







目录
一、虚拟机的安装与配置
(一)下载虚拟机安装包
1.虚拟机官网下载:https://my.vmware.com/cn.html
2.或直接下载我的安装包(版本:VMware16 pro):链接: https://pan.baidu.com/s/1KsKFYj3OsvFgSWeAxINFvw 提取码: yyqt
(二)虚拟机安装
1.此安装过程非常简单,点击exe文件后一直‘下一步’就好。需要注意的是,建议自定义安装至想要的位置,否则默认C盘
2.安装完毕后,点击桌面快捷方式后会出现许可证密钥界面,不想购买的小伙伴可以网页搜索相关密钥,或者联系我都可以哟
3.输入密钥后,虚拟机就暂时告一段落了
二、Ubuntu系统的安装
(一)下载Ubuntu系统镜像
1.Ubuntu官网下载:https://ubuntu.com/download/desktop
2.或直接下载我的安装包(版本:20.04.2.0):链接: https://pan.baidu.com/s/1f-aQjdD0IqvQ4exFSEwZ-A 提取码: 6y7i
(二)Ubuntu安装
1.打开虚拟机,点击‘创建新的虚拟机’

2.此步选‘典型’即可 ,根据需求可选自定义

3. 在‘安装程序光盘映像文件’导入Ubuntu镜像目录,然后选择‘稍后安装操作系统’

4.此步选择‘Linux’与‘Ubuntu64位’,如果是其他需求可自选

5.命名依靠个人文采来,位置根据自己喜好去

6.此处默认‘20.0’与‘将虚拟磁盘拆分成多个文件’,无须更改

7. 此处选择‘自定义硬件’

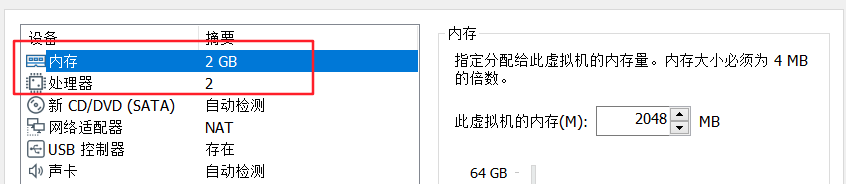
8. ‘内存’与‘处理器’根据电脑配置来,建议内存在2G以上,可适当上调
9.‘CD/DVD’选择‘启动时连接’与‘使用ISO映像文件’,‘网络适配器’选‘NAT’,其余默认即可,检查一遍后点击右下角‘关闭’

10.点击‘开启此虚拟机’,若报错可能需要关机后进入BIOS页面开启虚拟化支持,重启后再进入虚拟机(具体可自行查询或联系我)

11.开机后会出现一段代码,稍微等待一下即可(不是not found 之类的报错就行)
12.滑动到最后选择中文(简体) ,点击‘安装Ubuntu’(其他语言爱好者可自选),注意:最下方的弹窗不要点击‘我已完成安装’,装作没看见或者关闭

13. 键盘布局默认汉语,点击‘继续’

14.保持默认‘正常安装’与‘安装Ubuntu时下载更新’

15.保持默认‘清除整个磁盘并安装Ubuntu’,点击‘现在安装’

16.允许‘将改动写入磁盘’,点击‘继续’

17.保持默认‘Shanghai’,点击‘继续’

18.设置帅气的姓名和安全的密码

19.进入安装界面,时间不会短,喝杯水休息一下

20.安装完毕后点击‘现在重启’

21.重启过程中记得按一下‘ENTER’键

22.此时Ubuntu系统可能不会全屏,点击‘虚拟机’与‘安装VMware Tools’ (如果显示的是‘重新安装VMware Tools’,则无须再次安装)

23. 桌面或左栏出现光盘图标后,点击左下角9个小点或者按‘Ctrl+Alt+T’打开终端

24.在终端输入命令 tar -zxvf VMwareTools-10.1.3-5214329.tar.gz 后按回车,版本不一样后面的数字不一样,可按下‘Tab’键自动补齐当前版本
$ tar -zxvf VMwareTools-10.1.3-5214329.tar.gz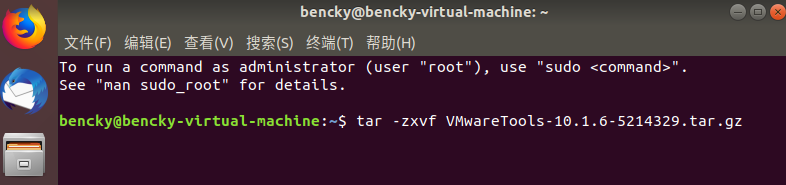
25.等待解压完毕后,继续输入命令 cd vmware-tools-distrib ,回车后再输入 sudo ./vmware-install.pl ,回车后输入密码再回车即开始安装,遇到[yes]或者[no]输入yes ,其余停下的地方按回车即可 ,最后出现如下界面即成功
$ cd vmware-tools-distrib
$ sudo ./vmware-install.pl
26.点击此图标即可全屏

27.点击左下角的小点后可选择经常用的软件,右击‘添加到收藏夹’至桌面左栏

28.若第一次启动发现屏幕不清晰,可进入设置,点击显示器,调节分辨率与缩放

三、Hadoop的安装与配置
(一)创建Hadoop用户
$ sudo useradd -m hadoop -s /bin/bash #创建hadoop用户,并使用/bin/bash作为shell
$ sudo passwd hadoop #为hadoop用户设置密码,之后需要连续输入两次密码
$ sudo adduser hadoop sudo #为hadoop用户增加管理员权限
#然后注销当前用户,用hadoop用户登录


(二)更新配置与设置免密登录
$ sudo apt-get update #更新hadoop用户的apt,方便后面的安装
$ sudo apt-get install vim #安装vim编辑器
$ sudo apt-get install openssh-server #安装SSH server
$ ssh localhost #登陆SSH,第一次登陆输入yes
$ exit #退出登录的ssh localhost
$ cd ~/.ssh/ #如果没法进入该目录,执行一次ssh localhost
$ ssh-keygen -t rsa #连续敲击三次回车
$ cat ./id_rsa.pub >> ./authorized_keys #加入授权
$ ssh localhost #此时已不需密码即可登录localhost,如下图
(三)安装与配置jdk
1.首先在Oracle官网下载jdk1.7(我的版本:jdk-7u80-linux-x64.tar.gz) http://www.oracle.com/technetwork/java/javase/downloads/index.html
2.解压压缩包
$ mkdir /usr/lib/jvm #创建jvm文件夹
$ sudo tar zxvf jdk-7u80-linux-x64.tar.gz -C /usr/lib #解压到/usr/lib/jvm目录下
$ cd /usr/lib/jvm #进入该目录
$ mv jdk1.7.0_80 java #重命名为java
$ vim ~/.bashrc #给jdk配置环境变量
3.在 .bashrc 文件添加如下指令(按‘i’插入,编辑完成按‘Esc’与‘:wq’保存并退出)
export JAVA_HOME=/usr/lib/jvm/java
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH

4.生效环境变量并检验java版本(出现类似下图即成功)
$ source ~/.bashrc #使新配置的环境变量生效
$ java -version #检测是否安装成功,查看java版本
$ echo $JAVA_HOME

(四)安装Hadoop与配置环境变量
1.Hadoop官网下载安装包:https://hadoop.apache.org/releases.html ,根据需要选择版本
2.解压缩
$ sudo tar -zxvf hadoop-3.3.1.tar.gz -C /usr/local #解压到/usr/local目录下
$ cd /usr/local #到该目录下
$ sudo mv ./hadoop-3.3.1/ ./hadoop #重命名为hadoop
$ sudo chown -R hadoop ./hadoop #修改文件权限
$ cd /usr/local/hadoop #到该目录下
$ ./bin/hadoop version #检查是否正确
$ vim ~/.bashrc #配置hadoop环境变量
3.在 .bashrc 文件添加如下指令(按‘i’插入,编辑完成按‘Esc’与‘:wq’保存并退出)
export HADOOP_HOME=/usr/local/hadoop
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

4.生效环境变量并检验hadoop版本(出现类似下图即成功)
$ source ~/.bashrc
$ hadoop version
(五)伪分布式配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改配置文件 core-site.xml 和 hdfs-site.xml等。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
1.修改 ‘hadoop-env.sh’文件(更改For example:后面的JAVA_HOME路径)
$ cd /usr/local/hadoop/etc/hadoop #到该目录下
$ vim hadoop-env.sh #修改该文件
2.修改‘core-site.xml’文件,加入如下代码
$ vim core-site.xml<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>

3.修改‘hdfs-site.xml’文件,加入如下代码
$ vim hdfs-site.xml<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>hadoop-cluster</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hdfs/nn</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:/usr/local/hadoop/hdfs/snn</value>
</property>
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:/usr/local/hadoop/hdfs/snn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hdfs/dn</value>
</property>
</configuration>

4.修改‘mapred-site.xml’文件,加入如下代码
$ vim mapred-site.xml<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>maprd.reduce.tasks</name>
<value>1</value>
</property>
</configuration>

5.修改‘yarn-site.xml’文件,加入如下代码
$ vim yarn-site.xml最后一个<value>hadoop classpath 后的代码通过输入命令 hadoop classpath 查看
$ hadoop classpath<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>localhost:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>file:/usr/local/hadoop/yarn_data/nm</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>hadoop classpath /usr/local/hadoop/etc/hadoop:/usr/local/hadoop/share/hadoop/common/lib/*:/usr/local/hadoop/share/hadoop/common/*:/usr/local/hadoop/share/hadoop/hdfs:/usr/local/hadoop/share/hadoop/hdfs/lib/*:/usr/local/hadoop/share/hadoop/hdfs/*:/usr/local/hadoop/share/hadoop/mapreduce/*:/usr/local/hadoop/share/hadoop/yarn:/usr/local/hadoop/share/hadoop/yarn/lib/*:/usr/local/hadoop/share/hadoop/yarn/*</value>
</property>
</configuration>

6.输入命令创建以下几个文件夹
$ mkdir -p /usr/local/hadoop/hdfs/nn
$ mkdir -p /usr/local/hadoop/hdfs/snn
$ mkdir -p /usr/local/hadoop/hdfs/dn
$ mkdir -p /usr/local/hadoop/yarn_data/nm7.执行namenode格式化并启动进程
$ cd /usr/local/hadoop #到该目录下、
$ ./bin/hdfs namenode -format #格式化
$ start-all.sh #启动进程
$ jps #判断是否启动成功 
8.成功启动后到浏览器访问web:http://localhost:9870 和 http://localhost:8088


(六)实际测试Hadoop自带案例
通过运行Hadoop安装包里面自带的mapreduce示例代码来检验Hadoop环境是否可以运行
$ mkdir /home/hadoop/data #创建data文件夹
$ cd /home/hadoop/data #到该文件夹目录下
$ touch a.txt #创建测试文本
$ vim a.txt #编辑测试文本内容
$ cat a.txt #检查文本内容
$ hadoop fs -mkdir /input #创建input目录
$ hadoop fs -rm -r /output #若有output目录,则将其删除
$ hadoop fs -put /home/hadoop/data/a.txt /input #将测试文本放入input目录
$ hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-example-3.3.1.jar wordcount /input /output #开始执行此任务 #第一个参数为任务的jar包位置,第二个参数为任务运行的接口类,第三个参数为输入数据目录,第四个参数为输出结果目录
$ hadoop fs -ls /output #查看输出目录
$ hadoop fs -cat /output/part-r-00000 #查看输出结果四、笔者若有所思
1.以上只是我近一段时间的一些小总结,可能很粗糙,也有很多的漏洞,希望大家能够给予包容、多多指正、互相学习。可能你按照我的操作,最后不一定能够在自己的机器上成功,但是我也非常希望大家能够从我的文章中获取到哪怕一点点有用的知识。大家在评论区的一句小小的鼓励都是我不断前进的动力。如果大家有更友好的理解、更精炼的操作、更丰富的资源,非常希望、非常欢迎、非常期待各位读者能够积极与我、与其他读者分享和交流;
2.Hadoop确实是一个非常强大的工具,能够在上面解决很多复杂的问题,但同时他它也非常脆弱,对操作者不太友好,很容易出现一些意想不到的问题。就跟变脸一样,可能突然就用不了了,或者一模一样的操作,别人好好的,但是在你这可能就是不行。特别是我们这些初出茅庐的萌新,心态很容易爆炸。哈哈,出现问题一定要冷静加佛系,一定要思考和总结,一定要分享与交流;
3.放弃不难,但坚持一定很酷!加油!互联网事业的奋斗者们!
















 93
93











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











