







base64加解密c++实现
Base64编码原理
目前单字符最大为3Byte(特殊字符),汉字(2Byte)、字母(1Byte)…
而base64则是通过位运算加索引表将3个字符的内容编码为4个字符,也就是编码当前所有的单字符是完全够用的,base64能实现不可见字符和图片的传递,非常的便捷实用。
1、加密原理
将3个8bit的转换为4个6bit的数据,再通过索引表转换为4个可见字符,如下:

base64的正常索引表为:ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/
上述即明文为:"son"时 先将三个字符依次转化为 83 111 110
对应二进制则为 01010011 01101111 01101110
将则24位拼在一起之后4等分(6个一组):
010100 110110 111101 101110
之后转化为10进制,作为下标进行索引,如上图所示。
对一个长为len的明文,重复进行len//3次,如果len为三的倍数那么密文长度为(4/3)len,如果len的长度不为3的倍数,则需要额外的补充’\0’直到分组为3的倍数,补充几次‘/0’则在密文尾部添加几个‘=’,最终明文长度仍为4的倍数

2、c++实现加解密过程
加密函数主体:
核心为通过移位运算和&运算,将24bit划分为4组6bit接着转为10进制,进行索引,同时对明文不满足3的倍数进行填充。
string base64_encode(char*m,int len){ //转入的明文m 和 明文长度len
string cipher;
char tmp_3[3];//3个一组 临时存放
char enbase_4[4];//3->4
int i=0;
//了解base64的原理后直到是3->4所以通过一个循环来实现过程
while(len){
tmp_3[i]= *(m++);//将明文内容3个一组引入到tmp临时空间中去
i++;
if(i==3){ //如果得到3个字符,则进行位运算
enbase_4[0]=(tmp_3[0]&(0xfc))>>2; //0xfc == 0x11111100
enbase_4[1]=((tmp_3[0]&(0x03))<<4)+((tmp_3[1]&0xf0)>>4);
enbase_4[2]=((tmp_3[1]&0x0f)<<2)+((tmp_3[2]&0xc0)>>6);
enbase_4[3]=tmp_3[2]&0x3f;//通过位运算实现3个8bit一组 -> 4个6bit一组
for(int j=0;j<4;j++){
cipher+=base_table[enbase_4[j]]; //索引
}
i=0;
}
len--;
}
//上述循环将len//3 组数据转为base64 ,最优情况 i=0&&len==0;其余则是i=1 || i=2
if(i)
{
for(int j=i;j<3;j++)
tmp_3[j]='\0'; //补充到三位 每一个字节补'\0' 即 0b00000000
enbase_4[0]=(tmp_3[0]&(0xfc)) >>2;
enbase_4[1]=((tmp_3[0]&(0x03))<<4) + ((tmp_3[1]&0xf0)>>4);
enbase_4[2]=((tmp_3[1]&0x0f)<<2) + ((tmp_3[2]&0xc0)>>6);
// 三次即可,如果i=2的话 最多只有三组6为二进制的值不全为0,且最后一组的后两位一定为0
for(int j=0;j<i+1; j++) //注意为j<i+1 1个8bit 分为2个6bit
{
cipher+=base_table[enbase_4[j]];
}
while(i!=3){
cipher+='='; //缺几个字节 就补几个'='
i++;
}
}
return cipher;
}
解密函数主体:
解密则是加密的逆过程,实现4->3 ,并且是找出密文在base64表中的下标,将所有找出的下标8个一组转ASCII,得到最初的明文,特殊是对于尾部有‘=’的处理
string base64_decode(char*c,int len){
string m;
char tmp_4[4];
char debase_3[3];//实现4B->3B
int i=0;
int index=0; //表示当前在密文中的下标
while(len--&&c[index]!='='){ //读完密文或读到‘=’退出循环
tmp_4[i]=base_table.find(c[index])&0x3f; //通过find函数 找到下标对应的值
i++;index++;
if(i==4){
debase_3[0]=((tmp_4[0]&0x3f)<<2) + ((tmp_4[1]&0x30)>>4);
debase_3[1]=((tmp_4[1]&0xf)<<4) + ((tmp_4[2]&0x3c)>>2);
debase_3[2]=((tmp_4[2]&0x3)<<6) + (tmp_4[3]&0x3f);//注意位运算的优先级
for(int j =0;j<3;j++)
m+=(char)debase_3[j];
i=0;
}
}
if(i){ // 如果i不为0 则i表示 '=' 在4个字符中的下标
for(int j=i;j<4;j++)
tmp_4[j]='\0';//把所有等号的位置全补上0
debase_3[0]=((tmp_4[0]&0x3f)<<2) + ((tmp_4[1]&0x30)>>4);
debase_3[1]=((tmp_4[1]&0xf)<<4) + ((tmp_4[2]&0x3c)>>2); //最多转成两个字符
for(int j=0;j<i-1;j++) //j<i-1 比如 i=3时出现'=' 那么证明一个等号 故明文有两位
m+=debase_3[j];
}
return m;
}
IDA中算法分析
补全主函数后生成EXE文件,用IDA64对EXE文件进行静态分析。

用c++实现base64编码的时候用到了string库,分析看起来比较复杂,去了解了一下std::string库的常见使用。
std::string的使用总结
std::string s1;
std::string s3(s2);
std::string s2(“this is a string”);
begin 得到指向字符串开头的Iterator
end 得到指向字符串结尾的Iterator
rbegin 得到指向反向字符串开头的Iterator
rend 得到指向反向字符串结尾的Iterator
size 得到字符串的大小
length() 和size函数功能相同
max_size 字符串可能的最大大小
capacity 在不重新分配内存的情况下,字符串可能的大小
empty 判断是否为空
operator[] 取第几个元素,相当于数组
c_str 取得C风格的const char* 字符串
data 取得字符串内容地址
operator= 赋值操作符
reserve 预留空间
swap 交换函数
insert 插入字符
append 追加字符
push_back 追加字符
erase 删除字符串
clear 清空字符容器中所有内容
resize 重新分配空间
assign 和赋值操作符一样
replace 替代
copy 字符串到空间
find 查找,返回基于0的索引号
rfind 反向查找
find_first_of 查找包含子串中的任何字符,返回第一个位置
find_first_not_of 查找不包含子串中的任何字符,返回第一个位置
find_last_of 查找包含子串中的任何字符,返回最后一个位置
find_last_not_of 查找不包含子串中的任何字符,返回最后一个位置
substr(n1,len) 得到字符串从n1开始的长度为len的子串
比较字符串(支持所有的关系运算符)
compare 比较字符串
operator+ 字符串链接
operator+= += 操作符
operator== 判断是否相等
operator!= 判断是否不等于
operator< 判断是否小于
operator>> 从输入流中读入字符串
operator<< 字符串写入输出流
getline 从输入流中读入一
————————————————
版权声明:本文为CSDN博主「哀酱」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u010821666/article/details/77934510
通过一定的C++基础,std::string 大致能辨识,string本身是打包好的一个类,所以有着构造和析构函数这种赋值。
base64加密分析
程序流程是对输入进行了base64加密,之后和一个字符串解密,一般题目中只要识别出编码方式便能简单破解,为了深入学习base64编码原理,下面主要分析base64的加密算法。

第一部分,对明文字符串进行3个一组分组,每一组进行分割和base索引。
从上图也可以看出base64算法明显的特征:分组进行位运算实现3变4,另外就是base64索引表。
源代码将base64的表写成了static,存放在全局变量区,内部文件可见,外部文件不可见,所以要获得表需要进行动态调试,跟进v4便可得到表,不太清楚为什么base_table显示UNKNOW。
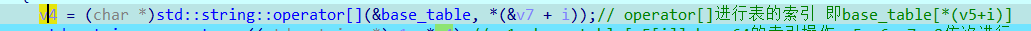

当然如果把static string base_table换成其他内容则变成了一道base64换表的题,并且需要动态调试找到索引表。
 接下来则是对明文不是3的倍数的处理:
接下来则是对明文不是3的倍数的处理:
即如果2个字符则补一个’='且密文经过换表的内容为2+1=3
二进制位 xxxxxx xxxxxx xxxx00 000000 也就是只要前3部分的索引值,剩余一位补‘=’。
同理如果1个字符则要补两个‘=’那么分割的二进制位 xxxxxx xx0000 000000 000000 也就是只有前两部分的值为特殊值,剩余两位补‘=’。
小插曲-base64隐写
通过上述补位也可以看出,补充的0有部分是参与base64表的索引的,则也为我们提供了一个思路,可不可以不用0来补,用其他相用的数据是否可能起到更好的效果,这就与MISC中的base64隐写有了一定的联系,即一个等号时,第三部分低二位的值用明文来填充,两个等号时第二部分的低4位用明文来填充。
即:
xxxxxx xxxxxx xxxxab 000000
xxxxxx xxabcd 000000 000000
a,b,c,d…代表某一二进制数据。可见base64隐写虽然可能对明文的最后一个字母有所影响,但是不影响解密内容,毕竟只是改写了填充部分。
附上解密代码:
import base64
a=("")
mode=("ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/") #base64 mode码表
c=("")
f = open("base64.txt","r") #读取文件
line = f.readline() #一行一行读取 下标指针自动向后移动
while line:
if("=" in line):
a=line.replace('=','')[-2:] #去掉‘=’留下最后一个字符 文件读取最后一位为‘/n'
print(a,end="") #这里用来检测是否出错了
num=(line.count('='))*2 #等号个数来决定截取二进制字符的个数 一个'='截取两个 二个'='截取4个
c=c+(bin(mode.index(a[0])).replace("0b",'')[-(num):].zfill(num)) #这里是关键,对其进行查表对号,再进行二进制转换筛选
line = f.readline() #.zfill()是在左边填0 补成num位
else:
line = f.readline() #没有等号就跳过
continue
f.close()
for i in range (0,len(c),8):
print(chr(int(c[i:i+8],2)),end='') #输出 8位二进制转为 10进制 之后转ascii码
根据脚本和上述解释,理解起来感觉更加轻松。
源码
最终附上自己写的源码,可能在健壮性和效率等有些方面不足或存在错误,还请各位师傅们指正。
#include<iostream>
#include<cstring>
using namespace std;
string base64_encode(char*m,int len);
string base64_decode(char*c,int len);
static string base_table="ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
int main(){
char m[100];
string ss;
cout<<"pleas tell me your secret:";
cin>>m;
ss=base64_encode(m,strlen(m));
string secret="ZmxhZ3tUaGlzX2lzX215X2Jhc2V9";
if(secret==ss)
cout<<"you get it"<<endl;
else
cout<<"try a again!"<<endl;
return 0;
}
string base64_encode(char*m,int len){
string cipher;
char tmp_3[3];//3个一组 临时存放
char enbase_4[4];//3->4
int i=0;
while(len){
//tmp_3[i] = m[i]; 错误的索引 i被改变了
tmp_3[i]= *(m++);
i++;
if(i==3){
enbase_4[0]=(tmp_3[0]&(0xfc))>>2; //0xfc == 0x11111100
enbase_4[1]=((tmp_3[0]&(0x03))<<4)+((tmp_3[1]&0xf0)>>4);
enbase_4[2]=((tmp_3[1]&0x0f)<<2)+((tmp_3[2]&0xc0)>>6);
enbase_4[3]=tmp_3[2]&0x3f;//通过位运算实现3个8bit一组 -> 4个6bit一组
for(int j=0;j<4;j++){
cipher+=base_table[enbase_4[j]]; //索引
}
i=0;
}
len--;
}
//上述循环将len//3 组数据转为base64 ,最优情况 i=0&&len==0;其余则是i=1 || i=2
if(i)
{
for(int j=i;j<3;j++)
tmp_3[j]='\0'; //补充到三位 每一个字节补'\0' 即 0b00000000
enbase_4[0]=(tmp_3[0]&(0xfc)) >>2;
enbase_4[1]=((tmp_3[0]&(0x03))<<4) + ((tmp_3[1]&0xf0)>>4);
enbase_4[2]=((tmp_3[1]&0x0f)<<2) + ((tmp_3[2]&0xc0)>>6);
// 三次即可,如果i=2的话 最多只有三组6为二进制的值不全为0,且最后一组的后两位一定为0
for(int j=0;j<i+1; j++) //注意为j<i+1 1个8bit 分为2个6bit
{
cipher+=base_table[enbase_4[j]];
}
while(i!=3){
cipher+='='; //缺几个字节 就补几个'='
i++;
}
}
return cipher;
}
string base64_decode(char*c,int len){
string m;
char tmp_4[4];
char debase_3[3];//实现4B->3B
int i=0;
int index=0; //表示当前在密文中的下标
while(len--&&c[index]!='='){
tmp_4[i]=base_table.find(c[index])&0x3f; //通过find函数 找到下标对应的值
i++;index++;
if(i==4){
debase_3[0]=((tmp_4[0]&0x3f)<<2) + ((tmp_4[1]&0x30)>>4);
debase_3[1]=((tmp_4[1]&0xf)<<4) + ((tmp_4[2]&0x3c)>>2);
debase_3[2]=((tmp_4[2]&0x3)<<6) + (tmp_4[3]&0x3f);//注意位运算的优先级
for(int j =0;j<3;j++)
m+=(char)debase_3[j];
i=0;
}
}
if(i){ // 如果i不为0 则表示 '=' 在4个字符中的下标
for(int j=i;j<4;j++)
tmp_4[j]='\0';
debase_3[0]=((tmp_4[0]&0x3f)<<2) + ((tmp_4[1]&0x30)>>4);
debase_3[1]=((tmp_4[1]&0xf)<<4) + ((tmp_4[2]&0x3c)>>2); //最多转成两个字符
for(int j=0;j<i-1;j++) //j<i-1 比如 i=3时出现'=' 那么证明一个等号 故明文有两位
m+=debase_3[j];
}
return m;
}
实战中的魔改例子
1、通过异或还原表
 具体步骤不在过多叙述,主要看到在循环体的索引后进行了一步异或,跟进查看表的内容。
具体步骤不在过多叙述,主要看到在循环体的索引后进行了一步异或,跟进查看表的内容。
 确实,异或使base64表面目全飞。
确实,异或使base64表面目全飞。
dump出,接着跟0x76异或一次,发现是原始的base64表,正常base64解密即可。
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/
2、通过移位产生表
附上实例:
 对每一个转换后的6bit数 + 61 也就是表的ASCII码范围是61 + i (i 从 0 到 63),直接python写个脚本生成表,通过索引还原,再解密即可。
对每一个转换后的6bit数 + 61 也就是表的ASCII码范围是61 + i (i 从 0 到 63),直接python写个脚本生成表,通过索引还原,再解密即可。
import base64
table=''
for i in range(64):
table+=chr(i+61)
c='@BdxRTbRBbjIVf`PEyqe^\^\|cc|JRubaGLytHeRI@jgNegHU[Myy]=='
base='ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
cc=''
for i in range(len(c)-2):
cc+=base[table.find(c[i])]
cc+='=='
cipher=base64.b64decode(cc)
参考链接:
base64加密原理c++.
std::string使用总结.
为什么要使用Base64?.















 1206
1206











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









