文件元数据改变,如文件名
find命令
find命令用来在指定目录下查找的文件,任何未予参数之前的字符串都将被视为欲查找的目录名,
如果使用改名了时,不设置任何参数,则find命令将在当前目录下查找子目录与文件。
并且将查找的子目录和文件全部进行显示

语法
find 查找目录和文件,语法:
find 路径 -命令参数 [输出形式]
参数说明:
路径:告诉find在哪儿去找你要的东西,
| 参数 | 解释 | |
|---|---|---|
| pathname | 要查找的路径 | |
| options选项 | ||
| -maxdepth | <目录层级>:设置最大目录层级; | |
| -mindepth | <目录层级>:设置最小目录层级; | |
| tests模块 | ||
| -atime | 按照文件访问access的时间查找,单位是天 | |
| -ctime | 按照文件的改变change状态来查找文件,单位是天 | |
| -mtime | 根据文件修改modify时间查找文件【最常用】 | |
| -name | 按照文件名字查找,支持* ? [] 通配符 | |
| -group | 按照文件的所属组查找 | |
| -perm | 按照文件的权限查找 | |
| -size n[cwbkMG] | 按照文件的大小 为 n 个由后缀决定的数据块。 其中后缀为: b: 代表 512 位元组的区块(如果用户没有指定后缀,则默认为 b) c: 表示字节数 k: 表示 kilo bytes (1024字节) w: 字 (2字节) M:兆字节(1048576字节) G: 千兆字节 (1073741824字节) | |
| -type 查找某一类型的文件 | b - 块设备文件。 d - 目录。 c - 字符设备文件。 p - 管道文件。 l - 符号链接文件。 f - 普通文件。 s - socket文件 | |
| -user | 按照文件属主来查找文件。 | |
| -path | 配合-prune参数排除指定目录 | |
| Actions模块 | ||
| -prune | 使find命令不在指定的目录寻找 | |
| -delete | 删除找出的文件 | |
| -exec 或-ok | 对匹配的文件执行相应shell命令 | |
| 将匹配的结果标准输出 | ||
| OPERATORS | ||
| ! | 取反 | |
| -a -o | 取交集、并集,作用类似&&和\ | \ |
unix/linux文件系统每个文件都有三种使劲戳
- 访问时间(-atime/天,-amin/分钟):用户最近一次访问时间(文件修改了,还未被读取过,则不变)。
- 修改时间(-mtime/天,-mmin/分钟):文件最后一次修改时间(数据变动)。
- 变化时间(-ctime/天,-cmin/分钟):文件数据元(例如权限等)最后一次修改时间。

- 文件任何数据改变,change变化,无论是元数据变动,或是对文件mv,cp等
- 文件内容被修改时,modify和change更新
- 当change更新后,第一次访问该文件(cat,less等),access time首次会更新,之后则不会
touch -a :仅更新Access time(同时更新Change为current time)
touch -m:仅更新Modify time(同时更新Change为current time)
touch -c:不创建新文件
touch -t:使用指定的时间更新时间戳(仅更改Access time与Modify time,Change time更新为current time)
案例
# 恰好在7天内被访问过的文件
[root@localhost tmp]# find /opt/ -maxdepth 3 -type f -atime 7
时间说明
- -atime -2 搜索在2天内被访问过的文件
- -atime 2 搜索恰好在2天前被访问过的文件
- -atime +2 超过2天内被访问的文件
使用-exec或是-ok再次处理
-ok比-exec更安全,存在用户提示确认
#找出以.txt结尾的文件后执行删除动作且确认
[root@pylinux opt]# find /opt/luffy_boy -type f -name "*.txt" -ok rm {} \;
备注
-exec 跟着shell命令,结尾必须以;分号结束,考虑系统差异,加上转义符\;
{}作用是替代find查阅到的结果
{}前后得有空格
#把30天以前的日志,移动到old文件夹中
find . -type f -mtime +30 -name "*.log" -exec cp {} old \;
xargs命令
xargs又称管道命令,构造参数等。
是i命令传递的一个过滤器,也是组合多个命令的一个工具他把一个数据流分割为一些足够小的块以便过滤器和命令进行处理
简单的说就是把其他命令给他的数据,传递给他后面的命令作为参数
-d 为输入指定一个定制的分割符,默认分隔符是空格
-i 用 {} 代替 传递的数据
-I string 用string来代替传递的数据-n[数字] 设置每次传递几行数据
-n 选项限制单个命令行的参数个数
-t 显示执行详情
-p 交互模式
-P n 允许的最大线程数量为n
-s[大小] 设置传递参数的最大字节数(小于131072字节)
-x 大于 -s 设置的最大长度结束 xargs命令执行
-0,--null项用null分隔,而不是空白,禁用引号和反斜杠处理
重点
xargs识别字符串的标识是空格或是换行符,因此如果遇见文件名有空格或是换行符,xargs就会识别为两个字符串,就会报错
- -print0在find中表示每一个结果之后加一个NULL字符,而不是换行符(find默认在结果后加上\n,因此结果是换行输出的)
- Xargs -0 表示xargs用NULL作为分隔符

file命令
显示文件的类型
which命令
查找PATH环境变量中的文件,Linux内置命令不在不在path中
whereis命令
whereis命令用来指定二进制程序,源代码和man手册页等相关文件的路径
tar命令
tar命令在Linux系统中,可以时效件对多个文件进行,压缩,打包,解压
语法:
tar(选项)(参数)
-A或--catenate:新增文件到以存在的备份文件;
-B:设置区块大小;
-c或--create:建立新的备份文件;
-C <目录>:这个选项用在解压缩,若要在特定目录解压缩,可以使用这个选项。
-d:记录文件的差别;
-x或--extract或--get:从备份文件中还原文件;
-t或--list:列出备份文件的内容;
-z或--gzip或--ungzip:通过gzip指令处理备份文件;
-Z或--compress或--uncompress:通过compress指令处理备份文件;
-f<备份文件>或--file=<备份文件>:指定备份文件;
-v或--verbose:显示指令执行过程;
-r:添加文件到已经压缩的文件;
-u:添加改变了和现有的文件到已经存在的压缩文件;
-j:支持bzip2解压文件;
-v:显示操作过程;
-l:文件系统边界设置;
-k:保留原有文件不覆盖;
-m:保留文件不被覆盖;
-w:确认压缩文件的正确性;
-p或--same-permissions:用原来的文件权限还原文件;
-P或--absolute-names:文件名使用绝对名称,不移除文件名称前的“/”号;不建议使用
-N <日期格式> 或 --newer=<日期时间>:只将较指定日期更新的文件保存到备份文件里;
--exclude=<范本样式>:排除符合范本样式的文件。
-h, --dereference跟踪符号链接;将它们所指向的文件归档并输出
注意
- f参数必须写在最后,后面紧跟压缩文件名
- tar命令仅打包,习惯用.tar作为后缀
- tar命令加上z参数,文件以.tar.gz或.tgz表示
gzip命令
gzip通过压缩算法lempel-ziv 算法(lz77) 将文件压缩为较小文件,节省60%以上的存储空间,以及网络传输速率
gzip(选项)(参数)
-a或——ascii:使用ASCII文字模式;
-c或--stdout或--to-stdout 把解压后的文件输出到标准输出设备。
-d或--decompress或----uncompress:解开压缩文件;
-f或——force:强行压缩文件。不理会文件名称或硬连接是否存在以及该文件是否为符号连接;
-h或——help:在线帮助;
-l或——list:列出压缩文件的相关信息;
-L或——license:显示版本与版权信息;
-n或--no-name:压缩文件时,不保存原来的文件名称及时间戳记;
-N或——name:压缩文件时,保存原来的文件名称及时间戳记;
-q或——quiet:不显示警告信息;
-r或——recursive:递归处理,将指定目录下的所有文件及子目录一并处理;
-S或<压缩字尾字符串>或----suffix<压缩字尾字符串>:更改压缩字尾字符串;
-t或——test:测试压缩文件是否正确无误;
-v或——verbose:显示指令执行过程;
-V或——version:显示版本信息;
-<压缩效率>:压缩效率是一个介于1~9的数值,预设值为“6”,指定愈大的数值,压缩效率就会愈高;
--best:此参数的效果和指定“-9”参数相同;
--fast:此参数的效果和指定“-1”参数相同。
案例
#压缩目录中每一个html文件为.gz,文件夹无法压缩,必须先tar打包
gzip *.html #gzip压缩,解压都会删除源文件
zip命令
zip命令:是一个应用广泛的跨平台的压缩工具,压缩文件的后缀为zip文件,还可以压缩文件夹
语法:
zip 压缩文件名 要压缩的内容
-A 自动解压文件
-c 给压缩文件加注释
-d 删除文件
-F 修复损坏文件
-k 兼容 DOS
-m 压缩完毕后,删除源文件
-q 运行时不显示信息处理信息
-r 处理指定目录和指定目录下的使用子目录
-v 显示信息的处理信息
-x “文件列表” 压缩时排除文件列表中指定的文件
-y 保留符号链接
-b<目录> 指定压缩到的目录
-i<格式> 匹配格式进行压缩
-L 显示版权信息
-t<日期> 指定压缩文件的日期
-<压缩率> 指定压缩率
最后更新 2018-03-08 19:33:4
unzip命令
用于解压缩
参数
-l:显示压缩文件内所包含的文件;
-d<目录> 指定文件解压缩后所要存储的目录。
date命令
date命令用于显示当前系统时间,或者修改系统时间
语法
date 参数 时间格式
参数
-d, --date=STRING
显示由 STRING 指定的时间, 而不是当前时间
-s, --set=STRING
根据 STRING 设置时间
-u, --utc, --universal
显示或设置全球时间(格林威治时间)
时间格式
%%
文本的 %
%a
当前区域的星期几的简写 (Sun..Sat)
%A
当前区域的星期几的全称 (不同长度) (Sunday..Saturday)
%b
当前区域的月份的简写 (Jan..Dec)
%B
当前区域的月份的全称(变长) (January..December)
%c
当前区域的日期和时间 (Sat Nov 04 12:02:33 EST 1989)
%d
(月份中的)几号(用两位表示) (01..31)
%D
日期(按照 月/日期/年 格式显示) (mm/dd/yy)
%e
(月份中的)几号(去零表示) ( 1..31)
%h
同 %b
%H
小时(按 24 小时制显示,用两位表示) (00..23)
%I
小时(按 12 小时制显示,用两位表示) (01..12)
%j
(一年中的)第几天(用三位表示) (001..366)
%k
小时(按 24 小时制显示,去零显示) ( 0..23)
%l
小时(按 12 小时制显示,去零表示) ( 1..12)
%m
月份(用两位表示) (01..12)
%M
分钟数(用两位表示) (00..59)
%n
换行
%p
当前时间是上午 AM 还是下午 PM
%r
时间,按 12 小时制显示 (hh:mm:ss [A/P]M)
%s
从 1970年1月1日0点0分0秒到现在历经的秒数 (GNU扩充)
%S
秒数(用两位表示)(00..60)
%t
水平方向的 tab 制表符
%T
时间,按 24 小时制显示(hh:mm:ss)
%U
(一年中的)第几个星期,以星期天作为一周的开始(用两位表示) (00..53)
%V
(一年中的)第几个星期,以星期一作为一周的开始(用两位表示) (01..52)
%w
用数字表示星期几 (0..6); 0 代表星期天
%W
(一年中的)第几个星期,以星期一作为一周的开始(用两位表示) (00..53)
%x
按照 (mm/dd/yy) 格式显示当前日期
%X
按照 (%H:%M:%S) 格式显示当前时间
%y
年的后两位数字 (00..99)
%Y
年(用 4 位表示) (1970...)
%z
按照 RFC-822 中指定的数字时区显示(如, -0500) (为非标准扩充)
%Z
时区(例如, EDT (美国东部时区)), 如果不能决定是哪个时区则为空
默认情况下,用 0 填充数据的空缺部分. GNU 的 date 命令能分辨在 `%'和数字指示之间的以下修改.
`-' (连接号) 不进行填充 `_' (下划线) 用空格进行填充
案例
显示当前系统部分时间
1.显示短年份
date +%y
2.显示长年份
date +%Y
3.显示月份
date +%m
4.显示几号
date +%d
5.显示几时
date +%H
6.显示几分
date +%M
7.显示整秒
date +%S
8.显示时间如,年-月-日
date +%F
9.显示时间如,时:分:秒
date +%T
shred命令
用法:shred [选项]... 文件...
多次覆盖文件,使得即使是昂贵的硬件探测仪器也难以将数据复原。
-u, --remove 覆盖后截断并删除文件
shred heihei.txt 随机覆盖文件内容,不删除源文件
useradd命令
useradd命令用于Linux创建新的系统用户
useradd可以采用建立用户账号,账号建好之后,再用passwd设定账号密码,而可用usedel删除账号
使用useradd指令所建立的账号,实际上上是保存在/etc/passwd文本文件中
-c<备注>:加上备注文字。备注文字会保存在passwd的备注栏位中;
-d<登入目录>:指定用户登入时的启始目录;
-D:变更预设值;
-e<有效期限>:指定帐号的有效期限;
-f<缓冲天数>:指定在密码过期后多少天即关闭该帐号;
-g<群组>:指定用户所属的群组;
-G<群组>:指定用户所属的附加群组;
-m:自动建立用户的登入目录;
-M:不要自动建立用户的登入目录;
-n:取消建立以用户名称为名的群组;
-r:建立系统帐号;
-s<shell>:指定用户登入后所使用的shell;
-u<uid>:指定用户id。
案例
#创建用户禁止登陆,且不创建家目录
[root@luffycity ~]# useradd -M -s /sbin/nologin oldyu
创建用户流程
- 1.useradd chaoge
- 2.系统读取/etc/login.defs(用户定义文件),和/etc/default/useradd(用户默认配置文件)俩文件中定义的规则创建新用户
- 3.向/etc/passwd和/etc/group文件中添加用户和组信息,向/etc/shadow和/etc/gshadow中添加密码信息
- 4.根据/etc/default/useradd文件中配置的信息创建用户家目录
- 5.把/etc/skel中所有的文件复制到新用户家目录中
[root@pylinux ~]# grep -v "^#" /etc/login.defs |grep -v "^$"
MAIL_DIR /var/spool/mail #用户的邮件存放位置
PASS_MAX_DAYS 99999 #密码最长使用天数
PASS_MIN_DAYS 0 #更换密码最短时间
PASS_MIN_LEN 8 #密码最小长度
PASS_WARN_AGE 7 #密码失效前几天开始报警
UID_MIN 1000 #UID开始位置
UID_MAX 60000 #UID结束位置
SYS_UID_MIN 201
SYS_UID_MAX 999
GID_MIN 1000
GID_MAX 60000
SYS_GID_MIN 201
SYS_GID_MAX 999
CREATE_HOME yes #是否创建家目录
UMASK 077 #家目录的umask值
USERGROUPS_ENAB yes
ENCRYPT_METHOD MD5 #密码加密算法
MD5_CRYPT_ENAB yes
usermode命令
usermod命令用于修改系统已存在的用户信息,只能修改使用的中的用户
语法
usermod(选项)(参数)
选项
-c<备注>:修改用户帐号的备注文字;
-d<登入目录>:修改用户登入时的目录;
-e<有效期限>:修改帐号的有效期限;
-f<缓冲天数>:修改在密码过期后多少天即关闭该帐号;
-g<群组>:修改用户所属的群组;
-G<群组>;修改用户所属的附加群组;
-l<帐号名称>:修改用户帐号名称;
-L:锁定用户密码,使密码无效;
-s<shell>:修改用户登入后所使用的shell;
-u<uid>:修改用户ID;
-U:解除密码锁定。
userdel命令
删除用户相关文件
- 建议注释/etc/passwd用户信息而非直接删除用户
语法
userdel(选项)(参数)
选项
-f:强制删除用户,即使用户当前已登录;
-r:删除用户的同时,删除与用户相关的所有文件。
groupadd命令
groupadd命令用户创建一个新的工作组,新的工作组的信息将被添加到系统文件中。
语法
groupadd - 建立新群组
groupadd [ -ggid [ -o ]] [ -r ] [ -f ] group [[ ]]
选项
-g:指定新建工作组的id;
-r:创建系统工作组,系统工作组的组ID小于500;
-K:覆盖配置文件“/ect/login.defs”;
-o:允许添加组ID号不唯一的工作组。
groupdel命令
删除用户组
groupdel 组名
passwd命令
passwd命令修改用户密码和过期时间等,root可以改普通用户,反之不可以
语法
passwd(选项)(参数)
选项
-d:删除密码,仅有系统管理者才能使用;
-f:强制执行;
-k:设置只有在密码过期失效后,方能更新;
-l:锁住密码;
-s:列出密码的相关信息,仅有系统管理者才能使用;
-u:解开已上锁的帐号。
-i:密码过期多少天后禁用账户
-x:设置x天后可以修改密码
-n:设置n天内不得改密码
-e:密码立即过期,强制用户修改密码
-w:用户在密码过期前收到警告信息的天数
passwd实际场景
7天内用户不得改密码,60天后可以修改,过期前10天通知用户,过期30天后禁止用户登录
[root@luffycity ~]# passwd -n 7 -x 60 -w 10 -i 30 luffychao
Adjusting aging data for user luffychao.
passwd: Success
[root@luffycity ~]# passwd -S luffychao
luffychao PS 2019-10-17 7 60 10 30 (Password set, SHA512 crypt.)
id命令
id命令用于检查用户组以及对应的UID,GID等信息
[root@localhost ~]# id xhg
uid=1001(xhg) gid=1001(xhg) groups=1001(xhg)
whoami、who、w、last、lastlog
whoami显示可用于查看当前登录的用户,我是谁
w命令显示当前以登录的用户
[root@pylinux ~]# w
04:15:01 up 15 days, 18:03, 1 user, load average: 0.00, 0.01, 0.05
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root pts/0 122.71.x5.xx 04:05 5.00s 0.07s 0.00s w
1.显示当前系统时间、系统从启动到运行的时间、系统运行中的用户数量和平均负载(1、5、15分钟平均负载)
2.第二行信息
user:用户名
tty:用户使用的终端号
from:表示用户从哪来,远程主机的ip信息
login:用户登录的时间和日期
IDLE:显示终端空闲时间
JCPU:该终端所有进程以及子进程使用系统的总时间
PCPU:活动进程使用的系统时间
WHAT:用户执行的进程名称
who
[root@pylinux ~]# who
root pts/0 2018-07-12 04:05 (122.71.x5.xx)
名称 用户终端 用户登录的系统时间 从哪来的机器ip
last、lastlog命令查看用户详细的登录信息
#last命令显示已登录的用户列表和登录时间
[root@pylinux ~]# last
root pts/0 122.71.x5.xx Thu Jul 12 04:05 still logged in
root pts/0 122.71.x5.xx Thu Jul 12 04:02 - 04:05 (00:02)
root pts/1 122.71.x5.xx Wed Jul 11 16:56 - 16:57 (00:00)
wtmp begins Sun Jul 8 06:23:25 2018
lastlog命令显示当前机器所有用户最近的登录信息
[root@pylinux ~]# lastlog
用户名 端口 来自 最后登陆时间
root pts/0 122.71.65.73 四 7月 12 04:05:09 +0800 2018
bin **从未登录过**
yu pts/0 四 7月 12 04:05:51 +0800 2018
epmd **从未登录过**
rabbitmq 日 9月 29 03:42:01 +0800 2019
py pts/0 四 7月 12 04:06:02 +0800 2018
testyu **从未登录过**
su命令
su命令用于切换到指定用户
语法
su(选项)(参数)
选项
-c<指令>或--command=<指令>:执行完指定的指令后,即恢复原来的身份;
-f或——fast:适用于csh与tsch,使shell不用去读取启动文件;
-l或——login:改变身份时,也同时变更工作目录,以及HOME,SHELL,USER,logname。此外,也会变更PATH变量;
-m,-p或--preserve-environment:变更身份时,不要变更环境变量;
-s<shell>或--shell=<shell>:指定要执行的shell;
--help:显示帮助;
--version;显示版本信息。
visudo命令
visudo用于编辑/etc/sudoers文件,且提供语法检测,用于配置sudo命令
给xhg用户配置sudo使用权
sudo配置文件
| 用户或组 | 机器=(角色) | 允许执行命令 |
|---|---|---|
| User | machine= | Commands |
| oldboy | ALL=(ALL) | /usr/sbin/useradd、/usr/sbin/userdel |
配置sudo目的在于即能让运维方便干活(权限不足问题),又不威胁系统安全(权限把控)
sudo命令
sudo命令用来以其他身份来执行命令,预设的身份为root。在/etc/sudoers中设置了可执行sudo指令的用户。
普通用户不需要root密码即可用root权限执行命令。
语法
sudo(选项)(参数)
选项
-b:在后台执行指令;
-h:显示帮助;
-H:将HOME环境变量设为新身份的HOME环境变量;
-k:结束密码的有效期限,也就是下次再执行sudo时便需要输入密码;。
-l:列出目前用户可执行与无法执行的指令;
-p:改变询问密码的提示符号;
-s<shell>:执行指定的shell;
-u<用户>:以指定的用户作为新的身份。若不加上此参数,则预设以root作为新的身份;
-v:延长密码有效期限5分钟;
-V :显示版本信息。
- 配置了/etc/sudoers文件后,可以对用户命令提权,sudo 命令
- 想要切换root执行操作,可以sudo su - ,需要输入当前用户密码
chmod命令
chmod命令用来变更文件或目录的权限。
在UNIX系统家族里,文件或目录权限的控制分别以读取、写入、执行3种一般权限来区分,另有3种特殊权限可供运用。
用户可以使用chmod指令去变更文件与目录的权限,设置方式采用文字或数字代号皆可。
符号连接的权限无法变更,如果用户对符号连接修改权限,其改变会作用在被连接的原始文件。
权限范围:
操作对像
u 文件属主权限
g 同组用户权限
o 其它用户权限
a 所有用户(包括以上三种)
权限设定
+ 增加权限
- 取消权限
= 唯一设定权限
权限类别
r 读权限
w 写权限
x 执行权限
X 表示只有当该档案是个子目录或者该档案已经被设定过为可执行。
s 文件属主和组id
i 给文件加锁,使其它用户无法访问
r-->4
w-->2
x-->1
chown命令
修改文件属主、属组信息
语法:
chown alex test.txt #文件属于alex
chown :组 test.txt #修改文件属组
chown 用户:组 #修改
参数
-R, --recursive 递归处理所有的文件及子目录
-v, --verbose 为处理的所有文件显示诊断信息
chgrp命令
chgrp命令用来改变文件或目录所属的用户组。
该命令用来改变指定文件所属的用户组。
其中,组名可以是用户组的id,也可以是用户组的组名。
案例
-c或——changes:效果类似“-v”参数,但仅回报更改的部分;
-f或--quiet或——silent:不显示错误信息;
-h或--no-dereference:只对符号连接的文件作修改,而不是该其他任何相关文件;
-R或——recursive:递归处理,将指令目录下的所有文件及子目录一并处理;
-v或——verbose:显示指令执行过程;
--reference=<参考文件或目录>:把指定文件或目录的所属群组全部设成和参考文件或目录的所属群组相同;
chgrp -R alex /data #把/data目录下所有文件的属组改为alex
umask命令
umask 命令用来限制新文件权限的掩码。
也称之为遮罩码,防止文件、文件夹创建的时候,权限过大
当新文件被创建时,其最初的权限由文件创建掩码决定。
用户每次注册进入系统时,umask命令都被执行,并自动设置掩码改变默认值,新的权限将会把旧的覆盖。
- umask默认配置在/etc/profile 61-64行
umask值就是指“Linux文件的默认属性需要减掉的权限”。
比如Linux普通文件的最大默认属性是666,目录文件的最大属性是777。但是我们不想要用户在新建立文件时,文件的属性是666或777,那么我们就要设置umask值。
Linux系统预置的umask值是022,那么用户在新建立普通文件时,普通文件的属性就是666-022=644,新建立目录文件时,目录文件的属性就是777-022=755。
- 操作系统创建文件,默认最大权限是666(-rw-rw-rw-)
- 创建普通文件权限是
chatter命令
chattr命令用于更改文件的扩展属性,比chmod更改的rwx权限更底层
参数
a:只能向文件中添加数据,不得删除
-R:递归更改目录属性
-V:显示命令执行过程
模式
+ 增加参数
- 移除参数
= 更新为指定参数
A 不让系统修改文件最后访问时间
a 只能追加文件数据,不得删除
i 文件不能被删除、改名、修改内容
lsattr命令
lsattr命令用于查看文件的第二扩展文件系统属性,结合chattr一起用
-R
递归地列出目录以及其下内容的属性.
-V
显示程序版本.
-a
列出目录中的所有文件,包括以`.'开头的文件的属性.
-d
以列出其它文件的方式那样列出目录的属性, 而不列出其下的内容.
-v
显示文件版本.
history命令
history #命令 以及参数
-c: 清空内存中命令历史;
-r:从文件中恢复历史命令
数字 :显示最近n条命令 history 10
调用历史命令
!n #执行历史记录中的某n条命令
!! #执行上一次的命令,或者向上箭头
!string #执行名字以string开头的最近一次的命令
调用上一次命令的最后一个参数
ESC . #快捷键
!$
Linux常见通配符
| 符号 | 作用 |
|---|---|
| * | 匹配任意,0或多个字符,字符串 |
| ? | 匹配任意1个字符,有且只有一个字符 |
| 符号集合 | 匹配一堆字符或文本 |
| [abcd] | 匹配abcd中任意一个字符,abcd也可以是不连续任意字符 |
| [a-z] | 匹配a到z之间任意一个字符,要求连续字符,也可以连续数字,匹配[1-9] |
| [!abcd] | 不匹配括号中任意一个字符,也可以书写[!a-d],同于写法 |
[^abcd] | 同上,!可以换成 ^ |
特殊通配符
| 符号 | 作用 |
|---|---|
| [[:upper:]] | 所有大写字母 |
| [[:lower:]] | 所有小写字母 |
| [[:alpha:]] | 所有字母 |
| [[:digit:]] | 所有数字 |
| [[:alnum:]] | 所有的字母和数字 |
| [[:space:]] | 所有的空白字符 |
| [[:punct:]] | 所有标点符号 |
基本正则表达式符号
| 符号 | 作用 |
|---|---|
| ^ | 尖角号,用于模式的最左侧,如 “^oldboy”,匹配以oldboy单词开头的行 |
| $ | 美元符,用于模式的最右侧,如"oldboy$",表示以oldboy单词结尾的行 |
| ^$ | 组合符,表示空行 |
| . | 匹配任意一个且只有一个字符,不能匹配空行 |
| \ | 转义字符,让特殊含义的字符,现出原形,还原本意,例如\.代表小数点 |
| * | 匹配前一个字符(连续出现)0次或1次以上 ,重复0次代表空,即匹配所有内容 |
| .* | 组合符,匹配任意长度的任意字符 |
| ^.* | 组合符,匹配任意多个字符开头的内容 |
| .*$ | 组合符,匹配以任意多个字符结尾的内容 |
| [abc] | 匹配[]集合内的任意一个字符,a或b或c,可以写[a-c] |
[^abc] | 匹配除了后面的任意字符,a或b或c,表示对[abc]的取反 |
<pattern> | 匹配完整的内容 |
| <或> | 定位单词的左侧,和右侧,如<chao>可以找出"The chao ge",缺找不出"yuchao" |
扩展正则表达式符号
| 字符 | 作用 |
|---|---|
| + | 匹配前一个字符1次或多次,前面字符至少出现1次 |
| [😕]+ | 匹配括号内的":“或者”/"字符1次或多次 |
| ? | 匹配前一个字符0次或1次,前面字符可有可无 |
| 竖线 | 表示或者,同时过滤多个字符串 |
| () | 分组过滤,被括起来的内容表示一个整体 |
| a{n,m} | 匹配前一个字符最少n次,最多m次 |
| a{n,} | 匹配前一个字符最少n次 |
| a{n} | 匹配前一个字符正好n次 |
| a{,m} | 匹配前一个字符最多m次 |
grep命令
grep命令需要使用参数 -E即可支持正则表达式
egrep不推荐使用,使用grep -E替代
grep不加参数,得在特殊字符前面加"\"反斜杠,识别为正则
作用:文本搜索工具,根据用户指定的“模式(过滤条件)”对目标文本逐行进行匹配检查,打印匹配到的行
语法:
grep [options] [pattern] file
命令 参数 匹配模式 文件数据
-i:ignorecase,忽略字符的大小写;
-o:仅显示匹配到的字符串本身;
-v, --invert-match:显示不能被模式匹配到的行;
-E:支持使用扩展的正则表达式元字符;
-q, --quiet, --silent:静默模式,即不输出任何信息;
| 参数选项 | 解释说明 |
|---|---|
| -v | 排除匹配结果 |
| -n | 显示匹配行与行号 |
| -i | 不区分大小写 |
| -c | 只统计匹配的行数 |
| -E | 使用egrep命令 |
| –color=auto | 为grep过滤结果添加颜色 |
| -w | 只匹配过滤的单词 |
| -o | 只输出匹配的内容 |
sed命令
语法
sed [选项] [sed内置命令字符] [输入文件]
选项
| 参数选项 | 解释 |
|---|---|
| -n | 取消默认sed的输出,常与sed内置命令p一起用 |
| -i | 直接将修改结果写入文件,不用-i,sed修改的是内存数据 |
| -e | 多次编辑,不需要管道符了 |
| -r | 支持正则扩展 |
sed的内置命令字符用于对文件进行不同的操作功能,如对文件增删改查
sed常用内置命令字符:
| sed的内置命令字符 | 解释 |
|---|---|
| a | append,对文本追加,在指定行后面添加一行/多行文本 |
| d | Delete,删除匹配行 |
| i | insert,表示插入文本,在指定行前添加一行/多行文本 |
| p | Print ,打印匹配行的内容,通常p与-n一起用 |
| s/正则/替换内容/g | 匹配正则内容,然后替换内容(支持正则),结尾g代表全局匹配 |
sed匹配范围
| 范围 | 解释 |
|---|---|
| 空地址 | 全文处理 |
| 单地址 | 指定文件某一行 |
/pattern/ | 被模式匹配到的每一行 |
| 范围区间 | 10,20 十到二十行,10,+5第10行向下5行,/pattern1/,/pattern2/ |
| 步长 | 1~2,表示1、3、5、7、9行,2~2两个步长,表示2、4、6、8、10、偶数行 |
取出ip地址
[root@shell ~]# ifconfig ens33|sed -ne '2s/^.*inet//g' -e '2s/net.*$//p'
10.0.1.6
[root@shell ~]# ifconfig ens33|sed -n '2s/^.*inet//gp'|sed -n 's/net.*$//gp'
10.0.1.6 、
[root@shell ~]# ifconfig ens33|sed -r -n '2s/.*inet(.*)net.*/\1/p'
10.0.1.6
[root@shell ~]# ifconfig ens33|awk 'NR==2{print $2}'
10.0.1.6
awk命令
awk是一个强大的linux命令,有强大的文本格式化的能力,好比将一些文本数据格式化成专业的excel表的样式
awk更是是一门编程语言,支持条件判断、数组、循环等功能
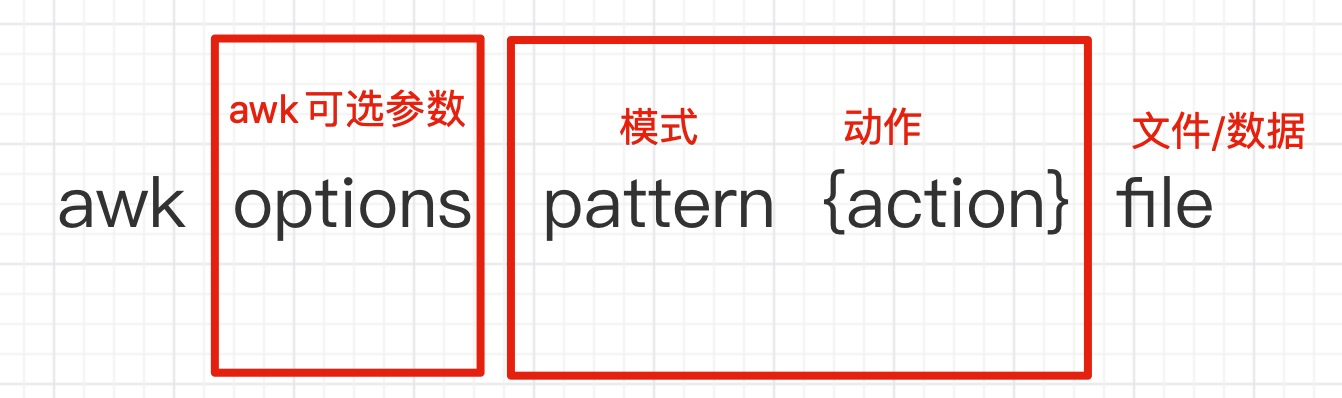
语法
awk [option] 'pattern[action]' file ...
awk 参数 '条件动作' 文件 动作 文件/数据
- Action指的是动作,awk擅长文本格式化,且输出格式化后的结果,因此最常用的动作就是
print和printf
awk内置变量
| 内置变量 | 解释 |
|---|---|
| $n | 指定分隔符后,当前记录的第n个字段 |
| $0 | 完整的输入记录 |
| FS | 字段分隔符,默认是空格 |
| NF(Number of fields) | 分割后,当前行一共有多少个字段 |
| NR(Number of records) | 当前记录数,行数 |
| 更多内置变量可以man手册查看 | man awk |
awk参数
| 参数 | 解释 |
|---|---|
| -F | 指定分割字段符 |
| -v | 定义或修改一个awk内部的变量 |
| -f | 从脚本文件中读取awk命令 |
| 内置变量 | 解释 |
|---|---|
| FS | 输入字段分隔符, 默认为空白字符 |
| OFS | 输出字段分隔符, 默认为空白字符 |
| RS | 输入记录分隔符(输入换行符), 指定输入时的换行符 |
| ORS | 输出记录分隔符(输出换行符),输出时用指定符号代替换行符 |
| NF | NF:number of Field,当前行的字段的个数(即当前行被分割成了几列),字段数量 |
| NR | NR:行号,当前处理的文本行的行号。 |
| FNR | FNR:各文件分别计数的行号 |
| FILENAME | FILENAME:当前文件名 |
| ARGC | ARGC:命令行参数的个数 |
| ARGV | ARGV:数组,保存的是命令行所给定的各参数 |
| 内置变量 | 解释 |
|---|---|
| FS | 输入字段分隔符, 默认为空白字符 |
| OFS | 输出字段分隔符, 默认为空白字符 |
| RS | 输入记录分隔符(输入换行符), 指定输入时的换行符 |
| ORS | 输出记录分隔符(输出换行符),输出时用指定符号代替换行符 |
| NF | NF:number of Field,当前行的字段的个数(即当前行被分割成了几列),字段数量 |
| NR | NR:行号,当前处理的文本行的行号。 |
| FNR | FNR:各文件分别计数的行号 |
| FILENAME | FILENAME:当前文件名 |
| ARGC | ARGC:命令行参数的个数 |
| ARGV | ARGV:数组,保存的是命令行所给定的各参数 |
crontab命令
crontab命令被用来提交和管理用户的需要周期性执行的任务
| 参数 | 解释 | 使用示例 |
|---|---|---|
| -l | list查看定时任务 | crontab -l |
| -e | edit编辑定时任务,建议手动编辑 | crontab -e |
| -i | 删除定时任务,提示用户确认删除,避免出错 | crontab -i |
| -r | 删除定时任务,移除/var/spool/cron/username文件,全没了 | crontab -r |
| -u user | 指定用户执行任务,root可以管理普通用户计划任务 | crontab -u chaoge -l |
fdisk命令
命令(输入 m 获取帮助):
n:创建新分区
d:删除已有分区
t:修改分区类型
l:查看所有已经ID
w:保存并退出
q:不保存并退出
m:查看帮助信息
p:显示现有分区信息
fdisk磁盘分区命令
-v 打印 fdisk 的版本信息并退出.
-l 列出指定设备的分区表信息并退出。
-u 以扇区数而不是以柱面数的形式显示分区表中各分区的信息.
-s 分区 将分区的 大小 (单位为块)信息输出到标准输出
ln命令
ln命令是单词link缩写,功能是创建文件之间的链接(make links between files),链接类型包括
- 硬链接 hard link
- 软链接 symbolic link
| 命令参数 | 解释 |
|---|---|
| ln无参数 | 创建硬链接 |
| -s | 创建软链接(符号链接) |
语法:
ln -s 源文件绝对路径 目标文件绝对路径
fsck命令
fsck命令被用于检查并且试图修复文件系统中的错误。当文件系统发生错误四化,可用fsck指令尝试加以修复
fsck命令
-a:自动修复文件系统,不询问任何问题;
-A:依照/etc/fstab配置文件的内容,检查文件内所列的全部文件系统;
-N:不执行指令,仅列出实际执行会进行的动作;
-P:当搭配"-A"参数使用时,则会同时检查所有的文件系统;
-r:采用互动模式,在执行修复时询问问题,让用户得以确认并决定处理方式;
-R:当搭配"-A"参数使用时,则会略过/目录的文件系统不予检查;
-s:依序执行检查作业,而非同时执行;
-t<文件系统类型>:指定要检查的文件系统类型;
-T:执行fsck指令时,不显示标题信息;
-V:显示指令执行过程。
mount命令
| 参数 | 解释 |
|---|---|
| -l | 显示系统以挂载的设备信息 |
| -a | 加载文件/etc/fstab中设置的所有设备 |
| -t | t<文件系统类型> 指定设备的文件系统类型。如果不设置,mount自行选择挂载的文件类型 minix Linux最早使用的文件系统。 ext2 Linux目前的常用文件系统。 msdos MS-DOS 的 FAT。 vfat Win85/98 的 VFAT。 nfs 网络文件系统。 iso9660 CD-ROM光盘的标准文件系统。 ntfs Windows NT的文件系统。 hpfs OS/2文件系统。Windows NT 3.51之前版本的文件系统。 auto 自动检测文件系统。 |
| -o | 添加挂载选项,是安全、性能优化重要参数 |
| -r | 只读,等于-o ro |
| -w | 读写,等-o rw |
| 参数 | 含义 |
|---|---|
| async | 以异步方式处理文件系统I/O操作,数据不会同步写入磁盘,而是写到缓冲区,提高系统性能,但损失数据安全性 |
| sync | 所有I/O操作同步处理,数据同步写入磁盘,性能较弱,数据安全性高 |
| atime/noatime | 文件被访问时是否修改时间戳,不更改时间,可以提高磁盘I/O速度 |
| auto/noauto | 通过-a参数可以自动被挂载/不自动挂载 |
| defaults | 默认值包括rw、suid、dev、exec、auto、nouser、async,/etc/fstab大多默认值 |
| exec/noexec | 是否允许执行二进制程序,取消提供安全性 |
| suid/nosuid | 是否允许suid(特殊权限)生效 |
| user/nouser | 是否允许普通用户挂载 |
| remount | 重新挂载 |
| ro | 只读 |
| rw | 读写 |
mdadm命令
参数
| 参数 | 解释 |
|---|---|
| -C | 用未使用的设备,创建raid |
| -a | yes or no,自动创建阵列设备 |
| -A | 激活磁盘阵列 |
| -n | 指定设备数量 |
| -l | 指定raid级别 |
| -v | 显示过程 |
| -S | 停止RAID阵列 |
| -D | 显示阵列详细信息 |
| -f | 移除设备 |
| -x | 指定阵列中备用盘的数量 |
| -s | 扫描配置文件或/proc/mdstat,得到阵列信息 |
rpm命令
rpm命令:rpm [OPTIONS] [PACKAGE_FILE]
# i表示安装 v显示详细过程 h以进度条显示,每个#表示2%进度
安装软件的命令格式 rpm -ivh filename.rpm
升级软件的命令格式 rpm -Uvh filename.rpm
卸载软件的命令格式 rpm -e filename.rpm
查询软件描述信息的命令格式 rpm -qpi filename.rpm
列出软件文件信息的命令格式 rpm -qpl filename.rpm
查询文件属于哪个 RPM 的命令格式 rpm -qf filename
netstat命令
netstat - 显示网络连接,路由表,接口状态,伪装连接,网络链路信息和组播成员组。
语法参数
Netstat 程序显示Linux网络子系统的信息。 输出信息的类型是由第一个参数控制的,就像这样: [[ ]]
(none)
无选项时, netstat 显示打开的套接字. 如果不指定任何地址族,那么打印出所有已配置地址族的有效套接字。 [[ ]]
--route , -r
显示内核路由表。 [[ ]]
--groups , -g
显示IPv4 和 IPv6的IGMP组播组成员关系信息。 [[ ]]
--interface=iface , -i
显示所有网络接口列表或者是指定的 iface 。 [[ ]]
--masquerade , -M
显示一份所有经伪装的会话列表。 [[ ]]
--statistics , -s
显示每种协议的统计信息。 [[ ]]
选项
--verbose , -v
详细模式运行。特别是打印一些关于未配置地址族的有用信息。 [[ ]]
--numeric , -n
显示数字形式地址而不是去解析主机、端口或用户名。 [[ ]]
--numeric-hosts
显示数字形式的主机但是不影响端口或用户名的解析。 [[ ]]
--numeric-ports
显示数字端口号,但是不影响主机或用户名的解析。 [[ ]]
--numeric-users
显示数字的用户ID,但是不影响主机和端口名的解析。 [[ ]]
--protocol=family , -A
指定要显示哪些连接的地址族(也许在底层协议中可以更好地描述)。 family 以逗号分隔的地址族列表,比如 inet , unix , ipx , ax25 , netrom , 和 ddp 。 这样和使用 --inet , --unix ( -x ), --ipx , --ax25 , --netrom, 和 --ddp 选项效果相同。 地址族 inet 包括raw, udp 和tcp 协议套接字。 [[ ]]
-c, --continuous
将使 netstat 不断地每秒输出所选的信息。 [[ ]]
-e, --extend
显示附加信息。使用这个选项两次来获得所有细节。 [[ ]]
-o, --timers
包含与网络定时器有关的信息。 [[ ]]
-p, --programs
显示套接字所属进程的PID和名称。 [[ ]]
-l, --listening
只显示正在侦听的套接字(这是默认的选项) [[ ]]
-a, --all
显示所有正在或不在侦听的套接字。加上 --interfaces 选项将显示没有标记的接口。 [[ ]]
-F
显示FIB中的路由信息。(这是默认的选项) [[ ]]
-C
显示路由缓冲中的路由信息。 [[ ]]
delay
netstat将循环输出统计信息,每隔 delay 秒。 [[ ]]
案例
常用组合参数
[root@mysql ~]# netstat -tunlp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1076/sshd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 1274/master
tcp6 0 0 :::3306 :::* LISTEN 2441/mysqld
tcp6 0 0 :::22 :::* LISTEN 1076/sshd
tcp6 0 0 ::1:25 :::* LISTEN 1274/master
# 参数解释
-l:显示所有Listen监听中的网络连接
-n:显示IP地址,不进行DNS解析成主机名、域名
-t:显示所有tcp连接
-u:显示所有udp连接
-p:显示进程号与进程名
显示当前系统的路由表
[root@mysql ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.0.1.2 0.0.0.0 UG 100 0 0 ens33
10.0.1.0 0.0.0.0 255.255.255.0 U 100 0 0 ens33
显示网络的接口情况
[root@mysql ~]# netstat -i
Kernel Interface table
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
ens33 1500 8173 0 0 0 4073 0 0 0 BMRU
lo 65536 0 0 0 0 0 0 0 0 LRU
# 参数解释
Iface:网络设备的接口名
MTU:最大传输单元,单位是字节
RX-OK/TX-OK:正确接收,发送了多少数据包
RX-ERR/TX-ERR:接收、发送数据包时丢弃了多少数据包
RX-OVR/TX-OVR:由于错误遗失了多少数据包
Flg:接口标记
L:是回环地址
B:设置了广播地址
M:接收所有数据包
R:接口正在运行
U:接口正处于活动状态
O:表示在该接口上禁止arp
P:表示一个点到点的连接
ss命令
ss命令是在centos7之后目的在于替代netstat的工具,用来查看网络状态信息,包括TCP、UDP、连接、端口等。优点在于能够显示更多详细的网络状态信息
如果系统没有ss命令,则需要安装下
yum install iproute -y
ss命令参数
-a 显示所有网络连接
-l 显示LISTEN状态的连接(连接打开)
-m 显示内存信息(用于tcp_diag)
-o 显示Tcp 定时器x
-p 显示进程信息
-s 连接统计
-n 显示ip地址,不进行dns解析
-d 只显示 DCCP信息 (等同于 -A dccp)
-u 只显示udp信息 (等同于 -A udp)
-w 只显示 RAW信息 (等同于 -A raw)
-t 只显示tcp信息 (等同于 -A tcp)
-x 只显示Unix通讯信息 (等同于 -A unix)
-4 只显示 IPV4信息
-6 只显示 IPV6信息
--help 显示帮助信息
--version 显示版本信息
ping命令
ping命令用于检测主机之间网络的连通性,执行ping命令使用ICMP传输协议,发出要求回应的信息。
参数
-c
count 在发送(和接收)了正好数量为 count 的回显应答分组后停止操作。在发送了 count 个分组后没有收到任何分组的特别情况是发送导致了终止(选程主机或网关不可达)。
-d
在所用的套接字上使用SO_DEBUG 选项。
-f
以高速方式来作ping 。以分组返回的速度来输出其它分组或每秒输出百次。当收到每个回显应答并打印一个退格符时,对每个回显请求都打印一个句点``.。这可以快速显示出丢弃了多少个分组,只有超级用户可以用这个选项。这(操作)对网络要求非常苛刻,应该慎重使用。
-i
wait 在发送每个分组时等待 wait 个秒数。缺省值为每个分组等待一秒。此选项与-f选项不能同时使用。
-l
preload 如果指定 preload ,那么 ping 程序在开始正常运行模式前尽可能快地发送分组。同样只有超级用户可以用这个选项。
-n
只以数字形式输出信息。这样就不尝试去查找主机名了。
-p
pattern 可以指定最多16个填充字节用于保持分组长度为16的整数倍。在网络上诊断与数据相关问题时此选项很有用。例如``-p ff将使发出的分组都用全1填充数据区。
-q
静态输出。在程序启动和结束时只显示摘要行。
-R
记录路由。在回显请求分组中包含记录路由选项并在相应的分组返回时显示路由缓冲区。注意IP首部的容量只能存放9条这样的路由。很多主机忽略或禁用此选项。
-r
在所连接的网络上旁路正常的选路表,直接向主机发送分组。如果主机未处于直接相连的网络上,那么返回一个错误。此选项可用来通过无路由接口对一台主机进行检测(例如当接口已被routed 程序丢弃后)。
-s
packetsize 指定要发送数据的字节量。缺省值为 56 ,这正好在添加了 8 字节的 ICMP 首部后组装成 64 字节的 ICMP 数据报。
详细模式输出。打印接收到的回显应答以外的ICMP分组。
-t
设置存活数值TTL的大小-v
-w
waitsecs 在 waitsecs 秒后停止 ping 程序的执行。当试图检测不可达主机时此选项很有用。
ping命令组合
[root@shell ~]# ping -c 3 -i 2 -s 1024 -t 255 10.0.1.6
PING 10.0.1.6 (10.0.1.6) 1024(1052) bytes of data.
1032 bytes from 10.0.1.6: icmp_seq=1 ttl=64 time=0.021 ms
1032 bytes from 10.0.1.6: icmp_seq=2 ttl=64 time=0.029 ms
1032 bytes from 10.0.1.6: icmp_seq=3 ttl=64 time=0.034 ms
--- 10.0.1.6 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 4000ms
rtt min/avg/max/mdev = 0.021/0.028/0.034/0.005 ms
#参数解释
-c 3 发送3次ICMP包
-i 3 每隔3秒发包
-s 1024 发送1024字节的数据包
-t 255 设置数据包存活值255
telnet命令
telnet命令以前用于登录远程主机然后进行管理,但是telnet采用明文传输报文,安全性很低,因此几乎以及弃用telnet,采用更安全的SSH服务了。
大多数网络设备,还是使用telnet登录,且telnet主要用于判断服务器是否打开了远程端口。
1.首先可能需要安装
yum install telnet -y
2.检测端口是否开放
[root@mysql ~]# telnet 10.0.1.6 80 # 命令 + ip + 端口
ssh命令
ssh命令是openssh套件中的客户端连接工具,可以使用ssh加密协议远程登录服务器,实现对服务器的远程管理,在windows中使用Xshell、SecureCRT等远程工具,Linux或是MacOS使用ssh命令连接。
参数
-p port
指定远程主机的端口. 可以在配置文件中对每个主机单独设定这个参数.
-t
强制分配伪终端. 可以在远程机器上执行任何全屏幕(screen-based)程序, 所以非常有用, 例如菜单服务。即使没有本地终端,多个-t选项也会强制分配终端
-v 调试模式,打印关于运行情况的调试信息. 在调试连接, 认证和配置问题时非常有用
wget命令
wget命令用来从指定的URL下载文件。wget非常稳定,它在带宽很窄的情况下和不稳定网络中有很强的适应性,如果是由于网络的原因下载失败,wget会不断的尝试,直到整个文件下载完毕。如果是服务器打断下载过程,它会再次联到服务器上从停止的地方继续下载。这对从那些限定了链接时间的服务器上下载大文件非常有用。
wget特点
- 支持断点下载
- 支持FTP和HTTP下载
- 支持代理服务器
用法: wget [选项]... [URL]...
长选项所必须的参数在使用短选项时也是必须的。
启动:
-V, --version 显示 Wget 的版本信息并退出。
-h, --help 打印此帮助。
-b, --background 启动后转入后台。
-e, --execute=COMMAND 运行一个“.wgetrc”风格的命令。
日志和输入文件:
-o, --output-file=FILE 将日志信息写入 FILE。
-a, --append-output=FILE 将信息添加至 FILE。
-d, --debug 打印大量调试信息。
-q, --quiet 安静模式 (无信息输出)。
-v, --verbose 详尽的输出 (此为默认值)。
-nv, --no-verbose 关闭详尽输出,但不进入安静模式。
-i, --input-file=FILE 下载本地或外部 FILE 中的 URLs。
-F, --force-html 把输入文件当成 HTML 文件。
-B, --base=URL 解析与 URL 相关的
HTML 输入文件 (由 -i -F 选项指定)。
--config=FILE Specify config file to use.
下载:
-t, --tries=NUMBER 设置重试次数为 NUMBER (0 代表无限制)。
--retry-connrefused 即使拒绝连接也是重试。
-O, --output-document=FILE 将文档写入 FILE。
-nc, --no-clobber skip downloads that would download to
existing files (overwriting them).
-c, --continue 断点续传下载文件。
--progress=TYPE 选择进度条类型。
-N, --timestamping 只获取比本地文件新的文件。
--no-use-server-timestamps 不用服务器上的时间戳来设置本地文件。
-S, --server-response 打印服务器响应。
--spider 不下载任何文件。
-T, --timeout=SECONDS 将所有超时设为 SECONDS 秒。
--dns-timeout=SECS 设置 DNS 查寻超时为 SECS 秒。
--connect-timeout=SECS 设置连接超时为 SECS 秒。
--read-timeout=SECS 设置读取超时为 SECS 秒。
-w, --wait=SECONDS 等待间隔为 SECONDS 秒。
--waitretry=SECONDS 在获取文件的重试期间等待 1..SECONDS 秒。
--random-wait 获取多个文件时,每次随机等待间隔
0.5*WAIT...1.5*WAIT 秒。
--no-proxy 禁止使用代理。
-Q, --quota=NUMBER 设置获取配额为 NUMBER 字节。
--bind-address=ADDRESS 绑定至本地主机上的 ADDRESS (主机名或是 IP)。
--limit-rate=RATE 限制下载速率为 RATE。
--no-dns-cache 关闭 DNS 查寻缓存。
--restrict-file-names=OS 限定文件名中的字符为 OS 允许的字符。
--ignore-case 匹配文件/目录时忽略大小写。
-4, --inet4-only 仅连接至 IPv4 地址。
-6, --inet6-only 仅连接至 IPv6 地址。
--prefer-family=FAMILY 首先连接至指定协议的地址
FAMILY 为 IPv6,IPv4 或是 none。
--user=USER 将 ftp 和 http 的用户名均设置为 USER。
--password=PASS 将 ftp 和 http 的密码均设置为 PASS。
--ask-password 提示输入密码。
--no-iri 关闭 IRI 支持。
--local-encoding=ENC IRI (国际化资源标识符) 使用 ENC 作为本地编码。
--remote-encoding=ENC 使用 ENC 作为默认远程编码。
--unlink remove file before clobber.
目录:
-nd, --no-directories 不创建目录。
-x, --force-directories 强制创建目录。
-nH, --no-host-directories 不要创建主目录。
--protocol-directories 在目录中使用协议名称。
-P, --directory-prefix=PREFIX 以 PREFIX/... 保存文件
--cut-dirs=NUMBER 忽略远程目录中 NUMBER 个目录层。
HTTP 选项:
--http-user=USER 设置 http 用户名为 USER。
--http-password=PASS 设置 http 密码为 PASS。
--no-cache 不在服务器上缓存数据。
--default-page=NAME 改变默认页
(默认页通常是“index.html”)。
-E, --adjust-extension 以合适的扩展名保存 HTML/CSS 文档。
--ignore-length 忽略头部的‘Content-Length’区域。
--header=STRING 在头部插入 STRING。
--max-redirect 每页所允许的最大重定向。
--proxy-user=USER 使用 USER 作为代理用户名。
--proxy-password=PASS 使用 PASS 作为代理密码。
--referer=URL 在 HTTP 请求头包含‘Referer: URL’。
--save-headers 将 HTTP 头保存至文件。
-U, --user-agent=AGENT 标识为 AGENT 而不是 Wget/VERSION。
--no-http-keep-alive 禁用 HTTP keep-alive (永久连接)。
--no-cookies 不使用 cookies。
--load-cookies=FILE 会话开始前从 FILE 中载入 cookies。
--save-cookies=FILE 会话结束后保存 cookies 至 FILE。
--keep-session-cookies 载入并保存会话 (非永久) cookies。
--post-data=STRING 使用 POST 方式;把 STRING 作为数据发送。
--post-file=FILE 使用 POST 方式;发送 FILE 内容。
--content-disposition 当选中本地文件名时
允许 Content-Disposition 头部 (尚在实验)。
--auth-no-challenge 发送不含服务器询问的首次等待
的基本 HTTP 验证信息。
HTTPS (SSL/TLS) 选项:
--secure-protocol=PR 选择安全协议,可以是 auto、SSLv2、
SSLv3 或是 TLSv1 中的一个。
--no-check-certificate 不要验证服务器的证书。
--certificate=FILE 客户端证书文件。
--certificate-type=TYPE 客户端证书类型,PEM 或 DER。
--private-key=FILE 私钥文件。
--private-key-type=TYPE 私钥文件类型,PEM 或 DER。
--ca-certificate=FILE 带有一组 CA 认证的文件。
--ca-directory=DIR 保存 CA 认证的哈希列表的目录。
--random-file=FILE 带有生成 SSL PRNG 的随机数据的文件。
--egd-file=FILE 用于命名带有随机数据的 EGD 套接字的文件。
FTP 选项:
--ftp-user=USER 设置 ftp 用户名为 USER。
--ftp-password=PASS 设置 ftp 密码为 PASS。
--no-remove-listing 不要删除‘.listing’文件。
--no-glob 不在 FTP 文件名中使用通配符展开。
--no-passive-ftp 禁用“passive”传输模式。
--retr-symlinks 递归目录时,获取链接的文件 (而非目录)。
递归下载:
-r, --recursive 指定递归下载。
-l, --level=NUMBER 最大递归深度 (inf 或 0 代表无限制,即全部下载)。
--delete-after 下载完成后删除本地文件。
-k, --convert-links 让下载得到的 HTML 或 CSS 中的链接指向本地文件。
-K, --backup-converted 在转换文件 X 前先将它备份为 X.orig。
-m, --mirror -N -r -l inf --no-remove-listing 的缩写形式。
-p, --page-requisites 下载所有用于显示 HTML 页面的图片之类的元素。
--strict-comments 用严格方式 (SGML) 处理 HTML 注释。
递归接受/拒绝:
-A, --accept=LIST 逗号分隔的可接受的扩展名列表。
-R, --reject=LIST 逗号分隔的要拒绝的扩展名列表。
-D, --domains=LIST 逗号分隔的可接受的域列表。
--exclude-domains=LIST 逗号分隔的要拒绝的域列表。
--follow-ftp 跟踪 HTML 文档中的 FTP 链接。
--follow-tags=LIST 逗号分隔的跟踪的 HTML 标识列表。
--ignore-tags=LIST 逗号分隔的忽略的 HTML 标识列表。
-H, --span-hosts 递归时转向外部主机。
-L, --relative 只跟踪有关系的链接。
-I, --include-directories=LIST 允许目录的列表。
--trust-server-names use the name specified by the redirection
url last component.
-X, --exclude-directories=LIST 排除目录的列表。
-np, --no-parent 不追溯至父目录。
案例
检测网站URL是否正常
[root@shell ~]# yum install telnet -y^C
[root@shell ~]# wget -q -T 3 --tries=1 --spider www.pythonav.cn
[root@shell ~]# echo $?
0
[root@shell ~]# wget -q -T 3 --tries=1 --spider www.pythonav.cn1
[root@shell ~]# echo $?
4
nslookup命令
nslookup 命令:用于查找域名服务器的程序,nslookup有两种模式:交互和非交互
此命令需要安装
[root@local-pyyu tmp]# yum install bind-utils -y
nmap命令
map是一款开放源码的网络探测工具,全称Network Mapper
目的在于快速扫描大型网络,nmap可以发现网络上有哪些主机,主机提供了什么服务,并且探测操作系统类型等信息。
需要安装此命令
yum install nmap -y
语法参数
Nmap命令的格式为:
Nmap [ 扫描类型 ... ] [ 通用选项 ] { 扫描目标说明 }
下面对Nmap命令的参数按分类进行说明:
1. 扫描类型
-sV 探测服务版本信息
-sT TCP connect()扫描,这是最基本的TCP扫描方式。这种扫描很容易被检测到,在目标主机的日志中会记录大批的连接请求以及错误信息。
-sS TCP同步扫描(TCP SYN),因为不必全部打开一个TCP连接,所以这项技术通常称为半开扫描(half-open)。这项技术最大的好处是,很少有系统能够把这记入系统日志。不过,你需要root权限来定制SYN数据包。
-sF,-sX,-sN 秘密FIN数据包扫描、圣诞树(Xmas Tree)、空(Null)扫描模式。这些扫描方式的理论依据是:关闭的端口需要对你的探测包回应RST包,而打开的端口必需忽略有问题的包(参考RFC 793第64页)。
-sP ping扫描,用ping方式检查网络上哪些主机正在运行。当主机阻塞ICMP echo请求包是ping扫描是无效的。nmap在任何情况下都会进行ping扫描,只有目标主机处于运行状态,才会进行后续的扫描。
-sU 如果你想知道在某台主机上提供哪些UDP(用户数据报协议,RFC768)服务,可以使用此选项。
-sA ACK扫描,这项高级的扫描方法通常可以用来穿过防火墙。
-sW 滑动窗口扫描,非常类似于ACK的扫描。
-sR RPC扫描,和其它不同的端口扫描方法结合使用。
-b FTP反弹攻击(bounce attack),连接到防火墙后面的一台FTP服务器做代理,接着进行端口扫描。
2. 通用选项
-P0 在扫描之前,不ping主机。
-PT 扫描之前,使用TCP ping确定哪些主机正在运行。
-PS 对于root用户,这个选项让nmap使用SYN包而不是ACK包来对目标主机进行扫描。
-PI 设置这个选项,让nmap使用真正的ping(ICMP echo请求)来扫描目标主机是否正在运行。
-PB 这是默认的ping扫描选项。它使用ACK(-PT)和ICMP(-PI)两种扫描类型并行扫描。如果防火墙能够过滤其中一种包,使用这种方法,你就能够穿过防火墙。
-O 这个选项激活对TCP/IP指纹特征(fingerprinting)的扫描,获得远程主机的标志,也就是操作系统类型。
-I 打开nmap的反向标志扫描功能。
-f 使用碎片IP数据包发送SYN、FIN、XMAS、NULL。包增加包过滤、入侵检测系统的难度,使其无法知道你的企图。
-v 冗余模式。强烈推荐使用这个选项,它会给出扫描过程中的详细信息。
-S <IP> 在一些情况下,nmap可能无法确定你的源地址(nmap会告诉你)。在这种情况使用这个选项给出你的IP地址。
-g port 设置扫描的源端口。一些天真的防火墙和包过滤器的规则集允许源端口为DNS(53)或者FTP-DATA(20)的包通过和实现连接。显然,如果攻击者把源端口修改为20或者53,就可以摧毁防火墙的防护。
-oN 把扫描结果重定向到一个可读的文件logfilename中。
-oS 扫描结果输出到标准输出。
--host_timeout 设置扫描一台主机的时间,以毫秒为单位。默认的情况下,没有超时限制。
--max_rtt_timeout 设置对每次探测的等待时间,以毫秒为单位。如果超过这个时间限制就重传或者超时。默认值是大约9000毫秒。
--min_rtt_timeout 设置nmap对每次探测至少等待你指定的时间,以毫秒为单位。
-M count 置进行TCP connect()扫描时,最多使用多少个套接字进行并行的扫描。
3. 扫描目标
目标地址 可以为IP地址,CIRD地址等。如192.168.1.2,222.247.54.5/24
-iL filename 从filename文件中读取扫描的目标。
-iR 让nmap自己随机挑选主机进行扫描。
-p 端口 这个选项让你选择要进行扫描的端口号的范围。如:-p 20-30,139,60000。
-exclude 排除指定主机。
-excludefile 排除指定文件中的主机。
ps命令
ps命令用于报告当前系统的进程状态。可以搭配kill指令随时中断、删除不必要的程序。ps命令是最基本同时也是非常强大的进程查看命令,使用该命令可以确定有哪些进程正在运行和运行的状态、进程是否结束、进程有没有僵死、哪些进程占用了过多的资源等等,总之大部分信息都是可以通过执行该命令得到的。
参数
-a 显示所有终端机下执行的进程,除了阶段作业领导者之外。
a 显示现行终端机下的所有进程,包括其他用户的进程。
-A 显示所有进程。
-c 显示CLS和PRI栏位。
c 列出进程时,显示每个进程真正的指令名称,而不包含路径,参数或常驻服务的标示。
-C<指令名称> 指定执行指令的名称,并列出该指令的进程的状况。
-d 显示所有进程,但不包括阶段作业领导者的进程。
-e 此参数的效果和指定"A"参数相同。
e 列出进程时,显示每个进程所使用的环境变量。
-f 显示UID,PPIP,C与STIME栏位。
f 用ASCII字符显示树状结构,表达进程间的相互关系。
-g<群组名称> 此参数的效果和指定"-G"参数相同,当亦能使用阶段作业领导者的名称来指定。
g 显示现行终端机下的所有进程,包括群组领导者的进程。
-G<群组识别码> 列出属于该群组的进程的状况,也可使用群组名称来指定。
h 不显示标题列。
-H 显示树状结构,表示进程间的相互关系。
-j或j 采用工作控制的格式显示进程状况。
-l或l 采用详细的格式来显示进程状况。
L 列出栏位的相关信息。
-m或m 显示所有的执行绪。
n 以数字来表示USER和WCHAN栏位。
-N 显示所有的进程,除了执行ps指令终端机下的进程之外。
-p<进程识别码> 指定进程识别码,并列出该进程的状况。
p<进程识别码> 此参数的效果和指定"-p"参数相同,只在列表格式方面稍有差异。
r 只列出现行终端机正在执行中的进程。
-s<阶段作业> 指定阶段作业的进程识别码,并列出隶属该阶段作业的进程的状况。
s 采用进程信号的格式显示进程状况。
S 列出进程时,包括已中断的子进程资料。
-t<终端机编号> 指定终端机编号,并列出属于该终端机的进程的状况。
t<终端机编号> 此参数的效果和指定"-t"参数相同,只在列表格式方面稍有差异。
-T 显示现行终端机下的所有进程。
-u<用户识别码> 此参数的效果和指定"-U"参数相同。
u 以用户为主的格式来显示进程状况。
-U<用户识别码> 列出属于该用户的进程的状况,也可使用用户名称来指定。
U<用户名称> 列出属于该用户的进程的状况。
v 采用虚拟内存的格式显示进程状况。
-V或V 显示版本信息。
-w或w 采用宽阔的格式来显示进程状况。
x 显示所有进程,不以终端机来区分。
X 采用旧式的Linux i386登陆格式显示进程状况。
-y 配合参数"-l"使用时,不显示F(flag)栏位,并以RSS栏位取代ADDR栏位
-<进程识别码> 此参数的效果和指定"p"参数相同。
--cols<每列字符数> 设置每列的最大字符数。
--columns<每列字符数> 此参数的效果和指定"--cols"参数相同。
--cumulative 此参数的效果和指定"S"参数相同。
--deselect 此参数的效果和指定"-N"参数相同。
--forest 此参数的效果和指定"f"参数相同。
--headers 重复显示标题列。
--help 在线帮助。
--info 显示排错信息。
--lines<显示列数> 设置显示画面的列数。
--no-headers 此参数的效果和指定"h"参数相同,只在列表格式方面稍有差异。
--group<群组名称> 此参数的效果和指定"-G"参数相同。
--Group<群组识别码> 此参数的效果和指定"-G"参数相同。
--pid<进程识别码> 此参数的效果和指定"-p"参数相同。
--rows<显示列数> 此参数的效果和指定"--lines"参数相同。
--sid<阶段作业> 此参数的效果和指定"-s"参数相同。
--tty<终端机编号> 此参数的效果和指定"-t"参数相同。
--user<用户名称> 此参数的效果和指定"-U"参数相同。
--User<用户识别码> 此参数的效果和指定"-U"参数相同。
--version 此参数的效果和指定"-V"参数相同。
--widty<每列字符数> 此参数的效果和指定"-cols"参数相同。
pstree命令
pstree指令用ASCII字符显示树状结构,清楚地表达程序间的相互关系。如果不指定程序识别码或用户名称,则会把系统启动时的第一个程序视为基层,并显示之后的所有程序。若指定用户名称,便会以隶属该用户的第一个程序当作基层,然后显示该用户的所有程序。 使用ps命令得到的数据精确,但数据庞大,这一点对掌握系统整体概况来说是不容易的。pstree命令正好可以弥补这个缺憾。它能将当前的执行程序以树状结构显示。pstree命令支持指定特定程序(PID)或使用者(USER)作为显示的起始。
-a 显示每个程序的完整指令,包含路径,参数或是常驻服务的标示。
-c 不使用精简标示法。
-G 使用VT100终端机的列绘图字符。
-h 列出树状图时,特别标明执行的程序。
-H<程序识别码> 此参数的效果和指定"-h"参数类似,但特别标明指定的程序。
-l 采用长列格式显示树状图。
-n 用程序识别码排序。预设是以程序名称来排序。
-p 显示程序识别码。
-u 显示用户名称。
-U 使用UTF-8列绘图字符。
-V 显示版本信息。
案例
显示进程是哪个用户执行的
pstree -u
pgrep命令
pgrep 是通过程序的名字来查询进程的工具,一般是用来判断程序是否正在运行。
-u 显示指定用户的所有进程号
kill命令
kill 命令:发送指定的信号到相应进程。不指定信号将发送SIGTERM(15)终止指定进程。
参数:
-l <信号编号>,若不加信号的编号参数,则使用“-l”参数会列出全部的信号名称
-a 当处理当前进程时,不限制命令名和进程号的对应关系
-p 指定kill 命令只打印相关进程的进程号,而不发送任何信号
-s 指定发送信号
-u 指定用户
killall命令
kill杀死进程需要获取进程的pid号,killall命令可以直接通过名字杀死
参数
killall 发送一条信号给所有运行任意指定命令的进程. 如果没有指定信号名, 则发送 SIGTERM.
信号可以以名字 (如 -HUP ) 或者数字 (如 -1 ) 的方式指定. 信号 0 (检查进程是否存在)只能以数字方式指定.
如果命令名包括斜杠 (/), 那么执行该特定文件的进程将被杀掉, 这与进程名无关.
如果对于所列命令无进程可杀, 那么 killall 会返回非零值. 如果对于每条命令至少杀死了一个进程, killall 返回 0.
killall 进程决不会杀死自己 (但是可以杀死其它 killall 进程). [[ ]]
OPTIONS (选项)
-e
对于很长的名字, 要求准确匹配. 如果一个命令名长于 15 个字符, 则可能不能用整个名字 (溢出了). 在这种情况下, killall 会杀死所有匹配名字前 15 个字符的所有进程. 有了 -e 选项,这样的记录将忽略. 如果同时指定了 -v 选项, killall 会针对每个忽略的记录打印一条消息.
-g
杀死属于该进程组的进程. kill 信号给每个组只发送一次, 即使同一进程组中包含多个进程.
-i
交互方式,在杀死进程之前征求确认信息.
-l
列出所有已知的信号名.
-q
如果没有进程杀死, 不会提出抱怨.
-v
报告信号是否成功发送.
-V
显示版本信息.
-w
等待所有杀的进程死去. killall 会每秒检查一次是否任何被杀的进程仍然存在, 仅当都死光后才返回. 注意: 如果信号被忽略或没有起作用, 或者进程停留在僵尸状态, killall 可能会永久等待.
pkill命令
pkill命令可以通过进程名终止指定的进程,对比killall杀死进程可能要执行多次,pkill可以杀死进程以及子进程
-f 显示完整程序
-l 显示源代码
-n 显示新程序
-o 显示旧程序
-v 与条件不符合的程序
-x 与条件符合的程序
-p<进程号> 列出父进程为用户指定进程的进程信息
-t<终端> 指定终端下的所有程序
-u<用户> 指定用户的程序
top命令
top命令用于实时的监控系统处理器状态,以及各种进程的资源占用情况。
还可以按照CPU的使用量、内存使用量进行排序显示,以及交互式的命令操作
参数
-b 批处理
-c 显示完整的治命令
-I 忽略失效过程
-s 保密模式
-S 累积模式
-d<时间> 设置间隔时间
-u<用户名> 指定用户名
-p<进程号> 指定进程
-n<次数> 循环显示的次数
交互式命令
在top执行过程中,输入一些指令,可以查看不同的结果
z:打开,关闭颜色
Z: 全局显示颜色修改
h:显示帮助画面,给出一些简短的命令总结说明;
k:终止一个进程;
i:忽略闲置和僵死进程,这是一个开关式命令;
q:退出程序;
r:重新安排一个进程的优先级别;
S:切换到累计模式;
s:改变两次刷新之间的延迟时间(单位为s),如果有小数,就换算成ms。输入0值则系统将不断刷新,默认值是5s;
f或者F:从当前显示中添加或者删除项目;
o或者O:改变显示项目的顺序;
l:切换显示平均负载和启动时间信息;
m:切换显示内存信息;
t:切换显示进程和CPU状态信息;
c:切换显示命令名称和完整命令行;
M:根据驻留内存大小进行排序;
P:根据CPU使用百分比大小进行排序;
T:根据时间/累计时间进行排序;
w:将当前设置写入~/.toprc文件中。
B:全局字体加粗
数字1:用于多核监控CPU,监控每个逻辑CPU的情况
b:打开,关闭加粗
x,高亮的形式排序对应的列
< > :移动选择排序的列
系统资源解释
前五行是系统整体的统计信息。第一行是任务队列信息,同 uptime 命令的执行结果。其内容如下:
01:06:48 当前时间
up 1:22 系统运行时间,格式为时:分
1 user 当前登录用户数
load average: 0.06, 0.60, 0.48 系统负载,即任务队列的平均长度。
三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值。
第二、三行为进程和CPU的信息。当有多个CPU时,这些内容可能会超过两行。内容如下:
Tasks: 29 total 进程总数
1 running 正在运行的进程数
28 sleeping 睡眠的进程数
0 stopped 停止的进程数
0 zombie 僵尸进程数
Cpu(s): 0.3% us 用户空间占用CPU百分比
1.0% sy 内核空间占用CPU百分比
0.0% ni 用户进程空间内改变过优先级的进程占用CPU百分比
98.7% id 空闲CPU百分比
0.0% wa 等待输入输出的CPU时间百分比
0.0% hi
0.0% si
最后两行为内存信息。内容如下:
Mem: 191272k total 物理内存总量
173656k used 使用的物理内存总量
17616k free 空闲内存总量
22052k buffers 用作内核缓存的内存量
Swap: 192772k total 交换区总量
0k used 使用的交换区总量
192772k free 空闲交换区总量
123988k cached 缓冲的交换区总量。
内存中的内容被换出到交换区,而后又被换入到内存,但使用过的交换区尚未被覆盖,
该数值即为这些内容已存在于内存中的交换区的大小。
相应的内存再次被换出时可不必再对交换区写入。
动态进程字段的解释
PID 进程id
PPID 父进程id
RUSER Real
UID 进程所有者的用户id
USER 进程所有者的用户名
GROUP 进程所有者的组名
TTY 启动进程的终端名。不是从终端启动的进程则显示为
PR 优先级
NI nice值。负值表示高优先级,正值表示低优先级
P 最后使用的CPU,仅在多CPU环境下有意义
%CPU 上次更新到现在的CPU时间占用百分比
TIME 进程使用的CPU时间总计,单位秒
TIME+ 进程使用的CPU时间总计,单位1/100秒
%MEM 进程使用的物理内存百分比
VIRT 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
SWAP 进程使用的虚拟内存中,被换出的大小,单位kb。
RES 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
CODE 可执行代码占用的物理内存大小,单位kb
DATA 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb
SHR 共享内存大小,单位kb
nFLT 页面错误次数
nDRT 最后一次写入到现在,被修改过的页面数。
S 进程状态。
- D=不可中断的睡眠状态
- R=运行
- S=睡眠
- T=跟踪/停止
- Z=僵尸进程
COMMAND 命令名/命令行
WCHAN 若该进程在睡眠,则显示睡眠中的系统函数名
Flags 任务标志,参考
nohup命令
nohup命令可以将程序已忽略挂起信号的方式运行起来,被运行程序的输出信息将不显示到终端。
无论是否将nohup命令的输出重定向到终端,输出都将写入到当前目录的nohup.out文件,如果当前目录的nohup.out文件不可写入,则输出到$HOME/nohup.out文件中
参数
用法:nohup 命令 [参数]...
或:nohup 选项
忽略挂起信号运行指定的命令。
--help 显示此帮助信息并退出
--version 显示版本信息并退出
如果标准输入是一个终端,重定向自/dev/null。
如果标准输出是一个终端,尽可能将输出添加到"nohup.out",
否则添加到"$HOME/nohup.out"。
如果标准错误输出是一个终端,重定向它到标准输出。
要保存输出内容到一个文件,使用 "nohup COMMAND > FILE" 形式的命令。
bg命令
bg命令用于将作业放到后台运行,使前台可以执行其他任务。
该命令的运行效果与在指令后面添加符号&的效果是相同的,都是将其放到系统后台执行。
如果一个程序要运行很久,但是你又得做其他的事,你就可以这么招
runlevel命令
读取系统的/var/run/utmp文件夹定位系统的运行级别记录,然后显示当前系统的执行等级
0 :停机
1 :单用户模式
2 :多用户模式,无网络
3 :完全的多用户模式
4 :用户自定义
5 :图形界面多用户模式
6 :重启
init命令
nit是Linux的进程初始化工具,是所有Linux进程的父进程,进程ID号是1。
init命令的主要任务是根据配置文件/etc/inittab创建Linux进程
# 0 - 停机(千万不能把initdefault 设置为0 )
# 1 - 单用户模式
# 2 - 多用户,没有 NFS
# 3 - 完全多用户模式(标准的运行级)
# 4 - 没有用到
# 5 - X11 (xwindow)
# 6 - 重新启动 (千万不要把initdefault 设置为6 )
因此
init 0 代表直接关机
init 6 代表重启
service命令
service命令用于对系统服务管理,centos7已经用systemctl替代
service命令用于对系统服务进行管理,比如启动(start)、停止(stop)、重启(restart)、重新加载配置(reload)、查看状态(status)等
# service mysqld #打印指定服务mysqld的命令行使用帮助。
# service mysqld start #启动mysqld
# service mysqld stop #停止mysqld
# service mysqld restart #重启mysqld
# service mysqld reload #重新加载my.cnf配置文件
# service nginx stop/start/restart/reload
htop命令
顾名思义,top就是比htop更好用的工具
#安装命令
[root@chaogelinux ~]# yum install htop -y
调整htop的风格
在htop监控页面中,添加主机名,以及时间
1. 进入htop
2. 按下setup,进入设置
3. 上下左右,移动,状态栏会发生变化(空格键,更改风格)
4. 按下回车键,可以选择添加表(meters)
5. F10保存
6. htop能够记忆用户的设置
搜索进程
按下F3
输入nginx 查找nginx的进程
杀死进程
定位到想要杀死进程的哪一行,按下F9
选择发送给进程的信号,一般是15,正常中断进程
回车,进程就挂了
显示进程树
按下F5
快捷键
M:按照内存使用百分比排序,对应MEM%列;
P:按照CPU使用百分比排序,对应CPU%列;
T:按照进程运行的时间排序,对应TIME+列;
K:隐藏内核线程;
H:隐藏用户线程;
#:快速定位光标到PID所指定的进程上。
/:搜索进程
glances命令
Glances 是一个由 Python 编写,使用 psutil 库来从系统抓取信息的基于 curses 开发的跨平台命令行系统监视工具。
glances 可以为 Unix 和 Linux 性能专家提供监视和分析性能数据的功能,其中包括:
- CPU 使用率
- 内存使用情况
- 内核统计信息和运行队列信息
- 磁盘 I/O 速度、传输和读/写比率
- 文件系统中的可用空间
- 磁盘适配器
- 网络 I/O 速度、传输和读/写比率
- 页面空间和页面速度
- 消耗资源最多的进程
- 计算机信息和系统资源
glances 工具可以在用户的终端上实时显示重要的系统信息,并动态地对其进行更新。这个高效的工具可以工作于任何终端屏幕。另外它并不会消耗大量的 CPU 资源,通常低于百分之二。glances 在屏幕上对数据进行显示,并且每隔两秒钟对其进行更新。您也可以自己将这个时间间隔更改为更长或更短的数值。glances 工具还可以将相同的数据捕获到一个文件,便于以后对报告进行分析和绘制图形。输出文件可以是电子表格的格式 (.csv) 或者 html 格式。
安装glances
通过python的包管理工具pip直接安装,类似于yum的作用
[root@chaogelinux ~]# pip3 install glances
# 方法二
通过linux的yum工具安装,需要配置epel源
yum install
glance界面**
glances 是一个命令行工具包括如下命令选项:
-b:显示网络连接速度 Byte/ 秒
-B @IP|host :绑定服务器端 IP 地址或者主机名称
-c @IP|host:连接 glances 服务器端
-C file:设置配置文件默认是 /etc/glances/glances.conf
-d:关闭磁盘 I/O 模块
-e:显示传感器温度
-f file:设置输出文件(格式是 HTML 或者 CSV)
-m:关闭挂载的磁盘模块
-n:关闭网络模块
-p PORT:设置运行端口默认是 61209
-P password:设置客户端 / 服务器密码
-s:设置 glances 运行模式为服务器
-t sec:设置屏幕刷新的时间间隔,单位为秒,默认值为 2 秒,数值许可范围:1~32767
-h : 显示帮助信息
-v : 显示版本信息
进程信息字段
VIRT: 虚拟内存大小
RES: 进程占用的物理内存值
%CPU:该进程占用的 CPU 使用率
%MEM:该进程占用的物理内存和总内存的百分比
PID: 进程 ID 号
USER: 进程所有者的用户名
TIME+: 该进程启动后占用的总的 CPU 时间
IO_R 和 IO_W: 进程的读写 I/O 速率
NAME: 进程名称
NI: 进程优先级
S: 进程状态,其中 S 表示休眠,R 表示正在运行,Z 表示僵死状态。
IOR/s 磁盘读取
IOW/s 磁盘写入
gances交互式命令
h : 显示帮助信息
q : 离开程序退出
c :按照 CPU 实时负载对系统进程进行排序
m :按照内存使用状况对系统进程排序
i:按照 I/O 使用状况对系统进程排序
p: 按照进程名称排序
d : 显示磁盘读写状况
w : 删除日志文件
l :显示日志
s: 显示传感器信息
f : 显示系统信息
1 :轮流显示每个 CPU 内核的使用情况(次选项仅仅使用在多核 CPU 系统)
glances运行web服务
1.安装python的包管理工具pip
yum install python python-pip python-devel gcc -y
2.安装web模块,bottle
pip install bottle
3.启动服务
[root@chaogelinux ~]# glances -w
Glances web server started on http://0.0.0.0:61208/
glances服务器/客户端模式
glances支持C/S模块,可以实现远程监控,而不用登陆另一台服务器
1.运行服务端
[root@chaogelinux ~]# glances -s -B 0.0.0.0
Glances server is running on 0.0.0.0:61209
2.客户端连接
glances -c 服务端ip
`bash
#安装命令
[root@chaogelinux ~]# yum install htop -y
###### 调整htop的风格
在htop监控页面中,添加主机名,以及时间
```bash
1. 进入htop
2. 按下setup,进入设置
3. 上下左右,移动,状态栏会发生变化(空格键,更改风格)
4. 按下回车键,可以选择添加表(meters)
5. F10保存
6. htop能够记忆用户的设置
搜索进程
按下F3
输入nginx 查找nginx的进程
杀死进程
定位到想要杀死进程的哪一行,按下F9
选择发送给进程的信号,一般是15,正常中断进程
回车,进程就挂了
显示进程树
按下F5
快捷键
M:按照内存使用百分比排序,对应MEM%列;
P:按照CPU使用百分比排序,对应CPU%列;
T:按照进程运行的时间排序,对应TIME+列;
K:隐藏内核线程;
H:隐藏用户线程;
#:快速定位光标到PID所指定的进程上。
/:搜索进程
glances命令
Glances 是一个由 Python 编写,使用 psutil 库来从系统抓取信息的基于 curses 开发的跨平台命令行系统监视工具。
glances 可以为 Unix 和 Linux 性能专家提供监视和分析性能数据的功能,其中包括:
- CPU 使用率
- 内存使用情况
- 内核统计信息和运行队列信息
- 磁盘 I/O 速度、传输和读/写比率
- 文件系统中的可用空间
- 磁盘适配器
- 网络 I/O 速度、传输和读/写比率
- 页面空间和页面速度
- 消耗资源最多的进程
- 计算机信息和系统资源
glances 工具可以在用户的终端上实时显示重要的系统信息,并动态地对其进行更新。这个高效的工具可以工作于任何终端屏幕。另外它并不会消耗大量的 CPU 资源,通常低于百分之二。glances 在屏幕上对数据进行显示,并且每隔两秒钟对其进行更新。您也可以自己将这个时间间隔更改为更长或更短的数值。glances 工具还可以将相同的数据捕获到一个文件,便于以后对报告进行分析和绘制图形。输出文件可以是电子表格的格式 (.csv) 或者 html 格式。
安装glances
通过python的包管理工具pip直接安装,类似于yum的作用
[root@chaogelinux ~]# pip3 install glances
# 方法二
通过linux的yum工具安装,需要配置epel源
yum install
glance界面**
glances 是一个命令行工具包括如下命令选项:
-b:显示网络连接速度 Byte/ 秒
-B @IP|host :绑定服务器端 IP 地址或者主机名称
-c @IP|host:连接 glances 服务器端
-C file:设置配置文件默认是 /etc/glances/glances.conf
-d:关闭磁盘 I/O 模块
-e:显示传感器温度
-f file:设置输出文件(格式是 HTML 或者 CSV)
-m:关闭挂载的磁盘模块
-n:关闭网络模块
-p PORT:设置运行端口默认是 61209
-P password:设置客户端 / 服务器密码
-s:设置 glances 运行模式为服务器
-t sec:设置屏幕刷新的时间间隔,单位为秒,默认值为 2 秒,数值许可范围:1~32767
-h : 显示帮助信息
-v : 显示版本信息
进程信息字段
VIRT: 虚拟内存大小
RES: 进程占用的物理内存值
%CPU:该进程占用的 CPU 使用率
%MEM:该进程占用的物理内存和总内存的百分比
PID: 进程 ID 号
USER: 进程所有者的用户名
TIME+: 该进程启动后占用的总的 CPU 时间
IO_R 和 IO_W: 进程的读写 I/O 速率
NAME: 进程名称
NI: 进程优先级
S: 进程状态,其中 S 表示休眠,R 表示正在运行,Z 表示僵死状态。
IOR/s 磁盘读取
IOW/s 磁盘写入
gances交互式命令
h : 显示帮助信息
q : 离开程序退出
c :按照 CPU 实时负载对系统进程进行排序
m :按照内存使用状况对系统进程排序
i:按照 I/O 使用状况对系统进程排序
p: 按照进程名称排序
d : 显示磁盘读写状况
w : 删除日志文件
l :显示日志
s: 显示传感器信息
f : 显示系统信息
1 :轮流显示每个 CPU 内核的使用情况(次选项仅仅使用在多核 CPU 系统)
glances运行web服务
1.安装python的包管理工具pip
yum install python python-pip python-devel gcc -y
2.安装web模块,bottle
pip install bottle
3.启动服务
[root@chaogelinux ~]# glances -w
Glances web server started on http://0.0.0.0:61208/
glances服务器/客户端模式
glances支持C/S模块,可以实现远程监控,而不用登陆另一台服务器
1.运行服务端
[root@chaogelinux ~]# glances -s -B 0.0.0.0
Glances server is running on 0.0.0.0:61209
2.客户端连接
glances -c 服务端ip















 1025
1025

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









