







Mongo的基本shell操作
初始MongoDB
Linux 端启动 MongoDB 服务
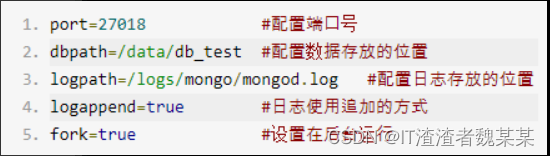
在 /data 路径下创建文件夹 db_test 来存放 MongoDB 服务的数据。(数据存放位置)
cd /data #进入data路径
mkdir db_test #创建db文件夹
在 /logs 路径下创建文件夹 mongo 存放日志文件 mongod.log(文件不用创建,到时候会自动生成,但路径即文件夹必须提前创建好)。(日志文件)
mkdir /logs #创建/logs路径
cd /logs #进入log路径
mkdir mongo #创建mongo文件夹
在 /etc/mongod(没有路径就创建)路径下新建配置文件 mongod.conf,使用配置文件启动 MongoDB 服务(把命令写入配置文件,以后启动服务就不用再输入一长串的命令,直接启动配置文件即可)。
启动客户端
mongo --port 27017(端口号)
退出客户端
exit
关闭 MongoDB 服务
能连接到客户端时:
use admin #使用系统数据库admin,只有在admin数据库中才可以进行关闭服务的操作
db.shutdownServer() #关闭服务
客户端无法连接时:
查看 Mongo 相关进程 ps -ef | grep mongo
kill 和 Mongo 的服务进程 kill进程号码
数据库的基本操作
创建数据库
MongoDB安装完成后,可以通过pgrep mongo -l命令来查看是否已经启动。
在操作数据库之前,需要连接它,连接本地数据库服务器,输入命令:mongo
创建数据库命令:use Testdb(如果数据库不存在,则创建数据库,否则切换到指定数据库)
查看所有数据库我们可以用命令:show dbs
然而并没有我们刚创建的Testdb数据库。要想显示它,我们需要向数据库插入一些数据:db.Testdb.insert({_id:1,name:"王小明"}):
删除数据库
MongoDB删除数据库需要先切换到该数据库中:use Testdb 然后执行删除命令:db.dropDatabase()
集合操作
MongoDB数据库中的集合相当于MySQL数据库中的表。
- 先进入指定数据库
Testdb:use Testdb - 显示所有集合 show collections
- 创建集合命令:db.集合名.insert()。(注意:一条数据用大括号{}括起来,多条数据用[]将所有数据括起来) 例:
db.mytest2.insert([{"name" : "王小明","sex":"男"},{"name" : "李小红","sex":"女"}]) - 查询集合命令:db.集合名.find()。
- 删除集合命令:db.集合名.drop()。
文档操作
插入文档命令
:db.集合名.insert(文档)。
document=({_id:1,
name: '魏建新',
sex: '男',
hobbies: ['乒乓球','羽毛球'],
birthday: '2002-09-12'
});
db.person.insert(document)
//person是集合名,如果该集合不在该数据库中,MongoDB会自动创建该集合并插入文档
更新文档
主要用到了:update()和save()方法。
用update()方法来更新person的数据,把王小明的出生日期替换成1996,命令如下:
db.person.update({birthday:"1996-02-14"},{$set:{birthday:"1996"}})
save()方法通过传入的文档来替换已有文档。
db.person.save({
"_id" :1,
"name" : "李小红",
"sex" : "女",
"hobbies" : [
"画画",
"唱歌",
"跳舞"
],
"birthday" : "1996-06-14"
})
或:db.person.save(newdocument)
查询文档
-
pretty()方法,使输出更整齐 -
条件查询
| 操作 | 格式 | 范例 | 关系数据库中类似的语句 |
|---|---|---|---|
| 等于 | {<key>:<value>} | db.stu1.find({“name”:“李小红”}).pretty() | where name = ‘李小红’ |
| 小于 | {<key>:{$lt:<value>}} | db.stu1.find({“age”:{$lt:18}}).pretty() | where age < 18 |
| 小于或等于 | {<key>:{$lte:<value>}} | db.stu1.find({“age”:{$lte:18}}).pretty() | where age <= 18 |
| 大于 | {<key>:{$gt:<value>}} | db.stu1.find({“age”:{$gt:18}}).pretty() | where age > 18 |
| 大于或等于 | {<key>:{$gte:<value>}} | db.stu1.find({“age”:{$gte:18}}).pretty() | where age >= 18 |
| 不等于 | {<key>:{$ne:<value>}} | db.stu1.find({“age”:{$ne:18}}).pretty() | where age != 18 |
- AND条件
find()方法可以传入多个键(key),每个键(key)以逗号隔开,即常规SQL的AND条件。如查询集合stu1中年龄为20岁的男性信息:
db.stu1.find({"age":20, "sex":"男"}).pretty()
删除文档数据
删除指定的数据:db.stu1.remove({'age':20}) //删除年龄为20的数据
删除全部数据(集合并不会删除):db.stu1.remove({})
MongoDB文档的高级查询操作
数据的导入与导出
数据导入
数据导入工具:mongoimport;
mongoimport -d Testdb1 -c score --type csv --headerline --ignoreBlanks --file test.csv
- -d Testdb1 :指定将数据导入到 Testdb1 数据库;
- -c score :将数据导入到集合 score ,如果这个集合之前不存在,会自动创建一个(如果省略 --collection 这个参数,那么会自动新建一个以 CSV 文件名为名的集合);
- –type csv :文件类型,这里是 CSV;
- –headerline :这个参数很重要,加上这个参数后创建完成后的内容会以 CSV 文件第一行的内容为字段名(导入json文件不需要这个参数);
- –ignoreBlanks :这个参数可以忽略掉 CSV 文件中的空缺值(导入json文件不需要这个参数);
- –file 1.csv :这里就是 CSV 文件的路径了,需要使用绝对路径。
数据导出
数据导出工具: mongoexport;
#导出 json 格式文件:
mongoexport -d Testdb1 -c score -o /file.json --type json
- -o /file.json :输出的文件路径/(根目录下)和文件名;
- –type json :输出的格式,默认为 json。
#导出 csv 格式的文件:
mongoexport -d Testdb1 -c score -o /file.json --type csv -f "_id,name,age,sex,major"
- -f :当输出格式为 csv 时,需要指定输出的字段名。
高级查询
假设有集合 hobbies 内容如下:
| _id | name | sex | hobbies |
|---|---|---|---|
| 1 | 小红 | 女 | 唱歌,跳舞,羽毛球 |
| 2 | 小明 | 男 | 唱歌,乒乓球,羽毛球 |
| 3 | 小亮 | 男 | 乒乓球,羽毛球 |
$all 匹配所有
#查询其中所有喜欢“唱歌”和“羽毛球”的人:
db.hobbies.find({hobbies:{$all:["唱歌","羽毛球"]})
$exists 判断字段是否存在
#查询 hobbies 集合中存在 age 字段的文档:
db.hobbies.find({age:{$exists:true}})
#hobbies 集合中不存在 age 字段的文档:
db.hobbies.find({age:{$exists:false}})
$mod 取模运算
#查询 age 取模7等于4的文档:
db.hobbies.find({age:{$mod:[7,4]}})
$in 包含
#查询 age =17或 age =20的文档 :
db.hobbies.find({age:{$in:[17,20]}})
$nin 不包含
#查询 age !=17且 age !=20的文档:
db.hobbies.find({age:{$nin:[17,20]}})
$size 数组元素个数
#可以查询特定长度的数组,比如 hobbies 这一字段,查询有两个爱好的文档:
db.hobbies.find({hobbies:{$size:2}})
查询结果排序
db.collection.find().sort({_id:1}) #将查询结果按照_id升序排序
db.collection.find().sort({_id:-1}) #将查询结果按照_id降序排序
假设数据库有集合 student 如下:
| _id | name | age | sex | major |
|---|---|---|---|---|
| 1 | 王晓丽 | 19 | 女 | 计算机 |
| 2 | 张明 | 21 | 男 | 计算机 |
| 3 | 秋雅 | 20 | 女 | 播音主持 |
| 4 | 张欣欣 | 18 | 女 | 表演 |
$or 条件之间的或查询
#$or 表示多个查询条件之间是或的关系,比如查询性别 sex 为 男 或年龄 age 为18的文档信息:
db.student.find({$or:[{sex:"男"},{age:18}]})
$and 条件之间的且查询
#$and表示多个查询条件之间是且的关系,比如查询年龄 age 大于18且小于21(18 < age < 21)的信息:
db.student.find({$and:[{age:{$gt:18}},{age:{$lt:21}}]})
$not 条件取反查询
#$not 用来执行取反操作,比如查询年龄 age 大于等于20岁,然后进行取反(即查询年龄小于20岁的文档):
db.student.find({age:{$not:{$gte:20}}})
正则表达式匹配查询
#查询不符合major=计*开头文档:
db.student.find({major:{$not:/^计.*/}})
count() 返回结果集总数
#比如返回上一步正则查询到的结果集有几条:
db.student.find({major:{$not:/^计.*/}}).count()
游标
什么是游标
通俗的说,游标不是查询结果,而是查询的返回资源,或者接口。通过这个接口,你可以逐条读取。就像 fopen 打开文件,得到一个资源一样,通过资源,可以一行一行的读文件。
使用循环插入数据
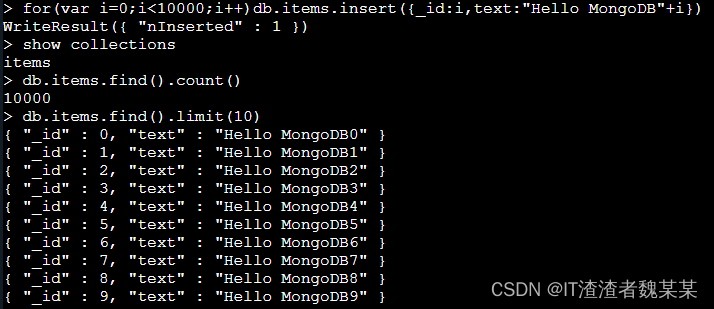
#我们首先插入10000条数据到集合 items,因为 mongodb 底层是 javascript 引擎,所以我们可以使用 js 的语法来插入数据:
for(var i=0;i<10000;i++)db.items.insert({_id:i,text:"Hello MongoDB"+i})
声明游标
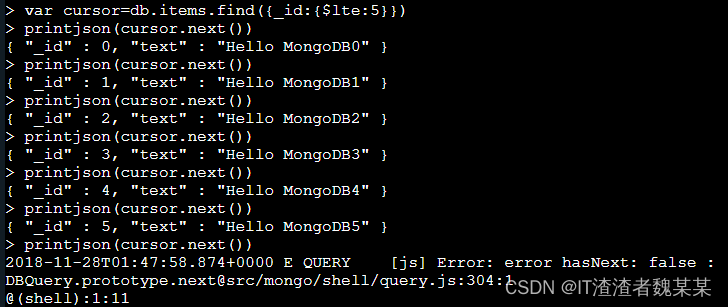
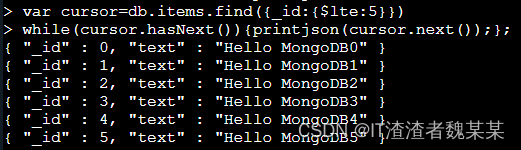
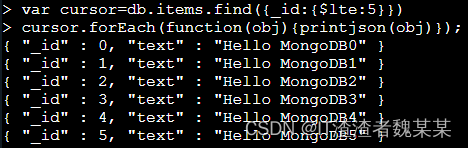
#定义一个变量来保存这个游标,find 的查询结果(_id<=5)赋值给了游标 cursor 变量,代码如下:
var cursor=db.items.find({_id:{$lte:5}})
打印游标中的数据信息
- printjson(cursor.next()) 打印下一条数据
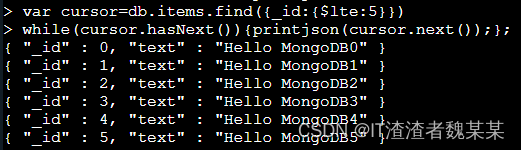
- 使用 js 的 while 语法来循环打印
- 使用 for 循环打印
- 使用 forEach 打印
游标的使用场景
我们可以在分页的情况下使用游标。
假设每页有10行,我们查询第701页,可以配合 skip() 和 limit() 来实现,具体步骤如图所示:
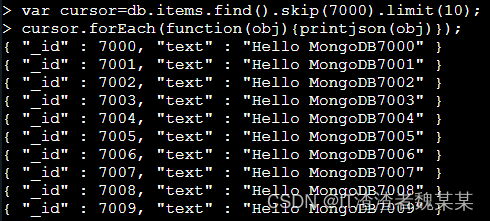
如果不想全部取出,只取出某一个,可以使用如下方法,取出数组下标,具体步骤如图所示:
















 3161
3161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









