







Redis学习笔记
一、增
1.给库中添加数据,格式为:
set key value //设置单个键值对,可用来修改值
mset key value //设置多个键值对,可用来修改值
setnx key value //只允许添加,如果修改的键已经存在则修改失败
msetnx k1 v1 k2 v2 //如果添加的键中有已经存在的键则全部添加失败
getset key value //键key对应的原value修改为新值,并将旧值返回
setex key time value //设置key的值(value)并设置过期时间(time)
set key value nx ex 10 //这种方式为上锁操作,且设置锁的过期时间为10秒,加nx的都为上锁操作,包含上边3,4条
二、删
1.删除指定的key数据,格式为: del key 或者
unlink key (只会将key从keyspace元数据中删除的,真正的删除会在后续的异步操作完成)
127.0.0.1:6379> unlink a
(integer) 1
127.0.0.1:6379> del 3
(integer) 1
2.清空所有数据
//清空当前数据库的所有数据,1个库
127.0.0.1:6379> flushdb
OK
//清空所有redis数据库的所有数据,16个库
127.0.0.1:6379> flushall
OK
三、改、
后边对应的数据类型有对应的操作方式
四、查
1.查看该数据库中的所有键,格式为: keys *
127.0.0.1:6379> keys *
1) "1"
2) "2"
2.查看该数据库中对应键的字符串值,格式为:
get k1 //获取单个键的值
mget k1 k2 //获取多个键的值
五、其他
1.判断某个键是否存在,格式为: exists key
127.0.0.1:6379> exists 1
//返回值
(integer) 1
2.查看键是什么类型,格式为: type key
127.0.0.1:6379> type 1
//返回值
string
3.给某个键添加过期时间,格式为: expire key time(s)
127.0.0.1:6379> expire 1 50
(integer) 1
4.查看该键还有多少秒过期,格式为: ttl key
127.0.0.1:6379> ttl 1
(integer) 42
//表示还有42秒过期
127.0.0.1:6379> ttl 1
(integer) -2
//表示已经过期
127.0.0.1:6379> ttl 2
(integer) -1
//表示永不过期
5.选择数据库,格式为: select index
127.0.0.1:6379> select 0
OK
6.查看该数据库中key的数量,格式为: dbsize
127.0.0.1:6379> dbsize
(integer) 2
六、数据类型
1.字符串类型(String)
字符串类型的实际分配到的空间一般大于字符串的真是大小,底层使用动态分配的原理,如果字符串的大小小于1M,则扩容时会加倍现有的空间;如果字符串的大小大于1M,则扩容时一般为扩容空间为1M;且字符串的大小最大不能超过512M。
(1) 获取指定范围的字符串
getrange key start end
例如: k1 : helloworld
getrange k1 0 4 //返回的数据为hello
(2)设置指定位置的值
setrange key 起始位置 修改的值
例如: k1 : helloworld
setrange k1 0 abc //修改完后使用get k1 得到 abcloworld
append key value //将value值追加到key键的值的最后
strlen key //返回该键的值的字符串长度
incr key //将对应的值加一,只能对数字值进行操作,如果不存在则设置为1
decr key //将对应的值减一,只能对数字值进行操作,如果不存在则设置为-1
2.列表类型
列表底层为quicklist,而quicklist的底层为ziplist,ziplist又是一个双向的链表。
lpush key1 v1 v2 v3 //在列表的左侧插入值,所以获取的顺序为 v3 v2 v1
rpush key2 v1 v2 v3 //在列表的右侧插入值,所以获取的顺序为 v1 v2 v3
lpop key1 //从列表的左侧取出第一个元素,所以获取的值为v3
rpop key2 //从列表的右侧取出第一个元素,所以获取的值为v3 这里取出的值在列表中会删除
rpoplpush key1 key2 //将key1的右侧取出一个值放在key2的左侧
lrange key1 0 -1 //表示遍历下标(从左到右)输出列表的值,但不删除
lindex key index //可以根据下标获取元素
llen key //获取列表的元素个数,即长度
lrem key n value //从左边删除n个value值
lset key index value //将key中的下标为index的值替换为value
linsert key before/after value newvalue //在key中的value值前边/后边插入newvalue值
3.集合类型
sadd key v1 v2 //向set集合中添加多个值
smembers key //查看集合的所有值
sismember key value //查看集合中是否有该value 如果有返回1 没有返回0
scard key //返回集合中元素的个数
srem key value //从set集合中删除value,可以多个值一起删除
spop key //随机从集合中取出一个值(这里会删除这个值)
srandmember key n //随机从key中读取n个值,不会删除
smove source destination value //将value从source集合中移动到destination集合中
sinter k1 k2 //返回两个集合的交集
sunion k1 k2 //返回两个集合的并集
sdiff k1 k2 //返回两个集合的差集
4.Hash类型
hset key value //存储Hash数据
hget key field //取出key里的field字段数据
hmset key field1 value1 field2 value2 //一次性存储多个键值对
hsetnx key field value //添加键值对,如果这个键不存在则添加成功,否则失败
例子:
127.0.0.1:6379> hset id:1 name zhangsan age 20
(integer) 2
127.0.0.1:6379> hget id:1 name
"zhangsan"
hexists key field //查看hash表key中的域是否存在field字段 存在返回1 不存在返回0
hkeys key //查看key中的含有field字段名
hvals key //查看key中的所有字段的值
hincrby key field number //将key中的field字段的值加上number
5.有序集合类型
zadd key score1 value1 score2 value2 //用来创建有序集合或者向有序集合中添加值
zrange key start end [withscores] //从小到大的获取有序集合中的值,加上withscores会将每个值的score返回
zrevrange key start end [withscores] //从大到小的获取有序集合中的值,加上withscores会将每个值的score返回
zincrby key increment value //为key中的value的score加上increment(可正可负)
zrem key value //删除该key下的value值
zcount key start end // 查询在[start,end]区间有多少个元素
zrank key value // 返回该值在集合中的排名,从0开始
6.bitmap类型
7.HyperLogLog类型
擅长进行基数运算
pfadd key value //向HyperLogLog中存储数据
pfcount key //查看该HyperLogLog集合中的基数个数
pfmerge PLL3 PLL1 PLL2 //将PLL1和PLL2中的数据合并到PLL3中
8.Geospatial类型
geoadd key 经度 纬度 地名 经度 纬度 地名 ... //向Geospatial集合中添加位置和经纬度
geopos key 地名 //获取地名的经纬度
geodist key 地名1 地名2 x单位 //以x为单位,获取地名1与地名2的直线距离
georadius key 经度 纬度 距离 单位 //获取经纬度以方圆多少单位内的位置
七、订阅与发布
订阅: 通过订阅可以获取发布者发布的消息
发布: 发布者向信道发布消息
subscribe channel // 订阅channel
publish channel message //向channel中发布message,发布后订阅channel的订阅者可以接受到message
八、事务(三大特性:没有隔离级别的概念 不保证原子性 单独的隔离操作)
单独的隔离操作:指在事务队列进行时,其他客户端发来的请求不能打断事务的进行。事物的所有命令都会按顺序的进行。
没有隔离级别的概念:在事务被提交之前所有事务中的命令都不会被实际的执行。
不保证原子性: 事务中有一条命令报错其他命令仍然会继续执行,不会回滚。
命令:Multi (类比MySQL事务的开启事务) Exec(类比MySQL事务的提交事务) Discard(类比MySQL事务的回滚)
在开启事务后的队列中如果有命令报错(即 Multi 阶段),那提交事务后则事务中的全部命令均不执行
在开启事务后的队列中命令无错误,而提交事务后报错(即 Exec 阶段)则事务中错误命令不执行,其他命令均执行
事务冲突:
悲观锁:
认为总会有人来修改数据,所以在对数据进行操作时就会把数据上锁,我使用时别人不能对数据进行操作
乐观锁:
认为不会有人来修改数据,但是在我对数据进行修改时会同时获得版本号,再修改完数据后查看版本号是否与以前一致,如果一致则修改数据并更改版本号,如果版本号不一致则修改数据失败。
乐观锁在redis中的实现:
watch key //监视key,在两个或多个事务同时进行时,如果其中一个事务修改了这个键的值,则其他的事务对该键值的操作全部失效。
在redis中,乐观锁加事务能够很好的解决超卖问题,但是会出现连接超时和商品遗留问题。连接超时可以通过配置连接池解决,而商品遗留问题需要通过Lua脚本来解决。
后边学习的时候忘了做笔记,小做一些理论
九、持久化
1.RDB(Redis DataBase):
劣势:
1.适用于对数据一致性和完整性要求不高的数据持久化。
2.RDB这种持久化技术的最后一次持久化后的数据容易丢失。
3.RDB在持久化时会创建临时文件,所以对空间有要求,在持久化时会膨胀数据文件。
4.不能做到秒级持久化、实时持久化,因为每次持久化都要创建子进程,对性能消耗较大。
优势:
1.使用了写时复制技术,在持久化时会创建一个dump.rdb文件,在持久化完成后替换上一次持久化的文件。
2.Redis在持久化时一般会创建一个(fork)子进程来进行持久化,父进程不需要进行任何IO操作,效率提高,且父进程与子进程一般共用同一段物理内存。
3.可以周期性的持久化数据。
2.AOF
生成的appendonly.aof 为持久化文件,如果文件损坏,可以通过
redis-check-aof --fix appendonly.aof //来修复文件
优势:
1.数据保证:我们可以设置appendfsync策略,一般默认是everysec,表示每秒同步一次,所以即使服务死掉了,咱们也最多丢失一秒数据,除了这种同步频率外,还有:always与no
always:表示始终同步,只要有写操作就会同步,性能较差,数据完整性较好。
no:不主动同步数据,把时机把控交给操作系统。
2.自动缩小:当aof文件大小到达一定程度的时候,后台会自动的去执行aof重写,此过程不会影响主进程,重写完成后,新的写入将会写到新的aof中,旧的就会被删除掉。
劣势:
1.性能相对较差:它的操作模式决定了它会对redis的性能有所损耗
2.体积相对更大:尽管是将aof文件重写了,但是毕竟是操作过程和操作结果仍然有很大的差别,体积也毋庸置疑的更大。
3.恢复速度更慢
十、主从复制
一主多从 : 读写分离,容灾恢复。记住:Master主库负责写,Slave从库负责读,在主库上可以同时读写,但从库上不能进行写操作,否则会报错。主库挂了,Redis的读操作不受影响,但写操作就不可以了,只能等到主库恢复后,方可以写操作。如果从库挂了,主库和另外剩余的从库不受影响,但当挂了的从库恢复后,执行:info replication 后,他的角色就变成了Master,之前约定的主从关系消失了,需要显式指定主从关系,需要执行:slaveof ip 端口,除非你在conf中进行主从说明
薪火相传 : 上一个slave可以是下一个slave的Master,slave同样可以接收其他slaves的连接和同步请求,那么该slave作为了链条中下一个的master, 可以有效减轻master的写压力,去中心化降低风险。中途变更转向会清除之前的数据,重新建立拷贝最新的。风险是一旦某个slave宕机,后面的slave都没法备份。
反客为主 : 当master宕机后,后面的slave通过手动指令可以升为master ,设置的指令为: slaveof no one ,意思是说,在从机中去掉一个,变为主机。反客为主的模式是在一主二仆的基础上变更过来的,因此,我们需要先将薪火传递模式修改为一主二仆或一主多仆。
哨兵模式 : 哨兵模式其实是反客为主的升级版,在反客为主模式中,我们需要执行指令 slaveof no one 来进行主机的选举,在哨兵模式中这个动作是自动完成了。哨兵哨兵,用于巡逻,当发现主机挂了后,他会立即在从机中选举一个充当主机。
但是,当死去的主机又回来后,哨兵会检测到,但是主机的地位将不再是它,它会充当从机。哨兵模式目前是最受欢迎的主从复制模式,它工作在一主二(多)仆基础之上。切记。配置sentinel.conf文件来实现哨兵模式(文件名必须为这个)
sentinel.conf文件内容:
# 这个是Redis6379配置内容,其他文件同理新增然后改一下端口即可,26380,和 26381。
#当前Sentinel服务运行的端口
port 26379
# 哨兵监听的主服务器 端口号 和 投票票数
sentinel monitor mymaster 127.0.0.1 6379 1
# 3s内mymaster无响应,则认为mymaster宕机了
sentinel down-after-milliseconds mymaster 3000
#如果10秒后,mysater仍没启动过来,则启动failover
sentinel failover-timeout mymaster 10000
# 执行故障转移时, 最多有1个从服务器同时对新的主服务器进行同步
sentinel parallel-syncs mymaster 1
十一、缓存穿透、缓存击穿、缓存雪崩
缓存穿透:访问redis缓存和数据库中都不存在的数据,导致大量访问直接打在数据库上。
解决方案:
(1)设置空值缓存,一般这种空值缓存过期时间会很短(不超过5分钟) ***应急方案***
(2)使用bitmaps设置白名单,为可访问的key在bitmaps上设置偏移量,对不在白名单上的数据请求进行拦截
(3)使用布隆过滤器,底层也是bitmaps
(4)进行实时监控,当发现redis命中率急剧下降时设置黑名单限制服务
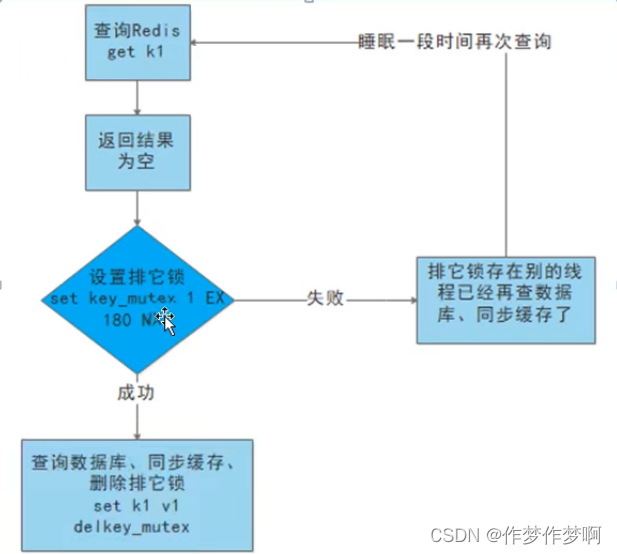
缓存击穿:访问redis缓存中过期的key,导致热点key的大量访问击穿打到数据库上。
解决方案:
(1)预先设置热门数据,将这些热门数据提前存入到redis缓存中,并设置较长的过期时间
(2)实时调整,实时监控,实时调整热点key的过期时长
(3)使用锁,如下图1-1
缓存雪崩:redis缓存中大量key批量过期,大量访问集中打到数据库上,导致请求等待,响应也随之变慢甚至崩溃。
解决方案:
(1)构建多级缓存 { nginx缓存,redis缓存,其他缓存 }
(2)设置锁和队列保证不会有大量线程对数据库一次性进行读写 # 效率较低,不适合高并发的情况
(3)设置过期标志更新缓存(设置提前量,如果达到阈值则通知其他线程去数据库进行更新key的操作)
(4)将缓存失效时间分散开,在多个同时失效的key的过期时间基础上加上随机事件
图1-1















 503
503











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











