






最近在用logstash做日志分析的时候,搜集了很多资料,但大部分都是关于logstash如何将日志各个部分加以分类存储到logstash中,没有写如何分析攻击日志的东西,所以在此我简单记录一下。
首先,logstash做日志分析最重要的还是过滤器的书写,logstash的过滤器支持grok匹配,而grok又是建立在正则表达式上面的,所以我们可以从这方面入手进行分析。
需求
1.将日志进行筛选,首先将所有日志进行常规分析,各个字段进行分类,存储到es中。
2.将可能是sql注入攻击的日志单独筛选出来,存入到es中
实现
1.首先看一下过滤器的编写
input {
file {
path => ["D:/logs/logs/*.log"]
start_position => "beginning"
type=>"elasticsearch"
}
file {
path => ["D:/logs/logs/*.log"]
start_position => "beginning"
type=>"sqlattrack"
}
}
filter{
if [type] == "sqlattrack"{
grok{
match=>{"message" => ".*?[^a-zA-Z](?<tag_1>((and|or|union|select|insert|delete|count|updata|where))).*?"}
}
}
if [type] == "elasticsearch"{
grok{
match=>{"message" => "%{IP:client_ip} - - \[%{HTTPDATE:timestamp}\] \"(%{WORD:verb} %{GREEDYDATA:request} HTTP/%{NUMBER:http_version}|{GREEDYDATA:request})\" %{NUMBER:response} %{NUMBER:buytes}"}
}
}
}
output {
if [type] == "elasticsearch"{
elasticsearch {
hosts => ["192.168.137.102:9200"]
index => "es_log_%{+YYYY.MM.dd}"
}
stdout{
codec=>rubydebug
}
}
if [type] == "sqlattrack" and ([tag_1] =="and" or [tag_1]=="or" or [tag_1]=="union" or [tag_1]=="select" or [tag_1]=="delete" or [tag_1]=="count" or [tag_1]=="updata" or [tag_1]=="where" or [tag_1]=="insert"){
elasticsearch {
hosts => ["192.168.137.102:9200"]
index => "es_logsql_%{+YYYY.MM.dd}"
}
stdout{
codec=>rubydebug
}
}
}logstash的config文件包含三大块,分别是input filter output,其中input和output比较好理解,相信大家看一下我的代码能看懂,我在此简单的解释一下:path就是我日志的路径,start_position是指从哪开始读,logstash默认是从文件末尾开始读的,我这里将其写为从文件首部开始读取,type字段可以自己起名,是一个标识字段,大家可以随意。我将日志读取了两遍,第一次是为了整体存储,第二次则是为了筛选可能存在攻击行为的日志,所以这两个type必须是不一样的。
output的判断是比较重要的,也就是根据type标识不同,将过滤得到的日志分别命名,存到es中。hosts就是我es的地址,index是索引名,相当于起一个在es中存储名字,可以类比做数据库的表名。我们主要看filter的写法。
在这里给大家推荐一个网址https://www.5axxw.com/tools/v2/grok.html,这个网站可以测试你的grok匹配是否正确

第一个框填入你的日志,第二个框填入你编写的匹配规则,第三个框也就是得到的json数据。
在这里我就不解释比较简单的grok匹配了,大家可以对比一下,我将我日志的截图和分析结果放上来,这个市面上的资料是比较多的。
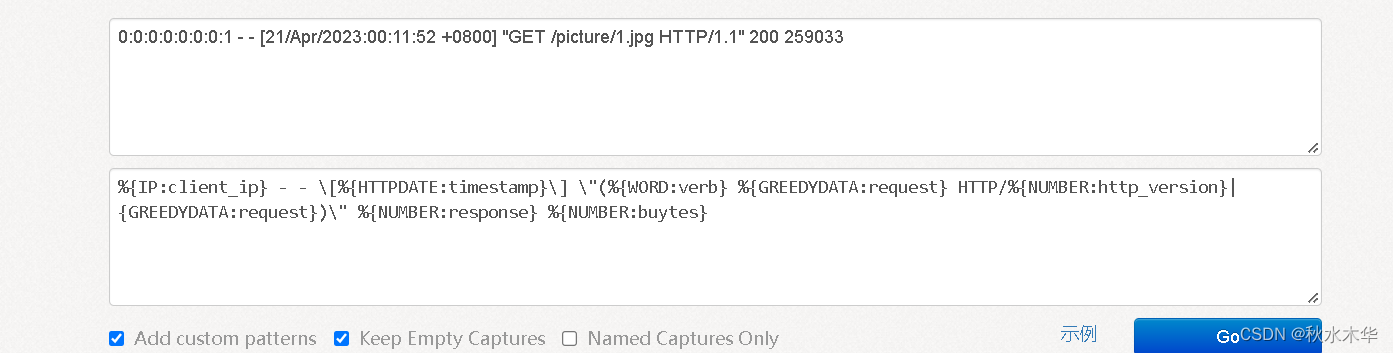
{
"client_ip": [
[
"0:0:0:0:0:0:0:1"
]
],
"IPV6": [
[
"0:0:0:0:0:0:0:1"
]
],
"IPV4": [
[
null
]
],
"timestamp": [
[
"21/Apr/2023:00:11:52 +0800"
]
],
"MONTHDAY": [
[
"21"
]
],
"MONTH": [
[
"Apr"
]
],
"YEAR": [
[
"2023"
]
],
"TIME": [
[
"00:11:52"
]
],
"HOUR": [
[
"00"
]
],
"MINUTE": [
[
"11"
]
],
"SECOND": [
[
"52"
]
],
"INT": [
[
"+0800"
]
],
"verb": [
[
"GET"
]
],
"request": [
[
"/picture/1.jpg"
]
],
"http_version": [
[
"1.1"
]
],
"BASE10NUM": [
[
"1.1",
"200",
"259033"
]
],
"response": [
[
"200"
]
],
"buytes": [
[
"259033"
]
]
}然后给大家看一下他们在es中的存储样子
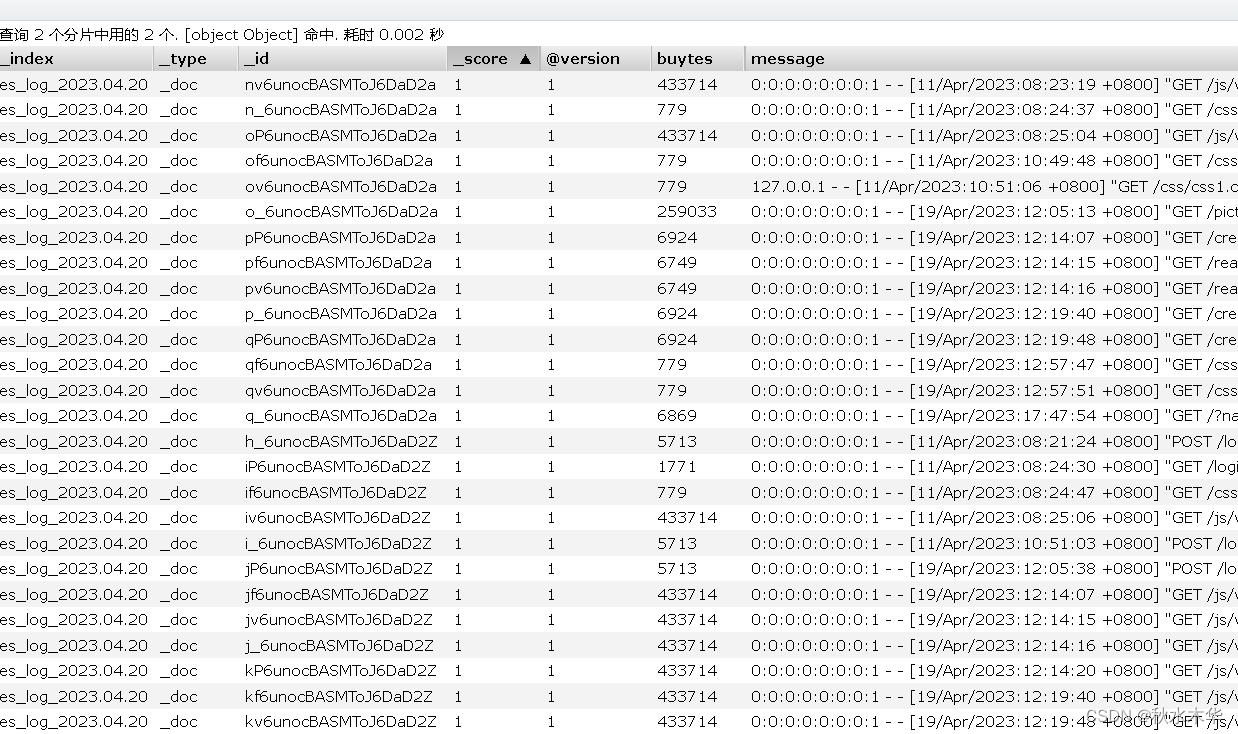
{
"_index": "es_log_2023.04.20",
"_type": "_doc",
"_id": "nv6unocBASMToJ6DaD2a",
"_version": 1,
"_score": 1,
"_source": {
"@version": "1",
"buytes": "433714",
"message": "0:0:0:0:0:0:0:1 - - [11/Apr/2023:08:23:19 +0800] "GET /js/vue.js HTTP/1.1" 200 433714 ",
"type": "elasticsearch",
"timestamp": "11/Apr/2023:08:23:19 +0800",
"request": "/js/vue.js",
"host": "WIN-Q87V9552R8L",
"verb": "GET",
"http_version": "1.1",
"response": "200",
"client_ip": "0:0:0:0:0:0:0:1",
"path": "D:/logs/logs/1.log",
"@timestamp": "2023-04-20T12:40:42.420Z"
}
}这些就是比较常规的,接下来我具体讲一下sql攻击匹配,可能方法比较笨,但百度实在找不到相关的东西,这也是我自己琢磨的。
首先是先找一个sql攻击的日志,然后匹配一下,这个比较简单,对你自己的网站进行sql注入攻击,得到的日志粘到刚才那个网站测试就好了。
.*?[^a-zA-Z](?<tag_1>((and|or|union|select|insert|delete|count|updata|where))).*?这是我写的一个比较简单的匹配规则,.*?的意思是非贪婪匹配,匹配任意长度的任何字符串,但是是尽可能匹配少的,两边都是.*?也就是说这两边出现什么都可以,主要是有没有我括号里面的东西。
?<tag_1>的解释: tag_1是我自己起的名字,就是相当于变量名,他的匹配规则就是我后面写的那些,当匹配到后面的东西时,他的值就是匹配到的东西,否则就是null。在我的表达式里面,我仅对几种比较常见可能存在sql注入攻击的字符进行匹配,大家可以根据我这个写法进行扩写
然后看output就比较轻松了,当tag_1的字符是这几个时,可能是攻击行为,将其存到可能存在攻击的日志中。















 1230
1230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









