







目录
新增数据
单条插入
单条插入:单条插入的话我们一般常用的方法有以下几种,这里我就以异步方式为主,其实插入数据的同时可以根据自己选择的函数返回对应想要的数据,如下:
//返回插入行数
await db.Insertable(insertObj).ExecuteCommandAsync()
//插入返回自增列 (实体除ORACLE外实体要配置自增,Oracle需要配置序列)
await db.Insertable(insertObj).ExecuteReturnIdentityAsync();
// 返回雪花ID
long id= db.Insertable(实体).ExecuteReturnSnowflakeId();
// 实用技巧:
var dbTime = db.GetDate(); // 获取数据库时间
db.Insertable(insertObj).AS("table01").ExecuteCommand(); // 强制设置表名(默认表名来自实体) 这里我们参考上一篇文章:地址 创建好Code First操作之后,在入口文件处直接注册连接数据库的服务,然后启动时调用创建表方法,就可以根据我们设置的实体类创建对应的数据库表:
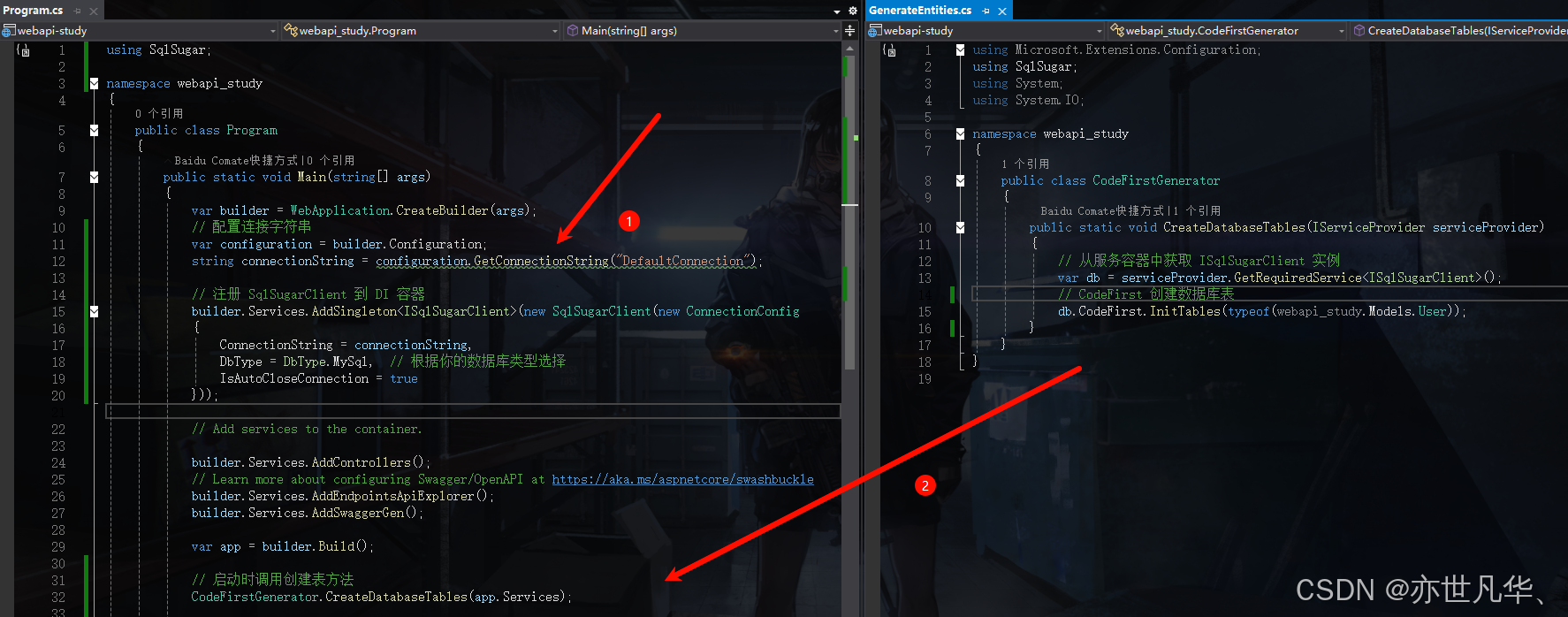
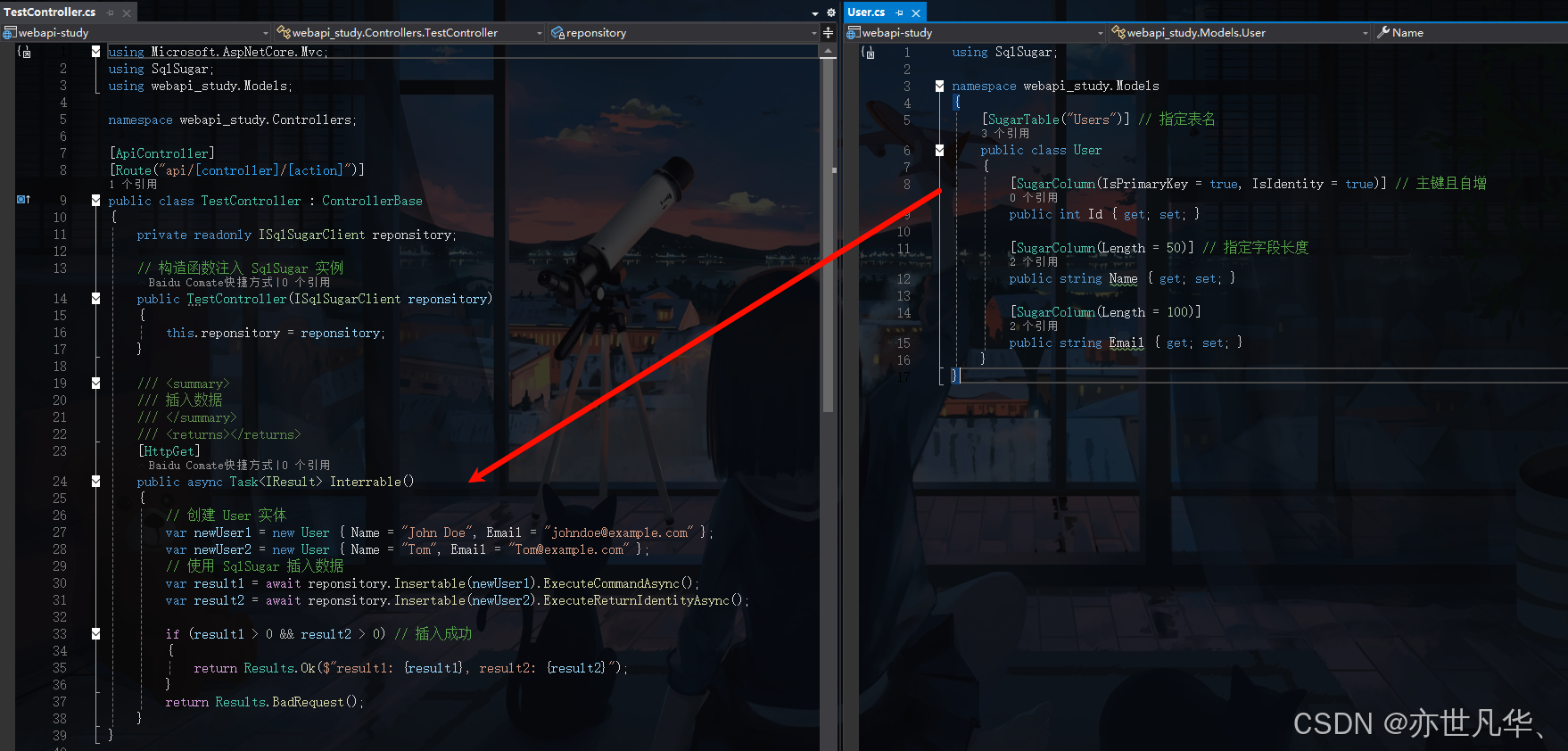
然后这里我们就根据我们创建的实体类构建两个实体,然后调用Insertable函数进行插入操作,然后通过后面两个函数来实现插入的同时获取对应的数据,且一定要带上不然报错了:
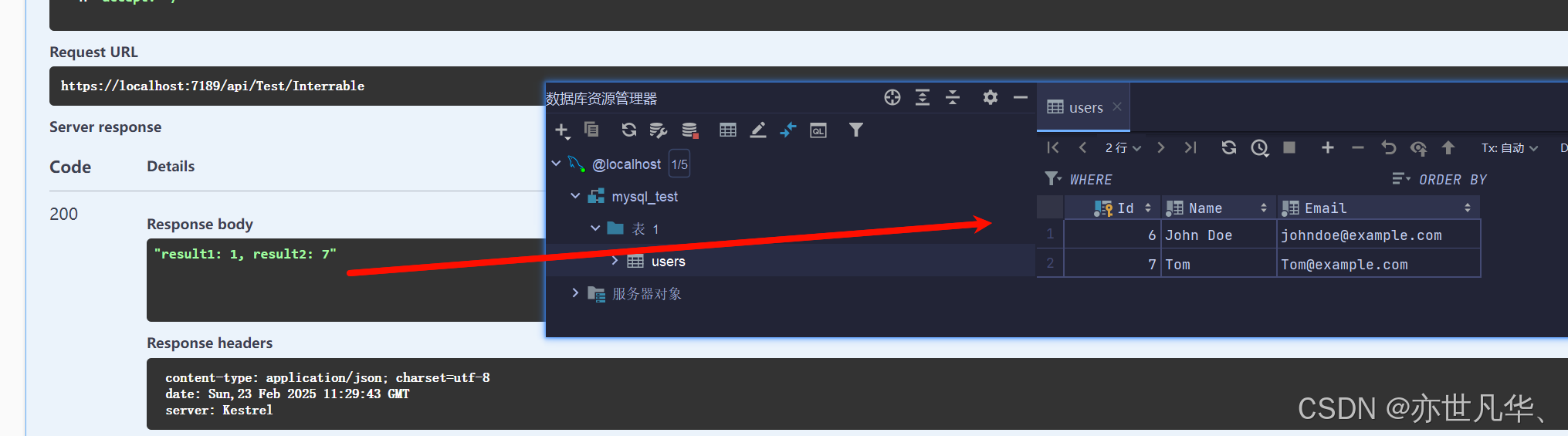
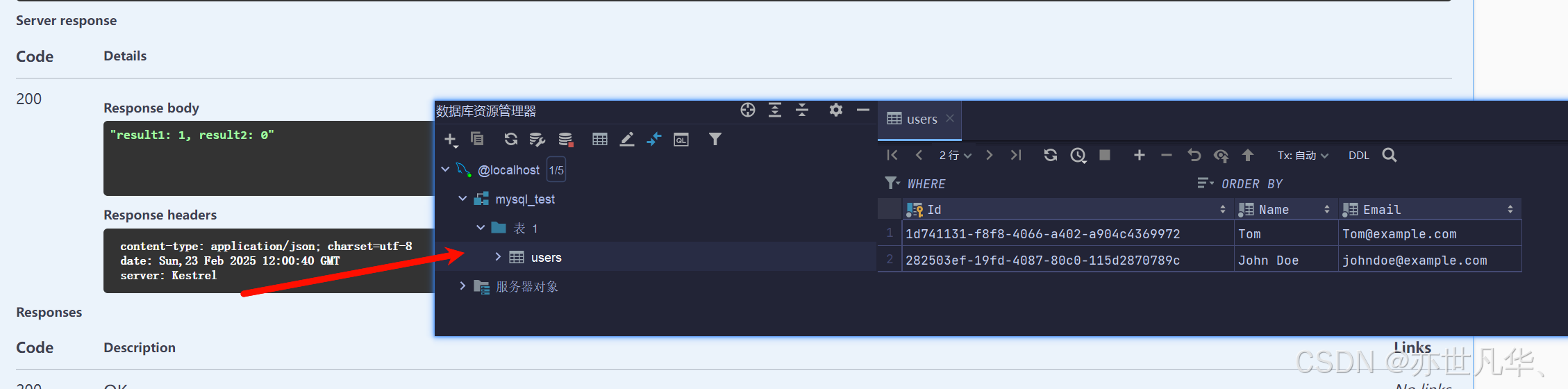
调用接口之后可以看到我们已经成功插入数据了,result1: 1, result2: 7分别表示插入的行数已经对应的主键,如下图所示:
雪花ID(Snowflake ID):是一种分布式系统中生成唯一ID的算法,最初由Twitter开发旨在解决高并发系统中生成唯一ID的问题,其核心思想是将一个64位的整数拆分为多个部分,其中每部分有不同的用途,这使得雪花ID不仅具有全局唯一性还能保证ID的有序性便于进行排序和分区,雪花ID通常由以下几个部分组成:

1)时间戳(41位):表示生成ID时的时间,通常是当前时间减去某个固定的起始时间戳(一般使用毫秒为单位)这样能确保ID是递增的
2)机器ID(10位):表示生成ID的机器或服务器的标识,通常用于标识不同的数据中心或不同的机器为了支持更高的并发机器ID的位数可能根据需求有所变化
3)数据中心ID(5位,选择性):有些版本的雪花ID算法还会将数据中心ID加入到ID中用于支持分布式数据中心部署
4)序列号(12位):在同一毫秒内生成多个ID时通过序列号来区分这些ID,它的最大值为4095(2^12 - 1)意味着在同一毫秒内最多能生成4096个唯一ID
雪花ID适用于分布式、高并发、时序性强的场景,尤其是需要生成有序ID并且要求高性能的情况,常见的应用场景包括高并发网站、分布式服务等;而另一个常用的GUID则适用于全局唯一性要求较强且不关心时序性场景,通常用于需要标识会话、跨系统唯一标识的情况,这里我们拿GUID为例,如下我们创建Id的时候通过Guid设置其为主键:
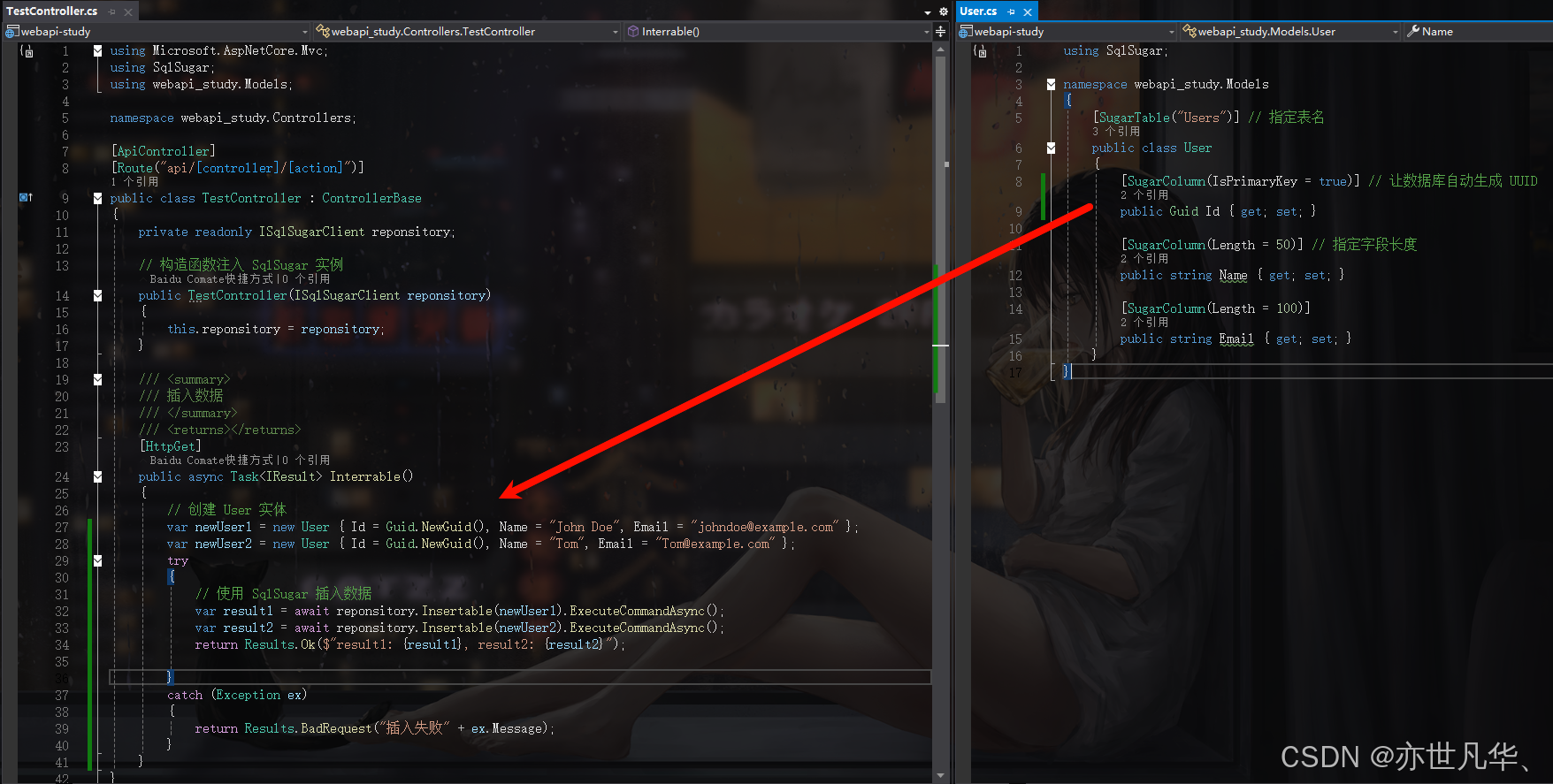
在实际开发中雪花ID更常用于大规模的分布式系统特别是在数据库和日志系统中,而GUID则更多用于较为简单的需要跨系统唯一标识的应用,如下可以看到我们插入的数据已经使用Guid为主键:
批量插入
批量插入:批量插入的话我们一般常用的方法有以下几种,这里我就以异步方式为主,其实批量插入数据的同时可以根据自己选择的函数返回对应想要的数据,如下:
// 参数化内部分页插入(底层是分页插入)
//优点:适合插入条数固定,并且条数较少,请求频繁高的功能(最大利用执行计划缓存)
//缺点:个别库500以上就开始慢了,要加事务才能回滚
db.Insertable(List<实体>).UseParameter().ExecuteCommandAsync();
// 非参数化插入(防注入)
//优点:综合性能比较平均,列少1万条也不慢,属于万金油写法,不加事务情况下部分库有失败回滚机质
//缺点:数据量超过5万以上占用内存会比较大些,内存小可以用下面2种方式处理
db.Insertable(List<实体>).ExecuteCommandAsync();
// 大数据写入(特色功能:大数据处理上比所有框架都要快30%)
//优点:1000条以上性能无敌手
//缺点:不支持数据库默认值API功能简单,小数据量并发执行不如普通插入,插入数据越大越适合用这个
db.Fastest<实体>().PageSize(100000).BulkCopyAsync(List<实体>);
// 从一个表导入到另一个表
//优点:性能好
//缺点:数据必须在数据库已存在,才能这样插入到新表
// 1) 不同实体插入
db.Queryable<Order>()
//.IgnoreColumns(it=>it.Id) 如果是自增可以忽略,不过ID就不一样了
.Select(it=>new { name=it.name,......})
.IntoTable<实体2>();
// 2) 同实体不同表插入
db.Queryable<Order>()
//.IgnoreColumns(it=>it.Id) 如果是自增可以忽略,不过ID就不一样了
.IntoTable<Order>("新表名"); 万金油写法:这里我们拿常用的万金油写法来演示一下批量插入的操作,代码如下这里我们创建一个List列表,然后循环往列表中插入数据,最后通过一个时间定时器来监听最终插入所有数据的耗时,如下:
/// <summary>
/// 插入数据
/// </summary>
/// <returns></returns>
[HttpGet]
public async Task<IResult> Interrable()
{
var userList = new List<User>();
for (int i = 0; i < 1000; i++)
{
var user = new User();
user.Id = Guid.NewGuid();
user.Name = $"Name{i}";
user.Email = $"Email{i}@example.com";
userList.Add(user);
}
try
{
// 时间定时器,来监听插入耗时
var stopwatch = new Stopwatch();
stopwatch.Start();
await reponsitory.Insertable(userList).ExecuteCommandAsync();
stopwatch.Stop();
return Results.Ok($"插入成功,耗时:{stopwatch.ElapsedMilliseconds}ms");
}
catch (Exception ex)
{
return Results.BadRequest("插入失败" + ex.Message);
}
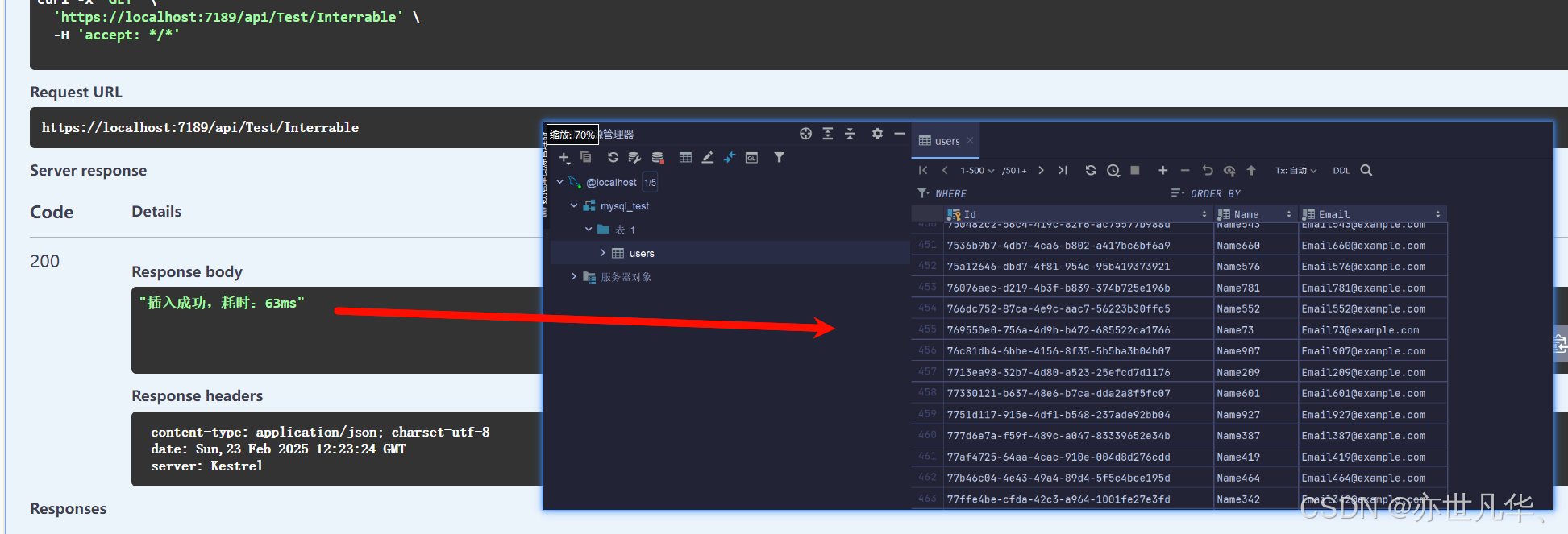
}可以看到最终插入完数据所需要的最终耗时也不过63毫秒,可谓是一瞬间就完成数据的插入:
大数据批量插入:这边如果我们想进行大批量数据插入的话,需要先确保自己的数据库能否支持大批量数据插入,并且自己的连接字符串的命令需要添加上AllowLoadLocalInfile=true来开启大量数据插入操作,如下所示:
server=localhost;database=mysql_test;user id=root;password=123456;AllowLoadLocalInfile=true;如果修改连接字符串后仍然报错,你可能需要在MySQL服务器端启用local_infile选项,可以通过执行以下SQL命令来启用:
SET GLOBAL local_infile = 1;然后这里我们就开始使用大批量数据插入的操作,往数据库中插入100w条数据
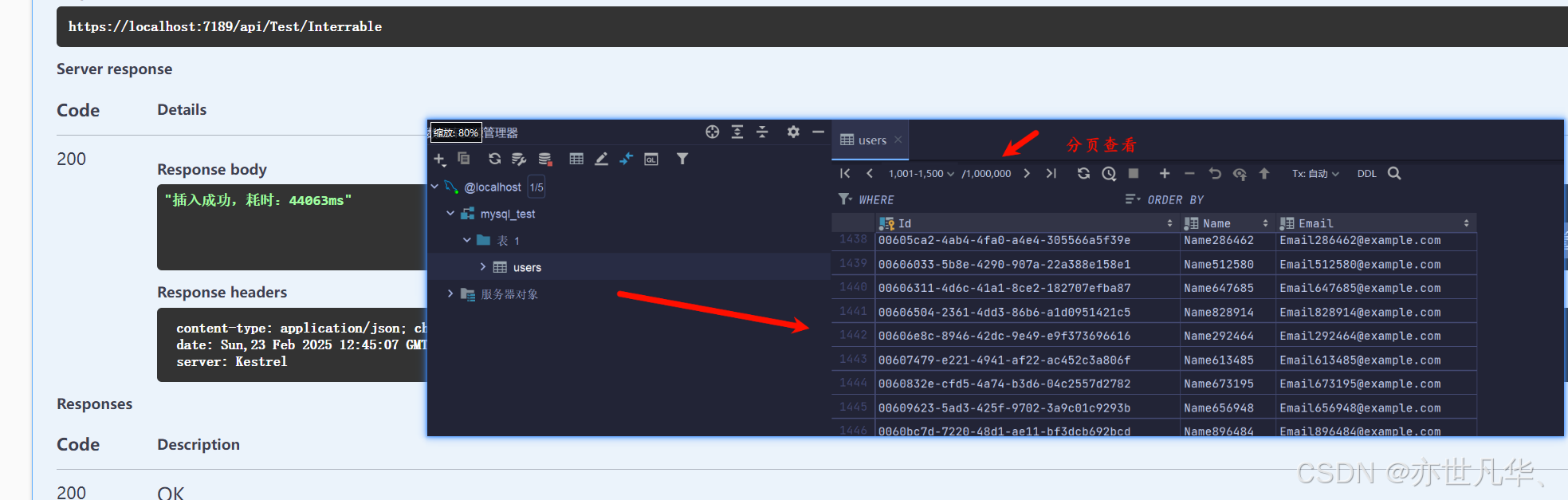
如下可以看到我们的百万条数据已经成功被插入了,耗时的话是44063ms:
分页插入
分页插入:如果想进行大批量数据的插入,并且想避免一次性负载过重可以用分页插入慢慢处理,如下所示:
/// <summary>
/// 插入数据
/// </summary>
/// <returns></returns>
[HttpGet]
public async Task<IResult> Interrable()
{
var userList = new List<User>();
for (int i = 0; i < 1000000; i++)
{
var user = new User();
user.Id = Guid.NewGuid();
user.Name = $"Name{i}";
user.Email = $"Email{i}@example.com";
userList.Add(user);
}
try
{
// 时间定时器,来监听插入耗时
var stopwatch = new Stopwatch();
stopwatch.Start();
await reponsitory.Fastest<User>().BulkCopyAsync(userList);
//await reponsitory.Insertable(userList).PageSize(1000).ExecuteCommandAsync();//普通分页
await reponsitory.Fastest<User>().PageSize(100000).BulkCopyAsync(userList);//大数据分页
stopwatch.Stop();
return Results.Ok($"插入成功,耗时:{stopwatch.ElapsedMilliseconds}ms");
}
catch (Exception ex)
{
return Results.BadRequest("插入失败" + ex.Message);
}
}虽然分页插入每次只处理较小的批量数据,避免一次性将所有数据加载到内存中降低内存压力,但是每次只处理较小的批量数据分页插入需要管理多个事务,每次插入完成后都需要提交一个事务这比单次大批量插入的事务开销更大,由于每次只插入小批量数据每次插入都会触发与数据库的 I/O 操作这也可能会增加总的耗时,如下:
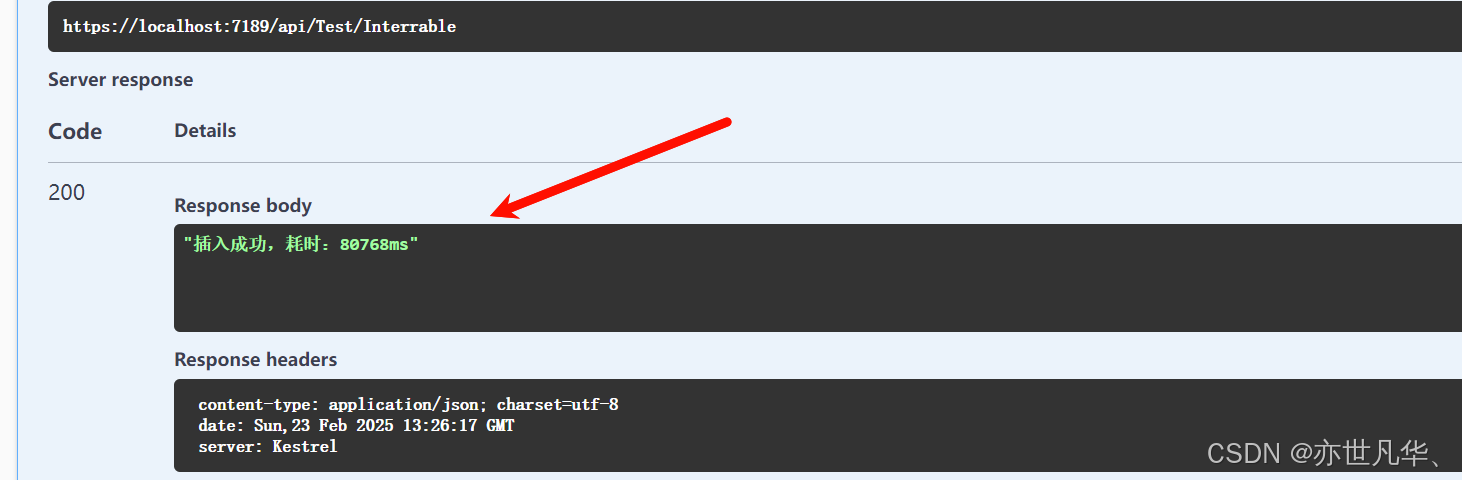
删除数据
删除数据:删除数据的话我们一般常用的方法有以下几种,其实单条与批量删除数据的同时可以根据自己选择的函数返回对应想要的数据,如下:
// 单个删除
db.Deleteable<Student>(new Student() { Id = 1 }).ExecuteCommand();
// 批量删除
db.Deleteable<Student>(list).ExecuteCommand();
// 批量删除+分页
db.Deleteable<Order>(list).PageSize(500).ExecuteCommand();
// 联表删除
db.Deleteable<Student>().Where(p => SqlFunc.Subqueryable<School>().Where(s => s.Id == p.SchoolId).Any()).ExecuteCommand()
// 逻辑删除(实体属性有isdelete或者deleted)进行软删除
db.Deleteable<LogicTest>().In(100).IsLogic()
.ExecuteCommand("deleted",true);这里我们拿软删除举例,首先我们先给我们的实体类添加对应的软删除字段:
namespace webapi_study.Models
{
[SugarTable("Users")] // 指定表名
public class User
{
[SugarColumn(IsPrimaryKey = true)] // 让数据库自动生成 UUID
public Guid Id { get; set; }
[SugarColumn(Length = 50)] // 指定字段长度
public string Name { get; set; }
[SugarColumn(Length = 100)]
public string Email { get; set; }
[SugarColumn(ColumnDataType = "bit", IsNullable = true)]
public bool? Deleted { get; set; } = false;
}
}然后我们借助软删除的函数指定我们要进行软删除的数据,将软删除的字段更改为true:
/// <summary>
/// 删除数据
/// </summary>
[HttpGet]
public async Task<IResult> Delete()
{
try
{
// 删除所有用户,实际应用中请谨慎操作
await reponsitory.Deleteable<User>().In("01acd349-d773-4e7f-909b-5e7216b0b123").IsLogic().ExecuteCommandAsync("deleted", true);
return Results.Ok("删除成功");
}
catch (Exception ex)
{
return Results.BadRequest("删除失败: " + ex.Message);
}
}最终呈现的效果如下所示:

修改数据
单条与批量更新
单条与批量更新:单条与批量更新的话我们一般常用的方法有以下几种,这里我就以异步方式为主,其实单条与批量更新数据的同时可以根据自己选择的函数返回对应想要的数据,如下:
// 根据主键更新单条
var result= db.Updateable(updateObj).ExecuteCommandAsync();//实体有多少列更新多少列
// 按需更新
db.Tracking(updateObj);//创建跟踪
updateObj.Name = "a1" + Guid.NewGuid();//只改修改了name那么只会更新name
db.Updateable(updateObj).ExecuteCommandAsync();//因为每条记录的列数不一样,批量数据多性能差,不建议用
db.Updateable(updateObj).UpdateColumns(it => new { it.Name,it.CreateTime }).ExecuteCommandAsync(); // 只更新某列
db.Updateable(updateObj).IgnoreColumns(it => new { it.CreateTime,it.TestId }).ExecuteCommandAsync() // 不更新某列
// 批量更新参数 List<Class>
var result= db.Updateable(updateObjs).ExecuteCommandAsync();
//大数据批量更新 适合列多数据多的更新
db.Fastest<RealmAuctionDatum>().BulkUpdate(GetList());单条更新:这里我们演示一下单条更新的效果,这里我们查询数据库中User表中的第一条数据,然后将其进行更新,代码如下所示:
/// <summary>
/// 更新数据
/// </summary>
/// <returns></returns>
[HttpGet]
public async Task<IResult> Uptateable()
{
var user = reponsitory.Queryable<User>().FirstAsync();
try
{
var result = await reponsitory.Updateable(new User
{
Id = user.Result.Id,
Name = "张三",
Email = "zhangsan@example.com"
}).ExecuteCommandAsync();
return Results.Ok("更新成功");
}
catch (Exception ex)
{
return Results.BadRequest("更新失败" + ex.Message);
}
}可以看到我们的数据已经成功的被更新出来了:
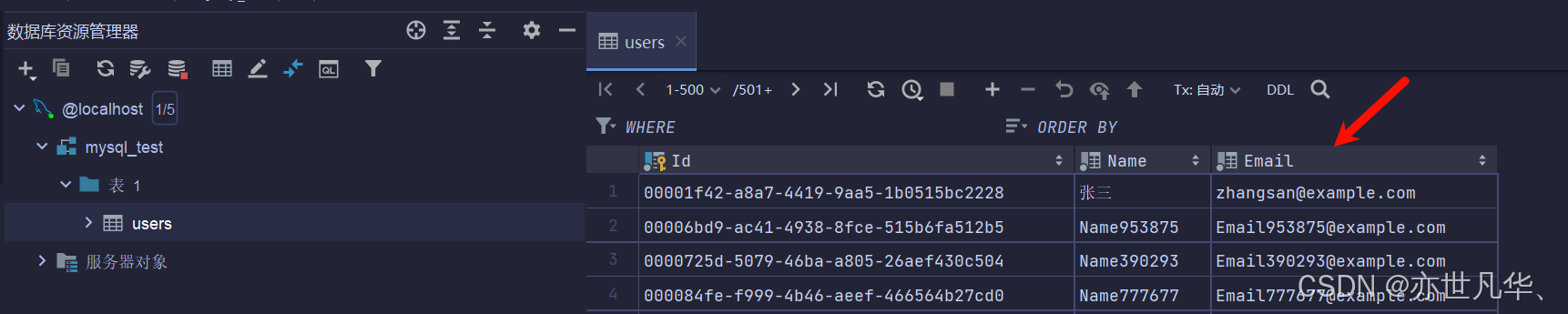
按需批量更新:这里我们可以按需更新,将所有的数据中Name拼接+1,Email拼接-1,如下所示将大批量的数据进行按需更新操作:
/// <summary>
/// 更新数据
/// </summary>
/// <returns></returns>
[HttpGet]
public async Task<IResult> Uptateable()
{
var users = reponsitory.Queryable<User>().ToList(); // 获取所有用户
try
{
foreach (var user in users)
{
// 拼接Name +1,Email -1
user.Name = user.Name + "1";
user.Email = user.Email + "-1";
}
// 批量更新
await reponsitory.Updateable(users)
.UpdateColumns(it => new User { Name = it.Name, Email = it.Email })
.ExecuteCommandAsync();
return Results.Ok("更新成功");
}
catch (Exception ex)
{
return Results.BadRequest("更新失败: " + ex.Message);
}
}最终得到的效果如下所示:
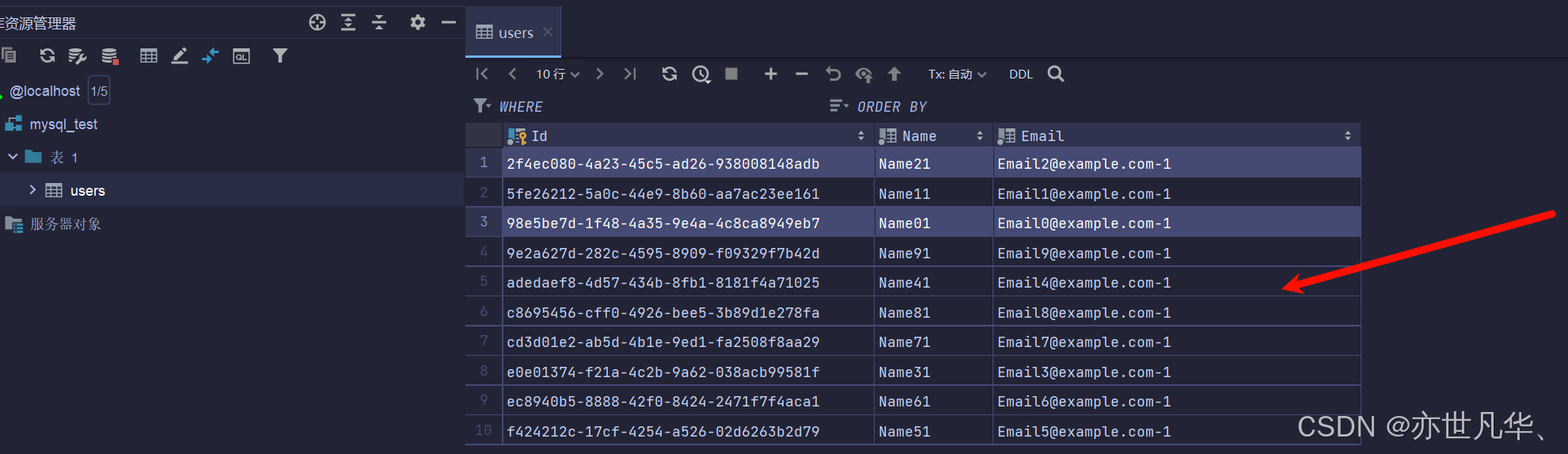
联表更新
联表更新可以采用以下方式进行:
//多库兼容
var t17 = db.Updateable<Student>()
.SetColumns(it =>new Student()
{
SchoolId=SqlFunc.Subqueryable<School>().Where(s=>s.Id ==it.SchoolId).Select(s=>s.Id),
Name = "newname"
})
.ExecuteCommand();
//也可以在Where加条件
//.Where(it => SqlFunc.Subqueryable<School>().Where(s => s.Id == it.SchoolId).Any())
//优雅写法:MySql PgSql SqlServer Oracle 达梦、金仓
//其中Oracle和达梦只支持2表
var t= db.Updateable<Order>()
.InnerJoin<Custom>((x, y) => x.CustomId == y.Id)
.SetColumns((x, y) => new Order() { Name = y.Name, Price = y.Id })
.Where((x, y) => x.Id == 1)
.ExecuteCommand();插入或更新
当数据库中数据不存在就插入,如果存在就更新,SqlSuagr也是提供了该方法的函数供我们进行操作,如下所示:
// 存在数据库更新 不存在插入 (默认是主键)
Db.Storageable(list2).ExecuteCommand()//(老版本是Saveable)
// 分页插入
Db.Storageable(list2).PageSize(1000).ExecuteCommand();
// 主键等于默认值插入否则更新(如果可以满足需求这种性能要好的多)
Db.Storageable(list).DefaultAddElseUpdate().ExecuteCommand()
// 大数据插入或者更新 (部分库不支持自增)
db.Fastest<Order>().BulkMerge(List);这里我查询数据库中是否有Name为张三的值,如果有就更新email,如果没有就执行插入操作
/// <summary>
/// 插入更新操作
/// </summary>
[HttpGet]
public async Task<IResult> InsertOrUpdate()
{
var user = new User { Id = Guid.NewGuid(), Name = "张三", Email = "zhangsan@example.com12" };
try
{
// 使用 FirstOrDefaultAsync 查询数据库,确保查询条件正确匹配
var existingUser = await reponsitory.Queryable<User>()
.Where(u => u.Name == "张三") // 确保 Name 字段与数据库中的一致
.FirstAsync();
if (existingUser != null)
{
// 如果用户已存在,更新其 Email
existingUser.Email = user.Email; // 直接更新现有用户对象的 Email
await reponsitory.Storageable(existingUser).ExecuteCommandAsync(); // 执行更新操作
}
else
{
// 如果用户不存在,插入新用户
await reponsitory.Storageable(user).ExecuteCommandAsync();
}
return Results.Ok("插入或更新成功");
}
catch (Exception ex)
{
return Results.BadRequest("操作失败: " + ex.Message);
}
}效果如下所示,执行多次只会更新email中的数据:
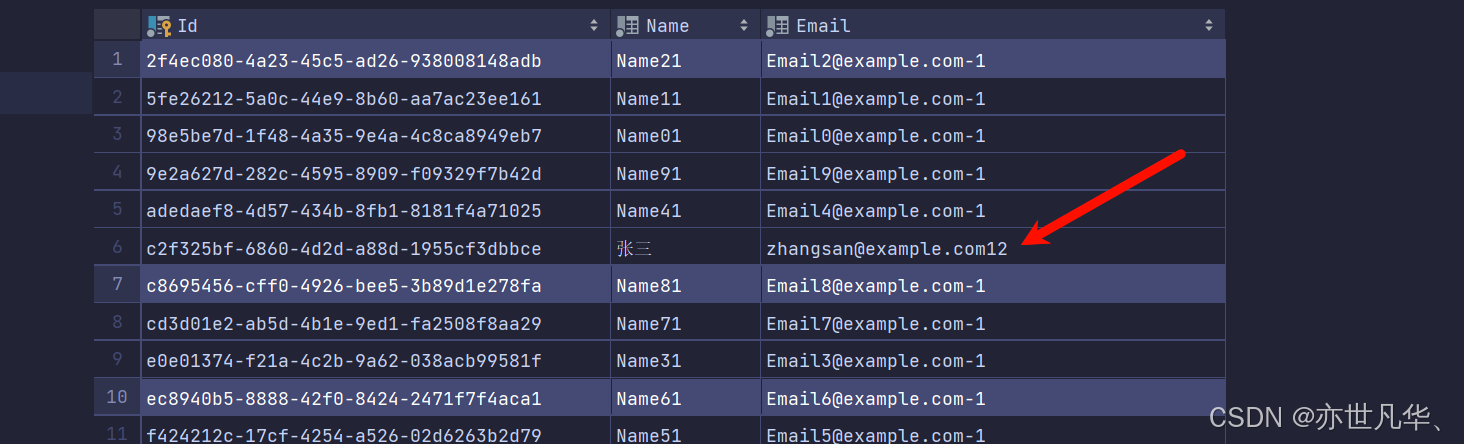
查询数据
// 类似select * from Student (查所有)
List<Student> list = db.Queryable<Student>().ToList()
// 类似select count(1) from Student (查询总数)
int count = db.Queryable<Student>().Count()
// 类似select * from Student where id = 1 (按条件查询)
db.Queryable<Student>().Where(it=>it.Id==1).ToList()
// 类似select * from Student where name like %jack% (模糊查询)
db.Queryable<Student>().Where(it =>it.Name.Contains("jack")).ToList();
// 类似select top 10 * from Student (查前10条)
db.Queryable<Student>().Take(10).ToList()
// 是否存在记录
db.Queryable<Student>().Where(it=>it.Id>11).Any()
// 简单排序
db.Queryable<Student>().OrderBy((st,sc)=>sc.Id,OrderByType.Desc).ToList()
// 获取最大最小值
db.Queryable<Order>().Max(it=>it.Id);
db.Queryable<Order>().Min(it=>it.Id);
// 查询过滤排除某一个字段
db.Queryable<Order>().IgnoreColumns(it=>it.Files).ToList();//只支持单表查询
// 分页查询
int pagenumber= 1; // pagenumber是从1开始的不是从零开始的
int pageSize = 20;
int totalCount=0;
var page = db.Queryable<Student>().ToPageList(pagenumber, pageSize, ref totalCount); //单表分页
var list = db.Queryable<Student>().LeftJoin<School>((st,sc)=>st.SchoolId==sc.Id).Select((st,sc)=>new{Id=st.Id,Name=st.Name,SchoolName=sc.Name})
.ToPageList(pageIndex, pageSize, ref totalCount); // //多表分页

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











