




 本文介绍了如何使用Python爬虫从网站上下载表情包。首先,通过requests库访问网页并解析HTML,再利用BeautifulSoup提取图片信息。接着,根据用户输入创建文件夹并下载图片,同时判断图片类型是jpg还是gif。最后,提供了完整代码实现表情包的批量下载。
本文介绍了如何使用Python爬虫从网站上下载表情包。首先,通过requests库访问网页并解析HTML,再利用BeautifulSoup提取图片信息。接着,根据用户输入创建文件夹并下载图片,同时判断图片类型是jpg还是gif。最后,提供了完整代码实现表情包的批量下载。
前言
随着网络的发达,大家在网上聊天时候经常发表情斗图,但是有的时候斗图斗不过就会让自己很难过,影响自己的心情。
本文介绍如何用python的简单爬虫爬取网站的图片。
目录
一、python爬虫是什么?
爬虫是基于Python编程而创造出来的一种网络资源的抓取方式,一般用于网络资源的获取。
二、使用步骤
1.引入库
我们这里需要用到几个库,requests(用于访问指定网址),urllib.parse(用于将输入的中文字符转化成URL编码格式),os(用于访问系统文件),bs4(用于爬取网页数据分析,这里我们用到的是其中的BeautifulSoup)
代码如下:
import requests, urllib.parse, os
from bs4 import BeautifulSoup2.添加文件夹
1.这里我们先访问电脑系统的D盘,看是否有名字为表情包的这个文件夹
代码如下:
path = 'D:\表情包'
isExists = os.path.exists(path)2.然后我们判断一下是否文件夹存在,如果存在我们就看一下是否在这个文件夹里面有我们输入的名字文件夹。
a = input('请输入你要查找的表情包名称: ')##输入你要查找的名称
path = 'D:\表情包'
path2 = path + '\\' + a
isExists = os.path.exists(path) ##判断是否存在这个文件夹,如果存在则返回True,如果不存在则返回False
if not isExists: ##如果不存在文件夹
os.mkdir(path) ##添加表情包文件夹
print(path + '创建成功')
os.mkdir(path2) ##在表情包文件夹中添加你搜索名称的文件夹
print(path2 + '创建成功')
else: ##如果存在
print(path + '已经存在')
isExists1 = os.path.exists(path2) ##判断表情包文件夹中是否存在你搜索的名称文件夹
if isExists1:
print(path2 + '已经存在')
else:
os.mkdir(path2) ##如果不存在,则添加这个文件夹
print(path2 + '创建成功')3.获取文件
1.我们先将我们输入的数据与网站组装成一个字符串并发送到网站,返回网页
url = 'https://www.fabiaoqing.com/search/bqb/keyword/' + urllib.parse.quote(a) + '/type/bq/page/' + str(page) + '.html' ##构成需要浏览的网页
res = requests.get(url) ##访问网页
res_txt = res.text ##将网页变成文本形式
print(res_txt)
比如说我输入一个“哈哈哈”可以看到其中返回的表情包图片地址和名称
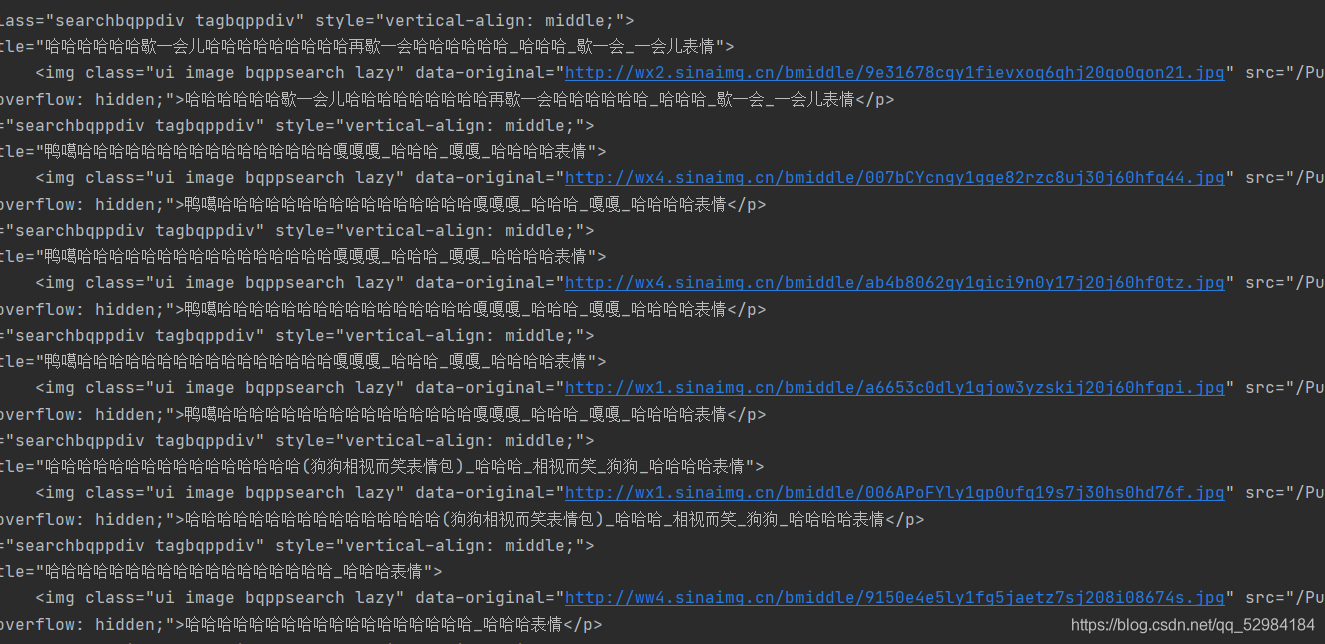

2.我们用BeautifulSoup分析返回的res_txt,可以得到我们想要的数据
bs = BeautifulSoup(res_txt, 'html.parser')
div = bs.find_all('img', class_='ui image bqppsearch lazy') ##查找同时满足'<img'和class='ui image bqppsearch lazy'的数据并返回到div中
print(div)输出结果:
![]()
哈哈哈,可以看到,输出数据变少了,集中在div中了
3.我们可以用for循环将div中的数据分别输出来
for i in div:
print(i)
输出结果:
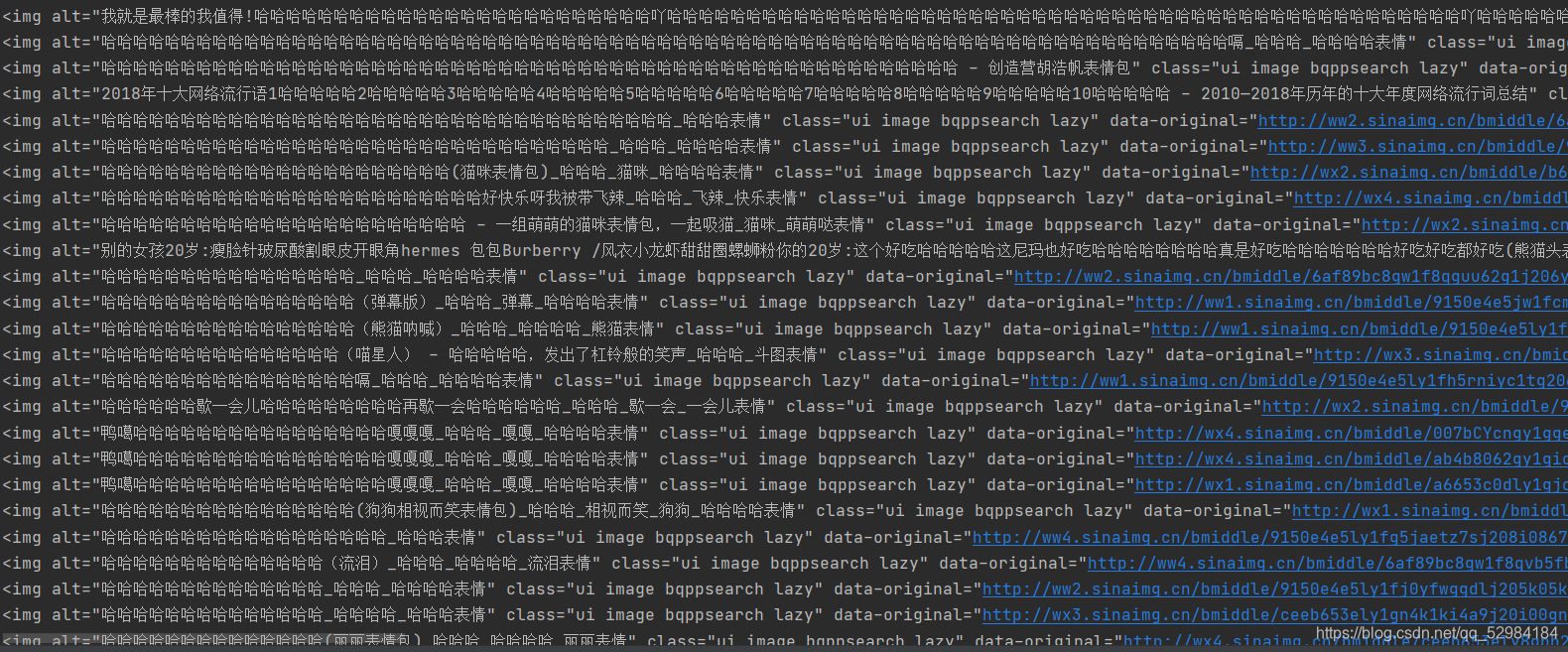
是不是发现想要的数据都出来了呢
4.我们继续用过滤,将每个数据我们想要的内容输出来
for i in div:
name = i.get('title')
src = i.get('data-original')
print(f'title:{name} src:{src}')只将名称和图片的地址输出来了

4.下载文件
1.访问上面找到的文件并下载
respose = requests.get(src)
with open(path2 + '\\%s.jpg' %name, 'wb')as file:
file.write(respose.content)
但是我发现不可以下载gif图了,失去了斗图的乐趣了
2.判断是gif还是jpg
if src[len(src) - 1] == 'g': ##判断网址最后一个字符是什么
with open(path2 + '\\%s.jpg' % name, 'wb')as file:
file.write(respose.content)
elif src[len(src) - 1] == 'f':
with open(path2 + '\\%s.gif' % name, 'wb')as file:
file.write(respose.content)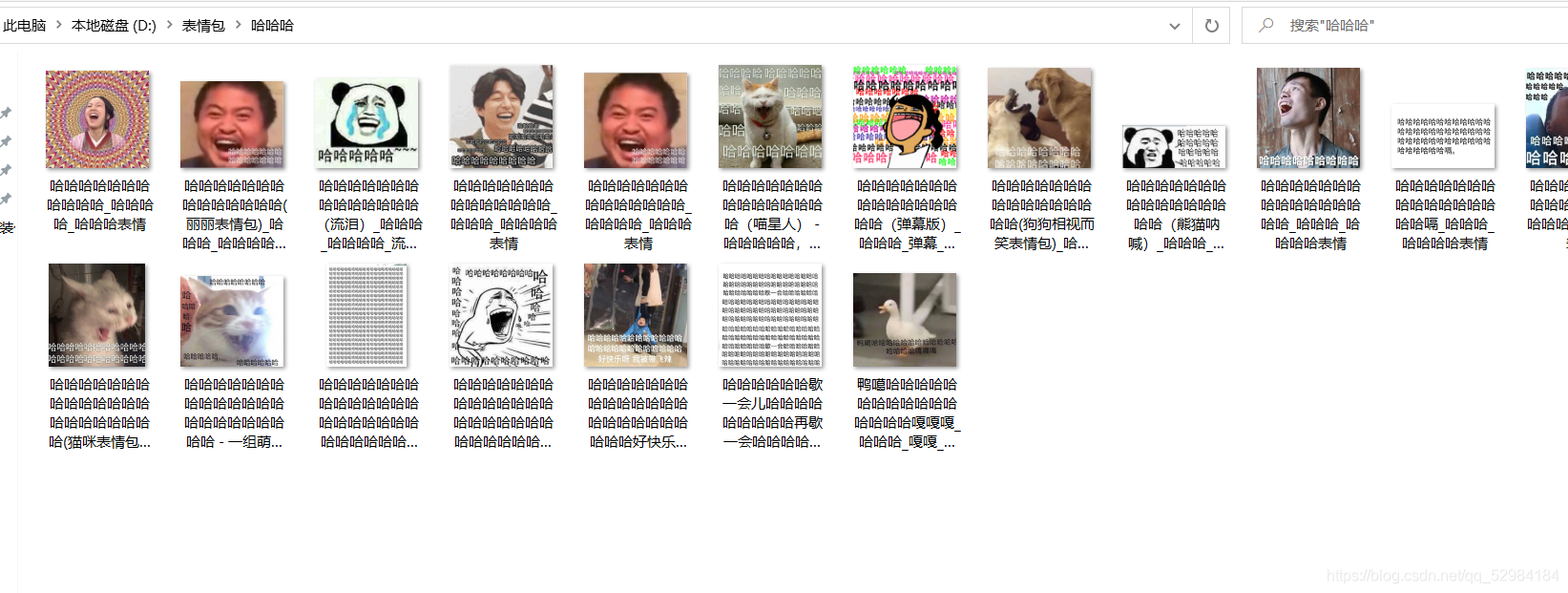
成功了!!!
完整代码
完整代码中我稍微加了一些代码,但是总体思路就是这样了
import requests, urllib.parse, os
from bs4 import BeautifulSoup
print('**********欢迎使用表情包下载工具**********\n')
print('*****输入0可退出*****\n')
a = 1
while a:
a = input('请输入你要查找的表情包名称: ')
if a == '0':
break
n = input('请输入你要下载的张数: ')
if n == '0':
break
num = 0
path = 'D:\表情包'
path1 = a
path2 = path + '\\' + a
isExists = os.path.exists(path)
if not isExists:
os.mkdir(path)
print(path + '创建成功')
os.mkdir(path2)
print(path2 + '创建成功')
else:
print(path + '已经存在')
isExists1 = os.path.exists(path2)
if isExists1:
print(path2 + '已经存在')
else:
os.mkdir(path2)
print(path2 + '创建成功')
class get():
def __init__(self, m, n):
self.m = m
self.num = n
def down(self):
respose = requests.get(self.src)
try:
if self.src[len(self.src) - 1] == 'g':
with open(path2 + '\\%s.jpg' % self.name, 'wb')as file:
file.write(respose.content)
self.num = self.num + 1
elif self.src[len(self.src) - 1] == 'f':
with open(path2 + '\\%s.gif' % self.name, 'wb')as file:
file.write(respose.content)
self.num = self.num + 1
except:
print('下载失败,输入个数太多了')
return 1
def src_get1(self):
bs = BeautifulSoup(self.m, 'html.parser')
div = bs.find_all('img', class_='ui image bqppsearch lazy')
for i in div:
self.name = i.get('title')
self.src = i.get('data-original')
if len(self.name) > 50:
continue
if os.path.exists(f'{path}\\{self.name}.jpg') or os.path.exists(f'{path}\\{self.name}.gif'):
continue
if self.num > eval(n):
break
else:
get.down(self)
print('开始下载......')
for page in range(1, int((int(n) / 45 + 1)) + 1):
url = 'https://www.fabiaoqing.com/search/bqb/keyword/' + urllib.parse.quote(a) + '/type/bq/page/' + str(page) + '.html'
res = requests.get(url)
res_txt = res.text
get_file = get(res_txt, num)
print('下载中......')
src_1 = get_file.src_get1()
num = num + 45
print(f'下载成功!!!\n文件保存在 {path2} 中。')
总结
本人第一次写文章,很多地方不懂,还请大家指出来,我好改正


















 5162
5162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











