







论文笔记:Large Language Models are Universal Tabular Classifiers
关于利用LLMs进行表格数据预测的文章
一、知识速递
1.1 判别式建模(传统)
传统的表格数据预测使用判别式建模通常涉及以下步骤:
场景:预测房价
假设我们有一组关于房屋的数据,包括房屋的面积(平方米)、房间数量、建造年份、地理位置等特征,以及我们想要预测的目标——房屋的售价。
-
步骤 1: 数据收集
首先收集大量房屋的这些特征和对应的售价。
-
步骤 2: 特征选择
在判别式建模中,我们会选择与房价最相关的特征,比如房屋面积、房间数量、建造年份等。
-
步骤 3: 模型训练
接下来,我们使用这些特征来训练一个判别式模型。这个模型会学习这些特征与房价之间的关系。例如,我们可能会使用线性回归模型,它试图找到一个线性方程来描述特征和房价之间的关系(这里的a、b、c 等是模型通过训练数据学习到的系数):
房价 = a × 面积 + b × 房间数量 + c × 建造年份 + … \text{房价} = a \times \text{面积} + b \times \text{房间数量} + c \times \text{建造年份} + \ldots 房价=a×面积+b×房间数量+c×建造年份+…
-
步骤 4: 模型评估
在训练过程中,我们会使用一部分数据来评估模型的性能,确保它能够准确地预测房价。
-
步骤 5: 模型应用
一旦模型训练完成并且评估表现良好,我们就可以用它来预测新房屋的售价。例如,如果一个新房屋的面积是120平方米,有3个房间,建造于2000年,我们就可以将这些值代入我们的模型方程中,得到一个预测的售价。
-
判别式建模的特点:
- 直接关系:模型直接学习特征和目标(房价)之间的关系。
- 特定任务:这个模型专门用于预测房价,如果我们要预测租金,就需要重新训练一个模型。
- 依赖训练数据:模型的准确性很大程度上依赖于训练数据的质量和相关性。
-
通俗解释:
想象一下,你是一个房地产经纪人,你有很多房子的资料,包括它们的大小、房间数量、新旧程度等。你想要预测这些房子能卖多少钱。你收集了很多已经卖出的房子的数据,然后你用这些数据来训练一个模型,这个模型就像是一个经验丰富的经纪人,它能够根据房子的特征来告诉你大概能卖多少钱。这就是判别式建模在表格数据预测中的应用。
1.2 生成式建模(本文提出)
生成式建模在表格数据预测中的应用是一种新颖的方法,它与传统的判别式建模不同,不是直接学习输入特征和输出标签之间的映射关系,而是试图学习数据的生成过程。这种方法可以提供数据的内在结构和分布,从而在预测时能够生成新的数据点或预测值。(后续详细解释)
二、方法和实现
2.1 提出问题
2.1.1 问题一:Universal Tabular Modeling(通用表格模型)选取
UniPredict框架的目标是开发一个能够处理任何领域数据集的通用表格预测模型(Universal tabular models)(图1 c),该模型通过利用元数据来适应不同的数据集和预测任务,从而实现更灵活和通用的预测能力,以下是传统的表格模型与Universal tabular models对比。
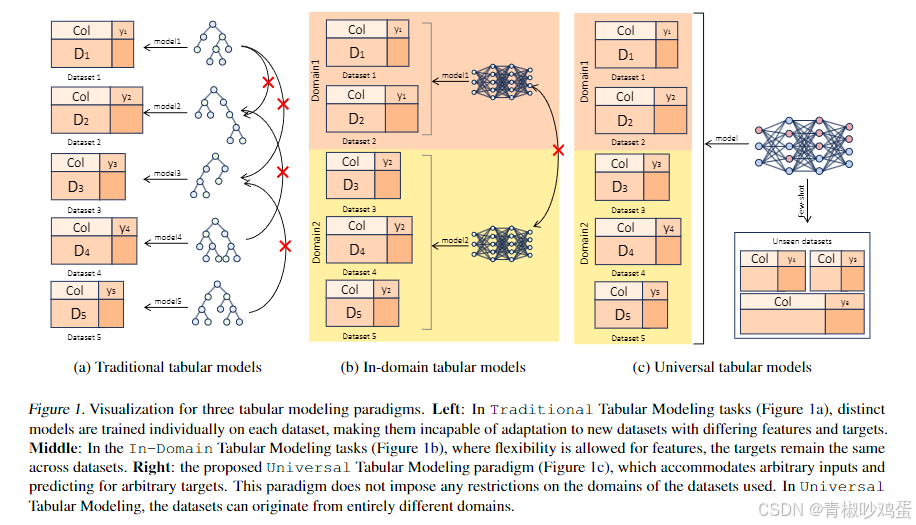
(a) 传统表格模型(Traditional Tabular Models)
- 特点:每个数据集都有独立的模型。这意味着对于每个数据集,都需要训练一个特定的模型来预测该数据集的目标变量。
- 限制:这种方法缺乏灵活性,因为每个模型都是为特定的数据集和目标变量定制的。如果数据集的特征或目标变量发生变化,模型就无法适应,需要重新训练。
- 图示:每个数据集(Dataset 1, 2, 3, 4, 5)都有对应的模型(model1, model2, model3, model4, model5),这些模型不能跨数据集使用。
(b) 领域内表格模型(In-domain Tabular Models)
- 特点:在领域内,允许特征的灵活性,但目标变量在数据集之间保持一致。这意味着模型可以处理具有不同特征的数据集,但预测的目标是相同的。
- 限制:虽然在特征上提供了一定的灵活性,但模型仍然局限于特定的目标变量。如果需要预测不同的目标,可能需要重新训练模型或调整模型结构。
- 图示:两个领域(Domain1 和 Domain2)中的数据集共享相同的模型(model1 和 model2),但这些模型只能处理特定领域内的数据。
(c) 通用表格模型(Universal Tabular Models)
- 特点:这种范式允许任意输入和预测任意目标。这意味着一个模型可以处理来自完全不同领域的数据集,并且能够预测不同的目标变量。
- 优势:提供了极大的灵活性和泛化能力。一个模型可以适应各种不同的数据集和预测任务,无需为每个新任务重新训练模型。
- 图示:一个通用模型可以处理来自不同领域的数据集(如 Domain1 和 Domain2),并且可以预测不同的目标变量(如 y1, y2, y3, y4, y5)。此外,这个模型还可以处理未见过的(Unseen datasets)数据集。
2.1.2 问题二:Few-shot Learning(少量样本学习)
期望模型在只有少量标注数据的情况下,也能够对新目标进行有效预测。这表明模型需要具备良好的泛化能力,能够在资源有限的情况下快速适应新任务。
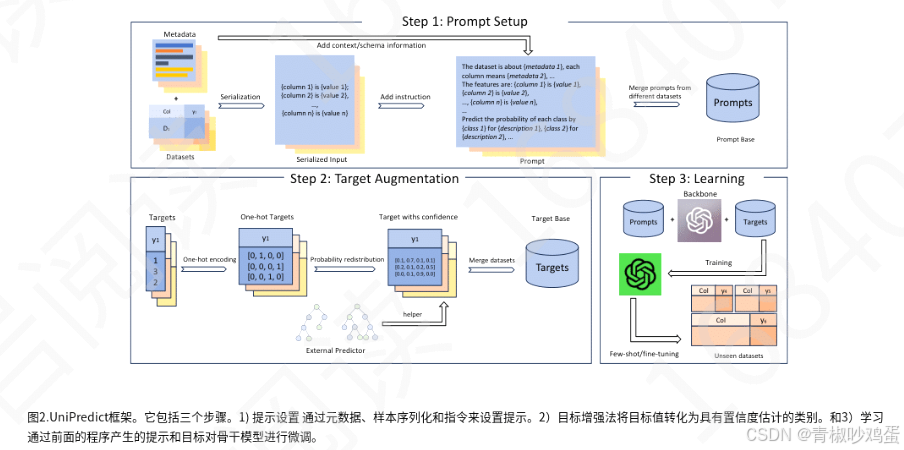
这张图详细展示了UniPredict框架的三个主要步骤,每个步骤都对应于处理表格数据和训练模型的不同阶段。以下是对图中每个步骤的解释:
(a) Prompt Setup(提示设置)
- 目的:为模型提供必要的上下文信息,以便它能够理解数据的结构和预测任务。
- 过程:
- Metadata(元数据):包括数据集的描述,如数据集是关于什么的,每个列的含义等。
- Serialization(序列化):将数据集中的每个样本转换为字符串格式,如“[column 1] is (value 1); [column 2] is (value 2); …”。
- Add Instruction(添加指令):明确模型需要执行的任务,如“Predict the probability of each class by [class 1] for (description 1); [class 2] for (description 2); …”。
- Prompts(提示):将上述信息合并成模型可以理解的提示。
(b) Target Augmentation(目标增强)
- 目的:将目标变量转换为模型可以处理的格式,并提供置信度估计。
- 过程:
- Targets(目标):原始的目标变量。
- One-hot Targets(独热编码目标):将目标变量转换为独热编码格式,这是一种常见的机器学习技术,用于将分类变量转换为模型可以处理的数值格式。
- Target with confidence(带置信度的目标):为每个目标类别分配一个置信度值,这可以是模型预测的置信度,或者是通过其他方法估计的。
- Target Base(目标基础):将所有数据集的目标合并,形成一个统一的目标基础。
(c) Learning(学习)
- 目的:使用前两步生成的提示和目标来微调模型。
- 过程:
- Backbone(骨干网络):模型的主干部分,通常是预训练的深度学习模型。
- Prompts + Targets(提示+目标):将提示和目标一起用于训练模型。
- Training(训练):使用这些提示和目标对模型进行微调,使其能够根据输入数据预测目标变量。
- Few-shot/Fine-tuning(少样本/微调):在少量数据上进行微调,以适应特定的预测任务。
- Unseen datasets(未见数据集):模型还可以处理在训练过程中未见过的数据集。
2.2 Prompt Engineering(提示工程)
这部分内容主要讲述了在UniPredict框架中如何将表格数据转换为大型语言模型(LLMs)能够理解的自然语言输入,这个过程被称为提示工程(Prompt Engineering)。
-
提示工程的重要性:
- 表格数据需要被转换成自然语言输入,以便LLMs能够理解。
- 自然语言输入的质量对LLMs的性能有重大影响。
-
输入提示的构建:
- 基于数据集D={M, S; T},定义了一个函数prompt(M, S, I),它接受预处理后的元数据M、表格样本S和指令I作为输入,并通过序列化产生LLMs的自然语言输入。
- 元数据M:代表数据集的上下文和模式定义的序列化描述。
- 表格样本S:代表原始样本内容的序列化。
- 指令I:包含指导LLMs对目标进行最终预测的指导,例如每个目标类别的概率预测。
-
元数据重格式化:
- 由于UniPredict需要适应具有不同模式的广泛表格数据集,数据集的元数据在促进这些多样化表格数据的语言建模中起着至关重要的作用。
- 许多表格列可能是缩写或使用私有字典编码,这使得LLMs难以理解表格输入。
- 提出了一个函数reformat(M),用于将任意输入M整合为(1)要预测的目标的描述和(2)特征的语义描述。
- 使用GPT-3.5来自动化元数据重格式化过程。
-
特征序列化:
- 给定原始元数据M和样本S,定义了一个函数serialize(c, v),它根据列名c和特征值v产生字符串输出,其中c属于reformat(M),v属于S。
- 每个值都与相应的列配对,格式为“{column} is {value}, {column} is {value}, …”。
- 在标记化之前,将数值四舍五入到固定的精度,并且可能会考虑更多依赖数据的分箱方法,如自适应直方图分箱。
-
附录中的示例:
- 提供了用于元数据重格式化和特征序列化的示例过程,这些示例可以在附录A.2和A.3中找到。
2.3 Instruction Formulation & Target Augmentation(指令制定&目标增强)
2.3.1 使用LLM进行表格预测时的问题
-
可靠性问题:
- 传统的机器学习(ML)算法会为每个类别产生概率预测,这种方法可以提供预测的置信度。
- 相比之下,直接提示LLM生成目标标签(如“是”或“否”)并不提供这种概率预测,因此在文本生成的不确定性下,LLM的标签预测可能不可靠。
-
鲁棒性问题:
- 当遇到具有挑战性的表格预测任务或噪声输入时,这种建模范式可能会失败,导致模型无法收敛。
- 在这些情况下,LLM可能拒绝生成预测,或者倾向于继续输入文本而不是生成预测结果。
为了解决这些问题,作者提出了以下解决方案:
2.3.2 目标增强
通过增加一个目标增强步骤来实现:
不是直接生成标签,而是指导模型预测每个类别的概率,eg:“是:0.8;否:0.2”。这样可以提供预测的置信度,增加可靠性,为LLM提供了更丰富的信息和更稳定的预测能力。
-
目标增强:将目标标签转换为每个类别的概率,提高预测的可靠性。
-
类别定义:离散目标用独热编码,连续目标按分位数定义类别。
-
XGBoost预测器:使用校准的XGBoost为每个数据集生成类别概率,避免信息泄露。
-
序列化:将类别和概率转换为序列,用于微调LLM。作者定义了一个函数serialize_target(t, p),将目标类别和概率序列化为一个格式化的序列,如 “class (t1) : (p1), class (t2) : (p2), …”。这个序列用作微调LLM的参考输出。
-
提高鲁棒性:目标增强为LLM提供更多监督,增强训练和推理时的稳定性。
2.4 Learning(学习)
这部分内容概述了如何通过微调和评估来训练和优化LLM,以便在表格数据预测任务中实现准确的预测。主要包括以下几个关键点:
-
微调目标:在微调阶段,目标是最小化经过调整的LLM函数(LLM(prompt(M,S,I)))生成的输出序列与目标增强生成的参考输出序列(serialize_target(augment(T)))之间的差异。
-
预测正确性评估:在测试阶段,评估的是预测的正确性,而不是输出与参考序列之间的相似性。这通过将LLM生成的自然语言序列映射到模型预测的实际类别,并与真实标签进行比较来实现。
-
映射技术:使用正则表达式匹配技术将LLM生成的序列映射到预测的类别。
-
模型学习过程:在模型学习过程中,使用不同数据集的样本和元数据生成提示,并基于指令微调来更新模型。然后,通过将类别预测(经过输出映射后)与原始目标值进行比较,评估模型的实际性能。
-
模型和工具:采用GPT-2作为模型的主干,并使用huggingface包进行训练。参数选择的详细信息可以在附录B.3中找到。
三、实验
本节回答了以下研究问题:
- 通用表格建模:
单个UniPredict模型是否能成功地对广泛的表格数据集进行通用建模? - 少样本学习:
与基线相比,预训练的UniPredict模型对新任务的适应程度如何? - 分析1:
在什么情况下UniPredict对其他人竞争力较差? - 分析2:
什么是使UniPredict成为通用表格谓词的成功候选者的关键因素?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









