







数据结构课程设计预习
实验预习目录
实验一:图书信息管理系统的设计与实现
1. 实验内容
设计并实现一个图书信息管理系统。根据实验要求设计该系统的菜单和交互逻辑,并编码实现增删改查的各项功能。 该系统至少包含以下功能:
(1) 根据指定图书个数,逐个输入图书信息;
(2) 逐个显示图书表中所有图书的相关信息;
(3) 能根据指定的待入库的新图书的位置和信息,将新图书插入到图书表中指定的位置;
(4) 根据指定的待出库的旧图书的位置,将该图书从图书表中删除;
(5) 能统计表中图书个数;
(6) 实现图书信息表的图书去重;
(7) 实现最爱书籍查询,根据书名进行折半查找,要求使用非递归算法实现,成功返回此书籍的书号和价格;
(8) 图书信息表按指定条件进行批量修改;
(9) 利用快速排序按照图书价格降序排序;
(10) 实现最贵图书的查找;
2. 数据结构
图书信息与顺序表的定义:
//图书信息的定义:
typedef struct {
char no[8]; //8位书号
char name[20]; //书名
int price; //价格
}Book;
//顺序表的定义
typedef struct {
Book *elem; //指向数据元素的基地址
int length; //线性表的当前长度
}SqList;
3. 代码设计
图书信息管理系统的实验我用的是顺序表的顺序存储结构,相较于链式存储结构,它的各种操作实现方式太单一,尤其在图书信息记录的插入和删除上比较费力。但它同时也有优势,就是它的代码可读性相较于链表要好,本次第一个实验较简单所以我用了顺序表。
·下面是我针对实验要求的代码设计:
//初始化
int InitList(SqList& L)
{
L.elem = new Book[MAXSIZE];
L.length = 0;
return OK;
}
//创建图书信息
void InitInformation(SqList& L)
{
cout << "请输入图书信息(书号 书名 价格)用空格隔开!" << endl;
for (int i = 0; i < MAXSIZE; i++)
{
cin >> L.elem[i].no >> L.elem[i].name >> L.elem[i].price;
if ((strcmp(L.elem[i].no, "0") == 0) && (strcmp(L.elem[i].name, "0") == 0) && (L.elem[i].price == 0))
break;
++L.length;
}
cout << "图书信息表创建成功!" << endl;
}
//输出图书信息表
void PrintBook(SqList& L)
{
int i = 0;
cout << "========图书列表如下========" << endl;
while (i < L.length)
{
printf("%s%c%s%c%.2f%c", L.elem[i].no, ' ', L.elem[i].name, ' ', L.elem[i].price, '\n');
++i;
}
}
//指定位置插入新图书
int InsertNewBook(SqList& L, int i)
{
Book b;
int j;
if ((i < 1) || (i > L.length) || L.length == MAXSIZE + 1)
{
cout << "抱歉,入库位置非法!" << endl;
return ERROR;
}
for (j = L.length - 1; j >= i - 1; j--)
L.elem[j + 1] = L.elem[j];
cout << "输入新入库的图书信息(依次输入书号、书名、价格):" << endl;
cin >> b.no >> b.name >> b.price;
L.elem[i - 1] = b;
++L.length;
cout << "插入成功!" << endl;
PrintBook(L);
return OK;
}
//删除表中指定位置的图书信息记录
int DeleteOldBook(SqList& L, int i)
{
if ((i < 1) || (i > L.length) || L.length == MAXSIZE + 1)
{
cout << "出库失败,未找到该图书!" << endl;
return ERROR;
}
for (int j = i - 1; j < L.length - 1; j++)
{
L.elem[j] = L.elem[j + 1];
}
--L.length;
cout << "删除成功!" << endl;
PrintBook(L);
return OK;
}
//统计表中图书数量
void BookNumber(SqList L)
{
cout << "现有图书数量为:" << L.length << endl;
}
//去重删除
void ExcludeSameDele(SqList& L, int i)
{
for (int j = i - 1; j < L.length - 1; j++)
{
L.elem[j] = L.elem[j + 1];
}
--L.length;
}
//图书去重
void ExcludeSame(SqList& L)
{//从第二本书开始遍历,分别与前几本书比较看是否重复
bool flag = false;//判断是否有重复,默认无重复
for (int i = 1; i < L.length; i++)
{
for (int j = 0; j < i; j++)
{//如果书号相同删除后面一个
if (strcmp(L.elem[i].no, L.elem[j].no) == 0)
{
ExcludeSameDele(L, i + 1);//删除重复书号的图书记录
i = 0;//删完之后有序表长缩减,所以i要重新置0再由i++置为1
flag = true;//更改标记
}
}
}
if (!flag)
cout << "图书没有重复,无需去重!" << endl;
else {
cout << "去重成功!" << endl;
BookNumber(L);//输出去重后有多少本书
PrintBook(L);//输出具体书籍信息
}
}
//查找最爱书籍
void FavoriteBook(SqList L)
{
char target[40];//存储待查的书名
int count = 0;//待查书目出现次数
cout << "请输入最爱的图书书名:";
cin >> target;
for (int i = 0; i < L.length; i++)
if (strcmp(L.elem[i].name, target) == 0)
count++;
cout << "找到了" << count << "本" << endl;
if (count)
{
for (int i = 0; i < L.length; i++)
if (strcmp(L.elem[i].name, target) == 0)
printf("%s%c%s%c%.2f%c", L.elem[i].no, ' ', L.elem[i].name, ' ', L.elem[i].price, '\n');
}
else cout << "抱歉,没有你的最爱!" << endl;
}
//图书均价
double average(SqList L)
{
double aver;//所有图书平均价格
double sum = 0;//所有图书总价
for (int i = 0; i < L.length; i++)
{
sum += L.elem[i].price;
}
aver = sum / L.length;
return aver;
}
//图书信息修改
void ModifyBook(SqList& L)
{
printf("%s%.2f%c", "修改前图书均价", average(L), '\n');
for (int i = 0; i < L.length; i++)
{
if (L.elem[i].price < average(L))
{//价格低于均价的提高20%
L.elem[i].price *= 1.2;
}
else
{//价格等于或高于均价的提高10%
L.elem[i].price *= 1.1;
}
}
printf("%s%.2f%c", "修改前图书均价", average(L), '\n');
PrintBook(L);
}
//将图书按价格降序排序
int Partition(SqList& L, int low, int high)
{
Book temp = L.elem[low]; //定义一个变量来存储low的值
while (low < high)
{
//如果high的值大于等于temp的值,high则减1;反之则将high的值赋值给low
while (low < high && L.elem[high].price <= temp.price) high--;
L.elem[low] = L.elem[high];
//如果low的值小于等于temp的值,low则加1;反之则将low的值赋值给high
while (low < high && L.elem[low].price >= temp.price) low++;
L.elem[high] = L.elem[low];
}
L.elem[low] = temp;//当high=low,跳出循环,并且将temp的值赋给low
return low;//返回low的位置
}
//快速排序(递归方法)
void QuickSort(SqList& L, int low, int high)
{
if (low < high) //跳出递归的条件
{
int pivotpos = Partition(L, low, high);
QuickSort(L, low, pivotpos - 1); //左边递归
QuickSort(L, pivotpos + 1, high); //右边递归
}
}
//查找最贵图书
void SearchExpensiveBook(SqList L)
{
double max = 0;//定义最大值并初始化为0
for (int i = 0; i < L.length; i++)
if (L.elem[i].price > max)
max = L.elem[i].price;
for (int i = 0; i < L.length; i++)
if (L.elem[i].price == max)
printf("%s%c%s%c%.2f%c", L.elem[i].no, ' ', L.elem[i].name, ' ', L.elem[i].price, '\n');
}
//UI功能界面
void OutputUI()
{
cout << "=========欢迎进入图书信息管理系统=========" << endl;
cout << "10.创建图书的信息表" << endl;
cout << "1.逐个显示图书信息表 2.插入新的图书信息" << endl;
cout << "3.删除指定的图书信息 4.显示图书数量" << endl;
cout << "5.对图书进行去重操作 6.查找最爱的图书" << endl;
cout << "7.对图书进行修改操作 8.将图书按价格降序排序" << endl;
cout << "9.查找最贵的图书操作 0.退出系统!" << endl;
}
实验二:隐式图的搜索问题
1. 实验内容
编写九宫重排问题的启发式搜索(A*算法)求解程序。
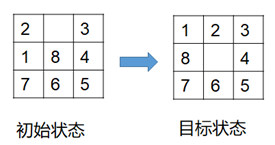
在3х3组成的九宫棋盘上,放置数码为1~8的8个棋子,棋盘中留有一个空格,空格周围的棋子可以移动到空格中,从而改变棋盘的布局。根据给定初始布局和目标布局,编程给出一个最优的走法序列。输出每个状态的棋盘。
测试数据:初始状态:123456780 目标状态:012345678
2. 实验提示
1)存储结构的定义
typedef struct node//八数码结构体
{
int nine[N][N];//数码状态
int f;//估价值
int direct;//空格移动方向
struct node *parent;//父节点
}pNode;
2)启发式搜索算法的描述:
(1)把初始节点S0 放入Open表中,f(S0)=g(S0)+h(S0);
(2)如果Open表为空,则问题无解,失败退出;
(3)把Open表的第一个节点取出放入Closed表,并记该节点为n;
(4)考察节点n是否为目标节点。若是,则找到了问题的解,成功退出;
(5)若节点n不可扩展,则转到第(2)步;
(6)扩展节点n,生成子节点ni(i=1,2,……),计算每一个子节点的估价值f(ni) (i=1,2,……),并为每一个子节点设置指向父节点的指针,然后将这些子节点放入Open表中;
(7)根据各节点的估价函数值,对Open表中的全部节点按从小到大的顺序重新进行排序;
(8)转到第(2)步。
启发式搜索算法的工作过程:

3. 输入输出要求
【输入格式】
输入包含三行,每行3各整数,分别为0-8这九个数字,以空格符号隔开,标识问题的初始状态。0表示空格,例如:
2 0 3
1 8 4
7 6 5
4. 代码设计
1)数据结构
const int N = 3; //数组边长大小
struct node { //状态类
int data[N][N]; //九宫数据
int G, H, F; //3个估价函数值
node* parent; //前继指针
//默认构造函数
node() :G(0), H(0), F(0), parent(NULL) {}
};
2)部分函数声明
class Astar {
public:
Astar(int startmaze[N][N], int endmaze[N][N]);//初始化Astatr
list<node*> GetPath();//获取全部路径
void Print();//显示最佳路径的每一步状态
private:
bool isok();//判断是否有解
node* findPath();//获取最佳路径
vector<node*> getSurroundPoints(node* Sudoku) const;//获取0周围的可以移动获得的状态表
bool isInList(list<node*>& list, node point);//判断开启列表中是否包含某点
bool isSame(node* p, node point);//判断两个9宫内数据是否相同
node* getLeastFpoint();//从开启列表中返回 F 值最小的状态指针
node* finallyload();//在开启列表中寻找结束状态并返回,否则返回空
node* upSudoku(node*, int, int) const;//返回给定状态0上移的状态指针
node* downSudoku(node*, int, int) const;//返回给定状态0下移的状态指针
node* leftSudoku(node*, int, int) const;//返回给定状态0左移的状态指针
node* rightSudoku(node*, int, int) const;//返回给定状态0右移的状态指针
//从初始状态到指定状态的移动代价(如果是初始节点,则其父节点是空)
int GetG(node* Sudoku) { return Sudoku->parent == NULL ? 1 : Sudoku->parent->G + 1; }
int GetH(node* Sudoku);//从指定状态到目标状态的估算成本
int GetF(node* Sudoku) { return GetH(Sudoku) + GetG(Sudoku); } //G,H之和
private:
node startSudoku; //初始九宫
node endSudoku; //目标九宫
list<node*> openList; //开启列表
list<node*> closeList;//关闭列表
list<node*> path; //最佳路径
3)实现想法
这个项目实现目标看上去很简单,但实际操作起来还是有很大难度的,我暂且还没有完全弄明白,所以算法的设计我用声明代替(参照网上资料的算法思维结构),具体设计过程和代码实现我还要回头研究!
更新:
A*算法伪代码:
把起始格添加到 "开启列表"
do {
寻找开启列表中 F 值最低的格子, 我们称它为当前格.
把它切换到关闭列表.
对当前格相邻的4格中的每一个
if (它不可通过 || 已经在 "关闭列表" 中) {
什么也不做.
}
if (它不在开启列表中) {
把它添加进 "开启列表", 把当前格作为这一格的父节点, 计算这一格的 FGH
}
if (它已经在开启列表中) {
if (以 G 为参考值检查新的路径是否更好, G 越小路径越好) {
把这一格的父节点改成当前格, 并且重新计算这一格的 GF 值.
}
}
} while( 目标格已经在 "开启列表", 这时候路径被找到)
如果开启列表已经空了, 说明路径不存在.
最后从目标格开始, 沿着每一格的父节点移动直到回到起始格, 这就是路径.
实验三:基于二叉排序树的低频词过滤系统
1. 实验内容
1)对于一篇给定的英文文章,利用线性表和二叉排序树来实现单词频率的统计,实现低频词的过滤,并比较两种方法的效率。具体要求如下:
2)读取英文文章文件(Infile.txt),识别其中的单词。
3)分别利用线性表和二叉排序树构建单词的存储结构。当识别出一个单词后,若线性表或者二叉排序树中没有该单词,则在适当的位置上添加该单词;若该单词已经被识别,则增加其出现的频率。
4)统计结束后,删除出现频率低于五次的单词,并显示该单词和其出现频率。
5)其余单词及其出现频率按照从高到低的次序输出到文件中(Outfile.txt),同时输出用两种方法完成该工作所用的时间。
6)计算查找表的ASL值,分析比较两种方法的效率。
2. 实验提示
1、在统计的过程中,分词时可以利用空格或者标点符号作为划分单词依据,文章中默认只包含英文单词和标点符号。
2、对单词进行排序时,是按照字母序进行的,每个结点还应包含该单词出现的频率。
3、存储结构的定义
二叉排序树的存储表示:
typedef struct BSTNode{
string WordName; //单词名称
int count; //单词出现频率
struct BSTNode *next;
} BSTNode, *BSTree;
4、实现过程可参见教材上线性表和二叉排序树的相关算法。
3. 显示界面(UI)
系统运行后主菜单如下:

当选择1后进入以下界面:

其中选择2时显示利用线性表来实现所有功能所用的时间。
当在主菜单选择2二叉排序树后,进入的界面与上图类同。
4.算法思想
从包含大量单词的文本中找到出现次数最少的单词。如果有多个单词都出现最少的次数,则将这些单词都比较下来用于后面输出。怎么判断一个完整的单词呢?我们可以依次遍历字符串遇到空格或非字母的字符时就跳出,一个单词就出来了,除此以外我们应该在遍历时将大小写统一防止误判,因为C++中大小写字母是完全不同的字符。分别用两种方法去实现遍历存放单词,一种是线性表,一种是二叉树。然后将两种方法的ASL值进行比较即可。
重要代码设计
存储单词及数量
//存储文件中的单词及数量
double RecognizeWord(ifstream& infile, vector<vector<char>>& WordList, vector<int>& WordNum) {
double ASL = 0; //平均查找次数
vector<char> word; //单词存储器
if (infile) {
char ch; //字母存储器
int i; //记录单词在单词表中的位置
while ((ch = infile.get()) != EOF) {
if (ch >= 65 && ch <= 90)ch += 32; //大写字母转换成小写
if (ch >= 97 && ch <= 122) //小写字母放在单词后面
word.push_back(ch);
else if (i = isRepeat(WordList, word)) { //判断单词表中是否存在新单词word
WordNum[i - 1]++; //新单词的频率加1
word.clear(); //清空单词存储器
ASL += i; //查找次数增加找到新单词的位置
}
else { //如果没找到
WordNum.push_back(1); //新单词的频率为1
WordList.push_back(word); //在单词表中加入新单词
word.clear(); //清空单词存储器
ASL += WordList.size(); //查找次数增加单词表的长度
}
}
}
5. 界面设计
1)根据运行要求的主函数设计
int main() {
int n; //记录用户的输入
bool flag = true; //控制程序退出
while (flag) {
system("cls");//清屏操作
//UI功能提示界面
cout << "1.线性表\n" << "2.二叉排序树\n" << "3.退出系统\n" << endl;
cout << "请选择你需要的服务,输入数字(1~3):" << endl;
cin >> n;
switch (n) {
case 1:Linear(); break;
case 2:BinarySortTree(); break;
case 3:flag = false; break;
default:cout << "选择错误,请重新输入:";
}
}
return 0;
}
2)选择线性表界面
这是伪代码,并不是具体代码!
void Linear() { //线性表的人机交互界面
ifstream infile; //输入流对象
infile.open("Infile.txt"); //打开要读取的文件
bool t = true; //控制程序退出
while (t) {
system("cls"); //防止页面过于繁杂,执行一次清屏
cout << "1.连续执行至完毕\n";
cout << "2.显示执行时间\n";
cout << "3.单步执行,识别并统计单词\n";
cout << "4.单步执行,删除并显示出现频率低单词\n";
cout << "5.单步执行,输出其余单词及其频率\n";
cout << "6.单步执行,计算并输出ASL值\n";
cout << "7.返回主菜单" << endl;
infile.close(); //关闭输入流对象
}
3)选择二叉排序树界面
这是伪代码,不是具体代码!
void BinarySortTree() { //排序二叉树的人机交互界面
ifstream infile; //输入流对象
infile.open("Infile.txt"); //打开要读取的文件
bool t = true; //控制程序退出
while (t) {
system("cls"); //执行清屏操作
cout << "1.连续执行至完毕\n";
cout << "2.显示执行时间\n";
cout << "3.单步执行,识别并统计单词\n";
cout << "4.单步执行,删除并显示出现频率低单词\n";
cout << "5.单步执行,输出其余单词及其频率\n";
cout << "6.单步执行,计算并输出ASL值\n";
cout << "7.返回主菜单" << endl;
infile.close(); //关闭输入流对象
}
实验源代码:
https://blog.csdn.net/qq_52942550/article/details/118190238?spm=1001.2014.3001.5501















 5048
5048











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









