







MAP , MRR , NDCG
第一步,读取数据并处理
-
读取 qrels.txt中的数据,并对格式进行处理,转成字典形式存储在列表中
queryAns = [] with open("qrels.txt", "r") as f: file = f.readlines() for line in file: query_dict = {} line = line.strip("\n") line = line.split(" ") query_dict['queryId'] = line[0] query_dict['tweetId'] = line[2] query_dict['relevant'] = int(line[3]) queryAns.append(query_dict)处理结果格式如下
每一条数据以字典的形式存储三个字段: { q u e r y I d , t w e e t I d , r e l e v a n t } \{queryId , tweetId , relevant \} {queryId,tweetId,relevant}

MAP实现
-
先介绍一下 A P AP AP

-
我们只考虑返回文档中的相关文档 K 1 , K 2 , ⋯ ⋯ K R K_1 , K_2,\cdots \cdots K_R K1,K2,⋯⋯KR
-
P @ k P@k P@k 为前 k k k 个返回文档的 p r e c i s i o n precision precision , 计算方式为:在返回的所有文档中,$\frac{前k个文档中相关文档的个数}{k} \$
-
A P AP AP 为一个 query 返回的结果中,对于所有相关文档的 K 1 , K 2 , ⋯ ⋯ K R K_1 , K_2,\cdots \cdots K_R K1,K2,⋯⋯KR 的 P @ k P@k P@k 的平均值

-
-
M A P MAP MAP 就是对所有 query 的 A P AP AP 的平均值
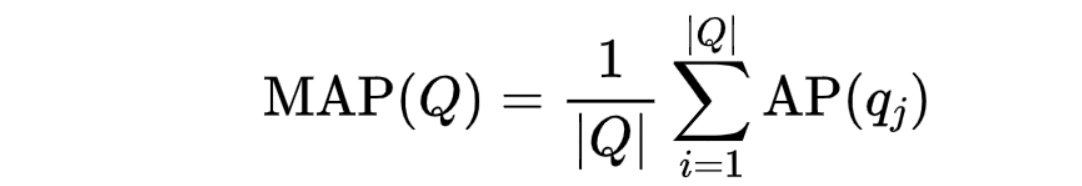
- Q代表的是query的个数 , q j q_j qj 代表第 j j j 个查询
-
例子
- 针对每个 query 计算
A
P
AP
AP

- 通过
A
P
AP
AP 计算
M
A
P
MAP
MAP

- 针对每个 query 计算
A
P
AP
AP
-
根据上述思路,很容易实现 M A P MAP MAP 的计算
- A P AP AP 用来存储每个 query 的 A P AP AP 值
- t o t a l N u m totalNum totalNum 用来存储当前位置之前的文档总数
- r e l N u m relNum relNum 用来存储当前位置之前的相关文档总数
- 以上三个值都是逐文档计算的,不断变化
def MAP(): AP = defaultdict(int) totalNum = defaultdict(int) relNum = defaultdict(int) for query in queryAns: query_id = query['queryId'] # 统计每个查询返回的结果个数 totalNum[query_id] += 1 # 统计每个查询返回的相关结果个数 if query['relevant'] == 0: relNum[query_id] += 0 else: relNum[query_id] += 1 # 计算AP if query['relevant'] != 0: AP[query_id] += relNum[query_id] * 1.0 / (totalNum[query_id] * 1.0) score_MAP = 0 num_query = 0 for key in AP: score_MAP += AP[key] / (relNum[key] * 1.0) num_query += 1 score_MAP /= (num_query * 1.0) print(score_MAP)
MRR实现
-
介绍 R R RR RR 和 M R R MRR MRR
- 令 K K K 是 query 返回的文档中第一个相关文档的位置
- $RR = \frac{1}{K} \$
-
M
R
R
MRR
MRR 是针对不同 query 的
R
R
RR
RR 的平均值

-
根据上述思想,很容易实现 M R R MRR MRR 的计算
- t o t a l N u m totalNum totalNum 用于存储当前位置之前的文档总数
def MRR(): totalNum = defaultdict(int) RR = {} for query in queryAns: query_id = query['queryId'] if query_id in RR: continue totalNum[query_id] += 1 if query['relevant'] != 0: RR[query_id] = 1 / (totalNum[query_id] * 1.0) num_query = 0 score_MRR = 0 for key in RR: score_MRR += RR[key] num_query += 1 score_MRR /= (num_query * 1.0) print(score_MRR)
NDCG实现
我们考虑累加式指标
-
C
G
n
CG_n
CGn 为当前文档之前的所有文档的相关性得分之和

优化累加式指标
-
我们应该注意到的是,返回文档顺序越往后,对用户来说这个文档发挥的作用就越小。用户会更多地关心前面的文档(比如使用浏览器搜索引擎时)
-
因此,我们应该将顺序靠后的文档的权重设小,且越靠后,权重越小。因此我们考虑 D C G DCG DCG ,如下所示

对于不同query可比较的累加式指标
对于不同的 query , 返回的文档集合是不同的,且不同文档的相关性也不同。上述指标 D C G DCG DCG 也不同,我们无法对于不同的 query 来用 D C G DCG DCG 对检索模型进行评价
因此我们在 D C G DCG DCG 上进行改进,将评价得分控制在 0 到 1 之间
-
理想情况下,返回结果中,相关性大的文档应该出现在前面。因此,我们将返回的文档按照相关性从大到小排序,像 D C G DCG DCG 一样进行计算,我们将其命名为 I D C G IDCG IDCG

-
提出的新指标为$NDCG = \frac{DCG}{IDCG} \$
-
该指标衡量了返回的结果和理想结果之间的差距,若得分越接近 1 , 证明返回的结果越接近理想情况,模型越好

-
根据上述原理, N D C G NDCG NDCG 实现代码如下
def NDCG(): query_list = defaultdict(list) #实际上是字典类型,每个value都是一个list score_NDCG = defaultdict(int) for query in queryAns: query_id = query['queryId'] query_list[query_id].append(query['relevant']) for query_id, normal_list in query_list.items(): sorted_list = sorted(normal_list, reverse=True) score_DCG = 0 score_IDCG = 0 for index in range(len(normal_list)): if index == 0: score_DCG = normal_list[index] score_IDCG = sorted_list[index] score_NDCG[query_id] = score_DCG * 1.0 / (score_IDCG * 1.0) else: score_DCG += normal_list[index] * 1.0 / math.log2(index + 1) score_IDCG += sorted_list[index] * 1.0 / math.log2(index + 1) score_NDCG[query_id] = score_DCG * 1.0 / (score_IDCG * 1.0)
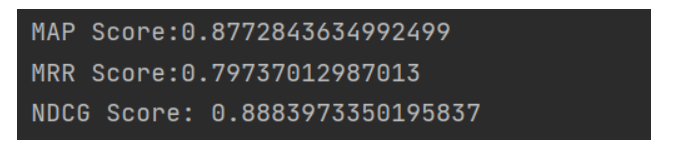
实验结果
- 处理完数据直接调用三个计算分数的函数
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











