






spark
一、spark组件:
-
Spark Core (核心底层部分)
- 基于RDD
- 支持多种语言
-
Spark SQL
- 基于DataFrame
- 结构化数据查询
-
Spark Streming 流处理
-
Spark MLLib 机器学习
-
Spark GraphX 图计算
二、spark与mr的区别
mr:额外的复制、序列化、磁盘IO开销、细粒度资源调度;多进程
spark:基于内存、DAG有向无环图、粗粒度资源调度;多线程
三、spark部署模式
-
Local模式(本地开发测试)
-
Standalone模式
- 独立运行模式
- 自带完整的资源管理服务
- 可单独部署到一个集群中
- 无需依赖任何其他资源管理系统
- 主从架构:Master/Worker
- 支持两种任务提交方式
- Cluster:适用于生产环境
- Client:适用于交互、调试
-
On Yarn模式
-
将Spark程序提交到Yarn上运行
-
由Yarn负责管理维护资源
-
不需要额外构建Spark集群
-
支持两种任务提交方式(如上)
-
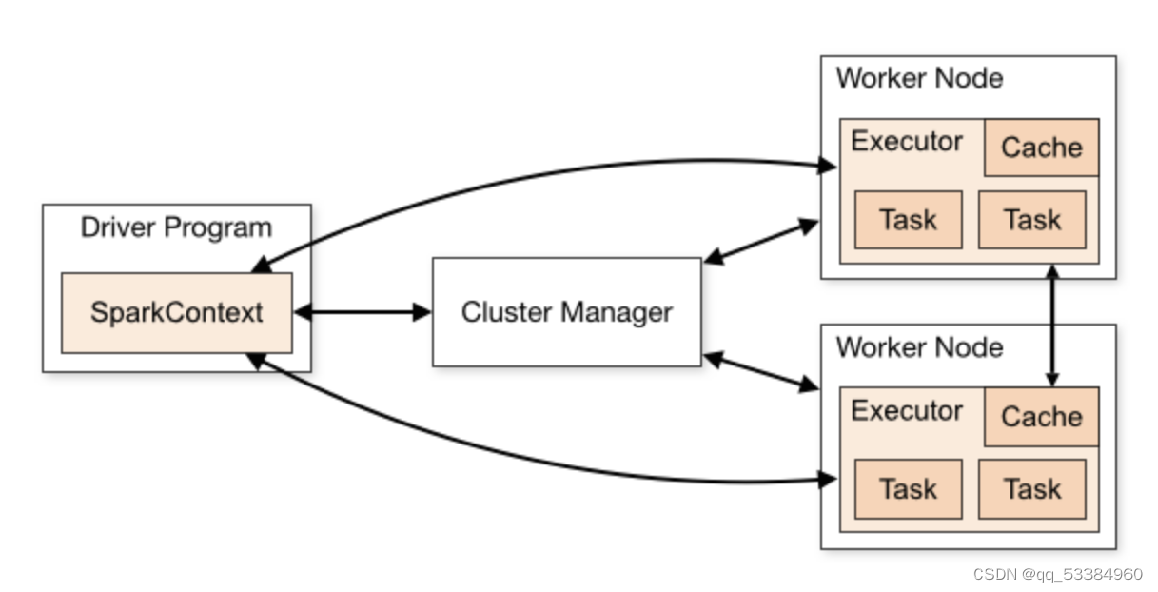
四、Spark任务架构
- Driver(一个JVM进程)
- 执行main方法
- 执行用户提交的代码,创建sparkcontext或soarksession
- 在Cluster Manager帮助下把task任务分发出去
- Spark Context/Session
- 由driver创建
- 程序和集群的交互入口
- 连接Cluster Manager
- Cluster Manager
- 部署整个spark集群
- Executor
- 一个创建在worker节点的进程
- 一个excutor有多个线程
- 一个线程对应一个task
- 负责执行spark任务,把结果返回给driver
- 将数据缓存到worder节点的内存
五、RDD五大特性
- RDD 是由一系列分区组成的
- Task是作用在分区上的,一个分区至少一个task
- RDD之间有一系列依赖关系(宽依赖《一对多》、窄依赖《一对一》)
- 分区器是作用在KV格式的RDD上的
- 为每个Task尽可能提供最佳计算位置
六、算子分类
-
Transformation 变换/转换算子
- 基于Value数据类型的Transformation算子(map、flatMap、filter)
- 基于Key-Value数据类型的Transfromation算子(groupByKey、reduceByKey、join)
-
Action 行动算子
-
会触发SparkContext提交Job作业
-
一个Action算子对应一个Job
-
foreach、count、take、collect、reduce
-
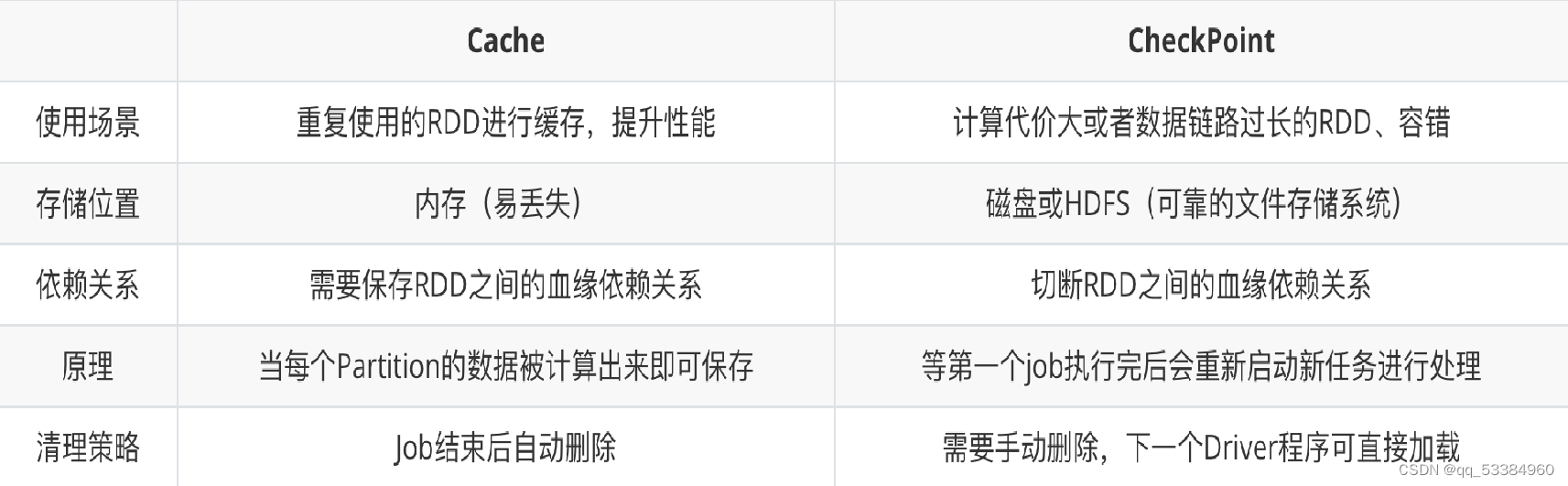
七、缓存
- cache/persist缓存
- checkpoint
- 当RDD的job执行完毕后,会从最后一个RDD往前回溯
- 当回溯到某个RDD调用了checkpoint方法后,Spark会启动一个新的job
- 该任务会重新计算该RDD的数据,并持久化到HDFS上
Spark调优
- 对多次使用的RDD进行持久化
- 使用MEMORY_AND_DISK_SER级别
该级别会将RDD数据序列化后再保存在内存中,此时每个 partition仅仅是一个字节数组而已,大大减少了对象数量,并降低了内存占用
(RDD存储共有12种,大致分为1、内存 2、磁盘 3、序列化 4、副本 5、本地内存)
-
使用高性能算子
- 使用reduceByKey/aggregateByKey替代groupByKey (aggregateByKey传入两个参数列表,第一个为初始值,第二个分为map和reduce两种逻辑运算)
- 使用mapPartitions替代普通map Transformation算子
- 使用foreachPartition替代foreach Action算子 (foreachPartition:针对每个分区执行一次算子,每个分区的数据被包装成一个 迭代器)
- 使用filter之后进行coalesce操作(coalesce: 默认shuffle为false,对于上一个RDD的分区可以调小 不可以调大)
- 使用repartitionAndSortWithinPartitions替代repartition与sort类操 作 代码
- repartition:coalesce(numPartitions,true) 增多分区使用这个
- coalesce(numPartitions,false) 减少分区 没有shuffle只是合并 partition
-
广播大变量::Executor一开始并没有广播变量,而是task运行需要用到广 播变量,会找executor的blockManager要,bloackManager找Driver里面的 blockManagerMaster要
好处:减少网络传输的性能开销,并减少对Executor内存的占用开销,降低 GC的频率
-
使用Kryo优化序列化性能
-
优化数据结构:对象、字符串、集合类型(HashMAP、LinkList)会占用大量内存,尽量使用原始类型(int、Long)代替字符串,或者数组代替集合类型,减少内存小占用,降低GC
-
使用高性能的库fastutil
-
提高本地化级别
- PROCESS_LOCAL进程本地化
- NODE_LOCAL节点本地化
- NO_PREF无最佳位置
- RACK_LOCAL机架本地化
- ANY跨机架调用
-
JVM调优
-
shuffle调优
-
调节Executor堆外内存
-
数据倾斜化
-
使用Hive ETL预处理数据
- 通过hive ETL进行数据预处理(预聚合),避免执行shuffle类算子。
-
过滤少数导致倾斜的key
- 如果发现导致数据倾斜的数据只有少数,可过滤掉少数key
-
提高shuffle操作的并行度
- 设置shuffle read task的数量,让原本分配给一个task的多个key分配给多个task,从而让每个task处理比原来更少的数据
-
双重聚合
- 针对执行reduceByKey等聚合类shuffle算子或者使用group by语句时,可进行双重聚合
- 第一次:局部聚合,给key打上随机数,聚合后全局聚合。
- 通过增加前缀变成多个不同的key,让原本被一个task处理的数据分散给多个task局部聚合。
-
将reduce join转为map join
- 有一大表一小表join,不使用join语句,使用broadcast与map实现join操作,避免shuffke,不会出现数据倾斜。
-
采样倾斜key并分拆join操作
- 针对两表join,且一表key分配均匀,一表key分配不均匀。
- 先将数据量过大的key通过sample采出样本,统计并计算数据量最大的是哪几个key;
- 然后将这几个key对应的数据从原来的RDD中拆分出来,形成一个单独的RDD,并给每个key都打上n以 内的随机数作为前缀,而不会导致倾斜的大部分key形成另外一个RDD。
- 接着将需要join的另一个RDD,也过滤出来那几个倾斜key对应的数据并形成一个单独的RDD,将每条数 据膨胀成n条数据,这n条数据都按顺序附加一个0~n的前缀,不会导致倾斜的大部分key也形成另外一个 RDD。
- 再将附加了随机前缀的独立RDD与另一个膨胀n倍的独立RDD进行join,此时就可以将原先相同的key打 散成n份,分散到多个task中去进行join了。
- 而另外两个普通的RDD就照常join即可。 最后将两次join的结果使用union算子合并起来即可,就是最终的join结果。
-
使用随机前缀和扩容RDD进行join
-















 1637
1637











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









