







1.js有哪三部分组成?
ECMAScript:JS核心内容,描述了语言的基础语法,比如var,for,数据类型
文档对象模型(DOM):把整个HTML 页面规划为元素构成的文档
浏览器对象模型(BOM ):对浏览器串口进行访问和操作
数据类型
1. 基本数据类型和引用数据类型的区别?
一共八种
基本数据类型:string 、number、boolean、undefined、null、bigint、symbol
引用数据类型:object、function、array
基本数据类型保存在栈内存中,保存的是一个具体的值
引用数据类型保存在堆内存当中,在栈中存储了指针,该指针指向堆中该实体的起始地址。声明一个引用类型的变量,保存的是引用类型数据的地址。
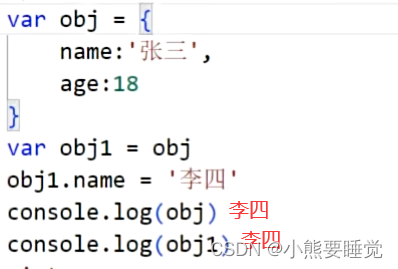
假如声明两个引用类型同时指向了一个地址的时候,修改其中一个那么另外一个也会改变,比如下面例子:
2. null和undefined的区别,如何让一个属性为null
null是定义并赋值null,undefined表示定义未被赋值。
if判断中都会被解析为false,
在用Number运算时,null的结果为0,undefined的结果为NaN,
让属性变为null就需要先定义,再赋空值。
3. js有几种方法判断变量的类型
四种。
- typeof() 常用于 判断基本数据类型,对于引用数据类型除了function返回’function‘,其余全部返回’object’
- instanceof() 只能判断引用数据类型,根据原型链判断,不能判断基本数据类型
- constructor 几乎可以判断基本数据类型和引用数据类型;根据构造器判断,如果声明了一个构造函数,并把它的原型指向了Array
- Object.prototype.toString.call() 用于所有类型的判断检测,每个对象上记载的属性名称

数组
1. 数组去重的方法?
- 利用对象属性key排除重复项:遍历数组,每次判断对象中是否存在该属性,不存在就存储在新数组中,并且把数组元素作为key,设置一个值,存储在对象中,最后返回新数组。
优点是效率较高,
缺点是占用了较多空间,使用的额外空间有一个查询对象和一个新的数组- 利用Set类型数据无重复项:new Set() ;var mySet = new Set(arr), new 一个 Set,参数为需要去重的数组,Set 会自动删除重复的元素,再将 Set 转为数组返回。
优点是效率更高,代码简单,思路清晰,
缺点是可能会有兼容性问题- filter+indexof 去重:这个方法和第一种方法类似,利用 Array 自带的 filter 方法,返回 arr.indexOf(num) 等于 index 的num。原理就是 indexOf 会返回最先找到的数字的索引,假设数组是 [1, 1],在对第二个1使用 indexOf 方法时,返回的是第一个1的索引0。
优点是可以在去重的时候插入对元素的操作,可拓展性强。- reduce +includes去重:利用reduce遍历和传入一个空数组作为去重后的新数组,然后内部判断新数组中是否存在当前遍历的元素,不存在就插入到新数组中。
缺点:这种方法时间消耗多,内存空间也有额外占用。
2. 伪数组和数组的区别?
- 伪数组的特点:类型是object、不能使用数组方法、可以获取长度、可以使用for in遍历
- 数组类型是array。
- 伪数组可以装换为数组的方法:
a. Array.prototype.slice.call(伪数组)
b.Array.from(伪数组)
c. […伪数组]- 有哪些是伪数组:函数的参数arguments,Map和Set的keys()、values()和entires()
3. 操作数组的方法有哪些
push() 、pop()、sort()、splice()、unshift()、shift() reverse()、concat()、
join()、map()、filter()、ervery()、some()、reduce()、isArray()、findIndex()
哪些方法会改变原数组?
push() 、pop()、unshift()、shift() 、 reverse()、sort()
4. 常用的数组方法(至少七个)
1) Array.push():此方法是在数组的后面添加新元素,此方法改变了数组的长度:
2)Array.pop():此方法在数组后面删除最后一个元素,并返回数组,此方法改变了数组的长度:
3) Array.shift():此方法在数组后面删除第一个元素,并返回数组,此方法改变了数组的长度:
4) Array.unshift():此方法是将一个或多个元素添加到数组的开头*,并返回新数组的长度:
5)Array.isArray():判断一个对象是不是数组,返回的是布尔值
6) Array.concat():此方法是一个可以将多个数组拼接成一个数组:
7)Array.toString() : 把数组作为字符串返回
8) Array.join() :以指定字符拼接成字符串,然后返回
9) Array.splice:(开始位置, 删除的个数,元素)
10)Array.map():此方法是将数组中的每个元素调用一个提供的函数,结果作为一个新的数组返回,并没有改变原来的数组
11)Array.forEach():此方法是将数组中的每个元素执行传进提供的函数,没有返回值,直接改变原数组,注意和 map 方法区分
12)Array.filter():此方法是将所有元素进行判断,将满足条件的元素作为一个新的数组返回
13)Array.every():此方法是将所有元素进行判断返回一个布尔值,如果所有元素都满足判断条件,则返回 true,否则为 false:
14)Array.some():此方法是将所有元素进行判断返回一个布尔值,如果存在元素都满足判断条件,则返回 true,若所有元素都不满足判断条件,则返回 false:
15)Array.reduce():此方法是所有元素调用返回函数,返回值为最后结果,传入的值必须是函数类型:
5. map 和 forEach 的区别:
- map有返回值,可以开辟新空间,return出来一个length和原数组一致的数组,即便数组元素是undefined或者是null。
- forEach默认无返回值,返回结果为undefined,可以通过在函数体内部使用索引修改数组元素。
6. 事件扩展符(…)用过吗,什么场景下?
- 数组克隆 let a = [1,2,3];let b = […a]
- 数组合并 let a = [1,2,3];let b = [4,5,6];let c = […a,…b]
- 类数组转成真正的数组 let a = new Set([1,2,3]); let b = […a]
ES6
1. ES5和ES6的区别?
js的组成:ES BOM DOM
ES5,ECMAScript5,2009年ECMAScript的第五次修订
ES6,ECMAScript6,2015年ECMAScript的第六次修订,是JS的下一个版本标准
2. ES6的新特性有哪些?
1.新增块级作用域(let,const)
是声明变量的关键字,
不存在变量提升,也就是说变量声明之前是用不了的,
存在暂时性死区的问题,
块级作用域的内容,
不能在同一个作用域内重复声明
2.新增了定义类的语法糖(class)
3.新增了一种基本数据类型(symbol)
4.新增了解构赋值
从数组或者对象中取值,然后给变量赋值。
5.新增了函数参数的默认值
6.给数组新增了API
7.对象和数组新增了扩展运算符
8.Promise
解决了回调地狱的问题。自身有all,reject,resolve,race方法,
原型上有then,catch
把异步操作队列化
三种状态:pending(初始状态)、fulfilled(操作成功)、rejected(操作失败)
状态:从pending到fulfilled 或者从pending到rejected,一旦发生,状态就会凝固,不会再变
async await用来同步代码做异步的操作,两者必须搭配使用。
async表明函数内有异步操作,调用函数会返回promise。
await是组成async的表达式,结果是取决于它等待的内容,如果是promise那就promise的结果,如果是普通函数就进行链式调用。
await后的promise如果reject状态,那么整个async函数都会中断,后面程序就不会执行
9.新增了模块化(import,export)
10.新增了set和map数据结构
set就是不重复
map的key类型不受限制
11.新增了generator
12.新增了箭头函数
不能作为构造函数使用,不能使用new,箭头函数没有arguments,箭头函数不能用call,apply,bind去改变this的执行
this指向外层第一个函数的this
3.对ES6的箭头函数的理解
箭头函数相当于匿名函数,简化了函数定义
- 没有this,this是从外部获取,就是继承外部的执行上下文中的this,在找不到最外层的普通函数时,其this一般指向window;
- 没有原型和super
- 不能作为构造函数,(是因为无自己的this、constructor)
浏览器本地存储方式
1. 浏览器的本地存储方式有哪些?
- cookies:H5标准前的本地存储方式,
兼容性好,请求头自带cookie;
存储量小,资源浪费,使用麻烦(封装)- localstorage:H5加入的以键值对为标准的方式,
操作方便,永久存储,兼容性较好。
保存值的类型被限定,浏览器在隐私模式下不可读取,不能被爬虫- sessionstorage:当前页面关闭后就会立刻清理,会话级别的存储方式
- indexedDB:H5标准的存储方式,以键值对进行存储,可以快读读取,适合WEB场景
2. cookies、localstorage、sessionstorage的区别?
- 写入方式:cookie是由服务器端写入的,而SessionStorage、 LocalStorage都是由前端写入的
- 生命周期:cookie的生命周期是由服务器端在写入的时候就设置好的,LocalStorage是写入就一直存在,除非手动清除,SessionStorage是页面关闭的时候就会自动清除。
- 在前端给后端发送请求的时候会自动携带Cookie中的数据,但是SessionStorage、 LocalStorage不会
- 应用场景:cookie一般用于存储登录验证信息SessionID或者token,LocalStorage常用于存储不易变动的数据,减轻服务器的压力,SessionStorage可以用来检测用户是否是刷新进入页面,如音乐播放器恢复播放进度条的功能。
3. token存在sessionstorage还是localstorage还是cookie?
token:验证身份的令牌,一般就是用户通过账户密码登录后,服务端把这些凭证通过加密等一系列操作后得到的字符串
1.存localstorage里面,后期每次请求接口都需要把它当作一个字段传给后台
2.存cookie中,会自动发送,缺点就是不能跨域
如果存在localstorage中,容易被xss攻击,但是如果做好了对应的措施,那么利大于弊;如果存在cookie中会有CSRF攻击
4. 如何实现可过期的localstorage数据?
一种是惰性删除,另一种是定时删除。
- 惰性删除
定义:某个键值过期后,该键值不会被马上删除,而是等到下次被使用的时候,才会被检查到过期,此时才能得到删除。
实现方法:存储的数据类型是个对象,该对象有两个key,一个是要存储的value值,另一个是当前时间。获取数据的时候,拿到存储的时间和当前时间做对比,如果超过过期时间就清除Cookie。- 定时删除
定义:每隔一段时间执行一次删除操作,并通过限制删除操作执行的次数和频率,来减少删除操作对CPU的长期占用。
实现过程,获取所有设置过期时间的key判断是否过期,过期就存储到数组中,遍历数组,每隔1S(固定时间)删除5个(固定个数),直到把数组中的key从localstorage中全部删除。
优点:有效的减少了因惰性删除带来的对localStorage空间的浪费。
5. token的登录流程:
1.客户端用账户密码请求登录
2.服务端收到请求后,需要去验证账户密码
3.验证成功后,服务端会签发一个token,把这个token发送给客户端
4.客户端收到token后保存起来,可以放在cookie也可以是localstorage
5.客户端每次向服务器发送请求资源的时候,都需要携带这个token
6.服务端收到请求,接着去验证客户端里的token,验证成功才会返回客户端请求的数据。
http网络部分和浏览器渲染
1. 说一下浏览器的缓存策略
强缓存(本地缓存)、协商缓存(弱缓存)
强缓存:不发起请求,直接使用缓存里的内容,浏览器把JS、CSS、image等存到内存中,下次用户访问直接从内存中取,提高性能
协商缓存:需要向后台请求,通过判断来决定是否使用协商缓存,如果请求内容没有变化,则返回304,浏览器就用缓存里面的内容
强缓存的触发:
HTTP1.0:时间戳响应标头
HTTP1.1:Cache-Control响应标头
协商缓存触发:
HTTP1.0:请求头:if-modified-since 响应头:last-modified
HTTP1.1:请求头:if-none-match 响应头:Etag
2. 说一下浏览器输入URL发生了什么?
DNS解析、TCP握手、HTTP缓存、重定向、服务器状态码、渲染引擎和JS引擎互斥、渲染过程、浏览器进程、网络进程、渲染进程
- DNS解析:将域名解析为IP地址
- TCP握手,
- 判断是否是HTTP缓存
1.如果是强制缓存且在有效期内,不再向服务器发请求,
2.如果是HTTP协商缓存向后端发送请求且和后端服务器对比,
在有效期内,服务器返回304,直接从浏览器获取数据,
如果不在有效期内服务器返回200,返回新数据。- 进行重定位: 如果请求的参数有问题,服务器端返回404,如果服务器端挂了返回500。
- 渲染引擎和JS引擎互斥
3. 页面渲染的过程是怎样的
- DNS解析
- 建立TCP连接
- 发送HTTP请求
- 服务器处理请求
- 渲染页面:
1.浏览器会获取HTML和CSS的资源,然后把HTML解析成DOM树;
2.再把CSS解析成CSSOM;
3.把DOM和CSSOM合并成渲染树;进行布局
4.把渲染树的每个节点渲染到屏幕上(绘制)
4. DOM树和渲染树有什么区别?
DOM树是和HTML标签一一对应的,包括head和隐藏元素
渲染树不包括head和隐藏元素
渲染师是由DOM树和CSSOM树合并而成的
5. 重绘、重排的理解
重排 :当DOM的变化影响了元素的几何信息(元素的的位置和尺寸大小),浏览器需要重新计算元素的几何属性,将其安放在界面中的正确位置。
重绘:当一个元素的外观发生改变,但没有改变布局,重新把元素外观绘制出来的过程,
重排必定发生重绘,但是涉及到重绘不一定要重排
避免重排的方法有
1.尽量用class类的方式统一修改样式
2.脱离文档流
3.transform的方式调整位置 而不是 top、left、margin等,触发GPU加速
6. http协议中 get和post有什么区别?
1.get一般是获取数据,post一般是提交数据
2.get参数会放在url上,所以安全性比较差,post是放在body中
3.get请求刷新服务器或退回是没有影响的,post请求退回时会重新提交数据
4.get请求时会被缓存,post请求不会被缓存
5.get请求会被保存在浏览器历史记录中,post不会
6.get请求只能进行url编码,post请求支持很多种
7. HTTP协议规定的协议头和请求头有什么?
协议头包含请求头
1.请求头信息:
Accept:浏览器告诉服务器所支持的数据类型
Host:浏览器告诉服务器我想访问服务器的哪台主机
Referer:浏览器告诉服务器我是从哪里来的
Use-Agent:浏览器类型、版本信息
Date:浏览器告诉服务器我是什么时候访问的
Connection:连接方式
Cookie
X-Request-with:请求方式
2.响应头信息:
Location:告诉浏览器你要去找谁
Server:告诉浏览器服务器的类型
Content-Type:告诉浏览器返回的数据类型
Refresh:控制了的定时刷新
8. 同源策略、跨域、跨域方法
同源策略是浏览器的核心,如果没有这个就会遭受网络攻击。
主要指协议+域名+端口号三者一致,若其中一个不一样则不是同源 ,会产生跨域
三个允许跨域加载资源的标签:img link script
跨域是浏览器不能执行其它的网站的脚本,这由浏览器的同源策略造成的,也是浏览器施加安全的限制。可以发送请求,后端也会正常返回结果,只不过这个结果被浏览器拦截了。
跨域方法:JSONP、CORS、websocket、 反向代理
跨域场景:前后端分离式开发、调用第三方接口

9. 实现前后端实时通信
- 短轮询:客户端设置定时器,每隔几秒就向服务端发送请求,通过频繁地请求到达实时的效果。这种方式要求服务器的响应速度很快。
- 长轮询:客户端和服务端保持一条长连接,一旦服务端有新的数据,不等客户端请求就会主动发送给对方。这种方式要求服务器有高并发能力。
- WebSocket:一种全双工通信协议,客户端和服务端处于相同的地位。通过客户端与服务端建立的HTTP连接进行切换,客户端会发送一个带update:websocket字段的HTTP请求请求协议切换,服务端会回复带101状态码的响应表示协议切换成功。接着它们使用websocket进行通信,一旦有新的数据服务端可以直接发送给客户端。
- SSE(Server-Sent Event):服务端与客户端建立的一个单向通道,只能由服务端传输特定形式的数据给客户端,这里并不是建立一个长连接。
10. 浏览器的垃圾回收机制
分为栈垃圾回收和堆垃圾回收
- 栈垃圾回收:JS基本数据类型的变量存储在栈中,引用类型的变量存储的堆中。 存在栈中的变量随着执行上下文的销毁而销毁。
- 堆垃圾回收有两种清除机制:
1.引用计数:堆中的每个变量会有一个计数器,记录引用该变量的次数。一旦计数器为0,垃圾回收机制会将这部分内存回收。
2.标记清除:堆中的每个变量会一个标记,如果有任何引用则标记会被清除,垃圾回收机制会将没有标记的部分内存回收。
事件
1. 事件委托(事件代理)是什么?
又叫事件代理,原理就是利用了事件冒泡的机制来实现,也就是说把子元素 的事件绑定到父元素身上
如果子元素组织了事件冒泡,那么委托也就不成立
阻止事件冒泡:event.stopPropagation()
addEventListener(‘click’,函数名 ,true/false),默认是false(事件冒泡),true(事件捕获)
好处:提高性能,减少事件的绑定,也就减少了内存的占用。
2.说一下事件循环、宏任务、微任务
JS是一个单线程的脚本语言,
主线程 执行栈 任务队列 宏任务 微任务
主线程先执行同步任务,然后才去执行任务队列里的任务,如果在执行宏任务之前有微任务,那么先执行微任务,全部执行完之后,等待主线程的调用,调用完之后,再去任务队列中查看是否有异步任务,这样一个循环往复的过程就是实现循环。
- 宏任务:任务队列中的任务称为宏任务,每个宏任务中都包含了一个微任务队列。
包含:
执行script标签内部代码、
setTimeout/setInterval、
ajax请、
postMessageMessageChannel、
setImmediate,
I/O(Node.js)- 微任务:等宏任务中的主要功能都完成后,渲染引擎不急着去执行下一个宏任务,而是执行当前宏任务中的微任务
微任务包含:
Promise、
MutonObserver、
Object.observe、
process.nextTick(Node.js)
this、new
1. js中关于this指向的问题
- 在全局执行环境中,
this都指向全局对象- 对象的this,哪个对象调用就指向哪个对象,如果是多层嵌套的情况,内部方法的this指向离被调用函数最近的对象(window也是对象,其内部对象调用方法的this指向内部对象,而不是window)。
- 构造函数中的this,与被构造函数实例出来的新对象绑定,即指向该新对象。
- 事件中的this ,this指向的是触发该事件的HTML元素对象,即指向事件源。
- 箭头函数的this:
1、箭头函数没有this,不能作为构造函数,所以也没有原型和new
2、箭头函数的this取决于它的外部函数 ,有就是外层函数的this,没有就是window。
2. 改变this指向方法?/call apply bind的区别
. new关键词改变了this的指向,this指向新创建的对象
- call 既可以调用函数又可以传参数,参数只需用逗号隔开,this指向指定的对象;
- apply 既可以调用函数又可以传参数,参数需要用一个数组进行包裹,this指向指定的对象;
- bind 不可以调用函数,可以传参数,参数只需用逗号隔开,返回得到一个新的函数,执行需要再次调用
都是改变this指向和函数的调用。call和apply的功能类似,只是传参的方法不同
call方法 传的是一个参数列表
apply传递的是一个数组
bind传参后不会立刻执行,会返回一个改变了this指向的函数,这个函数还是可以传参的,bind()()
call方法性能要比apply好一些,所以call用的更多一点
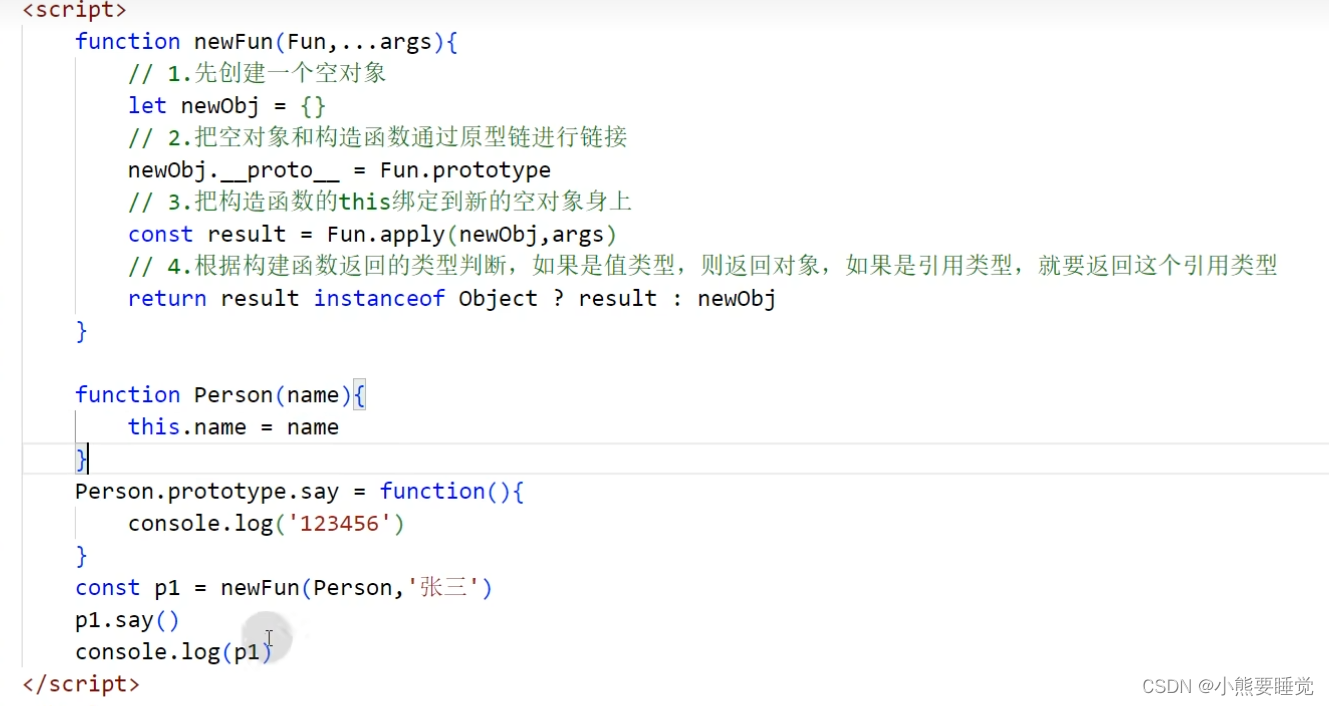
3. new的作用
- 创建一个空对象
- 添加属性,将新对象的__proto__指向构造函数的prototype(原型对象)
- 将此对象作为this的上下文
- 判断是否有返回值,如果有则返回此对象,如果没有则返回this
new关键字后面的构造函数不能是箭头函数。
JS
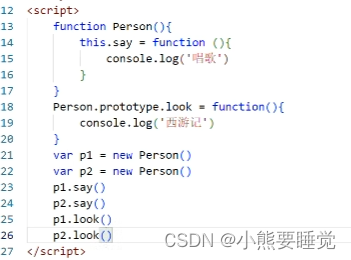
1.说一下原型链
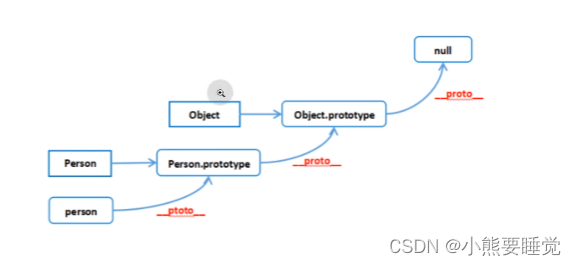
原型就是一个普通对象,它是为了构造函数的实例共享属性和方法:所有实例中引用的原型都是同一个对象。使用prototype可以把方法挂在原型上,内存值只保存一份
_proto_可以理解为指针,实例对象中的属性,指向了构造函数的原型(prototype)>
原型链就是一个实例对象在调用属性和方法的时候,会依次从实例本身、构造函数原型、原型的原型上去查找
2.js的设计原理
JS引擎:对js语法解析
运行上下文:浏览器调用的api
调用栈:单线运行 渲染工作 阻塞
事件循环 :当调用栈里面空了以后,就会把某些程序调入然后进行循环
回调
3.script标签里的async和defer有什么区别?
当没有async和defer这两个属性的时候,浏览器会立刻加载并执行指定的脚本
有async,加载和渲染后面元素的过程将和script的加载和执行并行进行(异步)
有defer,加载和渲染后面元素的过程将和script的加载并行进行(异步),但是它的执行事件要等所有元素解析完成之后才会执行。
4.闭包有什么特点?
- 定义:内层函数引用外层函数中变量,这些变量的集合就是闭包
- 特点:可以重复利用变量,并且这个变量不会污染全局的一种机制;这个变量是一直保存再内存中,不会被垃圾回收机制回收
- 闭包形成的原理:作用域链,当前作用域可以访问上级作用域中的变量
- 缺点: 容易造成了内存泄露,内存泄露积累多了就容易导致内存溢出 。闭包较多的时候,会消耗内存,导致页面的性能下降,
- 使用场景:防抖,节流,函数嵌套函数避免全局污染的时候
25.JS是如何继承的?
1.通过原型链继承
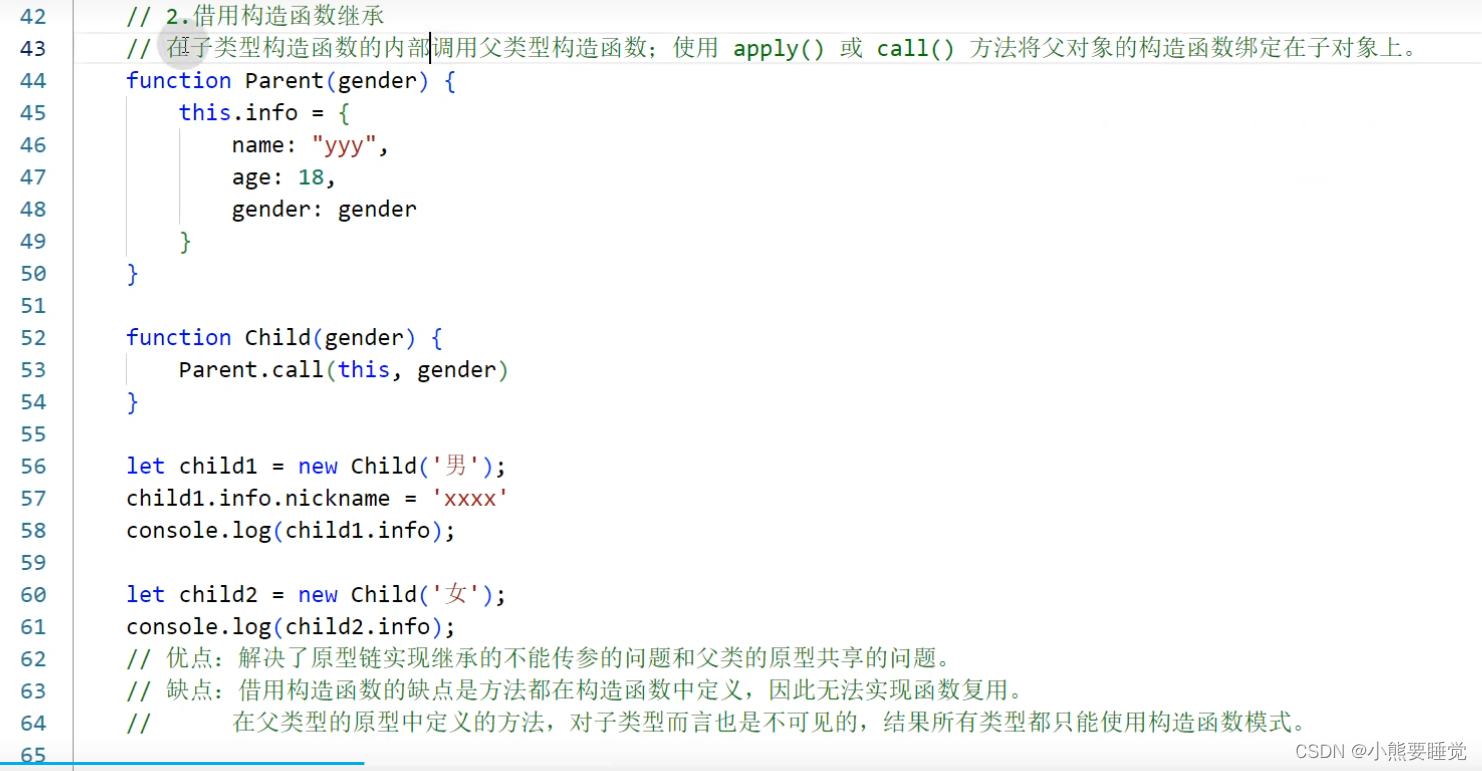
2.借用构造函数继承
3.组合式继承
4.ES6的class类继承
- 通过原型链继承 :让一个构造函数的原型是另一个类型的实例,那么这个构造函数new出来的实例就具有该实例的属性。
- 借用构造函数继承
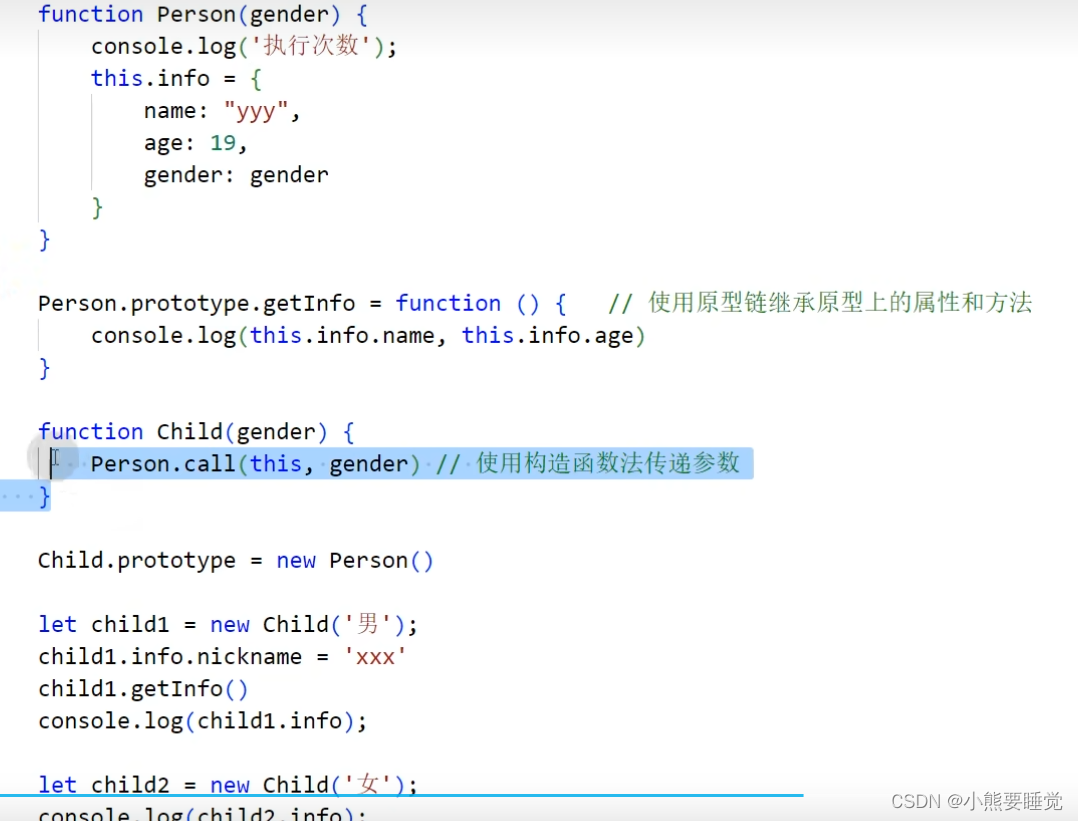
- 组合式继承
将原型链和借用构造函数的组合到一块。使用原型链实现对原型属性和方法的继承,
而通过借用构造函数来实现对实例属性的继承。这样,既通过在原型上定义方法实现了函数复用,又能够保证每个实例都有自己的属性
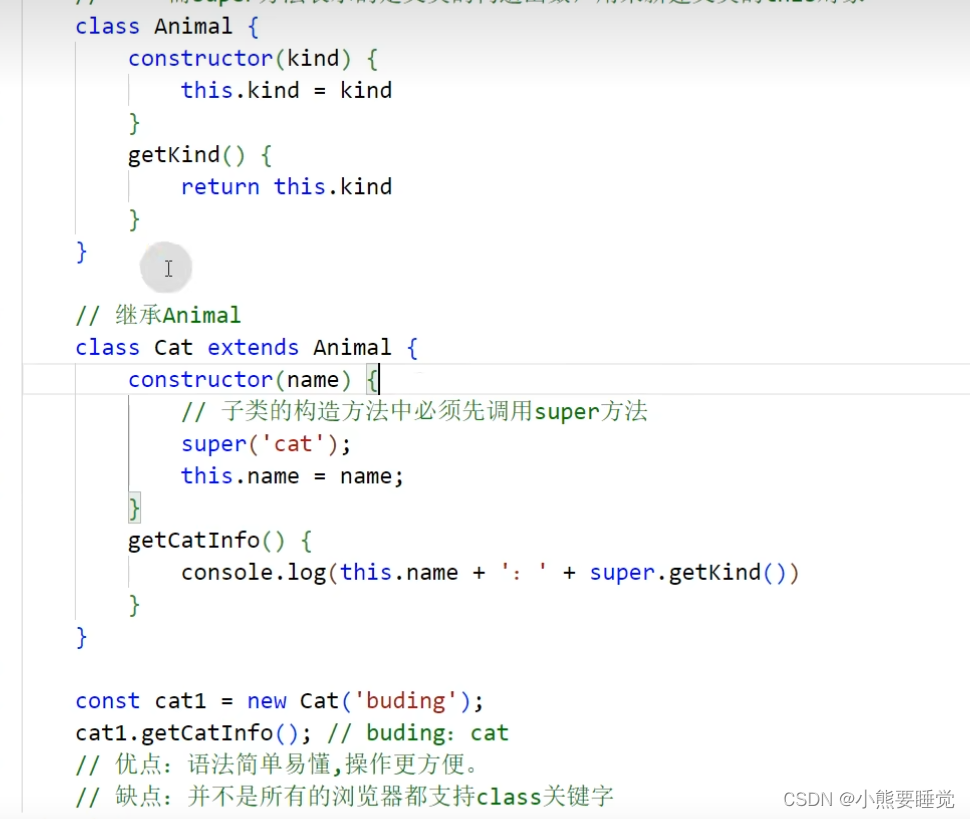
- ES6的class类继承
class通过extends关键字实现继承,
其实质是先创造出父类的this对象,然后用子类的构造函数修改this
子类的构造方法中必须调用super方法,且只有在调用了super()之后才能使用this,
因为子类的this对象是继承父类的this对象,然后对其进行加工,
而super方法表示的是父类的构造函数,用来新建父类的this对象


6. JS变量提升
- 定义是指JS的变量和函数声明会在代码编译期,提升到代码的最前面。
- 成立的前提是:使用Var关键字进行声明的变量,并且变量提升的时候只有声明被提升,赋值并不会被提升,同时函数的声明提升会比变量的提升优先。
- 变量提升的时候只有声明被提升,var、let和const中只有var存在变量提升。
- 结果,可以在变量初始化之前访问该变量,返回的是undefined。使用let和const声明的变量,在初始化之前访问会报错。函数提升优先于变量提升。
异步
1. JS异步实现的方法
所有异步任务都是在同步任务执行结束之后,从任务队列中依次取出执行
JS 异步编程进化史: callback -> promise -> generator/yield -> async/awt
方式:回调函数、事件监听、setTimeout、Promise、生成器Generators/yield、async/awt
宏任务:
(1)定时器setTimeout,setTimeinterval
(2)ajax请求:XMLHttpRequest,fetch,axios
(3)事件监听:on…,addEventListener
微任务:
(1)Promise.then
(2)async/await
2. setTimeout
2.1 setTimeout最小执行时间是多少?
是HTML5规定的内容:
setTimeout 最小执行时间是4ms
setInterval最小执行时间是10ms
3. promise
3.1 promise的内部原理是什么?它的优缺点是什么?
Promise对象, 封装了一个异步操作并且还可以获取成功或失败的结果。
Promise主要是解决回调地狱问题, 之前如果异步任务比较多,同时他们之间有相互依赖的关系,就只能使用回调函数处理,这样就容易形成回调地狱,代码的可读性差,可维护行也很差
有三种状态:pending初始状态 fulfilled成功状态 rejected失败状态
从pending到fulfilled 或者从pending到rejected,一旦发生,状态就会凝固,不会再变
首先就是我们无法取消promise,一旦创建它就会立即执行,不能中途取消
如果不设置回调,promise内部抛出的错误就无法反馈到外面
若当前处于pending状态时,无法得知目前在哪个阶段。原理:构造一个Promise实例,实例需要传递函数的参数,这个函数有两个形参,分别都是函数类型,一个是resolve一个是reject
promise上还有then方法,这个方法就是来指定状态改变时的确定操作,resolve是执行第一个函数,reject是执行第二个函数
3.2 promise和async await的区别?
1.都是处理异步请求的方法
2.promise是ES6,async是ES7的语法
3.async await是基于promise实现的,他和promise都是非阻塞性的
优缺点:
1.promise是返回对象我们要用then,catch方法去处理和捕获异常,并且书写方式是链式,容易造成代码重叠,不好维护;async await是通过tra catch进行捕获异常。
2.async await最大的优点就是能让代码看起来像同步一样,只要遇到await就会立刻返回结果,然后再执行后面的操作;promise.then()方式返回,会出现请求还没有返回,就执行了后面的操作
4. ajax
4.1 ajax是什么?怎么实现的?
创建交互式网页应用的网页开发技术。
在不重新加载整个网页的前提下,与服务器交换数据并更新部分内容
原理:通过XmlHttpRequest对象向服务器发送异步请求,然后从服务器拿到数据,最后通过JS操作DOM更新页面
1.创建XmlHttpRequest对象xmh
2.通过xmh对象里的open()方法和服务器建立连接
3.构建请求所需的数据,并通过xmh对象的send()发送给服务器
4.通过xmh对象的onreadystate chansge事件监听服务器和你的通信状态
5.接收并处理服务器响应的数据结果
6.把处理的数据更新到HTML页面上
4.2 说一下fetch请求方式?
Fetch是原生js,没有使用XMLHTTPRequest对象,fetch()方法返回Promise解析Respouse来自Request显示状态的方法:
特点:
1.精细的功能分割:头部信息、请求信息、响应信息等均分布在不同的对象,可以处理各种复杂的数据交互场景。
2.也可以适配promise API
3.同源请求也可以自定义不带cookie ,某些服务不需要cookie的场景下能少些流量。
4.2 解释一下XMLHTTPRequest
特点:所有功能集中在一个对象上,写的代码可维护性不强且容易混乱;不能适配新的promise API
其他
1.js有哪些内置对象?

2.前端的内部泄漏怎么理解?
js里已经分配内存地址的对象,但是由于长时间没有释放或者没办法清楚,造成长期占用内存的先序,会让内存资源大幅浪费,最终导致运行速度慢,甚至崩溃的情况。
垃圾回收机制
因素:一些为生命直接赋值的变量、 一些未清空的定时器;过度的闭包;一些引用元素未被清除
3.用递归的时候有没有遇到什么问题?
函数内部调用函数本身
一定要退出条件return
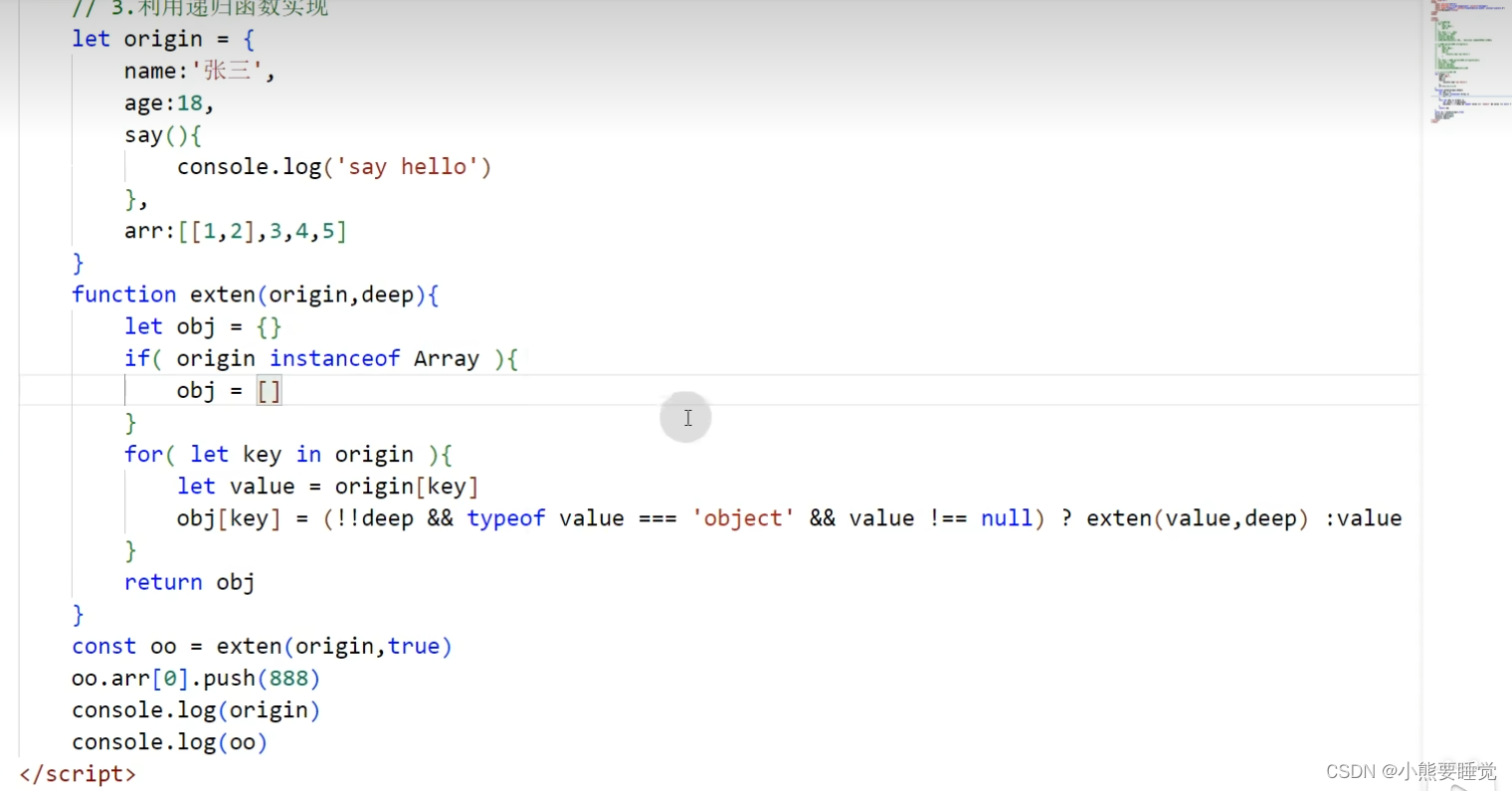
4.如何实现一个深拷贝?
深拷贝就是一个完全拷贝一份新的对象,会在堆内存中开辟新的空间,拷贝的对象被修改后,原对象不受影响,主要针对的是引用数据类型
1.扩展运算符
缺点:这个方法只能实现第一层,当有多层的时候还是浅拷贝
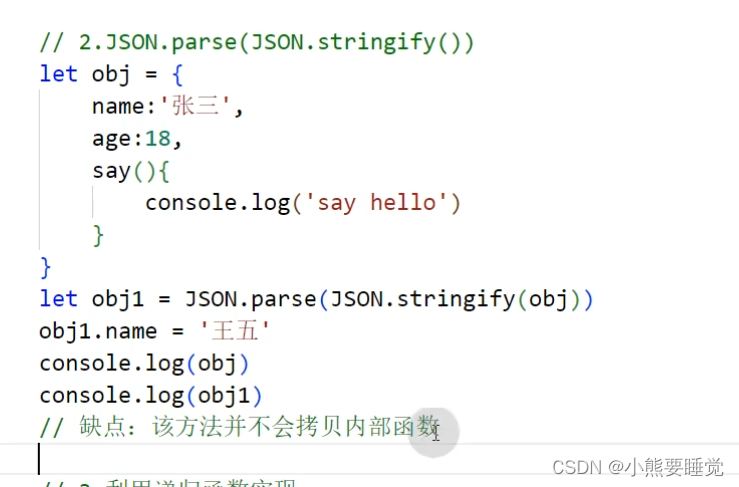
2.JSON.parse(JSON.stringify())
缺点:该方法并不会拷贝内部函数
3.利用递归函数实现

4 .精灵图和base64的区别是什么?
都是处理图片的方式
精灵图:把多张小图整合到一张大图上,合并之后大图的大小是比之前小图要小的,利用定位的一些属性把小图显示在页面上,当访问页面可以减少请求,提高加载速度
base64:传输8Bit字节代码的编码方式,把原本二进制形式转为64个字符的单位,最后组成字符串,把图片转换为字符串
base64是会和html css一起下载到浏览器中,减少请求,减少跨域问题,但是一些低版本不支持,若base6体积比原图片大,不利于css的加载
5.svg格式了解多少?
基于xml语法格式的图像格式,可缩放矢量图。其他图像是基于像素的,SVG是属于对图像形状的描述,本质是文本文件,体积小,并且不管放大多少倍都不会失真
1.SVG可直接插入页面中,成为DOM一部分,然后用JS或CSS进行操作
2.SVG可作为文件被引入
3.SVG可以转为base64引入页面

6.了解过JWT吗
是JSON web token 缩写,通过JSON形式在web应用中的令牌,可以在各方之间安全的把信息作为JSON对象传输。
作用:信息传输、授权
JWT的认证流程:
1.前端把账户密码发送给后端的接口
2.后端核对账户密码成功后,把用户id等其他信息作为JWT负载,把它和头部分别进行base64编码拼接后签名,形成一个JWT(token)。
3.前端每次请求时,都会把JWT放在HTTP请求头的Authorization字段内
4.后端检查是否存在,如果存在就验证JWT的有效性(签名是否正确,token是否过期、接收方是否是自己等等)
5.验证通过后后端使用JWT中包含的用户信息进行其他的操作,并返回对应结果
简洁、包含性、跨语言;因为Token是JSON加密的形式保存在客户端,所以JWT是跨语言的,原则上是任何web形式都支持。
7.npm的底层环境是什么?
node package manager,node的包管理和分发工具,已经成为分发node模块的标准,是JS的运行环境
npm的组成:网站、注册表、命令行工具
8.防抖和节流是什么?
都是应对页面中频繁触发事件的优化方案
防抖:避免事件重复触发
使用场景:1.频繁和服务器交互 2.输入框的自动保存事件
节流:减少流量,把频繁触发的事件减少,每隔一段时间执行
使用场景:scroll事件
9.解释一下什么是json?
json是一种纯字符串形式的数据,它本身不提供任何方法,适合在网络中进行传输、
JSON数据存储在.json文件中,也可以把JSON数据以字符串的形式保存在数据库、Cookise中
JS提供了JSON.parse()JSON.stringify()
什么时候使用json:定义接口,序列化,生成tochen,配置文件package.json
10当数据没有请求过来的时候,该怎么做?
可以在渲染数据的地方给一些默认的值
if判断语句
11.有没有做过无感登录?
1.在相应其中拦截,判断token返回过期后,调用刷新token的接口
2.后端返回过期时间,前端判断token的过期时间,去调用刷新token的接口
3.写定时器,定时刷新token接口
流程:
1.登录成功后保存token和refresh_token
2.在响应拦截器中对401状态码引入刷新token的api方法调用
3.替换保存本地新的token
4.把错误对象里的token替换
5.再次发送未完成的请求
6.如果refresh_token过期了,判断是否过期,过期了就清除所有token重新登录
12. 大文件上传是怎么做的?
分片上传:
1.把需要上传的文件按照一定的规则,分割成相同大小的数据块
2.初始化一个分片上传任务,返回本次分片上传的唯一标识
3.按照一定的规则把各个数据块上传
4.发送完成后,服务端会判断数据上传的完整性,如果完整,那么就会把数据库合并成原始文件
断电续传:
服务端返回,从哪里开始,浏览器自己处理














 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









