







直方图
作用:一幅图像的直方图的形状提供了关于增强对比度的可能性的有用信息。
-
概念

-
样例

-
低对比度的图像:灰度值的level分布得较为集中

-
高对比度的图像:灰度值的level分布得比较分散

-
图像的直方图分布和图像的样子有什么关系呢?
- 显然,右下角的图像看起来最舒服。原因是什么呢?
- 原因:
- 该图像的灰度值占据了所有可能的灰度值
- 不同灰度值之间像素的个数分布得比较均匀

为了让图像看起来更好,我们提出直方图均匀化(从低对比度变化到高对比度)
-
-
如何实现:我们应该设计一个变换函数,使得变换后的图像能够占据所有的灰度值

直方图处理方法

HE(Histogram Equalization):直方图均衡化
-
思想:将 r k r_k rk 变换到 [ 0 , 1 ] [0,1] [0,1] 。 r k r_k rk 本来的分布是 [ 0 , 255 ] [0 , 255] [0,255]
-
方法:将 r k r_k rk 映射成 s k s_k sk。 s k s_k sk 为灰度值从 0 到 k 的像素个数和除以图像的像素总个数
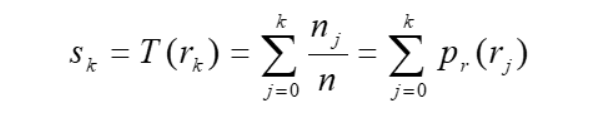
之后再将 s k s_k sk 的值乘以 255 得到最终的 r K r_K rK

-
这个方法是否得到的结果是否是均匀分布呢?
-
我们首先看一个连续的情况
-
p s ( s ) p_s(s) ps(s) 是 s s s 的概率密度函数 , p r ( r ) p_r(r) pr(r) 是位置 r r r 对应的函数值,也就是高度。

-
我们可以得到
$S = \int_{0}^{s}p_s(w)dw = \int_{0}^{r}p_r(w)dw $ , 即 ∫ 0 s p s ( w ) d w = ∫ 0 r p r ( w ) d w \int_{0}^{s}p_s(w)dw = \int_{0}^{r}p_r(w)dw ∫0sps(w)dw=∫0rpr(w)dw。对两边同时微分可得 p s ( s ) = p r ( r ) ∣ d r d s ∣ p_s(s) = p_r(r)|\frac{dr}{ds}| ps(s)=pr(r)∣dsdr∣
-
根据下面的推导,我们可以得到 s s s 的概率密度为 1 ,也就是说 s s s 在定义域内是均匀分布的

-
-
在离散的情况下,是否仍然是均匀分布呢?我们通过一个例子来说明

- 我们利用上述 HE 来进行变换,得到如下结果。可以看到,对离散值来说,变换后的分布是不均匀的

- 我们利用上述 HE 来进行变换,得到如下结果。可以看到,对离散值来说,变换后的分布是不均匀的
-
总结:使用本方法时(都是离散的像素值),将不会产生一个均匀的直方图,但会倾向于分散输入图像的直方图
-
优点:
- 增强对比度(有助于灰度值覆盖整个尺度)
- 全自动的

-
Histogram Matching:直方图匹配
满足对直方图增强的特殊要求(global)
- 直方图均衡化不允许交互式图像增强,并且只产生一个结果:一个近似于均匀直方图的结果
- 但有时,我们需要能够指定特定的直方图形状,以突出显示某些灰度范围。
方法:
-
将原始图像的灰度均衡化
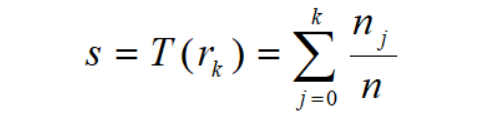
-
指定所需的密度函数并获得对应的变换函数 G ( z ) G(z) G(z)
-
最后得到, r k r_k rk 由 z z z 替代
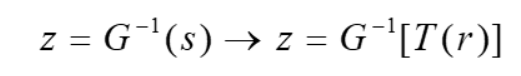
总结:本方法应用于图像增强的主要难点在于构建一个有意义的直方图。因此 -
要么指定一个特定的概率密度函数(比如高斯),然后通过这个函数来构造直方图
-
要么在图形设备上指定直方图的形状,然后将其输入进执行直方图规范算法的处理器中
例子
-
原始图像和直方图

-
变换函数和均衡化后的直方图(如何采用的是均衡化的方法,会发现图像很亮)

-
图像增强后的结果
- a是上面给的密度函数的处理结果
- b中曲线 (1) 是正函数 , 曲线 (2) 是反函数
- c是处理结果图
- d是c的直方图

Local Enhancement
Histogram的方法是全局的,本方法是针对局部的,根据每个像素附近的灰度分布来设计转换函数
Beyond Enhancement
- 直方图作为图像/区域描述符
- 图像检索
- 目标跟踪
- 直方图作为概率分布函数
- 分割/抠图
- 三种应用的例子如下



高斯与高斯混合模型
公式
- K K K 为数据维度
- μ \mu μ 是均值
-
∑
\sum
∑ 是协方差矩阵

用高斯拟合直方图

多峰分布

假设:任意形状的概率分布都可以用多个高斯分布函数去近似
高斯混合模型由 K K K 个不同的多元高斯分布共同组成,每一个分布被称为一个 component
尝试利用多个高斯分布函数的线性组合拟合x的分布,
ϕ
i
\phi_i
ϕi 是第
i
i
i 个多元高斯分布所占的权重

已知
K
K
K , 使用 soft k-means 聚类来进行参数估计,减小拟合误差

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











