







在现代心理健康研究中,抑郁症一直是一个备受关注的课题。随着科学的进步,研究人员逐渐认识到,抑郁症的成因远不止单一因素,而是由复杂的生物学、心理学和社会环境因素交织而成的。最近,MSA(综合性综合性模型)在揭示抑郁症机制上展现了惊人的潜力。通过多维度的分析,MSA模型为我们提供了一个全新的视角,让我们能够更深入地理解抑郁症的根源、影响以及可能的干预措施。在这篇文章中,我们将深入探讨MSA模型如何重新定义我们对抑郁症的认识,并展示它在临床实践中的潜在应用。这不仅是对抑郁症研究的全面总结,更是对未来心理健康干预的一次前瞻性展望。
目录
概述
随着社交网络的不断发展,近年来出现了多模态数据的热潮。越来越多的用户采用媒体形式的组合(例如文本加图像、文本加歌曲、文本加视频等)。来表达他们的态度和情绪。多模态情感分析(MSA)是从多模态信息中提取情感元素进行情感预测的一个热门研究课题。传统的文本情感分析依赖于词、短语以及它们之间的语义关系,不足以识别复杂的情感信息。随着面部表情和语调的加入,多模态信息(视觉、听觉和转录文本)提供了更生动的描述,并传达了更准确和丰富的情感信息。
此外,随着近些年来生活压力的增加,抑郁症已成为现代工作环境中最常见的现象。早期发现抑郁症对避免健康恶化和防止自杀倾向很重要。无创监测应激水平在筛查阶段是有效的。许多基于视觉提示、音频馈送和文本消息的方法已用于抑郁倾向监测。
我致力于对情感计算领域的经典模型进行分析、解读和总结,此外,由于现如今大多数的情感计算数据集都是基于英文语言开发的,我们计划在之后的整个系列文章中将中文数据集(SIMS, SIMSv2)应用在模型中,以开发适用于国人的情感计算分析模型,并应用在情感疾病(如抑郁症、自闭症)检测任务,为医学心理学等领域提供帮助,此外还加入了幽默检测数据集,在未来,我也计划加入更多小众数据集,以便检测更隐匿的情感,如嫉妒、嘲讽等,使得AI可以更好的服务于社会。
本篇文章开始,我计划使用连载的形式对经典的情感计算模型进行讲解、对比和复现,并开发不同数据集进行应用。并逐步实现集成,以方便各位读者和学者更深度地了解Multimodal Sentiment Analysis (MSA)以及他的研究重点和方向,为该领域的初学者尽量指明学习方向方法。
近年来,多模态情感分析和抑郁检测是利用多模态数据预测人类心理状态的两个重要研究课题;多模态情感分析(MSA)和抑郁症检测(DD)引起了越来越多的关注。与单模态分析相比,多模态模型在处理社交媒体数据时更鲁棒,并取得了显着的改进。随着用户生成的在线内容的蓬勃发展,MSA已被引入许多应用,如风险管理,视频理解和视频转录。
其中,表征学习是多模态学习中一项重要而又具有挑战性的任务。有效的模态表征应包含两个方面的特征:一致性和差异性。由于统一的多模态标注,现有方法在捕获区分信息方面受到限制。然而,额外的单峰注解是高时间和人力成本的。本文设计了一个基于自监督学习策略的标签生成模块,以获得独立的单峰监督。然后,对多模态任务和单模态任务分别进行联合训练,以了解其一致性和差异性。此外,在训练阶段,作者设计了一个权重调整策略,以平衡不同子任务之间的学习进度。即引导子任务集中于模态监督之间差异较大的样本。
核心逻辑
多模态情感分析和抑郁症利用多模态信号(包括文本ItIt、音频IaIa和视觉IvIv)来判断情感。一般来说,MSA和DD可以被视为回归任务或分类任务。在这项工作中,我们把它作为回归任务。因此,Self-MM将ItIt、IaIa和IvIv作为输入,并输出一个情感强度和抑郁程度结果y^m∈Ry^m∈R。在训练阶段,为了辅助表示学习,Self-MM具有额外的三个单峰输出,其中s∈{t,a,v}s∈{t,a,v},虽然有多个输出,但我们只使用最后的预测结果。
下图为模型整体结构图;如图所示,Self-MM由一个多模态任务和三个独立的单峰子任务组成。在多模态任务和不同的单峰任务之间,作者采用硬共享策略来共享底层表征学习网络。我们将整个模型运行分为3部分讲解:多模态任务,单模态任务,ULGM模块;接下来我们将分别进行详细介绍:
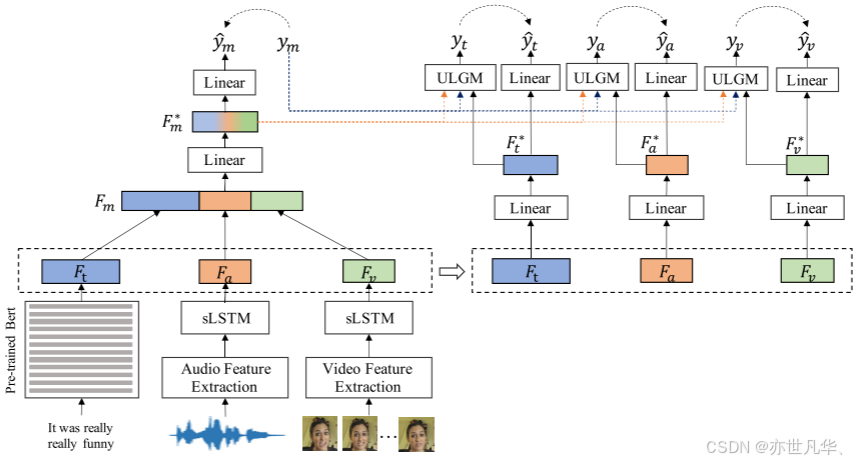
多模态任务:对于多模态任务,本文采用了经典的多模态情感分析架构。它包括三个主要部分:特征表示模块,特征融合模块和输出模块。在文本模态方面,由于预训练的语言模型取得了很大的成功,使用了预训练的12层BERT来提取句子表示。根据经验,最后一层中的第一个词向量被选择作为整句表示。对于音频和视觉模式,使用预训练的ToolKits从原始数据中提取初始向量特征 Ia∈Rla×daIa∈Rla×da 和 Iv∈Rlv×dvIv∈Rlv×dv。这里,la和lv分别是音频和视频的序列长度。然后,使用单向长短期记忆(sLSTM)来捕获时序特性。最后,采用端态隐向量作为整个序列的表示。然后,我们将所有的单峰表示连接起来,并将它们投影到低维空间 RdmRdm 中,最后,融合表示 Fm∗Fm∗ 用于预测多模态情感。
单模式任务:对于三个单模态任务,他们共享多模态任务的模态表征。为了减少不同模态之间的维数差异,作者将它们投影到一个新的特征空间中。然后,用线性回归得到单峰结果。为了指导单峰任务的训练过程,作者设计了一个单峰标签生成模块(ULGM)来获取标签。ULGM的详细信息在下一节讲解,最后,在m-labels和u-labels监督下,通过联合学习多模态任务和三个单峰任务。值得注意的是,这些单峰任务只存在于训练阶段。因此,我们使用 y^my^m作为最终输出。
下面是单模态特征处理子网络的代码:
# text subnets
self.aligned = args.need_data_aligned
self.text_model = BertTextEncoder(use_finetune=args.use_finetune, transformers=args.transformers, pretrained=args.pretrained)
# audio-vision subnets
audio_in, video_in = args.feature_dims[1:]
self.audio_model = AuViSubNet(audio_in, args.a_lstm_hidden_size, args.audio_out, \
num_layers=args.a_lstm_layers, dropout=args.a_lstm_dropout)
self.video_model = AuViSubNet(video_in, args.v_lstm_hidden_size, args.video_out, \
num_layers=args.v_lstm_layers, dropout=args.v_lstm_dropout)ULGM:ULGM旨在基于多模态注释和模态表示生成单模态监督值。为了避免对网络参数更新造成不必要的干扰,将ULGM设计为非参数模块。通常,单峰监督值与多峰标签高度相关。因此,ULGM根据从模态表示到类中心的相对距离计算偏移,如下图所示:
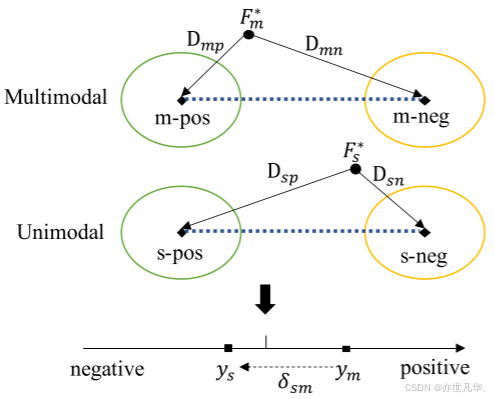
Relative Distance Value:由于不同的模态表示存在于不同的特征空间中,因此使用绝对距离值不够准确。因此,我们提出了相对距离值,它与空间差异无关。
下面为ULGM模块的实现过程,包括单模态分类器的实现:
# fusion
fusion_h = torch.cat([text, audio, video], dim=-1)
fusion_h = self.post_fusion_dropout(fusion_h)
fusion_h = F.relu(self.post_fusion_layer_1(fusion_h), inplace=False)
# # text
text_h = self.post_text_dropout(text)
text_h = F.relu(self.post_text_layer_1(text_h), inplace=False)
# audio
audio_h = self.post_audio_dropout(audio)
audio_h = F.relu(self.post_audio_layer_1(audio_h), inplace=False)
# vision
video_h = self.post_video_dropout(video)
video_h = F.relu(self.post_video_layer_1(video_h), inplace=False)
# classifier-fusion
x_f = F.relu(self.post_fusion_layer_2(fusion_h), inplace=False)
output_fusion = self.post_fusion_layer_3(x_f)
# classifier-text
x_t = F.relu(self.post_text_layer_2(text_h), inplace=False)
output_text = self.post_text_layer_3(x_t)
# classifier-audio
x_a = F.relu(self.post_audio_layer_2(audio_h), inplace=False)
output_audio = self.post_audio_layer_3(x_a)
# classifier-vision
x_v = F.relu(self.post_video_layer_2(video_h), inplace=False)
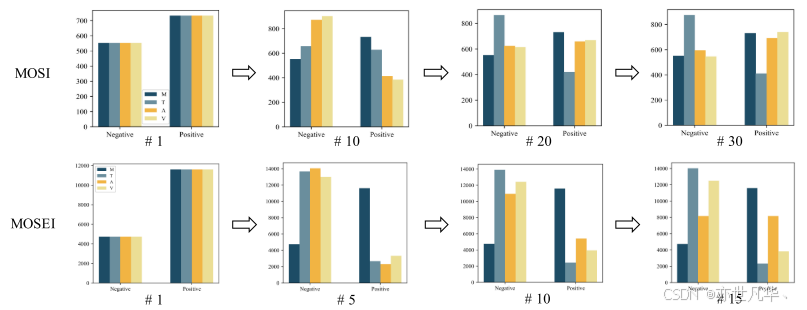
output_video = self.post_video_layer_3(x_v)下图为u-标签在不同数据集上的分布更新过程。每个子图像下的数字(#)指示时期的数量:
复现过程
在准备好数据集并调试代码后,进行下面的步骤,附件已经调通并修改,可直接正常运行,下载多模态情感分析集成包,并进行训练:
pip install MMSA
$ python -m MMSA -d mosi/dosei/avec -m lmf -s 1111 -s 1112SELF-MM模型是一种多模态情感分析解决方案,结合了文本、音频和视觉信息,并利用自我监督学习策略来学习各模态的特定表示。这种方法使得模型在缺乏大量标注数据的情况下仍能有效地提取多模态信息,从而进行情感分析及其他复杂的情感理解任务。项目提供了预处理的数据集及相关下载链接,包括音频特征、文本特征和视频特征等,SELF-MM模型适用于多种情感分析场景,如社交媒体监控、视频对话理解和电影评论分析。通过同时分析文本、语音和视觉信息,该模型能够深入理解多模态输入,从而提升用户体验和交互性。
1)高效的学习策略:采用自我监督多任务学习方法,无需大量标注数据即可学习到模态特定的表示。
2)全面的模态支持:模型能够处理文本、音频和视觉信息,充分考虑了多模态输入的特性。
3)易于使用的接口:项目提供清晰的代码结构和详细的配置文件,用户可以根据自己的数据路径进行设置,支持主流的预训练BERT模型的转换和应用。
4)广泛的应用范围:不仅局限于情感分析,还可扩展至其他多模态任务,如情感理解、情感生成等。
通过这些特点,SELF-MM模型不仅能提升情感分析的准确性和效率,还为多模态任务的研究和应用提供了强大的工具和支持。
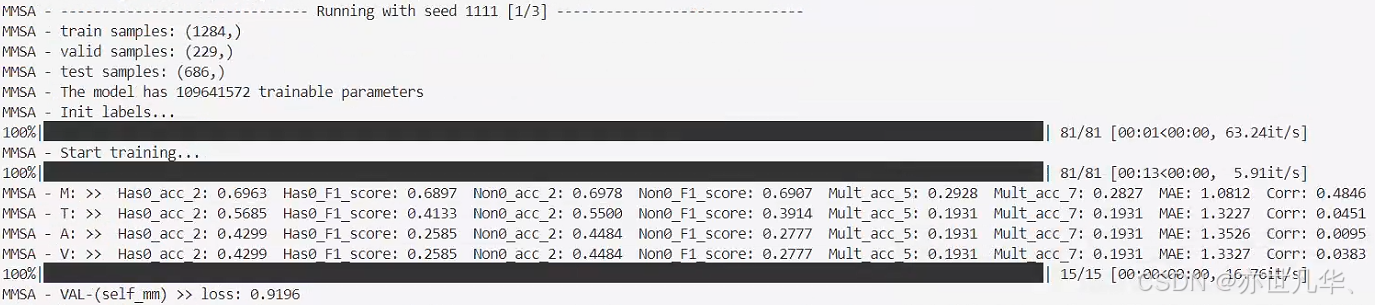
训练过程与最终结果如下:

写在最后
在探索MSA+模型对抑郁症的深刻见解的旅程中,我们不仅揭示了疾病的复杂性,还找到了应对和治疗的崭新思路。MSA+模型通过将生物、心理和社会因素融入一个综合框架,挑战了传统单一因素的理解方式,为我们描绘了一幅更为全面的抑郁症图景。它让我们意识到,抑郁症不仅仅是神经化学的失衡,而是一个多层次、多维度的互动过程。
通过MSA+模型,我们不仅能够更准确地识别抑郁症的风险因素,还能在个体化治疗方案上取得突破。其创新性的整合方式,为我们提供了一种全新的思考路径,激发了对未来研究和治疗的无限可能。这种综合视角不仅有助于我们更好地理解抑郁症的多样性,还推动了个体化和精准医学的发展。
总之,MSA+模型的应用标志着心理健康领域的一个重要进步。它不仅为我们提供了新的研究工具,也为临床实践注入了新的希望。未来,我们有理由相信,通过不断探索和应用这一模型,我们将能够在抑郁症的预防、诊断和治疗上取得更大的突破,从而为那些受困于抑郁症的患者带来真正的改变与希望。
详细复现过程的项目源码、数据和预训练好的模型可从地址获取。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











