




 本文详述了一次API性能测试及调优的过程。从接到任务开始,通过JMeter测试接口,发现响应时间过长且报错率高。通过硬件监控发现资源使用率低,问题可能出在软件层面。经分析,确定是数据库连接数不足和索引问题导致。通过增加连接数和优化索引,性能显著提升,但长时间压测后出现性能拐点,进一步排查发现慢查询是罪魁祸首。经过优化慢查询,最终实现了稳定高效的性能表现。
本文详述了一次API性能测试及调优的过程。从接到任务开始,通过JMeter测试接口,发现响应时间过长且报错率高。通过硬件监控发现资源使用率低,问题可能出在软件层面。经分析,确定是数据库连接数不足和索引问题导致。通过增加连接数和优化索引,性能显著提升,但长时间压测后出现性能拐点,进一步排查发现慢查询是罪魁祸首。经过优化慢查询,最终实现了稳定高效的性能表现。
某天突然接到隔壁部门的任务,需要帮忙对他们的API进行性能测试,对方大佬的要求非常简单:需测试2个接口,目前常规脚本执行速度大约在0.02秒一条数据,而该API是提供给部门内部人士使用的,允许在开多线程的时候,单条1-2秒,且速度不下降。再询问具体的数据,以一句专业人士来处理把我给打发走了。
我继续分析该要求,看目的是想进行压测,再分析下他们部门人数,并不多,十来个的数量,找对方开发要来了需进行压测的服务器的信息以及接口的数据,发现请求体和响应体的数据量也很低,话不多说,开始性能调优之旅。
1.调通接口
性能测试的起步是接口得先测通,先用Jmeter调用两接口,都能跑通
2.准备测试数据
为保证性能测试的结果偏近于生产环境,也由于对方业务的特殊性,于是继续找他们大佬索要测试数据,对方直接给了一万条数据,直接把测试数据放到CSV文件里,运行1条数据检查效果。
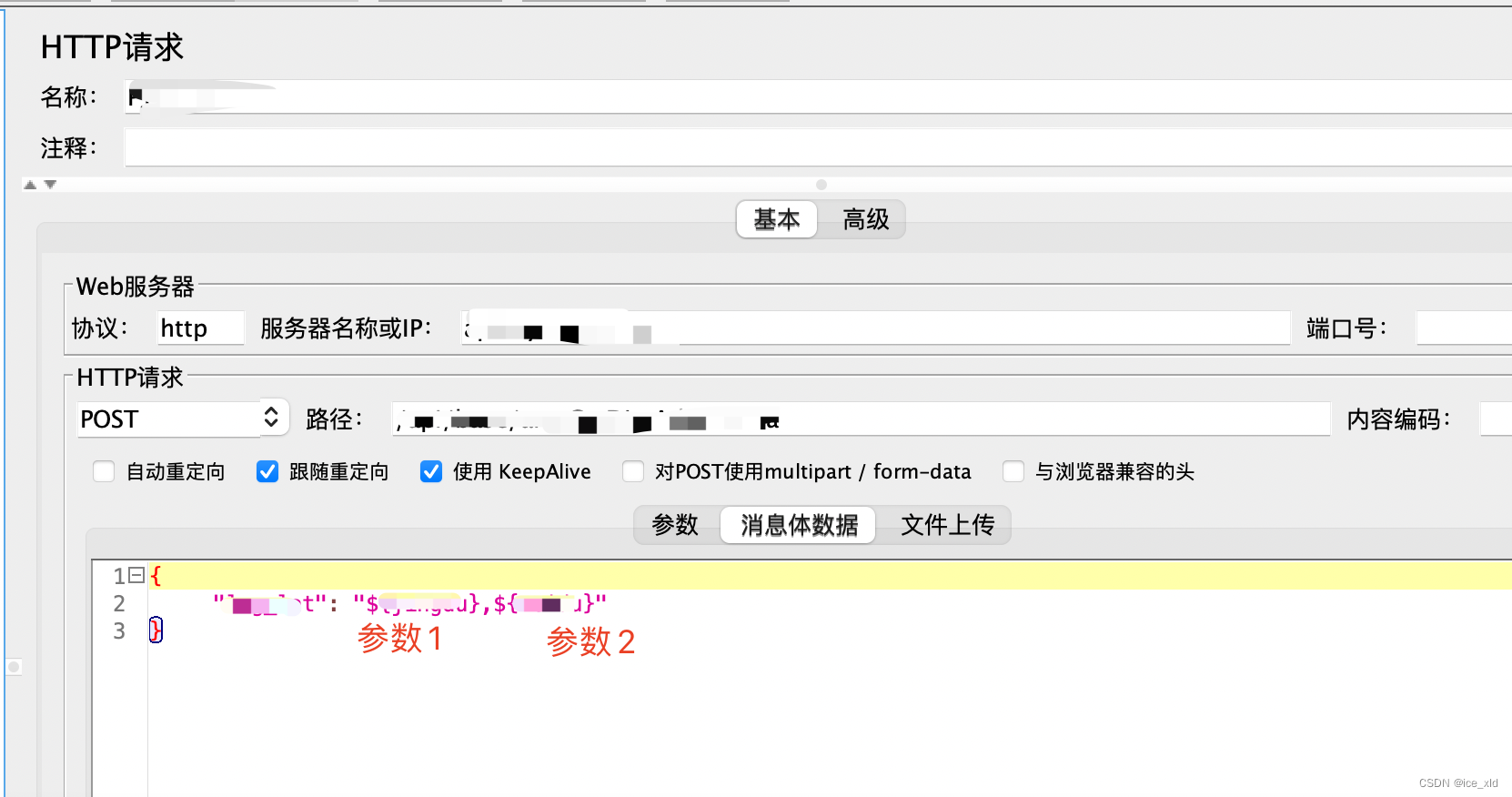
2个接口1个为get请求,1个为post请求,其中post请求是json格式的。
由于该接口仅供内部人士使用,因此有key(类似token)值即可使用
2.1测试数据的参数化
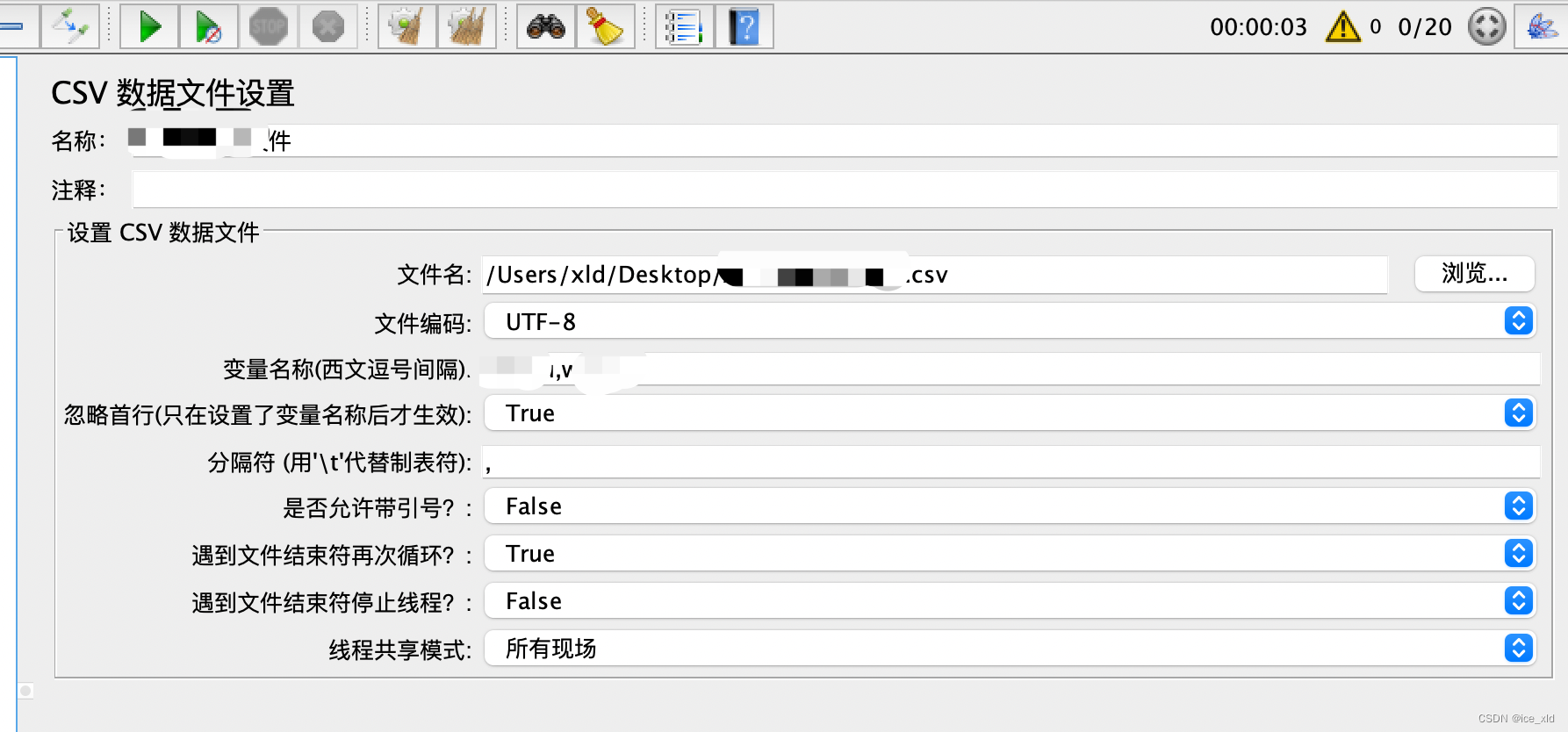
get请求的API设置
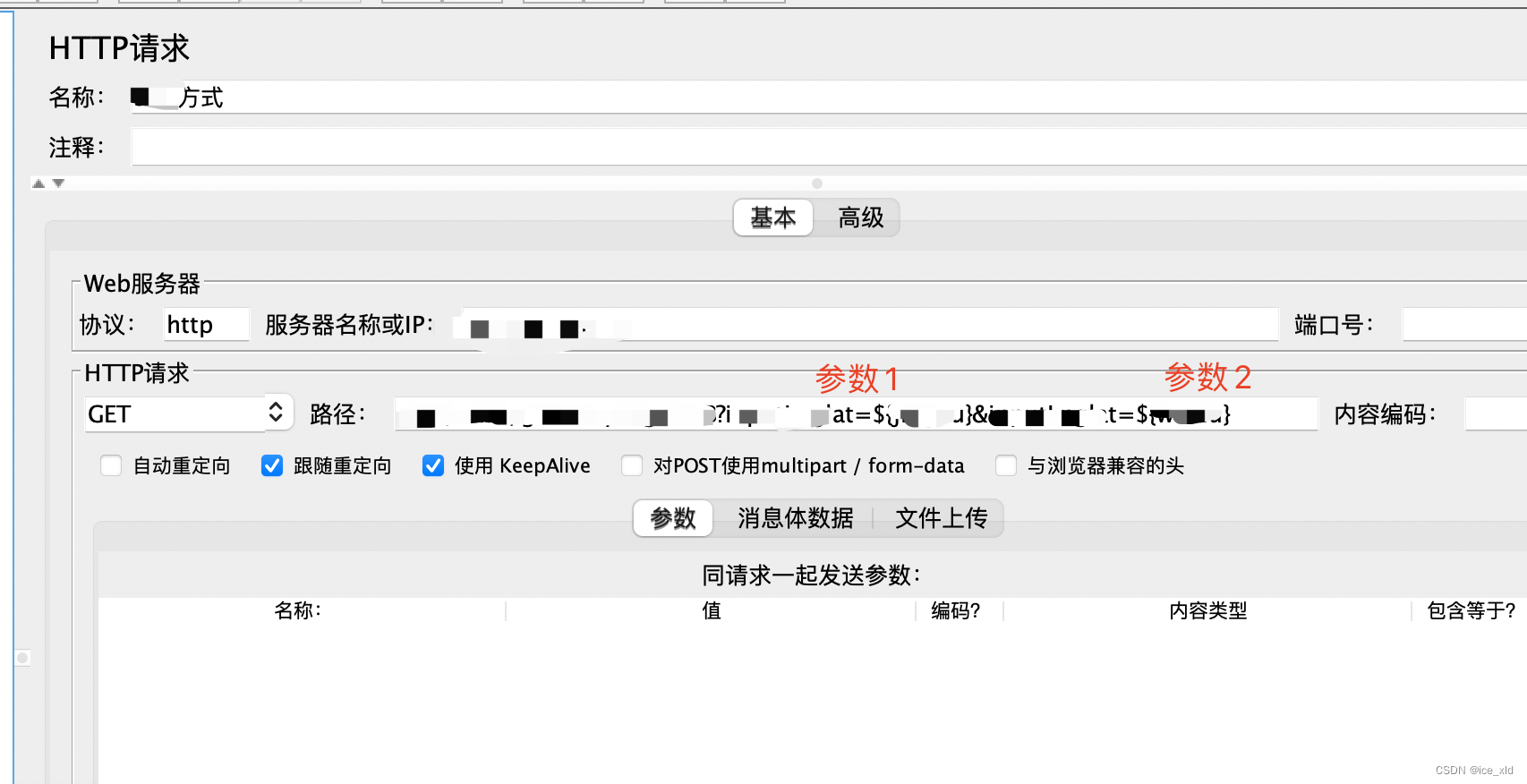
post请求的API设置
 执行后查看结果,没问题。
执行后查看结果,没问题。
3.查看压测环境的硬件信息
由于信息量太少,因此很多事情只能靠自己,通过硬件信息+对方人数来推测至少要达到的并发量。
3.1经典top命令
通过top命令查看硬件资源的使用情况,再按1可以看到CPU是8核,且后续可以查看每个CPU的使用情况。
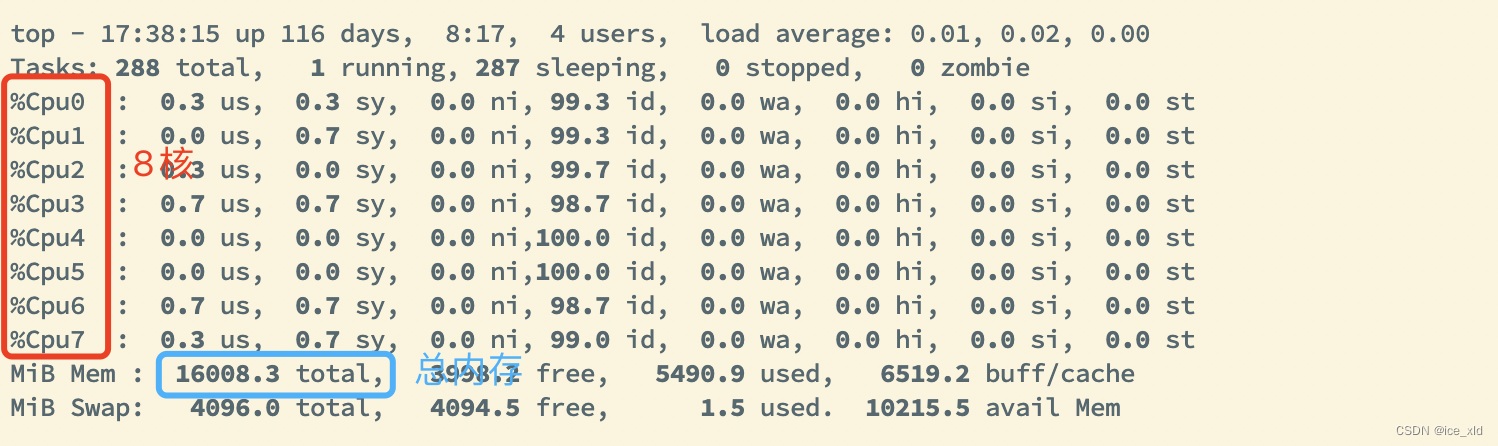
通过MiB Mem可以看到内存是16008MB,也可以使用free -m命令
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 710
710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









