






文章目录:
这是一篇论文笔记,本篇笔记会记录一些我认为关键的细节以及心得体会。论文地址:httphttps://arxiv.org/abs/1504.03641
论文的出发点是使用卷积神经网络去学习一个相似函数(similarity function),并探讨了多种网络结构。笔者侧重于去了解论文中提及的不同网络结构。
一、数据集简介(Dataset)
我们使用一个包含成对原始图像块的大型数据库(database)作为唯一输入。成对包括匹配的(matching)和未匹配的(non-matching)。使用彩色图像数据集(dataset)和灰色图像数据集都行,使用彩色数据集进行训练能取得更好的效果,但为了和其他方法对比,论文中使用灰色图片数据集进行训练。
本论文中图片块大小固定为64x64,除了使用SPP结构时输入图像大小无所谓外(SPP会在第三部分介绍)。
针对不同的实验,作者使用了不同的数据集,具体使用什么数据集会在实验部分介绍。
二、基本模型(Basic models)
我们是从成对的图像块中进行学习,并不是所有结构都可以从成对图像中学习的,下面先介绍三种可行的神经网络结构:2-channel,Siamese, Pseudo-siamese
2-channel
(下图左边)
直接将成对的图像叠起来,形成两通道的图像进行训练,所以称为两通道神经网络。其中的结构就是一个普通的卷积神经网络,最后再加一个决策层(decision layer),输出一个值。

Siamese
(上图右边)
在神经网络中有两个分支,每个分支有相同的结构而且共享权值(shared),这就是孪生神经网络。孪生神经网络的两个分支可以看成特征提取模块,决策层看做相似函数。
Pseudo-siamese
(上图右边)
和孪生神经网络不同的是:伪孪生神经网络的两个分支结构可以不同,不共享权重。所以,相对于孪生神经网络,伪孪生神经网络具有更高的灵活度(flexibility),但没2-channel灵活度高。
在测试时,由于孪生和伪孪生神经网络可以提前计算出所有的特征描述符,然后再进行相似度计算,所以测试效率(efficiency)更高。
三、其他模型(Additional models)
Deep network
在论文Very deep convolutional networks for large-scale image recognition中提出更深的神经网络会取得更好的结果。所以本论文作者也借鉴这种思想,运用到自己的模型中。具体由一个4x4卷积和6个3x3卷积组成,使用relu激活函数。这就可以替换掉第二部分基本模型中的卷积网络部分。
Central-surround two-stream network
该结构由两个stream组成(如下图),这里stream可以翻译成“流”,但有点奇怪,所以本文保留英文的表达。这里每个stream使用孪生神经网络的结构,当然也可以使用上面三个基本结构中的任何一个。
我们称右边stream为the central high-resolution stream,顾名思义,我们取每个patch(64x64)中间的32x32部分作为输入,没有降低分辨率。我们称左边的stream为the surround low-resolution stream,将每个patch降采样两倍作为输入,大小也为32x32。
使用该结构有几大优点。首先,可以获取多分辨率的信息。除此之外,我们考虑中间部分两次(包括高分辨率和低分辨率),将更多的注意力放在中间部分,周围部分有更少的注意力,这会取得更好的准确率(因为这样我们允许周围部分有更大的差异)。最后,由于输入patch大小减半,训练效率也会更高。
Spatial pyramid pooling (SPP)
前面也提到了,如果使用SPP结构就不需要固定输入patch大小。下面参考何恺明大神的论文Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
SPP将特征图划分为不同的bins,例如下图从右到左,bins数分别为1x1、2x2、4x4。再对每一个bin进行pooling(可以是max-pooling、average-pooling等),分别输出1x256、4x256、16x256(256为输出特征图channel数)。最后,得到一个固定长度的特征向量。
由于bins是固定的,所以无论输入多大,最终结果长度都一样。而在基于滑动窗口的卷积中,输出大小与输入大小相关。

当然,SPP也有许多优点,本文并不赘述,详细可见何恺明的论文。自此,本篇论文的基本模型结构也介绍完了。
四、优化(Optimization)
论文中所有模型都采用下图的损失函数:

这个损失函数有两项,一个正则化项(regularization)和一个铰链损失(hinge-based loss)项。在上图损失函数公式中,
o
i
n
e
t
o_i^{net}
oinet代表神经网络输出,
y
i
y_i
yi是标签:
{
−
1
,
1
}
\{-1,1\}
{−1,1},其中 -1 代表patch对不匹配,1 代表匹配。
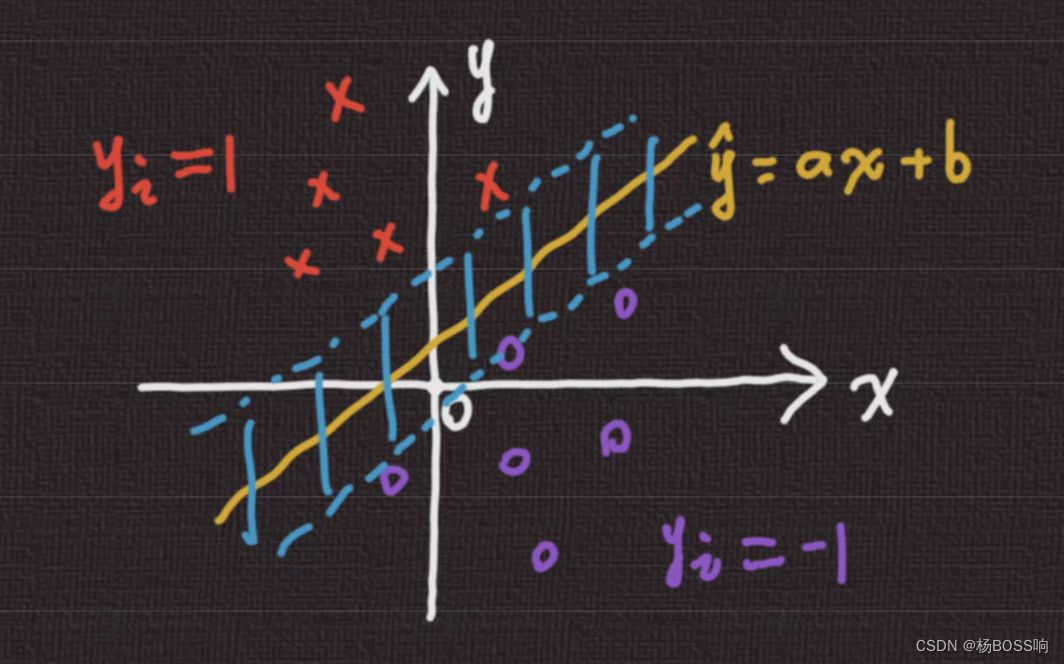
公式中的正则项不做介绍,铰链损失项同SVM中的损失项类似,我们以最简单的SVM二元分类来推导。如下图有两类("x"为正类,"o"为负类),我们需要找到一个函数(
y
^
=
a
x
+
b
\hat{y}=ax+b
y^=ax+b,相当于我们神经网络的输出
o
i
n
e
t
o_i^{net}
oinet)将两类分开。

当
y
i
=
1
y_i=1
yi=1 的时候,我们希望输出
y
^
=
a
x
+
b
>
0
\hat{y}=ax+b>0
y^=ax+b>0;当
y
i
=
−
1
y_i=-1
yi=−1 的时候,我们希望输出
y
^
=
a
x
+
b
<
0
\hat{y}=ax+b<0
y^=ax+b<0。其实为了得到更好的效果,即分界线离二类都比较远,我们会要求输出尽可能远离分界线。如下图,我们要求正类和负类不仅仅在分界线两侧,还要在蓝色区域两侧。
具体实现,只需更改一点点:
- 当 y i = 1 y_i=1 yi=1 的时候,我们希望输出 y ^ = a x + b > α \hat{y}=ax+b>\alpha y^=ax+b>α, α > 0 \alpha>0 α>0
- 当 y i = − 1 y_i=-1 yi=−1 的时候,我们希望输出 y ^ = a x + b < − α \hat{y}=ax+b<-\alpha y^=ax+b<−α, α > 0 \alpha>0 α>0
将上面两点合起来:
α
−
y
i
o
i
n
e
t
<
0
\alpha-y_io_i^{net}<0
α−yioinet<0,
(
α
>
0
)
(\alpha>0)
(α>0),这里还将上式的
y
^
\hat{y}
y^ 换为了
o
i
n
e
t
o_i^{net}
oinet。所以,当分类成功即满足上式时,我们希望
l
o
s
s
=
0
loss=0
loss=0 ;当分类错误即上式大于零时,我们希望
l
o
s
s
loss
loss越大越好,这里直接使用
l
o
s
s
=
α
−
y
i
o
i
n
e
t
loss=\alpha-y_io_i^{net}
loss=α−yioinet。写成一个具体的函数:
l
o
s
s
=
m
a
x
(
0
,
α
−
y
i
o
i
n
e
t
)
loss=max(0,\alpha-y_io_i^{net})
loss=max(0,α−yioinet)
在训练时,作者使用了**数据增强(Data Augmentation)**来对抗过拟合。将patch对进行水平和垂直翻转,旋转90、180、270度。作者说没有发现过拟合,每次差不多训练两天。作者还提供了超参数,具体见论文。
五、实验(Experiment)
Local image patches benchmark
我们使用由 Matthew Brown,Simon Winder,Gang Hua三位创建的基准(benchmark)数据集,该数据集由三个子数据集组成:Yosemite,Notre Dame,and Liberty,现在的数据集变成了Liberty,Notre Dame,Half Dome这三个。每个图像块(patch)都是大小为64x64的灰度图像,具有规范的尺度和方向。在由高斯差分(DOG)或者Harris获取的特征点周围进行采样得到每个patch。具体处理方法和实现细节见论文:Discriminative Learning of Local Image Descriptors。
在评估的时候,我们生成ROC曲线,记录假阳率(false positive rate) 在召回率 (recall)95% 时的值(FPR 95)。作者将上述三个数据集两两组合,得到训练集和测试集。我们还计算了不同组合得到的平均值mean,表中的mean(1,4)代表只平均前四个组合得到的结果。至于为什么要计算一个mean(1,4),我认为只是为了和前人的工作统一罢了。(注:表中最后一列的结果是传统算法SIFT得到的结果)

观察上表,基于2-channel的方法表现比较好,其中2ch-2stream表现最好。基于siam的方法没有传统方法好,其中的siam-2stream方法最好,这也证明了多尺度信息在匹配中的重要性。
Wide baseline stereo evaluation
这一部分的评估,使用数据集“fountain” and “herzjesu” ,由Strecha等人提出。(后面再更吧)
Local descriptors performance evaluation
我们使用Mikolajczyk数据集进行局部描述符的评估。
六、结论(Conclusions)
通过作者实验,作者发现基于 2-channel 神经网络模型在所有结果中表现最好,以后还需要探索如何加快评估(evaluation)效率。
至于siamese-based architectures 和 2-stream multi-resolution models也表现强健,总能提高模型的性能,也证明了多尺度信息的重要性。当然,基于SPP结构的模型也得到同样的结论。
最后,单纯使用更大的数据集进行训练可能会进一步提高模型整体性能。
















 1745
1745











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











