






文章目录
一、分析 Linux 内核创建一个新进程的过程
1、阅读理解 task_struct 数据结构
2、分析 fork 函数对应的内核处理过程 sys_clone,理解创建一个新进程如何创建和修改 task_struct 数据结构
3、使用 gdb 跟踪分析一个 fork 系统调用内核处理函数 sys_clone ,验证自己对 Linux 系统创建一个新进程的理解, 特别关注新进程是从哪里开始执行的?为什么从那里能顺利执行下去?即执行起点与内核堆栈如何保证一致。
4、根据本周所学知识分析 fork 函数对应的系统调用处理过程
二、实验过程
1.阅读理解 task_struct 数据结构
task_struct 数据结构是 Linux 内核中用于表示进程或线程的核心数据结构。它包含了大量的字段,用于管理和维护进程的各个方面。其中一些关键字段包括进程状态、内核堆栈、引用计数、进程标志、调试标志、唤醒信息、CPU信息等。task_struct 中的信息用于实现进程调度、资源管理、进程间通信、调试和跟踪等功能。task_struct设计复杂,是Linux 内核对进程管理的高度精细控制,确保操作系统能够有效地管理多个进程的执行,提供了强大的多任务处理能力。
以下是借助ChatGPT进行进一步分析如下:

2.分析 fork 函数对应的内核处理过程 sys_clone,理解创建一个新进程如何创建和修改 task_struct 数据结构
fork 是一个创建新进程的系统调用,它以当前进程(父进程)为模板,创建一个几乎完全相同的新进程(子进程)。新进程是父进程的副本,但两者在执行上下文和资源方面是独立的。这种能力是实现多任务处理的基础,允许一个进程创建并控制其他进程。fork 系统调用对应的内核处理过程实际上是通过 sys_clone 来实现的。
① fork系统调用(fork.c):
当用户进程调用 fork 时,它实际上是在用户空间发出了一个系统调用请求,请求内核创建一个新进程。fork 函数的工作步骤如下:
1、父进程通过fork调用陷入到内核(系统调用中断),内核创建一个新的 task_struct 结构体,作为子进程的描述。
2、内核为子进程分配一个独立的进程ID(PID)。
3、内核复制父进程的内存布局到子进程,包括代码段、数据段、栈等。
4、内核复制父进程打开文件描述符表,以便子进程能够访问相同的文件。 内核创建子进程的内核堆栈。
5、最后,内核将子进程标记为可执行,并设置返回值0(在父进程中)或子进程的PID(在子进程中)。 此后,fork 函数返回两次,一次对于父进程,一次对于子进程。
在C库中,fork 函数被调用时,实际上是使用 syscall 指令来触发系统调用,这将调用 do_fork 函数。以下是 do_fork 函数的关键代码:
asmlinkage long do_fork(unsigned long clone_flags, unsigned long stack_start,
struct pt_regs *regs, unsigned long stack_size,
int __user *parent_tid, int __user *child_tid) {
struct task_struct *p;
struct pid *pid;
int trace = 0;
struct task_struct *tracee;
struct pid *tracee_pid;
// 创建新的 task_struct 数据结构
p = dup_task_struct(current);
if (!p)
return -ENOMEM;
// 复制或共享父进程的内存布局(代码、数据、栈等)
// 复制或共享其他资源(例如文件描述符、信号处理程序等)
// 初始化新进程的状态等字段
p->state = TASK_RUNNING;
p->pid = alloc_pid(p);
// 将新进程添加到调度队列
// ...
return p->pid;
}
② sys_clone(kernel/fork.c):
内核处理 fork 系统调用时实际上调用了 sys_clone 函数,因为fork 实际上是 sys_clone 系统调用的一种特殊形式,它传递了一组标志位和参数。以下创建进程内核部分的关键步骤如下:
1、sys_clone 检查父进程的权限和参数是否有效,并为新进程分配一个唯一的PID。
2、设置新进程的状态、进程组等属性。
3、调用copy_process 函数,它复制了父进程的 task_struct结构和其他进程数据。这包括复制虚拟地址空间,文件描述符,信号处理程序等。
4、copy_process return后,内核为新进程安排调度并在需要时分配CPU。
以下是 sys_clone 的代码,能体现出sys_clone与 do_fork 函数之间的关系
asmlinkage long sys_clone(unsigned long clone_flags, unsigned long newsp,
int __user *parent_tid, int __user *child_tid,
unsigned long tls) {
// 获取当前进程的寄存器上下文
struct pt_regs *regs = current_pt_regs();
// 调用内核的 do_fork 函数来创建新进程
return do_fork(clone_flags, newsp, regs, 0, parent_tid, child_tid);
}
③ 如何创建新进程和修改 task_struct 数据结构
如何创建新进程和修改 task_struct 数据结构在①②中其实已经涉及,这里补充ChatGPT的理解:
3.gdb 跟踪分析
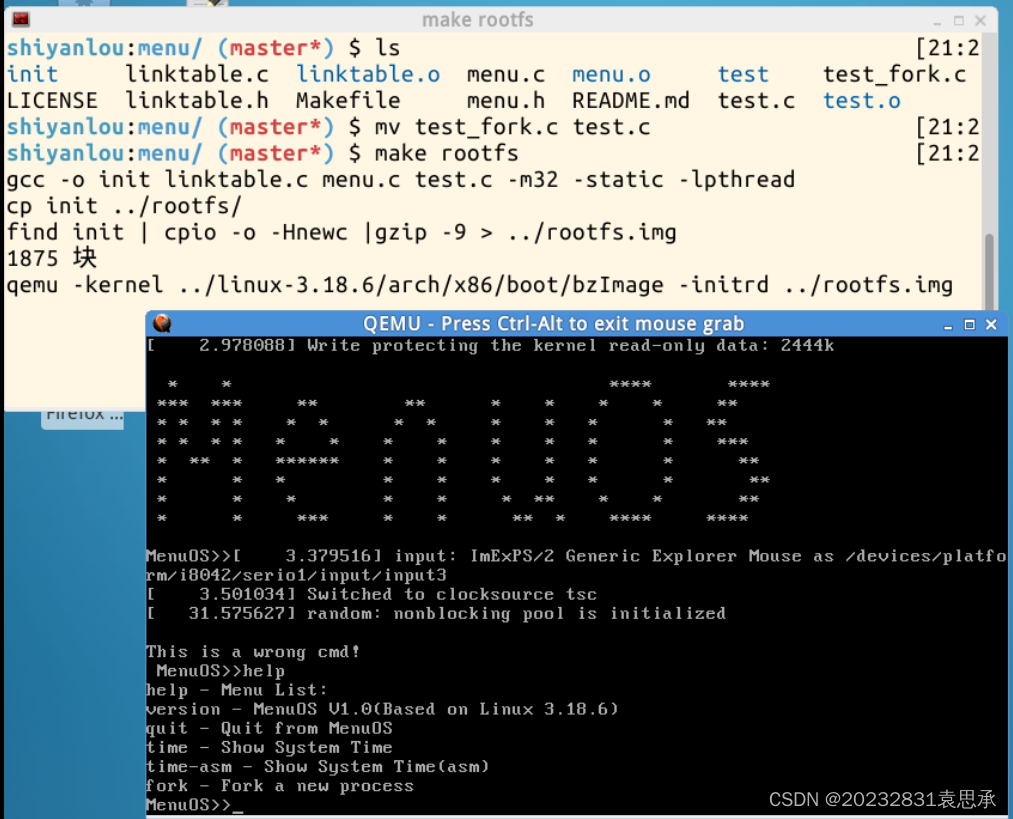
1、与以前几次实验一样,先重新编译新内核的menu,再将test_fork.c覆盖在运行程序test.c上
cd ~/LinuxKernel
rm menu -rf
git clone https://github.com/mengning/menu.git
cd menu
mv test_fork.c test.c//在MenuOS中增加fork命令,并覆盖掉test.c文件
make rootfs
MenuOS>>help
2、使用gdb对fork()函数进行跟踪分析
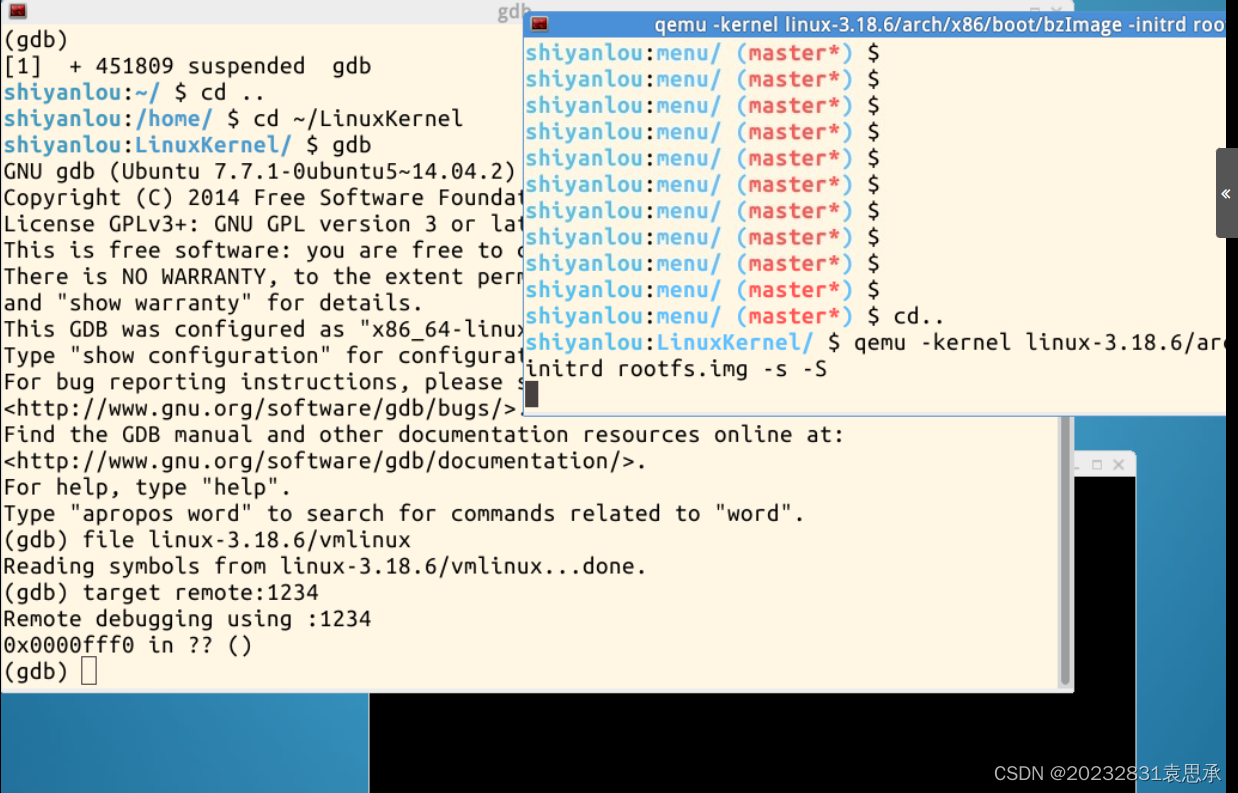
与之前几次实验一样,首先进入一个冻结内核,然后打开一个空shell,再进行gdb调试:
进入冻结内核:
cd LinuxKernel
qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd rootfs.img -s -S //冻结内核的启动
新打开一个空shell,进入gdb调试,并建立连接:
cd LinuxKernel
gdb
(gdb)file linux-3.18.6/vmlinux
(gdb)target remote:1234
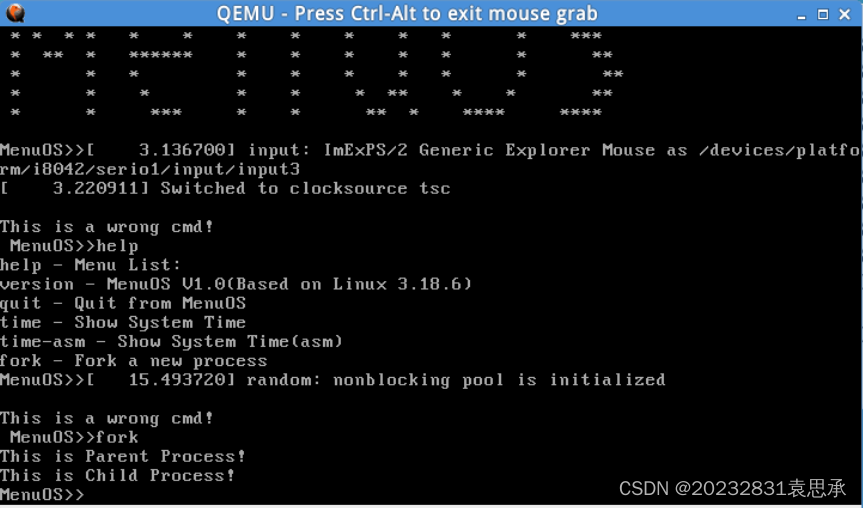
冻结的内核开始运行后,输入fork可发现fork输出了父进程和子进程,说明fork调用成功。
3、下面进入fork的调试:
分别对系统调用sys_clone、do_fork、dup_task_struct、copy_process、copy_thread、ret_from_fork设置断点进行单步调试
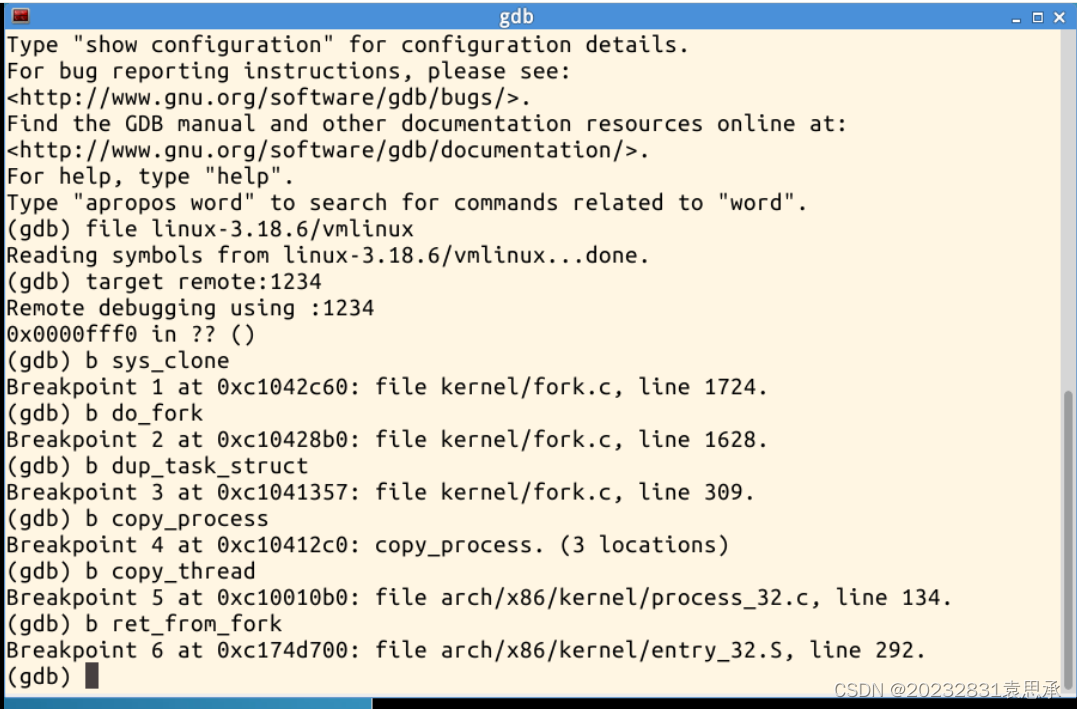
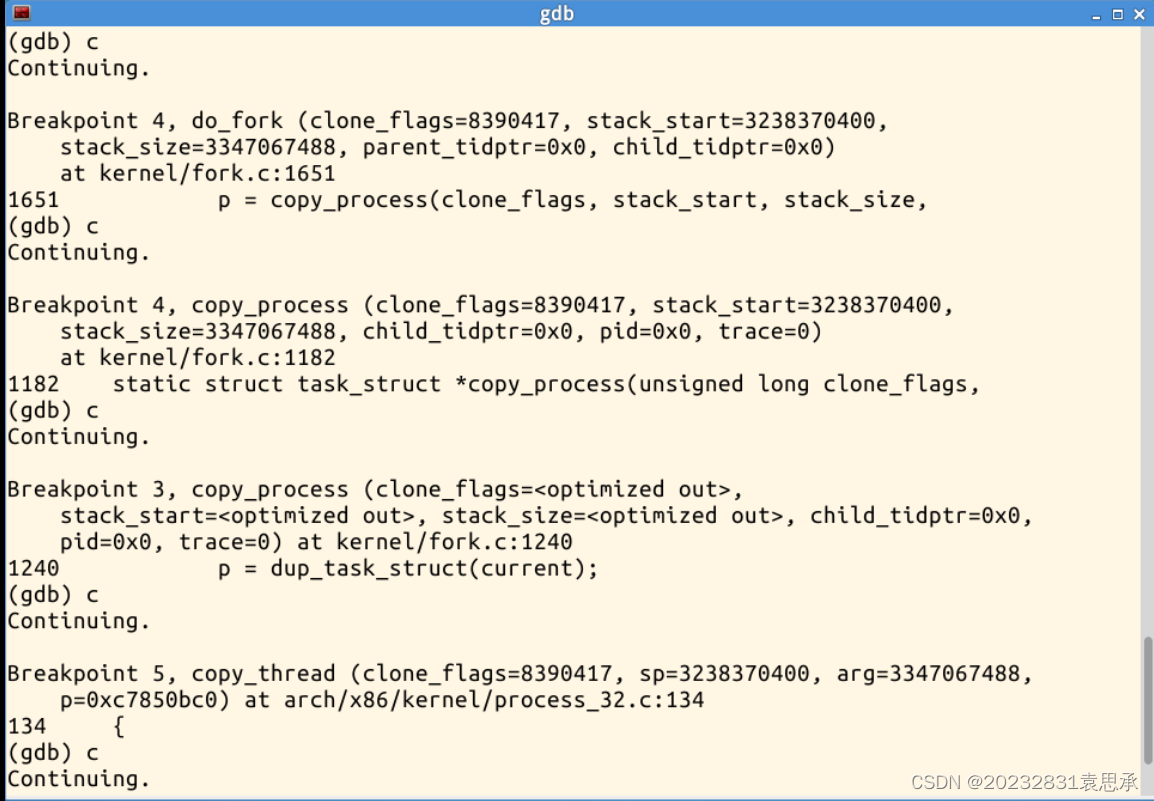
4.分析 fork 函数对应的系统调用处理过程
fork 函数在Linux内核中用于创建新进程,它实际上是一个系统调用,用于复制当前父进程的状态来创建一个新进程,这个新进程就是子进程。该函数的系统调用过程过程包含多个内核函数,主要是do_fork函数,它负责完成子进程的创建和初始化,并调用copy_process函数,用于复制父进程的关键数据结构,包括文件描述符表、内存映射、信号处理程序等。copy_thread函数也比较重要,它可以复制内核堆栈的内容,以确保新进程拥有独立的内核堆栈。
三、Chatgpt帮助

总结
通过本次实验,进一步了解了Linux 内核创建一个新进程的过程,即fork系统调用函数的运行过程,懂得了为什么会出现”一次调用,两次运行“的情况,从而对Linux内核有了新的理解。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









