






1.工具
工具:drissionpage(🛸 概述 | DrissionPage官网)、Google Chrome、PyCharm 2024.1.1
网站:福州市产业园区大全(524)_福州市产业规划 - 前瞻产业研究院 (qianzhan.com)
利用第三方库爬取网页数据输出csv文件
2.流程
2.1预览
正式开始前先看网页结构(F12或右击--检查),可以看到,要爬取的数据是表格的形式。
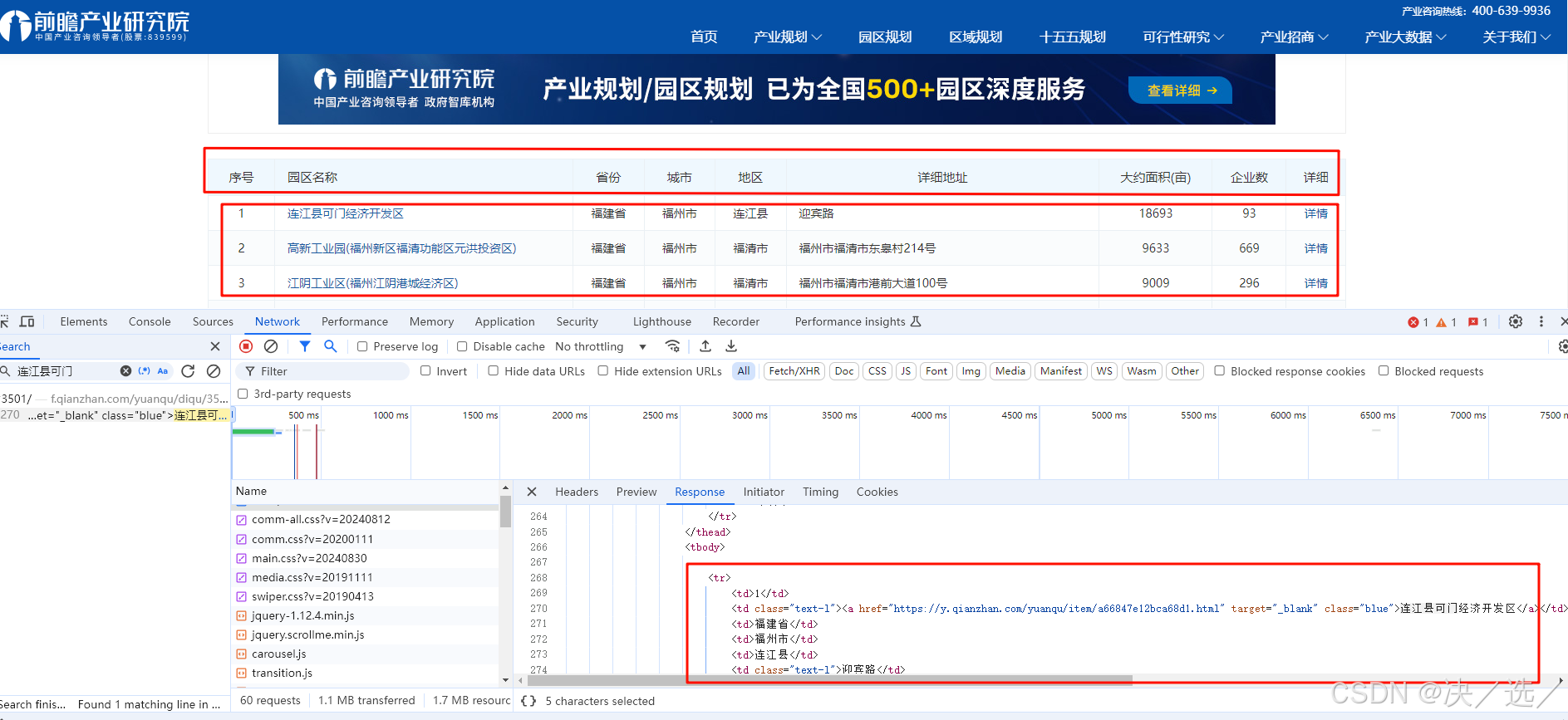
2.2代码实现
# author: 等一把尤尼克斯
# Date: 2024/10/14
# uesd: 用于采集园区数据,并输出csv文件
'''
请谨慎使用本代码,并在使用前谨慎评估其适用性。
'''
import csv
from DrissionPage import ChromiumPage
# 打开浏览器
browser = ChromiumPage()
# CSV 文件路径
csv_file = 'baidu_park_data.csv'
# 写入表头到 CSV 文件
with open(csv_file, 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f)
writer.writerow([
'序号', '园区名称', '省份', '城市', '地区',
'详细地址', '大约面积(亩)', '企业数'
])
# 监听数据包
browser.listen.start('f.qianzhan.com/yuanqu/diqu/3501')
for page_num in range(1, 11): # 使用 page_num 代替 page 作为循环变量
print(f'正在采集第 {page_num} 页')
# 访问指定页面
browser.get(f'https://f.qianzhan.com/yuanqu/diqu/3501/?pg={page_num}')
browser.wait.load_start() # 等待页面加载完成
# 先搜索 tr 结构,然后搜索指定的 td 列
ele1 = browser.ele('tag:tr@@text():园区名称')
print(ele1.text)
# 提取并写入每一行的数据
with open(csv_file, 'a', newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f)
for i in range(1, 21):
ele2 = browser.ele(f'x:/html/body/div[3]/div[3]/div[1]/table/tbody/tr[{i}]')
print(ele2.text)
row_data = ele2.text.split('\t')[:-1] # 去掉最后一列“详情”
writer.writerow(row_data)
# 点击下一页
for pg_num in range(2, 11, -1): # 使用 page_num 代替 page 作为循环变量
ele = browser.ele(f'x://*[@id="divpager"]/a[{pg_num}]').click()
browser.wait.load_start()

















 239
239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









