







主要参考了《深入Linux内核架构》和《精通Linux内核网络》相关章节
文章目录
epoll系统调用及内核实现
系统调用接口
-
int epoll_create(int size);
创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大。这个参数不同于select()中的第一个参数,给出最大监听的fd+1的值。需要注意的是,当创建好epoll句柄后,它就是会占用一个fd值,在linux下如果查看/proc/进程id/fd/,是能够看到这个fd的,所以在使用完epoll后,必须调用close()关闭,否则可能导致fd被耗尽。 -
*int epoll_ctl(int epfd, int op, int fd, struct epoll_event event);
epoll的事件注册函数,它不同与select()是在监听事件时告诉内核要监听什么类型的事件,而是在这里先注册要监听的事件类型。- 第一个参数是epoll_create()的返回值,
- 第二个参数表示动作,用三个宏来表示:
EPOLL_CTL_ADD:注册新的fd到epfd中;
EPOLL_CTL_MOD:修改已经注册的fd的监听事件;
EPOLL_CTL_DEL:从epfd中删除一个fd; - 第三个参数是需要监听的fd,第四个参数是告诉内核需要监听什么事,struct epoll_event结构如下:
-
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
等待事件的产生,类似于select()调用。- 参数events用来从内核得到事件的集合,maxevents告之内核这个events有多大,这个maxevents的值不能大于创建epoll_create()时的size(备注:在4.1.2内核里面,epoll_create的size没有什么用),参数timeout是超时时间(毫秒,0会立即返回,小于0时将是永久阻塞)。
- 该函数返回需要处理的事件数目,如返回0表示已超时
在实际应用中,select/poll监视的文件描述符可能会非常多,如果每次只是返回一小部分,那么,这种情况下select/poll
显得不够高效。epoll的设计思路,是把select/poll单个的操作拆分为1个epoll_create+多个epoll_ctrl+一个epoll_wait。
epoll机制实现了自己特有的文件系统eventpoll filesystem
struct epoll_event
struct epoll_event {
__uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
events可以是以下几个宏的集合:
EPOLLIN :表示对应的文件描述符可以读(包括对端SOCKET正常关闭);
EPOLLOUT:表示对应的文件描述符可以写;
EPOLLPRI:表示对应的文件描述符有紧急的数据可读(这里应该表示有带外数据到来);
EPOLLERR:表示对应的文件描述符发生错误;
EPOLLHUP:表示对应的文件描述符被挂断;
EPOLLET: 将EPOLL设为边缘触发(Edge Triggered)模式,这是相对于水平触发(Level Triggered)来说的。
EPOLLONESHOT:只监听一次事件,当监听完这次事件之后,如果还需要继续监听这个socket的话,需要再次把这个socket加入到EPOLL队列里
优势对比
epoll相比select/poll的优势:
- **select/poll每次调用都要传递所要监控的所有fd给select/poll系统调用(这意味着每次调用都要将fd列表从用户态拷贝到内核态,当fd数目很多时,这会造成低效)。**而每次调用epoll_wait时(作用相当于调用select/poll),不需要再传递fd列表给内核,因为已经在epoll_ctl中将需要监控的fd告诉了内核(epoll_ctl不需要每次都拷贝所有的fd,只需要进行增量式操作)。所以,在调用epoll_create之后,内核已经在内核态开始准备数据结构存放要监控的fd了。每次epoll_ctl只是对这个数据结构进行简单的维护。
- **select/poll一个致命弱点就是当你拥有一个很大的socket集合,不过由于网络延时,任一时间只有部分的socket是"活跃"的,但是select/poll每次调用都会线性扫描全部的集合,导致效率呈现线性下降。**但是epoll不存在这个问题,它只会对"活跃"的socket进行操作—这是因为在内核实现中epoll是根据每个fd上面的callback函数实现的。
- **当我们调用epoll_ctl往里塞入百万个fd时,epoll_wait仍然可以飞快的返回,并有效的将发生事件的fd给我们用户。这是由于我们在调用epoll_create时,内核除了帮我们在epoll文件系统里建了个file结点,在内核cache里建了个红黑树用于存储以后epoll_ctl传来的fd外,还会再建立一个list链表,用于存储准备就绪的事件,当epoll_wait调用时,仅仅观察这个list链表里有没有数据即可。**有数据就返回,没有数据就sleep,等到timeout时间到后即使链表没数据也返回。所以,epoll_wait非常高效。而且,通常情况下即使我们要监控百万计的fd,大多一次也只返回很少量的准备就绪fd而已,所以,epoll_wait仅需要从内核态copy少量的fd到用户态而已。那么,这个准备就绪list链表是怎么维护的呢?当我们执行epoll_ctl时,除了把fd放到epoll文件系统里file对象对应的红黑树上之外,还会给内核中断处理程序注册一个回调函数,告诉内核,如果这个fd的中断到了,就把它放到准备就绪list链表里。所以,当一个fd(例如socket)上有数据到了,内核在把设备(例如网卡)上的数据copy到内核中后就来把fd(socket)插入到准备就绪list链表里了。
性能测试
epoll 是 Linux 内核的可扩展 I/O 事件通知机制,其最大的特点就是性能优异。下图是 libevent(一个知名的异步事件处理软件库)对 select,poll,epoll ,kqueue 这几个 I/O 多路复用技术做的性能测试。

很多文章在描述 epoll 性能时都引用了这个基准测试,但少有文章能够清晰的解释这个测试结果。
这是一个限制了100个活跃连接的基准测试,每个连接发生1000次读写操作为止。纵轴是请求的响应时间,横轴是持有的 socket 句柄数量。随着句柄数量的增加,epoll 和 kqueue 响应时间几乎无变化,而 poll 和 select 的响应时间却增长了非常多。
可以看出来,epoll 性能是很高的,并且随着监听的文件描述符的增加,epoll 的优势更加明显。
不过,这里限制的100个连接很重要。epoll 在应对大量网络连接时,只有活跃连接很少的情况下才能表现的性能优异。换句话说,epoll 在处理大量非活跃的连接时性能才会表现的优异。如果15000个 socket 都是活跃的,epoll 和 select 其实差不了太多。
预备知识
f_op->poll 和 poll_wait
把当前进程加入到驱动里自定义的等待队列上
当驱动事件就绪后,就可以在驱动里自定义的等待队列上唤醒调用poll的进程
poll_wait作用:可以让驱动知道 事件就绪的时候唤醒哪些等待进程
钩子poll
内核f_op->poll必须配合驱动自己的等待队列才能用,不然驱动有事件产生后不知道哪些进程调用了poll来等待这个事件
内核f_op->poll要做的事情
- 调用poll_wait,将当前进程放入驱动设备的等待队列上,这样驱动就知道哪些进程在调用poll等待事件
- 检查此时立刻已有的事件(POLLIN\POLLOUT\POLLERR…)并返回掩码表示
进程调用
poll的时候,poll内部应该把当前进程放到合适的等待队列上这样事件产生的时候,调用
poll的进程由于已经在对应等待队列上了,于是就会被唤醒
后续将看到 epoll的fd自己的poll —— ep_eventpoll_poll,和poll_wait调用的函数(ep_insert设置的)
等待队列
等待队列对头:wait_queue_head_t
队列的成员:wait_queue_t
epoll中用 eppoll_entry管理 wait_queue_t和epitem,可用wait_queue_t反推出epoll_entry的地址
wait_queue_t的成员:
// 别名
struct __wait_queue {
unsigned int flags; // 指向进程描述符task_struct
void *private;
wait_queue_func_t func; // 唤醒时调用此函数,即钩子函数 —— epoll中为ep_poll_callback
struct list_head task_list; // 队列链表指针
};
一般钩子函数func是内核默认函数default_wake_function,功能就是唤醒了进程
我们也可以在把进程放入等待队列时主动设定钩子函数,使得在唤醒进程时自动执行我们需要的操作
epoll就利用了队列钩子函数:把产生的事件内容copy到rdlist
这样,事件来临时会自动把事件内容放到rdlist中,而不需要我们自己遍历监听句柄们查有谁产生了事件
数据结构
fs\eventpoll.c linux 4.12
struct eventpoll 管理epoll相关成员
epoll_create创建了epoll句柄eventpoll,返回其文件表示的描述符epfd
eventpoll内部有以下关键数据结构:
-
rbtree:红黑树,每个被加入到epoll监控的文件事件会创建一个epitem结构,作为rbtree节点使用rbtree的优点:可容纳大量文件事件,方便增删改(O(lgN))
-
rdlist:内核链表,用于存放当前产生了期待事件产生的文件句柄们(这里的一个文件句柄可以理解为一个epoll_event)
-
wq:当进程调用epoll_wait等待时,进程加入等待队列wq
-
poll_wait:eventpoll本身的等待队列,由于eventpoll自己也被当做文件,这个队列用于自己被别人调用select/poll/epoll监听的情况(一般没啥用)
poll_wait在啥时候用呢:
fd = socket(…);efd1 = epoll_create();efd2 = epoll_create();epoll_ctl(efd1, EPOLL_CTL_ADD, fd, …);epoll_ctl(efd2, EPOLL_CTL_ADD, efd1, …);
如上,efd1监控fd,而efd2监控了efd1,即嵌套的epoll监控:epoll监控另一个epoll句柄
efd2要监控efd1,将调用efd1的poll函数
回忆之前说过:文件f_op->poll需要配合驱动提供的等待队列
对于epollfd,等待队列就是poll_wait
efd2监听efd1,会调用efd1->f_op->poll,于是把当前进程放到efd1的poll_wait队列上
在epoll的内核实现中,当efd1本身监听到fd事件产生后,会顺便唤醒poll_wait上的进程
于是,“efd1监听到事件” 被通知到efd2。这样,就实现了epollfd被其他多路复用监听了!
故:poll_wait就是用于epoll句柄被另外的多路复用监听的,配合epoll自己的f_op->poll,看起来一般用不到
/*
* 该结构存储在文件结构的“private_data”成员中,代表了eventpoll接口的主要数据结构。
*/
struct eventpoll {
/* Protect the access to this structure */
spinlock_t lock;
/*
* This mutex is used to ensure that files are not removed
* while epoll is using them. This is held during the event
* collection loop, the file cleanup path, the epoll file exit
* code and the ctl operations.
*/
struct mutex mtx;
/* sys_epoll_wait() 使用的等待队列 */
wait_queue_head_t wq;
/* file->poll() 使用的等待队列 */
wait_queue_head_t poll_wait;
/* List of ready file descriptors */
struct list_head rdllist; // 就绪链表
/* RB tree root used to store monitored fd structs */
struct rb_root rbr; // 管理fd的红黑树
/*
* This is a single linked list that chains all the "struct epitem" that
* happened while transferring ready events to userspace w/out
* holding ->lock.
*/
struct epitem *ovflist; // 将事件到达的fd进行链接起来发送至用户空间
/* wakeup_source used when ep_scan_ready_list is running */
struct wakeup_source *ws;
/* The user that created the eventpoll descriptor */
struct user_struct *user;
struct file *file;
/* 用于优化循环检测检查 */
int visited;
struct list_head visited_list_link;
#ifdef CONFIG_NET_RX_BUSY_POLL
/* used to track busy poll napi_id */
unsigned int napi_id;
#endif
};
struct epitem 红黑树节点
每当我们调用 epoll_ctl 增加一个 fd 时,内核就会为我们创建出一个 epitem 实例,并且把这个实例作为红黑树的一个子节点,增加到 eventpoll 结构体中的红黑树中,对应的字段是 rbr。这之后,查找每一个 fd 上是否有事件发生都是通过红黑树上的 epitem 来操作。
/*
* 添加到 eventpoll 接口的每个文件描述符都会有一个链接到“rbr”RB 树的此类条目。
* 避免增加这个结构的大小,服务器上可能有成千上万个这样的结构,我们不希望它占用另一个缓存行。
*/
struct epitem {
union {
/* RB 树节点将此结构链接到 eventpoll RB 树 */
struct rb_node rbn;
/* Used to free the struct epitem */
struct rcu_head rcu;
};
/* 事件就绪队列 */
struct list_head rdllink;
/*
* 与“struct eventpoll”->ovflist 一起工作以保持项目的单个链接链。
*/
struct epitem *next;
/* 此结构体对应的被监听的文件描述符信息 */
struct epoll_filefd ffd;
/* Number of active wait queue attached to poll operations */
int nwait;
/* 双向链表,保存着被监听文件的等待队列,功能类似select/poll中的poll_table */
struct list_head pwqlist;
/* 这个epitem的所有者(eventpoll) */
struct eventpoll *ep;
/* List header used to link this item to the "struct file" items list */
struct list_head fllink;
/* wakeup_source used when EPOLLWAKEUP is set */
struct wakeup_source __rcu *ws;
/* 描述感兴趣事件和源 fd 的结构 */
struct epoll_event event;
};
struct eppoll_entry 等待队列的元素
每次当一个 fd 关联到一个 epoll 实例,就会有一个 eppoll_entry 、wait_queue_t 和 epitem 产生。eppoll_entry 的结构如下:
轮询挂钩使用的等待结构
epoll中用 eppoll_entry管理 wait_queue_t 和 epitem ,可用wait_queue_t反推出epoll_entry的地址
/* Wait structure used by the poll hooks */
struct eppoll_entry {
/* List header used to link this structure to the "struct epitem" */
struct list_head llink;
// 所属的epitem
struct epitem *base;
// 将链接到目标文件等待队列头的等待队列项。
wait_queue_t wait;
/* 链接“等待”等待队列项的等待队列头 */
wait_queue_head_t *whead;
};
ep_poll_callback 等待队列的回调函数
ep_poll_callback 函数的作用非常重要,它将内核事件真正地和 epoll 对象联系了起来。它又是怎么实现的呢?
**首先,通过这个文件的 wait_queue_entry_t 对象找到对应的 epitem 对象,因为 eppoll_entry 对象里保存了 wait_quue_entry_t,根据 wait_quue_entry_t 这个对象的地址就可以简单计算出 eppoll_entry 对象的地址,从而可以获得 epitem 对象的地址。**这部分工作在 ep_item_from_wait 函数中完成。一旦获得 epitem 对象,就可以寻迹找到 eventpoll 实例。
/*
* This is the callback that is passed to the wait queue wakeup
* mechanism. It is called by the stored file descriptors when they
* have events to report.
*/
static int ep_poll_callback(wait_queue_entry_t *wait, unsigned mode, int sync, void *key)
{
int pwake = 0;
unsigned long flags;
struct epitem *epi = ep_item_from_wait(wait);
struct eventpoll *ep = epi->ep;
// 判断返回的事件掩码里是否设置了标志位POLLFREE,如果是则将当前等待对象从文件描述符的等待队列中删除
if ((unsigned long)key & POLLFREE) {
ep_pwq_from_wait(wait)->whead = NULL;
/*
* whead = NULL above can race with ep_remove_wait_queue()
* which can do another remove_wait_queue() after us, so we
* can't use __remove_wait_queue(). whead->lock is held by
* the caller.
*/
list_del_init(&wait->task_list);
}
// 对epoll的实例加锁
spin_lock_irqsave(&ep->lock, flags);
ep_set_busy_poll_napi_id(epi);
/*
* 如果事件掩码不包含任何 poll(2) 事件,我们认为描述符被禁用。 这种情况很可能是 EPOLLONESHOT 位的影响,
* 该位在接收到事件时禁用描述符,直到发出下一个 EPOLL_CTL_MOD。
* 对EPOLLONESHOT标志的处理是在epoll_wait()的返回过程,调用ep_send_events_proc()的时候,如果设置了EPOLLONESHOT标志则将EP_PRIVATE_BITS以外的标志位全部清0:
*/
// 接下来判断epitem中的事件掩码是不是并没有包括任何poll(2)事件,如果是的话,则解锁后直接返回:
if (!(epi->event.events & ~EP_PRIVATE_BITS))
goto out_unlock;
/*
* Check the events coming with the callback. At this stage, not
* every device reports the events in the "key" parameter of the
* callback. We need to be able to handle both cases here, hence the
* test for "key" != NULL before the event match test.
*/
// 接下来判断返回的事件里是否有用户真正感兴趣的事件,没有则解锁后返回,否则继续。
if (key && !((unsigned long) key & epi->event.events))
goto out_unlock;
/*
* If we are transferring events to userspace, we can hold no locks
* (because we're accessing user memory, and because of linux f_op->poll()
* semantics). All the events that happen during that period of time are
* chained in ep->ovflist and requeued later on.
*/
// 如果此时就绪链表rdllist没有被其他进程访问(epoll_ctl和epoll_wait),
// 则直接将当前文件描述符添加到rdllist链表中,否则的话添加到ovflist链表中。
// ovflist默认值是EP_UNACTIVE_PTR,epoll_wait()遍历rdllist之前会把ovflist设置为NULL,
// 遍历完再恢复为EP_UNACTIVE_PTR,因此通过判断ovflist的值是不是EP_UNACTIVE_PTR可知此时rdllist是不是正在被访问。
if (unlikely(ep->ovflist != EP_UNACTIVE_PTR)) {
if (epi->next == EP_UNACTIVE_PTR) {
epi->next = ep->ovflist;
ep->ovflist = epi;
if (epi->ws) {
/*
* Activate ep->ws since epi->ws may get
* deactivated at any time.
*/
__pm_stay_awake(ep->ws);
}
}
goto out_unlock;
}
/* If this file is already in the ready list we exit soon */
if (!ep_is_linked(&epi->rdllink)) {
list_add_tail(&epi->rdllink, &ep->rdllist);
ep_pm_stay_awake_rcu(epi);
}
/*
* Wake up ( if active ) both the eventpoll wait list and the ->poll()
* wait list.
*/
// 如果是描述符是添加到ovflist链表中,说明此时已经有ep_wait()准备返回了,
// 因此不用再唤醒epoll实例的等待队列,因此1062行直接跳到解锁处;
// 否则的话,则唤醒因为调用epoll_wait()而等待在epoll实例等待队列上的进程(这里最多只会唤醒一个进程):
if (waitqueue_active(&ep->wq)) {
if ((epi->event.events & EPOLLEXCLUSIVE) &&
!((unsigned long)key & POLLFREE)) {
switch ((unsigned long)key & EPOLLINOUT_BITS) {
case POLLIN:
if (epi->event.events & POLLIN)
ewake = 1;
break;
case POLLOUT:
if (epi->event.events & POLLOUT)
ewake = 1;
break;
case 0:
ewake = 1;
break;
}
}
wake_up_locked(&ep->wq);
}
// 如果epoll实例的poll队列非空,也会唤醒等待在poll队列上的进程,不过是在解锁后才会进行唤醒操作。
if (waitqueue_active(&ep->poll_wait))
pwake++;
// 最后解锁并返回
out_unlock:
spin_unlock_irqrestore(&ep->lock, flags);
/* We have to call this outside the lock */
if (pwake)
ep_poll_safewake(&ep->poll_wait);
if (epi->event.events & EPOLLEXCLUSIVE)
return ewake;
return 1;
}
注意到ep_poll_callback()的返回值和EPOLLEXCLUSIVE标志有关,该标志是用来处理这种情况:当多个进程中的不同epoll实例在监视同一个文件描述符时,如果该文件描述符上有事件发生,则所有的epoll实例所在进程都将被唤醒,这样有可能造成“惊群”(thundering herd)。关于EPOLLEXCLUSIVE可以看这里。
显然 EPOLLEXCLUSIVE (详看 2016 年 4.5+ 内核添加的 patch)的逻辑不会无差别地唤醒所有进程/线程,它只唤醒一个正在睡眠的进程/线程处理新来的资源。
系统调用
epoll_create
epoll_create用于创建一个epoll的句柄,其在内核的系统实现如下:
sys_epoll_create:
SYSCALL_DEFINE1(epoll_create, int, size)
{
if (size <= 0)
return -EINVAL;
return sys_epoll_create1(0);
}
可见,我们在调用epoll_create时,传入的size参数,仅仅是用来判断是否小于等于0,之后再也没有其他用处。
整个函数就3行代码,真正的工作还是放在sys_epoll_create1函数中。
sys_epoll_create -> sys_epoll_create1:
-
总结epoll_create函数所做的事:
- 在内核中分配一个eventpoll结构和代表epoll文件的file结构,并且将这两个结构关联在一块,同时,返回一个也与file结构相关联的epoll文件描述符fd。
- 当应用程序操作epoll时,需要传入一个epoll文件描述符fd,内核根据这个fd,找到epoll的file结构,然后通过file,获取之前epoll_create申请eventpoll结构变量,epoll相关的重要信息都存储在这个结构里面。
- 接下来,所有epoll接口函数的操作,都是在eventpoll结构变量上进行的。
所以,epoll_create的作用就是为进程在内核中建立一个从epoll文件描述符到eventpoll结构变量的通道。
/*
* Open an eventpoll file descriptor.
*/
SYSCALL_DEFINE1(epoll_create1, int, flags)
{
int error, fd;
struct eventpoll *ep = NULL;
struct file *file;
/* Check the EPOLL_* constant for consistency. */
BUILD_BUG_ON(EPOLL_CLOEXEC != O_CLOEXEC);
if (flags & ~EPOLL_CLOEXEC)
return -EINVAL;
/*
* Create the internal data structure ("struct eventpoll").
*/
error = ep_alloc(&ep); // 首先调用ep_alloc函数申请一个eventpoll结构,并且初始化该结构的成员
if (error < 0)
return error;
/*
* Creates all the items needed to setup an eventpoll file. That is,
* a file structure and a free file descriptor.
*/
fd = get_unused_fd_flags(O_RDWR | (flags & O_CLOEXEC)); // 调用get_unused_fd_flags函数,在本进程中申请一个未使用的fd文件描述符
if (fd < 0) {
error = fd;
goto out_free_ep;
}
file = anon_inode_getfile("[eventpoll]", &eventpoll_fops, ep,
O_RDWR | (flags & O_CLOEXEC)); // 调用anon_inode_getfile,创建一个file结构
if (IS_ERR(file)) {
error = PTR_ERR(file);
goto out_free_fd;
}
ep->file = file;
fd_install(fd, file); // 调用fd_install函数,将fd与file交给关联在一起,之后,内核可以通过应用传入的fd参数访问file结构
return fd;
out_free_fd:
put_unused_fd(fd);
out_free_ep:
ep_free(ep);
return error;
}
epoll_ctl
接下来判断用户是否设置了EPOLLEXCLUSIVE标志,这个标志是4.5版本内核才有的,主要是为了解决同一个文件描述符同时被添加到多个epoll实例中造成的“惊群”问题,详细描述可以看这里。 这个标志的设置有一些限制条件,比如只能是在EPOLL_CTL_ADD操作中设置,而且对应的文件描述符本身不能是一个epoll实例。
epoll_ctl接口的作用是添加/修改/删除文件的监听事件:
-
epoll_ctl:EPOLL_CTL_ADD、EPOLL_CTL_MOD、EPOLL_CTL_DEL新增、修改、删除红黑树上的文件句柄
-
其中epll_ctl:EPOLL_CTL_ADD新增句柄不仅仅新增红黑树节点,更关键的是对文件开始监控!
与select/poll的本质区别:并不是调用epoll_wait的时候才监听文件,而是EPOLL_CTL_ADD的时候就开始监听了
sys_epoll_ctl:
SYSCALL_DEFINE4(epoll_ctl, int, epfd, int, op, int, fd,
struct epoll_event __user *, event)
{
int error;
int full_check = 0;
struct fd f, tf;
struct eventpoll *ep;
struct epitem *epi;
struct epoll_event epds; // 存储user空间传输入的描述监听事件的对象
struct eventpoll *tep = NULL;
error = -EFAULT;
/* ep_op_has_event(op)判断是否不是删除操作,如果op != EPOLL_CTL_DEL为true,则需要调用copy_from_user函数将用户空间传过来的event事件拷贝到内核的epds变量中。*/
if (ep_op_has_event(op) &&
copy_from_user(&epds, event, sizeof(struct epoll_event)))
goto error_return;
error = -EBADF;
// 获取epoll文件fd结构变量
f = fdget(epfd);
if (!f.file)
goto error_return;
// 获取被监听文件fd结构变量
tf = fdget(fd);
if (!tf.file)
goto error_fput;
// 接下来就是对参数的一些检查
error = -EPERM;
if (!tf.file->f_op->poll) // 目标文件是否支持poll操作
goto error_tgt_fput;
/* Check if EPOLLWAKEUP is allowed */
if (ep_op_has_event(op))
ep_take_care_of_epollwakeup(&epds);
error = -EINVAL;
// 监听的目标文件是是否是epoll文件或者本身
if (f.file == tf.file || !is_file_epoll(f.file))
goto error_tgt_fput;
/*
* epoll 仅在 EPOLL_CTL_ADD 时间添加到唤醒队列,因此 EPOLLEXCLUSIVE(独占) 不允许用于 EPOLL_CTL_MOD 操作。
* 此外,我们目前不支持嵌套独占唤醒。
*/
if (ep_op_has_event(op) && (epds.events & EPOLLEXCLUSIVE)) {
if (op == EPOLL_CTL_MOD)
goto error_tgt_fput;
if (op == EPOLL_CTL_ADD && (is_file_epoll(tf.file) ||
(epds.events & ~EPOLLEXCLUSIVE_OK_BITS)))
goto error_tgt_fput;
}
/*
* At this point it is safe to assume that the "private_data" contains
* our own data structure.
*/
ep = f.file->private_data;
/*
* 当我们插入一个 epoll 文件描述符时,在另一个 epoll 文件描述符中,有创建闭环的变化,这里最好处理,而不是在更关键的路径中。
* 在检查循环时,我们还确定可访问的文件列表并将它们挂在 tfile_check_list 上,因此我们可以检查我们是否创建了太多可能的唤醒路径。
*
* 当 epoll 文件描述符直接附加到唤醒源时,我们不需要在 EPOLL_CTL_ADD 上获取全局 'epumutex',除非 epoll 文件描述符是嵌套的。 在添加时采用“epmutex”的目的是防止通过多个 EPOLL_CTL_ADD 操作并行形成复杂的拓扑,例如循环和深度唤醒路径。
*/
mutex_lock_nested(&ep->mtx, 0);
if (op == EPOLL_CTL_ADD) {
if (!list_empty(&f.file->f_ep_links) ||
is_file_epoll(tf.file)) {
full_check = 1;
mutex_unlock(&ep->mtx);
mutex_lock(&epmutex);
if (is_file_epoll(tf.file)) {
error = -ELOOP;
if (ep_loop_check(ep, tf.file) != 0) {
clear_tfile_check_list();
goto error_tgt_fput;
}
} else
list_add(&tf.file->f_tfile_llink,
&tfile_check_list);
mutex_lock_nested(&ep->mtx, 0);
if (is_file_epoll(tf.file)) {
tep = tf.file->private_data;
mutex_lock_nested(&tep->mtx, 1);
}
}
}
/*
* Try to lookup the file inside our RB tree, Since we grabbed "mtx"
* above, we can be sure to be able to use the item looked up by
* ep_find() till we release the mutex.
*/
epi = ep_find(ep, tf.file, fd);
error = -EINVAL;
switch (op) {
case EPOLL_CTL_ADD:
if (!epi) {
epds.events |= POLLERR | POLLHUP; // 对要注册的事件event->events追加关心事件:EPOLLERR | EPOLLHUP
error = ep_insert(ep, &epds, tf.file, fd, full_check); // 插入红黑树,调用poll
} else
error = -EEXIST;
if (full_check)
clear_tfile_check_list();
break;
case EPOLL_CTL_DEL:
if (epi)
error = ep_remove(ep, epi);
else
error = -ENOENT;
break;
case EPOLL_CTL_MOD:
if (epi) {
if (!(epi->event.events & EPOLLEXCLUSIVE)) {
epds.events |= POLLERR | POLLHUP;
error = ep_modify(ep, epi, &epds);
}
} else
error = -ENOENT;
break;
}
if (tep != NULL)
mutex_unlock(&tep->mtx);
mutex_unlock(&ep->mtx);
error_tgt_fput:
if (full_check)
mutex_unlock(&epmutex);
fdput(tf);
error_fput:
fdput(f);
error_return:
return error;
}
EPOLL_CTL_ADD 已经调用poll(ep_eventpoll_poll,epoll文件句柄的poll函数)
与select/poll的本质区别:并不是调用epoll_wait的时候才监听文件,而是EPOLL_CTL_ADD的时候就开始监听了
case EPOLL_CTL_ADD:
if (!epi) {
epds.events |= POLLERR | POLLHUP; // 对要注册的事件event->events追加关心事件:EPOLLERR | EPOLLHUP
error = ep_insert(ep, &epds, tf.file, fd, full_check); // 插入红黑树,调用poll
} else
error = -EEXIST;
if (full_check)
clear_tfile_check_list();
break;
epoll_ctl(epfd, EPOLL_CTL_ADD, fd, fdevent)核心流程:
-
对要注册的事件event->events追加关心事件:EPOLLERR | EPOLLHUP
回忆epoll的使用中说过:EPOLLERR、EPOLLHUP事件会被自动监听,即使我们没设置 -
调用ep_insert
-
创建epitem结构,加入到红黑树中
-
【关键】revent = file->f_op->poll,即调用poll(ep_eventpoll_poll)
再接下来的事情非常重要,ep_insert 会为加入的每个文件描述字设置回调函数。这个回调函数是通过函数 ep_ptable_queue_proc 来进行设置的。这个回调函数是干什么的呢?其实,对应的文件描述字上如果有事件发生,就会调用这个函数,比如套接字缓冲区有数据了,就会回调这个函数。这个函数就是 ep_poll_callback。这里你会发现,原来内核设计也是充满了事件回调的原理。
- 调用poll_wait,
- 调用ep_ptable_queue_proc初始化
- 设置回调函数ep_poll_callback
- 把当前进程放到文件的等待队列(epoll_create创建的fd)上
- 调用ep_ptable_queue_proc初始化
- 调用poll_wait,
-
返回值revent是文件当前已产生事件掩码
-
检查返回事件:如果revent与关心事件event->events有交集(说明ADD之前事件就准备好了)
- 把此epitem节点拷贝到rdlist链表中;(就绪句柄拷贝到rdlist)
- 如果有进程在wq等待队列上(即有进程在调用epoll_wait等待),则唤醒之!
- 顺便,如果有进程在poll_wait等待队列上(即有进程调用多路复用来监听当前epoll句柄),则唤醒之!
-
可以看到,如果在EPOLL_CTL_ADD一个文件之前,这个文件关心的事件就已经产生了的话,由于会唤醒wq队列上的进程,则此时EPOLL_CTL_ADD会使得epoll_wait函数从阻塞中返回
poll_wait 设置 wait_queue_t的回调函数
static inline void poll_wait(struct file * filp, wait_queue_head_t * wait_address, poll_table *p)
{
if (p && p->_qproc && wait_address)
p->_qproc(filp, wait_address, p);
}
// poll_wait调用的函数
// 这是用于将我们的等待队列添加到目标文件唤醒列表的回调。
static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead,
poll_table *pt)
{
struct epitem *epi = ep_item_from_epqueue(pt);
struct eppoll_entry *pwq;
if (epi->nwait >= 0 && (pwq = kmem_cache_alloc(pwq_cache, GFP_KERNEL))) {
init_waitqueue_func_entry(&pwq->wait, ep_poll_callback); // 设置回调函数
pwq->whead = whead;
pwq->base = epi;
if (epi->event.events & EPOLLEXCLUSIVE)
add_wait_queue_exclusive(whead, &pwq->wait);
else
add_wait_queue(whead, &pwq->wait);
list_add_tail(&pwq->llink, &epi->pwqlist);
epi->nwait++;
} else {
/* We have to signal that an error occurred */
epi->nwait = -1;
}
}
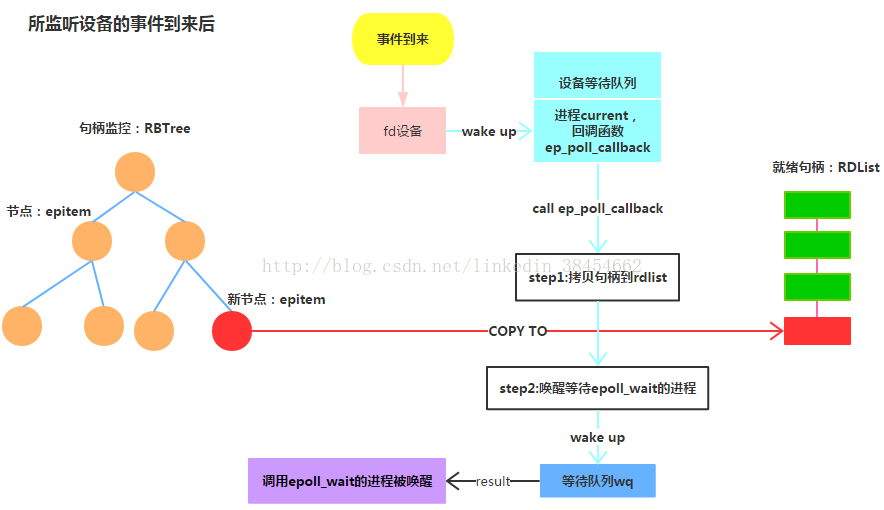
回调函数ep_poll_callback(当有事件到来时)
回调函数ep_poll_callback作为等待队列的回调函数:
当文件事件来临,唤醒文件等待队列上进程,ep_poll_callback函数将被自动调用,并把已产生事件们作为其参数传入
回调函数ep_poll_callback核心流程:
ep_poll_callback检查已产生事件与关心事件是否有交集,如果有:
- 将文件的epitem节点拷贝到rdlist链表上(就绪句柄拷贝到rdlist),若就绪链表被访问则拷贝到ovflist链表上
- 如果有进程在wq等待队列上(即有进程在调用epoll_wait等待),则唤醒之!
- 顺便,如果有进程在poll_wait等待队列上(即有进程调用多路复用来监听当前epoll句柄),则唤醒之!
简而言之:回调函数把文件句柄拷贝到rdlist,并唤醒epoll_wait等待的进程
epoll_wait
epoll_wait并不监听文件句柄
主要逻辑:
- 不断让出CPU,直到
- 等待rdlist不空
- 收到信号
- 超时
- 如果rdlist有数据,则(检查是否有效)拷贝到用户传入的events数组
下面这个图片忽略 redlist 不为空时的一些检查

epoll 的两种触发模式
epoll有EPOLLLT和EPOLLET两种触发模式,LT是默认的模式,ET是“高速”模式。
- LT(水平触发)模式下,只要这个文件描述符还有数据可读,每次 epoll_wait都会返回它的事件,提醒用户程序去操作;
- ET(边缘触发)模式下,在它检测到有 I/O 事件时,通过 epoll_wait 调用会得到有事件通知的文件描述符,对于每一个被通知的文件描述符,如可读,则必须将该文件描述符一直读到空,让 errno 返回 EAGAIN 为止,否则下次的 epoll_wait 不会返回余下的数据,会丢掉事件。
如果ET模式不是非阻塞的,那这个一直读或一直写势必会在最后一次阻塞。
还有一个特点是,epoll使用“事件”的就绪通知方式,通过epoll_ctl注册fd,一旦该fd就绪,内核就会采用类似callback的回调机制来激活该fd,epoll_wait便可以收到通知。

【epoll为什么要有ET触发模式?】:
如果采用 EPOLLLT 模式的话,系统中一旦有大量你不需要读写的就绪文件描述符,它们每次调用epoll_wait都会返回,这样会大大降低处理程序检索自己关心的就绪文件描述符的效率.。而采用EPOLLET这种边缘触发模式的话,当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据全部读写完(如读写缓冲区太小),那么下次调用epoll_wait()时,它不会通知你,也就是它只会通知你一次,直到该文件描述符上出现第二次可读写事件才会通知你!!!这种模式比水平触发效率高,系统不会充斥大量你不关心的就绪文件描述符。
【总结】:
ET模式(边缘触发)
- 只有数据到来才触发,不管缓存区中是否还有数据,缓冲区剩余未读尽的数据不会导致epoll_wait返回;
- 边沿触发模式很大程度上降低了同一个epoll事件被重复触发的次数,所以效率更高;
- 对于读写的connfd,边缘触发模式下,必须使用非阻塞IO,并要一次性全部读写完数据。
- ET的编程可以做到更加简洁,某些场景下更加高效,但另一方面容易遗漏事件,容易产生bug;
LT 模式(水平触发,默认)
- 只要有数据都会触发,缓冲区剩余未读尽的数据会导致epoll_wait返回;
- LT比ET多了一个开关EPOLLOUT事件(系统调用消耗,上下文切换)的步骤;
- 对于监听的sockfd,最好使用水平触发模式(参考nginx),边缘触发模式会导致高并发情况下,有的客户端会连接不上,LT适合处理紧急事件;
- 对于读写的connfd,水平触发模式下,阻塞和非阻塞效果都一样,不过为了防止特殊情况,还是建议设置非阻塞;
- LT的编程与poll/select接近,符合一直以来的习惯,不易出错;
总之,各有优缺点,需要根据业务场景选择最合适的模式。
边缘触发与水平触发的区别(调用poll的区别)
拷贝句柄函数ep_send_events(epoll_wait调用ep_poll调用ep_scan_ready_list调用ep_send_events)会先遍历rdlist中每个句柄,对于每个句柄,再次调用poll获取实际事件(如缓冲区是否仍有数据):
- 如果与关心事件有交集:
如果句柄是水平触发(EPOLLLT),则再次把句柄加入到rdlist;否则从rdlist中删除
于是水平模式下次还会准备好,这就是EPOLLET 与 EPOLLLT的区别原理
- 如果与关心事件无交集,从rdlist中删除之
问题:如此一来看起来水平模式的句柄永远都不断重新加入rdlist,这就成永远都通知了吧?
当事件已经被处理完后(缓冲区无数据),调用poll得到的实际事件与关心事件已经无交集了,于是会被删除的!
ep_send_events函数内再次调用poll获取实际事件就是为了EPOLLLT模式而生的,防止其永远加入rdlist!
于是,EPOLLLT读事件 做到了只要有数据就不停通知,直到没数据就不再通知了
内核的相关注释
如果这个文件已经添加了 Level Trigger 模式,我们需要重新插入到就绪列表中,以便下次调用 epoll_wait() 将再次检查事件的可用性。 此时,除了我们之外,没有人可以插入到 ep->rdllist 中。 epoll_ctl() 调用者被持有“mtx”的 ep_scan_ready_list() 锁定,并且轮询回调会将它们排队在 ep->ovflist 中。
关键点
ET模式下只会检查一次事件(调用一次poll),而LT模式会一直调用poll直到 关心的事件结束
- ET —— 事件到来调用一次 poll
- LT —— 直到事件结束一直调用 poll
epoll_wait调用的ep_scan_ready_list
ep_scan_ready_list // 简化了逻辑
{
error = (*sproc)(ep, &txlist, priv); // 调用ep_send_events_proc(见下文),处理就绪链表
...
// 如果“就绪链表”上仍有未处理的epi,且有进程阻塞在epoll句柄的睡眠队列,则唤醒它!
if (!list_empty(&ep->rdllist)) {
/*
* Wake up (if active) both the eventpoll wait list and
* the ->poll() wait list (delayed after we release the lock).
*/
if (waitqueue_active(&ep->wq))
wake_up_locked(&ep->wq);
if (waitqueue_active(&ep->poll_wait))
pwake++;
}
}
ep_send_events_proc {
...
// 遍历“就绪链表”
ready_list_for_each() {
// 将epi从“就绪链表”删除
list_del_init(&epi->rdllink);
// 实际获取具体的事件。
// 注意,睡眠entry的回调函数只是通知有“事件”,具体需要每一个文件句柄的特定poll回调来获取。
revents = ep_item_poll(epi, &pt);
if (revents) { // 有感兴趣的事件
if (__put_user(revents, &uevent->events) ||
__put_user(epi->event.data, &uevent->data)) {
// 如果没有完成,则将epi重新加回“就绪链表”等待下次。
list_add(&epi->rdllink, head);
return eventcnt ? eventcnt : -EFAULT;
}
// 如果是LT模式,则无论如何都会将epi重新加回到“就绪链表”,等待下次重新再poll以确认是否仍然有未处理的事件。这也符合“水平触发”的逻辑,即“只要你不处理,我就会一直通知你”。
if (!(epi->event.events & EPOLLET)) {
list_add_tail(&epi->rdllink, &ep->rdllist);
}
}
}
...
}
epoll中EPOLLSHOT的使用
EPOLLSHOT的作用主要用于多线程中
epoll在某次循环中唤醒一个事件,并用某个工作进程去处理该fd,此后如果不注册EPOLLSHOT,在该fd时间如果工作线程处理的不及时,主线程仍会唤醒这个时间,并另派线程池中另一个线程也来处理这个fd。
为了避免这种情况,需要在注册时间时加上EPOLLSHOT标志,EPOLLSHOT相当于说,某次循环中epoll_wait唤醒该事件fd后,就会从注册中删除该fd,也就是说以后不会epollfd的表格中将不会再有这个fd,也就不会出现多个线程同时处理一个fd的情况。
对于主线程,主线程的职责在于:
- a).主线程负责epoll循环
- b).当当前唤醒的事件fd为监听套接字时,由主线程来转换套接字,在转换套接字的过程中,主线程的epoll循环是处于停顿的,因为listenfd的工作线程实际上就是主线程,因此对于listenfd不需要注册EPOLLONESHOT,因为在listenfd上工作时主线程的epoll处于停顿,不会出现多个线程同时处理listenfd的情况。同时,在将监听套接字转换为套接字connfd后,将connfd注册进入epoll,此时需要附加上EPOLLONESHOT标志,因为对connfd的处理是由工作线程来处理的,要保证同时只有一个线程在处理某个fd。
- c).当当前唤醒的时间fd为非监听套接字时,将该fd的处理push进去生产者消费者模型的队列中,待工作线程处理。
对于工作线程:
- a).当前工作线程工作未完成,如在EPOLLIN中读出数据后。对于整个工作流程来说,读出数据只是工作的一半,还需要将处理后的数据写到对端,但由于注册了EPOLLONESHOT,EPOLLIN的事件被唤醒后该fd已经从epollfd中删去,所以对于尚未完成的工作,要重新注册,比如这里,重新注册fd为EPOLL|EPOLLET|EPOLLONESHOT。EPOLLONESHOT是必须的,因为要保证向对端写入时只有一个线程在该fd上工作。
- b).当前工作线程已经完成,此时该fd已经无意义,因此将该fd从epollfd中remove掉。
Epoll 新增 EPOLLEXCLUSIVE 选项解决了新建连接的’惊群‘问题
EPOLLEXCLUSIVE —— 只唤醒一个等待源, 从而避免’惊群‘.
参考
http://t.zoukankan.com/sduzh-p-6793879.html
https://blog.csdn.net/linkedin_38454662/article/details/73337208
https://mp.weixin.qq.com/s?__biz=MzkyMTIzMTkzNA==&mid=2247588131&idx=1&sn=76b175bd8fd2f8b3885366278ce5100b&chksm=c1856e72f6f2e764c2d6760e905ccd3de2c8756fb03fb52f84733d4d141b689e86ddcb8d588b&token=545738495&lang=zh_CN#rd
https://mp.weixin.qq.com/s?__biz=MzkyMTIzMTkzNA==&mid=2247563937&idx=2&sn=ae50d7fe2997b4609cb749d3fa1c3d6f&chksm=c1850df0f6f284e64767e787734bc53ef3234c68749566f2fcb04478a3778ecfd890cca752ef&token=545738495&lang=zh_CN#rd
https://blog.csdn.net/weixin_42096901/article/details/103011968
https://mp.weixin.qq.com/s?__biz=MzkyMTIzMTkzNA==&mid=2247538107&idx=1&sn=74e33ca006146d079168f5efb8d6a073&chksm=c184a2eaf6f32bfc9c35b51a4b8300ff83ba1d4ab2751bf26232a645ff4cc411a767d9477fe1&scene=178&cur_album_id=1843108380194750466#rd
https://blog.csdn.net/mumumuwudi/article/details/50552470
[reuseport使用](















 326
326











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









