






lxml库
1.库介绍
lxml是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高。
- 功能:
- 解析HTML
- 文件读取
- etree和XPath的配合使用
2.python库lxml的安装
windows系统下的安装:
#pip安装
pip3 install lxml
#wheel安装
#下载对应系统版本的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml
pip3 install lxml-4.2.1-cp36-cp36m-win_amd64.whl
linux下安装:
yum install -y epel-release libxslt-devel libxml2-devel openssl-devel
pip3 install lxml
3.lxml使用流程
lxml 库提供了一个 etree 模块,该模块专门用来解析 HTML/XML 文档
(1)导入模块
from lxml import etree
(2)创建解析对象
调用 etree 模块的 HTML() 方法来创建 HTML 解析对象
parse_html = etree.HTML(html)
HTML() 方法能够将 HTML 标签字符串解析为 HTML 文件,该方法可以自动修正 HTML 文本。
html_str = '''
<div>
<ul>
<li class="item1"><a href="link1.html">Python</a></li>
<li class="item2"><a href="link2.html">Java</a></li>
<li class="site1"><a href="c.biancheng.net">C语言中文网</a>
<li class="site2"><a href="www.baidu.com">百度</a></li>
<li class="site3"><a href="www.jd.com">京东</a></li>
</ul>
</div>
'''
html = etree.HTML(html_str)
result = etree.tostring(html)#将标签元素转化为字符串
print(result.decode('utf-8'))
运行结果:
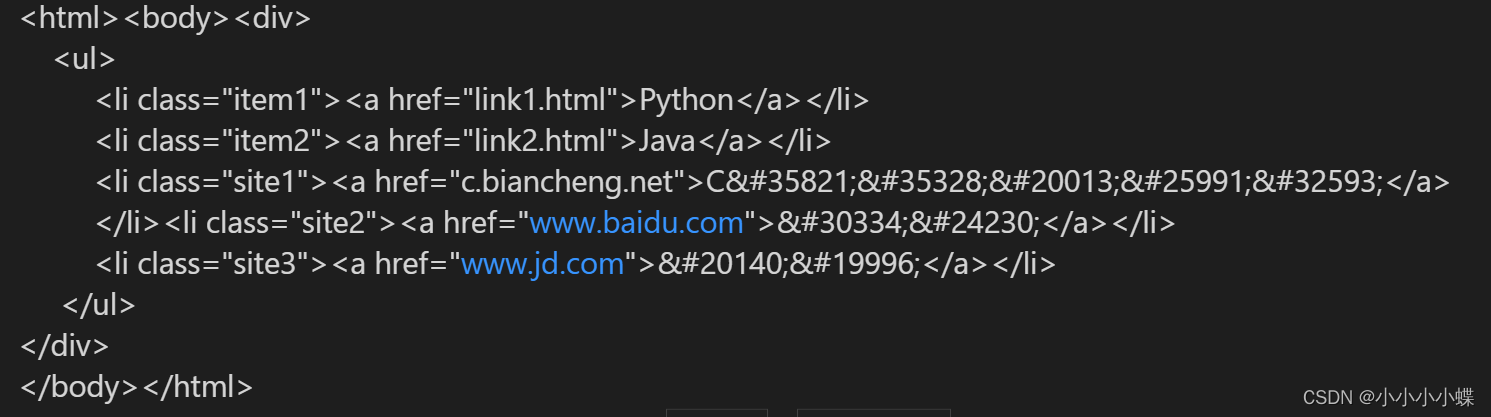
上述 HTML 字符串存在缺少标签的情况,比如“C语言中文网”缺少一个 闭合标签,当使用了 HTML() 方法后,会将其自动转换为符合规范的 HTML 文档格式。
(3)调用xpath表达式
最后使用第二步创建的解析对象调用 xpath() 方法,完成数据的提取
r_list = parse_html.xpath('xpath表达式')
4.XPath常用规则
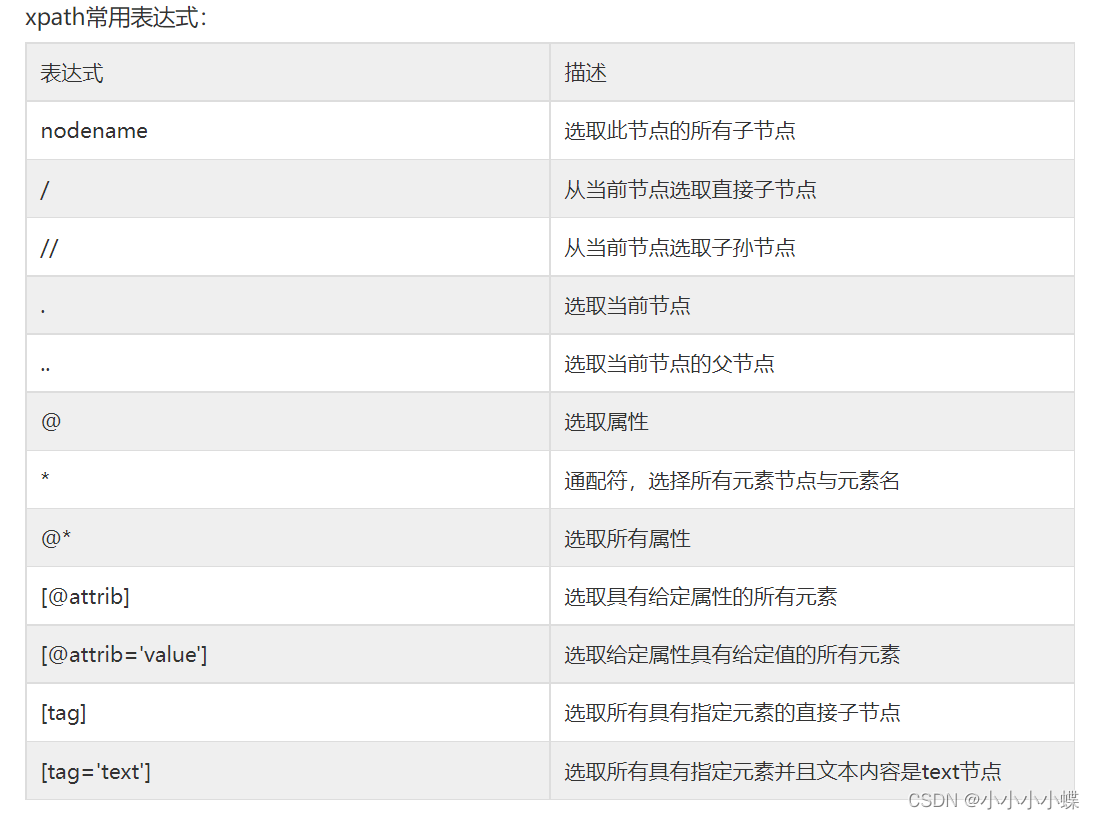
(1)文本输入与输出
lxml提供如下方式输入文本:
- fromstring():解析字符串
- HTML():解析HTML对象
- XML():解析XML对象
- parse():解析文件类型对象
(2)标签搜索
可以使用find、findall或者xpath来搜索Element包含的标签对象。区别如下:
- find():返回第一个匹配对象,并且xpath语法只能使用相对路径(以’.//’开头)
- findall():返回一个标签对象的列表,并且xpath语法只能使用相对路径(以’.//’开头)
- xpath():返回一个标签对象的列表,并且xpath语法的相对路径和绝对路径
>>> root = etree.XML("<root><a x='123'>aText<b/><c/><b/></a></root>")
>>> x=root.find('.//a[@x]')
>>> x
<Element a at 0x2242c10>
>>> x.text
'aText'
>>> x.tag
'a'
>>> x2=root.findall('.//a[@x]')
>>> x2
[<Element a at 0x2242c10>]
>>> type(x2)
<type 'list'>
>>> x3=root.xpath('//a[@x]')
>>> type(x3)
<type 'list'>
>>> x3
[<Element a at 0x2242c10>]
此外,lxml还支持css语法的选择方式,对于熟悉JQuery选择器的开发者是一个很好的补充(需要安装pip install cssselect):
>>> root = etree.XML("<root><a class='_123'>aText<b id='b1'/><c/><b/></a></root>")
>>> a1=root.cssselect('._123')
>>> a1[0].tag
'a'
>>> root = etree.XML("<root><a class='c123'>aText<b id='b1'/><c/><b/></a></root>")
>>> a1=root.cssselect('a')
>>> a1[0].text
'aText'
>>> a2=root.cssselect('.c123')
>>> a2[0].text
'aText'
>>> b=root.cssselect('#b1')
>>> b[0].tag
'b'
(3)读取文本解析节点
text='''
<div>
<ul>
<li class="item-0"><a href="link1.html">第一个</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0"><a href="link5.html">a属性</a>
</ul>
</div>
'''
html = etree.HTML(text) #初始化生成一个XPath解析对象
result = etree.tostring(html,encoding = 'utf-8') #解析对象输出代码
print(type(html))
print(type(result))
print('\n')
print(result.decode('utf-8'))
运行结果:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qKIOIGIO-1652436223627)(C:\Users\zhuxiaodie\AppData\Roaming\Typora\typora-user-images\image-20220308193600416.png)]](https://img-blog.csdnimg.cn/72a407b23c1f409392547c53ad3f41f1.png)
(4)读取HTML文件进行解析
html = etree.parse('page1.html',etree.HTMLParser()) #指定解析器HTMLParser会根据文件修复HTML文件中缺失的如声明信息
result = etree.tostring(html)
print(type(html))
print(type(result))
print('\n')
print(result.decode(encoding = 'utf-8'))
运行结果:

(5)获取所有节点
返回一个列表每个元素都是Element类型,所有节点都包含在其中
html = etree.parse('page1.html',etree.HTMLParser())
result = html.xpath('//*') #//代表获取子孙节点,*代表获取所有
print(type(html))
print(type(result))
print('\n')
print(result)
运行结果:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-znm39cAT-1652436223628)(C:\Users\zhuxiaodie\AppData\Roaming\Typora\typora-user-images\image-20220308200101382.png)]](https://img-blog.csdnimg.cn/deb7b152216f453bac379772f8b9141b.png)
如要获取li节点,可以使用//后面加上节点名称,然后调用xpath()方法
html.xpath('//li') #获取所有子孙节点的li节点(4)获取子节点
运行结果:
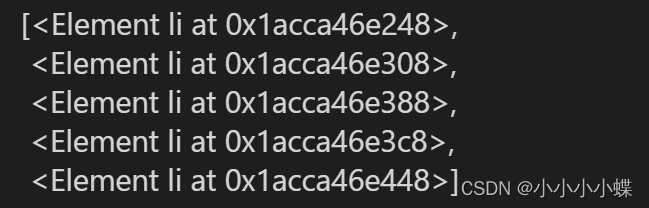
(6)获取子节点
通过/或者//即可查找元素的子节点或者子孙节点
result=html.xpath('//li/a')
运行结果:

(7)获取父节点
要查找父节点可以使用…来实现也可以使用parent::来获取父节点
text='''
<div>
<ul>
<li class="item-0"><a href="link1.html">第一个</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
</ul>
</div>
'''
html=etree.HTML(text,etree.HTMLParser())
result=html.xpath('//a[@href="link2.html"]/../@class')
result1=html.xpath('//a[@href="link2.html"]/parent::*/@class')
print(result)
print(result1)
运行结果:

(8)属性匹配
在选取的时候,我们还可以用@符号进行属性过滤。比如,这里如果要选取class为item-1的li节点,
text='''
<div>
<ul>
<li class="item-0"><a href="link1.html">第一个</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
</ul>
</div>
'''
html=etree.HTML(text,etree.HTMLParser())
result=html.xpath('//li[@class="item-1"]')
print(result)
运行结果:

(9)文本获取
用XPath中的text()方法获取节点中的文本
html=etree.HTML(text,etree.HTMLParser())
result=html.xpath('//li[@class="item-1"]/a/text()') #获取a节点下的内容
result1=html.xpath('//li[@class="item-1"]//text()') #获取li下所有子孙节点的内容
print(result)
print(result1)
运行结果:

(10)属性获取
使用@符号即可获取节点的属性
result=html.xpath('//li/a/@href') #获取a的href属性
result=html.xpath('//li//@href') #获取所有li子孙节点的href属性

(11)属性多值匹配
如果某个属性的值有多个时,可以使用contains()函数来获取
html=etree.HTML(text,etree.HTMLParser())
result=html.xpath('//li[@class="aaa"]/a/text()')
result1=html.xpath('//li[contains(@class,"aaa")]/a/text()')
#通过第一种方法没有取到值,通过contains()就能精确匹配到节点了
print(result)
print(result1)
运行结果:

(12)多属性匹配
根据多个属性确定一个节点,这时就需要同时匹配多个属性,此时可用运用and运算符来连接使用
html=etree.HTML(text,etree.HTMLParser())
result=html.xpath('//li[@class="aaa" and @name="fore"]/a/text()')
result1=html.xpath('//li[contains(@class,"aaa") and @name="fore"]/a/text()')
运行结果:

(13)按序选择
有时候,我们在选择的时候某些属性可能同时匹配多个节点,但我们只想要其中的某个节点,如第二个节点或者最后一个节点,这时可以利用中括号引入索引的方法获取特定次序的节点
html=etree.HTML(text1,etree.HTMLParser())
result=html.xpath('//li[contains(@class,"aaa")]/a/text()') #获取所有li节点下a节点的内容
result1=html.xpath('//li[1][contains(@class,"aaa")]/a/text()') #获取第一个
result2=html.xpath('//li[last()][contains(@class,"aaa")]/a/text()') #获取最后一个
result3=html.xpath('//li[position()>2 and position()<4][contains(@class,"aaa")]/a/text()') #获取第三个
result4=html.xpath('//li[last()-2][contains(@class,"aaa")]/a/text()') #获取倒数第三个
运行结果:
















 9780
9780











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









