







短期电力负荷的预测和管理,直接影响到电力供应的安全性、经济性和环境友好性。本文将深入探讨短期电力负荷的概念、影响因素以及当前的预测方法,旨在为读者提供一个全面的理解,并探讨未来的发展方向。
本文所涉及所有资源均在地址可获取
目录
概述
在电力负荷预测中,由于数据的高维性和波动性,传统的特征提取方法往往难以捕捉到负荷数据中的复杂模式和关系,短期电力负荷预测(STLF),即对未来几小时到几周的电力负荷进行准确预测。
来自《IEEE Transactions on Smart Grid》2022年7月的13卷第4期,《IEEE Transactions on Smart Grid》在中科院升级版中,大类工程技术位于1区,小类工程:电子与电气位于1区,非综述类期刊,作者包括IEEE会员Nakyoung Kim、IEEE学生会员Hyunseo Park、IEEE高级会员Joohyung Lee,以及IEEE高级会员Jun Kyun Choi,其论文地址如下:

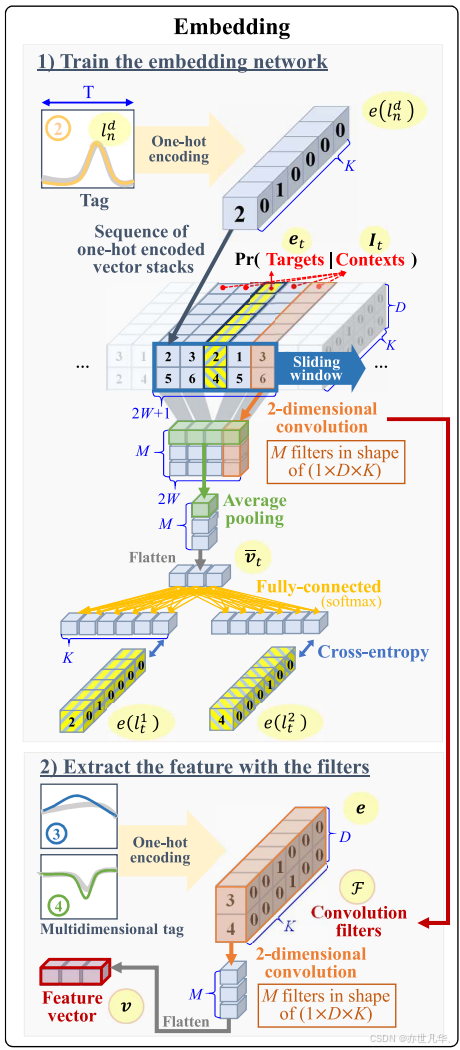
本论文通过提出一个名为MultiTag2Vec的特征提取框架来解决短期电力负荷预测(STLF)中的特征工程问题,该框架包括两个主要过程:标记(tagging)和嵌入(embedding),如下:
1)标记过程:首先,通过从高维时间序列数据中提取关键信息,将电气负荷数据转换成紧凑形式。这一步通过聚类子序列来发现重复出现的模式,并为每个模式分配唯一的标签,从而实现数据的标记。
2)嵌入过程:接下来,通过学习标签序列中的时间和维度关系来提取特征。为了捕捉这些关系,提出了一个带有卷积层的网络模型,该模型采用数学分析设计的多输出结构。通过训练,可以从任何任意多维标签中提取特征。
核心逻辑
本次论文复现的核心逻辑是对多维时间序列数据进行分段、聚类和标记,以提取和识别数据中的模式。下面是各部分的具体功能:
时间序列分段(segment_time_series):
输入为多维时间序列 X 和每段的长度 T,将时间序列分为多个长度为 T 的子序列,返回的结果是一个形状为 (N_segment, T, D) 的数组,其中 N_segment 是子序列的数量,D 是维度数。
模式发现(discover_patterns):
输入为分段后的子序列 segments 和聚类数量K,对每个维度进行 K-means 聚类,提取出每个维度的聚类中心(模式),返回一个形状为 (D, K, T) 的数组,表示每个维度的 K 个模式。
数据标记(tag_data):
输入为分段后的子序列 segments 和聚类中心 patterns,为每个子序列分配标签,标签是指与聚类中心距离最近的那个中心的索引。输出为一个形状为 (N_segment, D) 的标签数组,表示每个子序列在每个维度上的标记。
综上所述,代码的主要目的是将时间序列数据转化为可处理的形式,通过聚类分析识别潜在模式,并为每个子序列分配标签,便于后续分析或应用。
代码实现
多维特征提取的提取框架,实现时间序列切分,聚类,打标签如下:
def segment_time_series(X, T):
"""
将时间序列 X 分段为长度为 T 的子序列。
X: 多元时间序列 (N x D), N 为时间序列长度, D 为维度数
T: 每个子序列的长度
返回: 分段后的子序列集合,形状为 (N_segment, T, D)
"""
N, D = X.shape
N_segment = N // T # 计算分段后的子序列数量
segments = np.array([X[i*T:(i+1)*T] for i in range(N_segment)])
return segments
# 2. 模式发现
def discover_patterns(segments, K):
"""
对分段后的子序列进行聚类,提取模式。
segments: 分段后的子序列集合, 形状为 (N_segment, T, D)
K: 聚类的数量,即模式的数量
返回: 每个维度的模式集合,形状为 (K, T, D)
"""
N_segment, T, D = segments.shape
patterns = []
# 对每个维度单独进行聚类
for d in range(D):
# 提取第 d 个维度的所有子序列
data_d = segments[:, :, d] # 形状为 (N_segment, T)
# 使用 KMeans 进行聚类
kmeans = KMeans(n_clusters=K, random_state=42)
kmeans.fit(data_d)
# 保存聚类中心(模式)
patterns.append(kmeans.cluster_centers_)
# patterns 为 D 维的聚类中心集合,形状为 (D, K, T)
return np.array(patterns)
# 3. 数据标记
def tag_data(segments, patterns):
"""
对每个子序列打标签,标签为距离最近的聚类中心。
segments: 分段后的子序列集合, 形状为 (N_segment, T, D)
patterns: 每个维度的聚类中心集合,形状为 (D, K, T)
返回: 每个子序列的标签集合,形状为 (N_segment, D)
"""
N_segment, T, D = segments.shape
K = patterns.shape[1] # 模式的数量
labels = np.zeros((N_segment, D), dtype=int)
# 对每个维度进行标记
for d in range(D):
for i in range(N_segment):
# 计算当前子序列与所有聚类中心的距离
distances = np.linalg.norm(segments[i, :, d] - patterns[d], axis=1)
# 选择最小距离的聚类中心的标签
labels[i, d] = np.argmin(distances)
return labels嵌入网络定义:
class EmbeddingNetwork(nn.Module):
def __init__(self, D, K, M):
super(EmbeddingNetwork, self).__init__()
# 卷积层,用于提取输入张量的特征
self.conv = nn.Conv2d(in_channels=最后总结
短期电力负荷的管理不仅是电力行业的一项技术挑战,更是实现可持续发展的关键所在。随着可再生能源的崛起和智能电网技术的不断进步,未来的电力系统将更加灵活和高效。在面对气候变化、能源转型等全球性问题时,优化短期负荷预测和调度,将为电力行业开辟新的机遇与挑战。
想象一下,在不久的将来,智能系统能够实时分析并调节电力需求,帮助我们减少浪费、降低成本,同时保护我们的环境。通过不断探索和创新,我们可以构建一个更加智能、可靠且可持续的电力未来。这不仅关乎科技进步,更关乎我们每一个人的生活。让我们共同期待并参与这一变革的浪潮吧!
详细复现过程的项目源码、数据和预训练好的模型可从该文章下方附件获取。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











